




I. Introduction▲
I-A. Comment utiliser ce manuel▲
Si vous voulez savoir pourquoi j'ai ├®crit GoAsm, conna├«tre les aspects juridiques et les conditions de licence relatives ├Ā ce produit, la suite de cette introduction vous est destin├®e.
Si vous voulez un aper├¦u de certaines des caract├®ristiques de GoAsm, alors cliquez ici.
Si vous d├®butez et que vous voulez apprendre comment faire un programme Windows simple, cliquez ici.
Si vous souhaitez voir quelques exemples de code GoAsm pour plateforme 32 bits, activez les liens suivants┬Ā:
- HelloWorld1.asm┬Ā: programme de console Windows 32 bits (voir ├®galement ici)┬Ā;
- HelloWorld2.asm┬Ā: programme pour Windows GDI 32 bits dessinant une ellipse dans une fen├¬tre┬Ā;
- HelloWorld3.asm┬Ā: version plus ├®labor├®e de HelloWorld2.asm avec usage intensif de trames de pile, de structures, de variables locales, INVOKE et de d├®finitions (macros)┬Ā;
- HelloDialog.asm┬Ā: dialogue utilisant la fonction DialogBoxIndirectParam avec cr├®ation de contr├┤les par mod├©le interne (tables d├®crivant les contr├┤les).
Si vous souhaitez voir quelques exemples de code GoAsm pour plateforme 64 bits, activez les liens suivants┬Ā:
- Hello64World1.asm┬Ā: programme de console Windows 64 bits┬Ā;
- Hello64World2.asm┬Ā: programme Windows 64 bits dessinant une ellipse dans une fen├¬tre┬Ā;
- Hello64World3.asm┬Ā: programme Windows dessinant une ellipse dans une fen├¬tre avec commutation de compilation sur plateforme 32 ou 64 bits.
Les programmes Unicode ainsi que certains aspects de programmation aff├®rents ont ├®t├® int├®gr├®s dans un document s├®par├® qui constitue le volume 2.
Si vous voulez en savoir plus sur les lignes directrices qui structurent GoAsm, alors cliquez ici.
Si vous ├¬tes simplement int├®ress├® par la fa├¦on d'utiliser GoAsm, alors cliquez ici pour acqu├®rir les bases de cet assembleur, ici pour en conna├«tre ses fonctionnalit├®s avanc├®es ou ici pour d├®couvrir les points divers - mais n├®anmoins importants - le concernant.
Cliquez enfin ici si vous d├®sirez tout conna├«tre sur la programmation en 64 bits permise par cet assembleur.
Si vous d├®butez en assembleur
Bienvenue aux joies de la programmation assembleur┬Ā! ├ēcrivez des programmes de travail rapides et compacts. L'assembleur fonctionne tr├©s bien avec Windows. Et, s'il est vrai que nous sommes en pr├®sence d'un langage de bas niveau, il n'en demeure pas moins que l'API Windows (Applications Programming Interface) lui adjoint des fonctionnalit├®s de tr├©s haut niveau. Les deux sont parfaitement compatibles aussi bien en 64 bits qu'en 32 bits. Ce document vous aidera ├Ā appr├®hender la programmation en assembleur. Consultez plus particuli├©rement, dans votre parcours initiatique, le chapitre III et les annexes. On lira enfin avec le plus grand int├®r├¬t les tutoriels qui n'auraient pas fait l'objet de traduction et qui figurent sur le site http://www.godevtool.com/.
I-B. En quoi un nouvel assembleur est-il n├®cessaire┬Ā?▲
Il existe un certain nombre d'assembleurs sur le march├® tels que le tr├©s populaire MASM de Microsoft, NASM (issu d'une ├®quipe dirig├®e ├Ā l'origine par Simon Tatham et Julian Hall), TASM de Borland et enfin, A386 de Eric Isaacson. De mon point de vue, aucun de ces assembleurs ne peut ├¬tre consid├®r├® comme parfait dans le cadre de la programmation Windows. Certains ont m├¬me des d├®fauts g├¬nants. En ├®crivant GoAsm, je me suis efforc├® de construire un assembleur qui produise toujours un code de taille minimale avec une syntaxe claire et ├®vidente, qui n'impose que de faibles exigences au niveau du script source et propose des extensions pour aider ├Ā la programmation en Win32 et Win64. Cela m'a ├®galement donn├® l'occasion d'├®crire l'├®diteur de liens GoLink, qui est finement r├®gl├® pour travailler avec GoAsm.
D'autres que moi ont ├®galement essay├® d'engager une d├®marche similaire, notamment Ren├® Tournois, qui a ├®crit le fabricant d'ex├®cutables Spasm (maintenant appel├® RosAsm), et Tomasz Grysztar avec son assembleur flat (FASM).
