




I. Introduction▲
Les « Single Instructions Multiple Data » appliquent simultanément une même opération à plusieurs données. Cela correspond, par exemple, à des opérations vectorielles comme 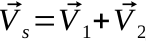  :
 :
|
|

Avec des XMM, cela devient :

Ces jeux d’instructions concernent des entiers (signés ou non) ou des flottants. De l’antique MMX aux différentes versions de SSE, les SIMD ont progressé en richesse fonctionnelle et en registres par leur nombre (de 8 à 16) et leur taille (de 64 bits à 128, voire 256).
Ces instructions ne concernent-elles que strictement les traitements mathématiques ? Pas vraiment.
Prenons l’exemple d’une couleur. Elle comporte trois composantes (rouge, vert, bleu) plus, éventuellement, une quatrième souvent utilisée comme information de transparence. Et il y a beaucoup d’actions sur les couleurs qui peuvent bénéficier d’instructions SIMD.
Ainsi Cs = (C1 + C2)/2 est l’écriture vectorielle de la moyenne de deux couleurs. Elle peut se traduire par :

Simple non ? Combien d’instructions aurait-il fallu en standard ? De l’ordre de 13 soit trois fois plus, car la séparation des composantes nécessite duplications et masquages.
Ignorer les SIMD en données composites ne paraît donc pas raisonnable.
II. Utilisation▲
Dans ce document nous nous limiterons aux seules instructions portant sur des entiers, mais la plupart des principes s’appliquent également aux instructions sur les flottants.
Le terme « composante » désignera les éléments d’un registre MMX/XMM sans s’intéresser au type. Un vecteur peut en effet être vu comme une collection d’octets, de mots de 16 bits, 32 bits, 64 bits ou 128 bits. Or souvent les instructions existent pour plusieurs types sans que cela change fondamentalement leur fonctionnement. Un terme assez générique comme composante paraît alors opportun.
II-A. Lecture d'instruction▲
Le nom des instructions n’est pas d’une lisibilité immédiate (euphémisme et raison du petit mémo joint). Prenons par exemple punpckldq (mais nous aurions pu prendre paddd, psubusb ou packsswb…) :
|
|
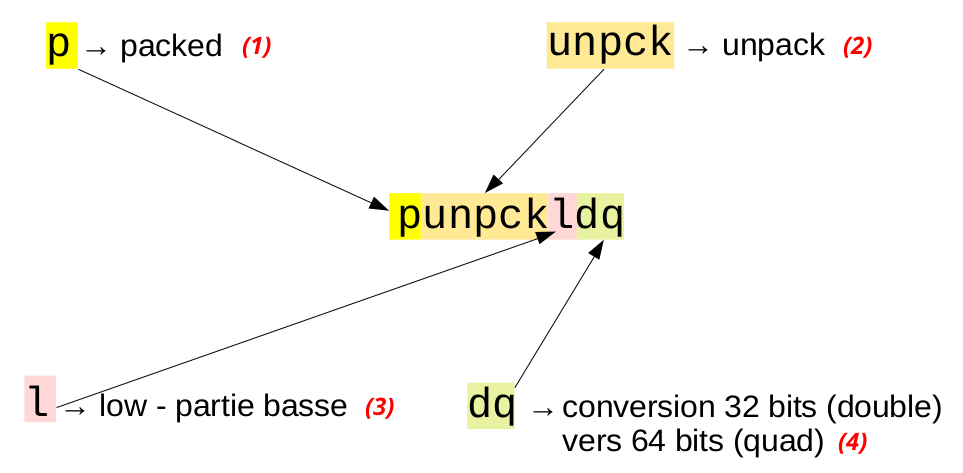
- (1) Le premier caractère (mais il y a des exceptions sinon ce ne serait pas drôle) indique la famille d’instructions. Ici p indique des opérations portant sur des groupes (packs) d’entiers.
- (2) La deuxième partie est le nom de l’opération, ici unpck annonce un décompactage qui va transformer des données d’un format en un format double (byte vers word, word vers double word…).
-
(3) La troisième partie peut comporter un ou plusieurs caractères. Chacun a un sens précis, ici l signifie low c’est-à -dire la moitié basse des registres MMX/XMM. Comme la commande double la taille des données, on ne prend des sources que la moitié basse (l) ou haute (h). Selon les instructions, il y a d’autres lettres :
- u pour unsigned (non signé). Les valeurs sont par défaut signées sauf dans le cas du compactage (packsswb) où le premier s pour signed indique de considérer les données comme signées avant d’opérer la saturation (écrêtage) ;
- s (à nouveau) pour saturation (la valeur 275 transformée en octet est écrêtée à 255 et alors que la simple troncature donnerait 19 car + 19 = 275).
- (4) La dernière partie indique le type de données : b pour byte (octet), w pour word (16 bits), d pour double word (32 bits), q pour quad word (64 bits) et dq pour double quad (128 bits).
- L’instruction de conversion unpck a deux types, le format à convertir et le format résultant. Aussi dq ne signifie pas ici double quad mais double word (d) transformé en quad (q) (sic).
II-B. MĂ©mo▲
Quelques conventions furent nécessaires pour garder concision et lisibilité.
II-B-1. Codes explicatifs▲
- Ils sont écrits dans un sabir issu d’un « C-like » qui accepterait des indices.
- Chaque registre est désigné par un M (pour Multimédia, domaine dédié des premières extensions SIMD) suivi d’un numéro : 1 pour le 1er argument (également destinataire du résultat) et 2 pour le 2e.
- Un indice (b, w, d, q, dq) précise le type de données. Cependant les codes explicatifs ne présentent qu’un seul type même si l’instruction offre des variantes avec d’autres types.
- Chaque composante du vecteur est représentée comme un élément de tableau. Ainsi M1w[i] désigne le word (16 bits) numéro i du registre MMX/XMM numéro 1.
Exemple :