I-C. Versions et mises ├Ā jour▲
Mon intention est de pr├®server GoAsm de tout bogue connu. Donc, je travaille habituellement sur des corrections de bogues d├©s que je les d├®couvre (├Ā moins d'├¬tre en vacances). Je produis g├®n├®ralement un correctif ├Ā destination de ceux qui signalent des bogues en leur envoyant (ou en postant) une copie de GoAsm avec un num├®ro de version affect├® d'une lettre suffixe. Les bogues relativement mineurs sont g├®n├®ralement trait├®s de cette fa├¦on et puis donnent finalement lieu ├Ā la publication d'une mise ├Ā jour formelle. Ces mises ├Ā jour peuvent ├¬tre obtenues ├Ā partir de mon site Web ├Ā l'adresse http://www.godevtool.com/. Un bogue grave peut entra├«ner la publication imm├®diate d'une mise ├Ā jour de GoAsm. Je travaille ├®galement ├Ā son am├®lioration de temps en temps┬Ā: cela se traduit par la mise ├Ā disposition d'une version b├¬ta de GoAsm qui est disponible pour tests. Ces versions d'essai sont souvent ├®galement disponibles ├Ā partir de mon site web. C'est n'est seulement qu'├Ā l'issue de ces tests et des ├®ventuelles modifications induites que les versions b├¬ta se transforment en mise ├Ā jour officielle.
I-D. Forum de discussion▲
Il existe un forum consacr├® ├Ā l'assembleur GoAsm et ses outils ├Ā l'int├®rieur du forum MASM g├®r├® par Hutch. Vous pouvez y exprimer vos id├®es sur les outils ┬½┬ĀGo┬Ā┬╗, me poser des questions ou faire de m├¬me avec d'autres utilisateurs et v├®rifier les mises ├Ā jour. Le forum est aussi l'occasion pour moi de vous consulter sur les am├®liorations ├Ā apporter ├Ā GoAsm et aux autres outils ┬½┬ĀGo┬Ā┬╗.
I-E. Environnements de D├®veloppement Int├®gr├® (IDE)▲
Les IDE sont des ├®diteurs qui vous aident ├Ā utiliser la syntaxe de programmation correcte, puis ├Ā ex├®cuter les outils de d├®veloppement en vue de cr├®er les fichiers de sortie. En voici quelques-uns┬Ā:
- Easy Code pour GoAsm┬Ā: excellent IDE de Visual Assembler ├®crit par Ramon Sala.
T├®l├®chargez ECGo.zip sur le site http://www.godevtool.com/ - incluant par ailleurs les versions les plus r├®centes des outils ┬½┬ĀGo┬Ā┬╗ et des fichiers d'inclusion pour l'utilisation de Easy Code - 792K.
Les tutoriels de Bill Aitken pour l'utilisation de GoAsm et de l'IDE.
- RadAsm┬Ā: excellent IDE de Visual Assembler pour Windows con├¦u par Ketil Olsen.
Vous pouvez aller sur Donkey's stable pour Radasm, les fichiers d'inclusion, les macros, des exemples et projets GoAsm.
- NaGoa┬Ā: Visual Assembler (utilisant GoRC seulement).
I-F. Aspects juridiques▲
I-F-1. Copyright▲
GoAsm est couvert par le Copyright ┬® Jeremy Gordon 2001-2016 [MrDuck Software] - all rights reserved.
I-F-2. GoAsm - licence et distribution▲
Vous pouvez utiliser GoAsm ├Ā toutes fins, y compris des programmes commerciaux. Vous pouvez le redistribuer librement (mais sans contrepartie financi├©re, ni l'utilisation avec un programme ou tout autre mat├®riau pour lequel l'utilisateur est invit├® ├Ā payer). Vous n'├¬tes pas habilit├® ├Ā masquer ou ├Ā contester mes droits d'auteur.
I-F-3. Avertissement▲
J'ai fait tous les efforts possibles pour faire en sorte que GoAsm et son programme d'accompagnement AdaptAsm soient au point, mais vous les utilisez enti├©rement ├Ā vos risques. Je ne peux accepter la moindre responsabilit├® concernant leur fonctionnement, le travail produit, ni les cons├®quences d'erreurs entachant ├®ventuellement ce manuel.
I-G. Remerciements▲
Je dois des remerciements particuliers ├Ā Wayne J. Radburn, de Gatineau, au Qu├®bec, qui a entrepris et conduit avec succ├©s tout r├®cemment un ensemble d'am├®liorations et de corrections de bogues dans les versions les plus r├®centes de GoAsm (0,57 ├Ā 0,61). Je voudrais ├®galement remercier Edgar Hansen de Kelowna, en Colombie-Britannique, Canada (┬½┬ĀDonkey┬Ā┬╗) pour son soutien continu et ses encouragements ├Ā Wayne et moi-m├¬me et, d'une mani├©re g├®n├®rale, remercier tous les utilisateurs de GoAsm. Nous sommes trois, d├®sormais, ├Ā d├®tenir le code source de GoAsm et de GoLink, et cela contribuera ├Ā garantir l'avenir du projet ┬½┬ĀGo┬Ā┬╗. Je suis ├®galement tr├©s reconnaissant ├Ā toutes ces autres personnes qui m'ont encourag├® ├Ā ├®crire ces programmes et m'ont ├®clair├® par d'utiles commentaires, des rapports et des conseils avis├®s. Je me dois de citer, en particulier┬Ā:
Leland M. George de West Virginia, Daniel Fazekas de Budapest, Greg Heller du Congo (┬½┬ĀBushpilot┬Ā┬╗), Ren├® Tournois de Louisville, Meuse, France (┬½┬ĀBetov┬Ā┬╗), Ramon Sala de Barcelone, Espagne, Bryant Keller de Cartersville, G├®orgie, Emmanuel Zacharakis (Manos), et Brian Warburton de Weybridge, au Royaume-Uni.
Merci aussi pour le soutien, les suggestions et les rapports de bogues de grv, Jeff Aguilon, Jonne Ahner, Thomas Hartinger, Martyn Joyce, Kaz├│ Csaba, Dmitry Ilyin, Patrick Ruiz, et de tous les contributeurs du forum GoAsm et outils associ├®s, ainsi que d'autres forums que j'aurais omis de mentionner ici.
II. Les concepts de GoAsm▲
II-A. Les caract├®ristiques de GoAsm en bref▲
- GoAsm est un assembleur 32 bits pour les processeurs 86 et Pentium et un assembleur 64 bits pour les processeurs AMD64 et EM64T.
- GoAsm produit un fichier objet dans le format Portable Executable COFF appropri├® pour un ├®diteur de liens tel que GoLink ou ALINK. Le format COFF est de loin sup├®rieur ├Ā l'OMF (Module Object Format) produit par certains assembleurs plus anciens parce que, dans le format OMF, la taille des fichiers objet est limit├®e ├Ā environ 55K. Dans tout projet d'envergure, vous vous situez au-del├Ā de cette limite.
- GoAsm fonctionne seulement en mode flat. Cela signifie qu'il n'y a pas de segmentation du code et des donn├®es. Cela rend le script source beaucoup plus propre et plus facile ├Ā ├®crire. Fondamentalement, dans GoAsm, vous pouvez d├®clarer la section, puis commencer ├Ā coder. En programmation 32 bits, vous pouvez utiliser les registres 32 bits pour y entreposer et manipuler des donn├®es (EAX, EBX, ECX, EDX, ESI, EDI, EBP, ESP) et aussi leurs subdivisions 8 bits et 16 bits (AL, AH, BL, BH, CL, CH, DL, DH et AX, BX, CX, DX, SI, DI, BP et SP). Vous pouvez adresser des donn├®es de toute taille dans la m├®moire, mais, dans la mesure o├╣ GoAsm fonctionne uniquement en mode flat vous ne pouvez utiliser que des adresses 32 bits pour ce faire. Il en r├®sulte que vous ne pouvez pas utiliser, par exemple, des instructions telles que ADC W [BX], 6 ou MOV AX, [SI] pour traiter des donn├®es en m├®moire┬Ā; vous devez imp├®rativement leur pr├®f├®rer ADC W [EBX], 6 ou MOV AX, [ESI].
- GoAsm a un certain nombre de fonctionnalit├®s pour vous aider ├Ā ├®crire des programmes Unicode ou pour utiliser le m├¬me script source pour des programmes Unicode et ANSI. GoAsm peut lire les fichiers Unicode (UTF-16 ou format UTF-8) et peut recevoir ses commandes et produire sa sortie en Unicode. Voir le support Unicode pour un aper├¦u et l'├®criture de programmes Unicode pour plus de d├®tails.
- GoAsm fonctionne ├®galement comme assembleur 64 bits. Bien que le code ex├®cutable en 64 bits soit tout ├Ā fait diff├®rent, le code source est tr├©s similaire et se r├®v├©le tout aussi facile ├Ā ├®crire. Vous pouvez m├¬me, ├Ā partir d'un m├¬me code source, produire des ex├®cutables en 32 ou 64 bits ├Ā l'aide d'un commutateur appropri├®. Voir le chapitre 6 relatif ├Ā l'├®criture de programmes 64 bits pour plus de d├®tails.
- GoAsm prend en charge tous les mn├®moniques standard (autres que ceux utilis├®s uniquement pour la programmation 16 bits), les instructions en virgule flottante x87, MMX, 3DNow! (avec les extensions), les instructions SSE, SSE2, SSE3 et SSSE4, ainsi que AES (cryptage selon l'algorithme de Rijndael), ADX, et quelques autres instructions nouvelles diverses. Voir ├Ā ce sujet mn├®moniques pris en charge et syntaxe des registres FPU, MMX et XMM.
- J'ai essay├® de prendre le meilleur de la syntaxe des assembleurs utilis├®e en g├®n├®ral et du C, de mon point de vue. Voir la section syntaxe et compatibilit├® avec d'autres assembleurs pour plus de d├®tails.
- Plus de flexibilit├® et de simplicit├® sont obtenues en renon├¦ant au contr├┤le du type de variable ou des param├©tres d'API. Voir mon explication pour cette d├®cision.