Correspond au code explicatif pour pmaxub :

Qui se lit ainsi : chaque octet (b) n° i de M1 reçoit la valeur maximale des composantes i de M1 et M2 traitée comme non signée (u) – ainsi 0xFF sera considéré comme le nombre positif 255 et non comme -1.
II-B-2. LibellĂ©s▲
Les libellés des instructions sont colorés afin de faire ressortir les différentes parties. Chaque couleur a un sens :
- rouge : partie du registre concernée par l’opération, moitié haute ou basse (h ou l) ;
- vert : non signé ou signé (u ou s) – signé par défaut ;
- bleu : types de données (b, w, d, q, dq). Deux variantes de bleu apparaissent pour les opérations de conversion qui utilisent deux types : entrant et résultant (ex. dq, wb…) ;
- magenta : saturation (s).
II-B-3. Restrictions▲
 Â : MMX seulement, non utilisable avec des XMM.
 : MMX seulement, non utilisable avec des XMM.  : XMM seulement, non utilisable avec des MMX (mais ce ne devrait plus être une contrainte…)
 : XMM seulement, non utilisable avec des MMX (mais ce ne devrait plus être une contrainte…)  : SSE4, AMD et Intel ne se sont pas mis d’accord, chacun a ses propres codes !
 : SSE4, AMD et Intel ne se sont pas mis d’accord, chacun a ses propres codes !
II-B-4. Limitations▲
Pour plusieurs raisons, il n’y a pas toutes les instructions entières dans ce mémo :
- il ne va que jusqu’au SSE4 (ce qui pose déjà des problèmes de compatibilité Intel/AMD) pour éviter du code qui ne tournerait pas sur des machines un peu anciennes ;
- certaines opérations paraissant peu utiles sont restées (injustement ?) à l’écart : ptest, phminposuw, phaddd…
- les oublis sont Ă©galement un facteur limitatif.
Certaines microsolutions datent un peu et pourraient bénéficier d’un réexamen à l’aune du jeu d’instructions actualisé.
III. Contraintes▲
III-A. Échanges▲
Les échanges avec les registres classiques sont dédiés à quelques instructions spécifiques.
Par ailleurs, l’élargissement des données reçues est souvent nécessaire pour pouvoir faire des calculs intermédiaires sans risque de dépassement ou de perte de précision. Or il faut plusieurs instructions (deux en non signé et trois en signé pour le faire).
Les Ă©changes sont donc Ă limiter.
III-B. LinĂ©aritĂ©▲
Comme les instructions SIMD n’influencent pratiquement pas les drapeaux, cela incite à une programmation très linéaire pour limiter des allers-retours SIMD/classique souvent laborieux.
Par exemple, un travail SIMD sur quatre octets mutés en quatre doubles qui aurait besoin de tests et branchements pourrait nécessiter de faire l’opération inverse avant même de tester puis orienter les traitements. Il y a de quoi y réfléchir à deux fois.
III-C. RigiditĂ©▲
Il y a pas mal d’instructions qui utilisent des immédiats (octets imm8) pour les décalages, les répartitions des composantes d’un registre MMX/XMM, etc. Cela signifie, par exemple, que faire des décalages variables en fonction de valeurs variables est impossible (certes, il existe des astuces, mais elles s’avèrent douloureuses en temps ce qui est un comble pour un jeu d’instructions censé améliorer les performances).
Cela commence à évoluer. Par exemple, pblendw permet de choisir, mot par mot, celui à placer dans le résultat, mais il utilise un immédiat (octet imm8) dont chaque bit dicte le choix. Il existe une variante, pblendvw, qui utilise XMM0 comme variable (d’où le v) en lieu et place de l’immédiat fixé à la compilation.
IV. Classes d’instructions▲
IV-A. ArithmĂ©tique▲
La classe arithmétique couvre les calculs classiques comme les additions, soustractions, max, min.
Il n’y a pas de problème avec la division : elle n’existe pas.
IV-A-1. Multiplication▲
La multiplication est un peu particulière : soit on opte pour ne garder que la partie haute (h) du résultat soit la partie basse (l). Si l’intérêt de n’avoir que la partie basse d’une multiplication peut laisser perplexe, la partie haute peut être intéressante :