- Tous les labels (sauf ceux r├®utilisables) sont suppos├®s ├¬tre global et public, en ce sens qu'ils sont accessibles ├Ā d'autres fichiers source (via l'├®diteur de liens). Ceci est tr├©s simplement r├®alis├® en utilisant un flag dans le fichier objet et ├®vite la n├®cessit├® de d├®clarer de tel ou tel label en GLOBAL et PUBLIC. D'o├╣ une grande ├®conomie de temps et d'effort au b├®n├®fice du programmeur┬Ā! (Les labels r├®utilisables dans le cadre des sauts de code courts sont trait├®s diff├®remment).
- Pour des raisons de certitude et de clart├® dans votre script, les crochets sont obligatoires pour l'├®criture et la lecture de m├®moire. Voir mon explication de ce choix.
- GoAsm fournit un moyen tr├©s simple de mettre en pile (PUSH) le pointeur d'une cha├«ne termin├®e par un z├®ro pour les appels d'API. Vous pouvez ├®galement pousser en pile le pointeur vers des donn├®es brutes ordinaires. Voir plus d'informations ├Ā ce sujet.
- Vous pouvez ├®galement charger les pointeurs cha├«nes termin├®es par 0 et des pointeurs vers les donn├®es brutes dans les registres de la m├¬me mani├©re. Par exemple MOV EAX, ADDR 'Bonjour'. Voir le paragraphe IV.K sur ce point.
- Contrairement ├Ā MASM, GoAsm ne renverse pas l'ordre de m├®morisation des caract├©res de valeurs imm├®diates. Par exemple, la saisie de MOV EAX, 'The ' ├Ā destination de GoAsm doit s'├®crire MOV EAX, ' ehT' avec MASM. La premi├©re syntaxe offre une bien meilleure lisibilit├® du code source. Elle est ├®galement plus coh├®rente avec les cha├«nes de caract├©res d'octets encadr├®es de guillemets, qui sont toujours charg├®es caract├©re par caract├©re. En th├®orie, il est discutable qu'un assembleur inverse l'ordre de m├®morisation. La raison en est que le processeur, du fait de sa structure, inverse l'ordre des octets charg├®s dans un registre lorsque ceux-ci proviennent de la m├®moire, cette inversion se produisant naturellement dans le sens registre vers m├®moire. On voit bien que ces deux inversions s'annulent dans les faits, d'o├╣ l'id├®e qu'il serait imprudent que l'assembleur ne casse cette logique au d├®triment de la lisibilit├® du code source. NASM avait pris le contrepied sur cette question et GoAsm s'est ralli├® ├Ā ce choix. Penchez-vous sur cette pratique respectivement pour le code et pour les donn├®es. Voir aussi le m├®canisme de m├®morisation invers├®e.
- GoAsm offre un syst├©me flexible et pratique en mati├©re de labels de code. Je crois que cela est extr├¬mement important. GoAsm offre trois possibilit├®s┬Ā: des labels uniques (┬½┬Āglobaux┬Ā┬╗), labels r├®utilisables de port├®e locale ainsi que des labels r├®utilisables de port├®e non limit├®e.
- ├Ć ce syst├©me de label de GoAsm, s'ajoute un syst├©me de notation tr├©s explicite pour les sauts de code courts et longs.
- Les appels de type ┬½┬ĀC┬Ā┬╗ sont disponibles en utilisant INVOKE.
- GoAsm vous permet d'appeler une fonction dans une biblioth├©que de code statique et d'en charger le code et les donn├®es directement dans le fichier de sortie au moment de l'assemblage.
- GoAsm et le linker GoLink sont les seuls fournissant le moyen d'appeler une fonction dans un autre ex├®cutable directement par ordinal, en utilisant une syntaxe simple telle que, par exemple┬Ā: CALL MyDll:6. Et vous pouvez importer des pointeurs de donn├®es sans aucune formalit├®.
- GoAsm vous permet de sp├®cifier les EXPORTS dans votre fichier source. Vous pouvez utiliser le nom seulement, sp├®cifiez une valeur ordinale, et vous assurer qu'aucun nom n'appara├«t dans l'ex├®cutable final si vous le souhaitez.
- Lors de l'├®dition des liens des fichiers objet GoAsm, GoLink est en mesure d'identifier les labels de code et de donn├®e qui n'auraient pas ├®t├® utilis├®s ou r├®f├®renc├®s. En utilisant cette fonctionnalit├®, vous pouvez facilement rep├®rer ces d├®clarations de donn├®es et zones de code redondants dans votre programme.
- Les instructions PUSH, POP, ARG, INC et DEC peuvent respectivement ├¬tre r├®p├®t├®es sur plusieurs op├®randes successifs en s├®parant ces derniers par des virgules.
- L'utilisation de FLAGS comme op├®rande de PUSH, POP et ARG, et INVOKE et USES.
- Sauvegarde et restauration automatiques des registres et des flags ├Ā l'aide de l'instruction USES.
- Pour simplifier les proc├®dures de callback de Windows, GoAsm fournit une structure automatis├®e de trame de pile utilisant FRAME ŌĆ” ENDF. Des sous-routines peuvent partager les donn├®es stock├®es sur la pile en utilisant USEDATA ŌĆ” ENDU. Les donn├®es locales peuvent ├¬tre d├®clar├®es dynamiquement sur une base de message sp├®cifique.
- Simplification de la forme de l'indicateur de type. Par exemple, D au lieu de DWORD PTR.
- GoAsm fournit un support complet pour les structures et unions. Les membres de structures d'unions sont trait├®s comme des labels de plein droit afin qu'ils puissent ├¬tre trait├®s en utilisant un point et apparaissent comme des symboles de d├®bogage.
- GoAsm fournit ├®galement un support complet pour les equates, les macros et les d├®finitions y compris les d├®finitions de port├®e limit├®e.
- GoAsm fournit un support complet pour les inclusions de fichiers (include), et vous pouvez ├®galement charger un fichier directement dans une section GoAsm en utilisant INCBIN.
- Au lieu d'utiliser INCBIN vous pouvez charger des blocs de donn├®es d├®clar├®s dans le fichier source lui-m├¬me en utilisant DATABLOCK.
- GoAsm est sensible ├Ā la casse des caract├©res (majuscules/minuscules) dans le cas des noms de labels et des noms de d├®finition. Cette fonctionnalit├® n'est pas escamotable car, permettre l'utilisation de labels de casse mixte peut induire de la confusion. Dans toutes les autres situations GoAsm n'est pas sensible ├Ā la casse. Par exemple, vous pouvez ├®crire indiff├®remment MOV [ESI], EAX, #INCLUDE, #IF, #DEFINE, STRUCT, DB, ou mov [ESI], eax, #include, #if, #define, struct, db.
- GoAsm ne supporte pas les commandes de run-time ┬½┬Āif┬Ā┬╗. MASM vous permet de tester les conditions et/ou des instructions de r├®p├®tition dans une boucle utilisant les commandes .IF / .ELSE / .ELSEIF / .ENDIF et .WHILE / .BREAK. Celles-ci testent les conditions ├Ā l'ex├®cution. L'assembleur A386 offre la forme #IF pour cette commande, laquelle teste les flags au moment de l'ex├®cution. Cependant, dans MASM, les s├®ries de commandes IF / ELSE / ELSEIF / ENDIF / IFDEF sont utilis├®es au moment du processus d'assemblage pour structurer le code objet en fonction des param├©tres test├®s. A386 utilise la forme #IF pour ce faire, tandis que NASM lui pr├®f├©re %IF. La syntaxe ┬½┬ĀC┬Ā┬╗ est #IF pour les tests de compilation. Pour ma part, ayant utilis├® toutes ces syntaxes pour les tests d'ex├®cution qui sont si semblables ├Ā la syntaxe ├®tablie tout en signifiant quelque chose de compl├©tement diff├®rent, j'affirme que c'est une excellente recette pour un d├®sastre assur├®. Pour le moment, j'ai d├®cid├® de ne pas soutenir toute forme de tests d'ex├®cution ou en boucle. Je suis pr├¬t ├Ā reconsid├®rer cette d├®cision radicale si quelqu'un peut sugg├®rer une syntaxe appropri├®e. Pour le moment les utilisateurs GoAsm devront donc se contenter des classiques CMP, TEST, LOOP et autres mn├®moniques de saut conditionnel. Pour autant, GoAsm soutient pleinement l'assemblage conditionnel au moment de la compilation utilisant les commandes de type ┬½┬ĀC┬Ā┬╗ #if / #else / #elseif / # endif, etc.
- GoAsm n'impose pas que l'adresse de d├®part de votre programme soit un nom r├®serv├® comme dans l'assembleur A386, bien que cette possibilit├® soit n├®anmoins offerte avec le mot r├®serv├® START. De plus, vous ne devez pas d├®finir un label puis la directive END pour d├®finir le point d'entr├®e (comme dans MASM). Avec GoAsm vous utilisez tout simplement un label et indiquez ├Ā l'├®diteur de liens ce qu'est ce label. Ou, si vous utilisez GoLink, START est pr├®sum├® en l'absence d'indication contraire. Consulter ├®galement sur ce point la section relative ├Ā l'utilisation de GoAsm avec diff├®rents linkers.
- Vous pouvez essayer GoAsm sur vos scripts source existants. Pour vous soulager de quelques travaux fastidieux pour adapter ces fichiers initialement destin├®s ├Ā d'autres assembleurs, j'ai ├®crit le programme AdaptAsm.exe, qui effectue ce travail pour vous (sans ├®craser, pour autant, le fichier d'origine┬Ā!).
- Et si vous d├®sirez conna├«tre pr├®cis├®ment la rapidit├® d'ex├®cution de GoAsm lors de l'assemblage de vos fichiers ou de parties d'entre eux, vous disposez pour cela de la directive GOASM_REPORTTIME.
II-B. Syntaxe et compatibilit├® avec d'autres assembleurs▲
La syntaxe acceptable pour l'assembleur est d'une importance capitale pour tout programmeur en assembleur. Elle varie selon les assembleurs. GoAsm ne cr├®e pas de code 16 bits et fonctionne uniquement en mode ┬½┬Āflat┬Ā┬╗ (absence de segments). Pour cette raison, sa syntaxe est tr├©s simple. J'ai choisi ce que je consid├©re ├¬tre la meilleure syntaxe avec, pour principal objectif, la clart├® et la coh├®rence. Vous pouvez ├¬tre en d├®saccord avec moi sur ce point. Si oui, je serais int├®ress├® par vos points de vue.