Correspond au code explicatif :

Il y a aussi une double multiplication suivie d’une addition (pmaddwd) :

Comme les valeurs sont signées, au pire nous avons
(215‑1)*(215‑1) + (215‑1)*(215‑1) = 231‑217 + 2 < 231‑1.
Cela tient dans un mot de 32 bits (double) et prend donc la même place que les couples de mots de 16 bits en entrée.
IV-A-2. Moyennes et valeurs absolues▲
Il y a également des fonctions plus spécifiques, mais qui restent simples comme la moyenne (pavg?) ou la somme des valeurs absolues des différences soit Σ|a-b| (psadbw)
IV-A-3. Tests▲
Un peu plus surprenant, il y a deux tests de comparaison (pcmpeq?, pcmpgt?) qui n’influencent pas les drapeaux (flags), mais retournent, composante par composante, 0x00 ou 0xFF selon que le résultat est faux ou vrai.
Enfin, il y a le très étrange pmovmskb qui place dans un registre classique les bits de poids fort (signe) des composantes octets d’un registre MMX/XMM : bit 0 = bit de poids fort de l’octet 0, bit 1 = bit de poids fort de l’octet 1, bit 2 = bit de poids fort de l’octet…
IV-B. Logiques▲
Les opérateurs logiques ne posent pas de problèmes à l’exception de pandn censé faire un « and not », mais qui fait plutôt un « not and » puisqu’il renvoie ~M1 & M2.
IV-C. Mouvements▲
Il y a bien sûr les opérations de chargement classiques, mais la structure composite des registres SIMD incite à bien d’autres mouvements.
IV-C-1. Mouvements de rĂ©partition des composantes▲
IV-C-1-a. PUNPCK▲
Souvent, nous avons besoin d’élargir le format des données élémentaires pour pouvoir y faire des calculs sans risque de débordement ou de perte de précision. Une commande comme cbw ou cwd serait utile en SIMD, mais elle n’existe qu’à partir de SSE4 : pmovsx?? pour les valeurs signées et pmovzx?? pour les valeurs non signées (remplissage à gauche par des 0). Avant SSE4, nous avons punpck?? qui permet en deux ou trois instructions de faire la même chose.
|
|
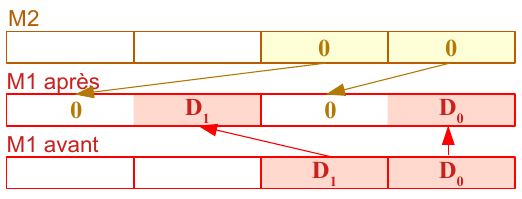
|
Non signé |
Signé |
|
|
|