Lors de l'├®criture initiale de GoAsm, j'ai r├®fl├®chi ├Ā la possibilit├® de construire une syntaxe enti├©rement compatible avec celle d'autres assembleurs, mais j'ai d├╗ rapidement y renoncer en raison d'├®carts trop importants susceptibles de se traduire par d'importantes incoh├®rences. J'ai ├®galement renonc├® ├Ā rendre GoAsm enti├©rement compatible avec un quelconque autre assembleur.
Vous reconna├«trez la syntaxe d'autres assembleurs. Lorsque cela ├®tait possible, j'ai essay├® de rester proche de ce que je consid├©re ├¬tre la meilleure syntaxe de l'assembleur d'usage g├®n├®ral. Vous reconna├«trez ├®galement certaines syntaxes emprunt├®es ├Ā la programmation en C. J'ai suivi principalement la syntaxe ┬½┬ĀC pr├®processeur┬Ā┬╗ lorsqu'il me semblait inutile de proc├®der autrement. Cela rend ├®galement l'utilisation du pr├®processeur commandes de GoAsm totalement compatible avec mon compilateur de ressources GoRC.
II-C. Pourquoi GoAsm ne v├®rifie pas les types et param├©tres▲
Apr├©s r├®flexion, j'ai d├®cid├® que GoAsm ne devait pas v├®rifier les types ou les param├©tres. Ceci, dans le but de r├®duire substantiellement la taille du script source et d'ajouter ├Ā sa flexibilit├® et ├Ā sa lisibilit├®. Je conclus que m├¬me v├®rifier sommairement le type dans la programmation assembleur pour Windows n'est pas du tout essentiel, et g├®n├©re plus d'inconv├®nients que d'avantages.
Permettez-moi de m'en expliquer ici.
Dans la v├®rification de type, l'assembleur doit s'assurer que les r├®f├®rences aux zones de m├®moire sont faites avec la bonne taille et le bon type de donn├®es en fonction de l'usage qui doit ├¬tre fait de ces zones de m├®moire. Ce r├®sultat est obtenu gr├óce ├Ā un processus en deux ├®tapes. Premi├©rement, lorsque la zone de m├®moire est d├®clar├®e, le programmeur doit lui allouer un certain ┬½┬Ātype┬Ā┬╗. Ensuite, lorsque la zone de m├®moire est utilis├®e, le programmeur a encore pour t├óche d'indiquer le type de la m├®moire appel├®e ├Ā ├¬tre utilis├®e. S'il y a discordance, l'assembleur ou le compilateur afficheront une erreur.t
Certains assembleurs, comme NASM, ne font aucune v├®rification de type. D'autres, comme A386, ne font que des v├®rifications sommaires sur les types BYTE, WORD, DWORD, QWORD et TWORD. MASM et TASM, comme C, vous permettent de sp├®cifier vos propres types en utilisant TYPEDEF puis en assurent la v├®rification.
La v├®rification de param├©tre s'assure que le nombre correct de param├©tres est pass├® ├Ā une API et en contr├┤le individuellement le type. La plupart des assembleurs ne v├®rifient pas les param├©tres, mais MASM permet de le faire si le pseudomn├®monique INVOKE est utilis├®.
Les requis pour parvenir ├Ā une v├®rification parfaite de type et de param├©tre correspondant au niveau du compilateur C sont ├®normes. Il suffit de regarder l'en-t├¬te d'un programme Windows et de voir les longues listes de diff├®rents types allou├®s aux diff├®rentes structures et les param├©tres d'API. Sans compter ├®videmment les efforts du programmeur qui sont n├®cessaires dans le script source pour veiller ├Ā ce qu'aucune erreur ne soit renvoy├®e par l'assembleur ou le compilateur.
Pour toutes ces raisons, j'ai d├®cid├® de suivre l'exemple de NASM sans m├¬me proposer la v├®rification ├®l├®mentaire de type impl├®ment├®e dans A386. J'ai utilis├® ce dernier de nombreuses ann├®es et j'ai appr├®ci├® sa syntaxe propre, mais j'ai plut├┤t ressenti sa v├®rification sommaire de type comme un obstacle lors de la programmation sous Windows. Ceci, parce que l'on est souvent confront├® ├Ā des situations o├╣ il est n├®cessaire d'├®crire ou de lire des donn├®es en utilisant une taille diff├®rente de celle utilis├®e pour les d├®clarer en premier lieu.
J'ai ├®galement renonc├® au contr├┤le de param├©tre, estimant qu'il complique inutilement les choses. Il exige d'├®normes listes d'API et des param├©tres qui doivent ├¬tre fournis ├Ā l'assembleur ou au compilateur afin qu'ils puissent v├®rifier que ceux-ci correspondent aux besoins de l'API. Oubliez-en ne serait-ce qu'un seul et votre programme ne compile pas. Consid├®rons l'exemple suivant┬Ā:
PUSH 40h, EDX, EAX, [hwnd]
CALL MessageBoxAVoici un appel d'API qui met en ┼ōuvre quatre param├©tres. Vous seriez tent├® d'attendre de l'assembleur qu'il en contr├┤le le nombre et qu'il vous alerte en cas d'erreur de votre part sur ce point. Mais vous n'avez pas besoin de cet avertissement car votre programme sera tout simplement plant├® si tel est le cas. Alors, pourquoi effectuer un tel test dans la mesure o├╣ il n'y a rien de sournois ici, en tout cas rien qui ne puisse ├¬tre appr├®hend├® au stade de l'exp├®rimentation┬Ā? Au-del├Ā du nombre de param├©tres on peut ├®galement s'interroger sur la n├®cessit├® de tester le type de chacun d'eux. En effet, quel est l'int├®r├¬t d'un tel contr├┤le dans la mesure o├╣ tous les param├©tres ├Ā destination des API sont de type DWord (avec une ou deux exceptions sur des milliers)┬Ā? Donc, le risque de taille erron├®e des donn├®es ├Ā destination d'une API est quasiment nul.
Je conviens qu'il peut ├¬tre possible d'envoyer le mauvais type de donn├®es ├Ā une API. Par exemple, vous pourriez envoyer une constante l├Ā o├╣ il devrait y avoir un handle ou le contenu d'une adresse m├®moire en lieu et place d'un pointeur vers une adresse m├®moire. Cependant, l'API ne fonctionnera tout simplement pas dans ce cas - et, encore une fois, il n'y a rien qui ne puisse ├¬tre remarqu├® au stade de l'exp├®rimentation.
L'abolition du contr├┤le de param├©tres et de type ne lib├©re pas seulement l'assembleur de beaucoup de travail, le rendant plus rapide en fonctionnement┬Ā; elle ├®pargne aussi au programmeur les interrogations qui accompagnent in├®vitablement la manipulation d'en-t├¬te et d'inclusion de fichiers. Enfin, elle garantit une plus grande fluidit├® dans l'adressage m├®moire, car les notifications d'erreur vous seront ├®pargn├®es si, d'aventure, vous voulez utiliser des donn├®es selon une taille qui ne correspond pas ├Ā celle qui a ├®t├® pr├®alablement d├®clar├®e. Donc, en GoAsm m├¬me si lParam a ├®t├® d├®clar├®e comme une valeur DWord,
MOV [lParam], ALest encore permis. Et si LOGFONT est une structure simple de DWords, GoAsm se satisfait pleinement, par exemple, de
MOV B[LOGFONT+14h], 1que vous pouvez utiliser pour d├®finir une police en italique.
En m'exemptant du contr├┤le de type et de param├©tres, j'ai ├®t├® en mesure d'abolir ├®galement EXTRN. GoAsm n'a pas besoin de conna├«tre le type de symboles qui sont d├®clar├®s en dehors du fichier source (c'est-├Ā-dire d├®couverts pendant la phase d'├®dition de liens). J'esp├©re que vous conviendrez que cela vous ├®pargnera beaucoup de travail acharn├® et l'angoisse d'avoir ├Ā ajouter ces EXTRN dans les programmes li├®s.
La contrepartie de la suppression du contr├┤le du type et des param├©tres est que vous devez indiquer ├Ā GoAsm la taille des donn├®es ├Ā exploiter, dans les cas o├╣ celle-ci n'est pas implicite.
Par exemple, MOV [MemThing], 23h est-il incorrect. Pour charger 23h en tant qu'octet en MemThing vous devez coder MOV B[MemThing], 23h (├®quivalent ├Ā MOV Byte Ptr [MemThing], 23h avec MASM). Ceci est parce GoAsm ne saura pas au moment de l'assemblage si la valeur 23h doit ├¬tre charg├®e en tant qu'octet, mot ou DWord, formats qui sont tous accept├®s par l'instruction MOV.
├Ć certains ├®gards, l'exigence d'un indicateur de type (lorsque celui-ci n'est pas ├®vident) est utile. Ceci, ne serait-ce que parce que vous pouvez voir imm├®diatement sur le libell├® de l'instruction elle-m├¬me la taille de m├®moire affect├®e par son action. Vous n'avez pas ├Ā vous reporter ├Ā une d├®claration de donn├®es ant├®rieure pour rechercher son type pour d├®terminer ce que l'instruction fera. Par exemple┬Ā:
MOV B[MemByte], 23h ; r├®confortant de voir que cela se limite ├Ā une op├®ration sur un octet
FLD Q[NUMBER] ; utile de savoir que c'est nombre r├®el Qword charg├® en double pr├®cision
INC B[COUNT] ; essentiel de savoir que ce comptage est limit├® ├Ā 256Un autre avantage d├®coulant de l'absence de v├®rification de tout param├©tre est qu'il n'y a pas besoin que GoAsm mette en relief les noms des appels vers d'autres modules ou ceux destin├®s ├Ā l'importation. Lors de l'utilisation GoLink, c'est un avantage consid├®rable puisqu'il n'y a pas besoin de fichiers LIB ├Ā l'├®tape d'├®dition de liens. Mais cela signifie aussi que les fichiers objet GoAsm seront diff├®rents de ceux fabriqu├®s par un compilateur C ou MASM, parce que ces fichiers contiennent des symboles qui seront mis en relief tandis que GoAsm ne fera pas rien de tel. Depuis sa version 0.26.10, GoLink est cependant en mesure d'accepter des fichiers objet des deux ensembles d'outils pr├®cit├®s et de les lier aux fichiers objet GoAsm (il suffit d'utiliser le commutateur de GoLink /mix - voir l'aide de GoLink).