Il ne faut pas se précipiter sur les instructions, même intéressantes, de SSE4, car ce ne sont pas les mêmes pour Intel et AMD !
IV-C-1-a-i. PACK▲
L’instruction packss?? ou packus?? fait l’opération inverse. Mais aller d’un format plus grand à un plus petit peut s’avérer impossible. Dans ce cas, une saturation est opérée : en dessous du minimum la valeur est fixée au minimum, au-dessus du maximum la valeur est limitée au maximum soit Xs = min(valmax, max(valmin, Xe)).
Une autre opération intéressante est le brassage pshuf?? qui permet de répartir les composantes comme on le souhaite. Un troisième argument (imm8) permet de dire comment ventiler les composantes du 2e argument dans le premier argument. Les deux premiers bits disent où aller chercher la première composante, les deux suivants…
|
|
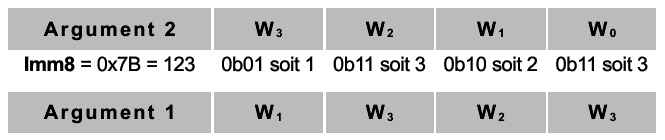
On remarque que rien n’empêche de répéter une affectation ajoutant la duplication au brassage pur. C’est très pratique pour, par exemple, affecter un coefficient commun de multiplication  .
.
Portion principale du code mixant deux couleurs selon un coefficient α = K/256 :

IV-C-1-b. PBLENDW▲
Il y a aussi pblendw déjà entr’aperçu. Si pshuf?? fait un brassage vertical changeant l’ordre, voire dupliquant des composantes, pblendw fait un brassage horizontal selon un troisième argument qui indique quelle composante remplacer par celle équivalente du second argument. Une version, pblendvw, permet de rendre cette action dépendante d’une variable (hébergée en xmm0).
Cette instruction appartient au jeu SSE4 incompatible Intel/AMD.
IV-C-1-c. Mouvements avec les registres gĂ©nĂ©raux▲
Il y a aussi les opérations de base de mouvements des registres généraux vers les registres SIMD et réciproquement. Ce sont toujours les parties basses des registres MMX/XMM qui sont concernées :

Des variantes, pins? et pextr?, permettent de désigner grâce à un troisième argument immédiat (imm8) le numéro de la composante du registre SIMD concerné.
V. Conclusion ?▲
Ce rapide survol avait pour but de montrer la richesse des jeux d’instructions SIMD sans en masquer les contraintes.
Il y a certes un prix à payer pour que ça tourne, mais ça tourne vite. Il y a des techniques complémentaires qui peuvent améliorer encore les performances, mais cela pourrait faire l’objet d’un autre article (une piste : l’exemple de code – si tant est qu’il soit exemplaire – n’est pas facile à lire, car les instructions sont rangées un peu bizarrement. Bizarrement, mais pas tout à fait au hasard  ).
).
La vraie découverte implique, hélas, de se plonger dans les documents d’Intel ou AMD qui ont en commun des volumes monstrueux. De plus cette découverte n’est pas acquise une fois pour toutes. D’une part, de nouvelles fonctions peuvent rendre obsolète un code pourtant bien conçu et, d’autre part, certaines nouvelles implémentations peuvent dégrader les performances d’une instruction ancienne (moins de silicium pour des fonctions peu utilisées ?).
Aussi, commencer par utiliser le mémo pour débuter à coder SIMD retardera, sans la supprimer, cette lecture fastidieuse. Et par la suite, le mémo évitera d’oublier telle ou telle lettre d’un libellé abstrus.
Signaler les erreurs ou omissions sera profitable Ă tous.
V-A. Note de la rĂ©daction▲
Merci Ă Claude Leloup pour sa relecture.