II-D. Pourquoi GoAsm utilise les crochets pour l'├®criture et la lecture de la m├®moire▲
Les programmeurs en assembleur ont longtemps d├®battu sur l'usage de crochets dans le libell├® de l'adressage m├®moire. L'argument dominant est que, puisque vous devez utiliser des crochets lorsque l'adresse est contenue dans un registre - par exemple MOV EAX, [EBX] -, alors vous devez ├®galement utiliser des crochets lorsque l'adresse est mat├®rialis├®e par un label - par exemple MOV EAX, [lParam]. ├ēvidemment, j'ai suivi ce d├®bat avec int├®r├¬t. MASM et A386 se sont abstenus de trancher, de sorte que les deux instructions qui suivent font exactement la m├¬me chose┬Ā:
MOV EAX, lParam
MOV EAX, [lParam]Cependant, A386 diff├®rencie les labels suivis ou non de deux points d'o├╣ il r├®sulte que la remarque qui pr├®c├©de est vraie si lParam a ├®t├® d├®clar├® par┬Ā:
lParam DD 0et fausse si lParam a ├®t├® d├®clar├® par┬Ā:
lParam: DD 0Dans ce dernier cas, MOV EAX, lParam, toujours selon l'assembleur A386, agirait ├Ā l'identique de MOV EAX, OFFSET lParam. Tr├©s d├®routant┬Ā!
NASM a fait le grand saut en en faisant une condition pour tout adressage m├®moire libell├® entre crochets. Toutefois, preuve que le d├®bat reste ind├®termin├®, MOV EAX, lParam y demeure permis. Dans cet assembleur, cette formulation ├®quivaut au MOV EAX, OFFSET lParam utilis├® par d'autres assembleurs.
Donc, quand on regarde le code assembleur, sans conna├«tre la syntaxe de l'assembleur concern├®, on ne peut jamais ├¬tre vraiment s├╗r de ce que MOV EAX, lParam fait. La m├¬me instruction peut faire deux choses totalement diff├®rentes selon l'assembleur utilis├®.
Le TASM de Borland, lorsqu'il passe en mode ┬½┬ĀId├®al┬Ā┬╗, proscrit compl├©tement MOV EAX, lParam et permet seulement┬Ā:
MOV EAX, [lParam]ou
MOV EAX, OFFSET lParamJ'approuve cette approche. L'objectif principal, ici, est de s'assurer que le codage est sans ambigu├»t├®. Pour cette raison, j'ai d├®cid├® que GoAsm devait ├¬tre strict sur cette question. Par cons├®quent, dans GoAsm┬Ā:
MOV EBX, wParamest compl├©tement interdit, ├Ā moins que wParam ne soit un mot d├®fini. Afin d'obtenir l'offset dans GoAsm, vous devez utiliser┬Ā:
MOV EBX, ADDR wParamou, si vous pr├®f├®rez┬Ā:
MOV EBX, OFFSET wParamqui signifie la même chose.
Si vous souhaitez adresser la m├®moire dans GoAsm, vous devez donc utiliser la syntaxe
MOV EBX, [wParam]II-E. Mn├®moniques support├®s par GoAsm▲
II-E-1. Qu'est-ce qu'un ┬½┬Āmn├®monique┬Ā┬╗┬Ā?▲
Un mn├®monique est une instruction sous forme de texte que vous utilisez dans votre script source assembleur. GoAsm assemble ces mn├®moniques et les convertit en codes op├®ration (opcodes) que le processeur ex├®cute. Ces codes op├®ration sont parfois appel├®s codes machine. Les mn├®moniques sont recommand├®s par les fabricants de processeurs. Ils sont destin├®s ├Ā transmettre sous forme abr├®g├®e et aussi pr├®cis├®ment que possible ce que l'instruction fait. Bien qu'il existe maintenant plus de 550 mn├®moniques, un programmeur en assembleur n'en utilise seulement que 20 ou 30 r├®guli├©rement. Voir une proposition de liste des mn├®moniques les plus couramment utilis├®s dans l'annexe consacr├®e aux d├®butants en assembleur.
Pour des raisons de portabilit├® des scripts source et de coh├®rence en pr├®vision d'├®ventuelles mises ├Ā jour, tous les assembleurs reconnaissent normalement les mn├®moniques au niveau o├╣ ils se rejoignent dans la fonction d'assemblage. Pour autant, le processeur ignore les mn├®moniques et ne fonctionne que dans le code de la machine lui-m├¬me. Les programmeurs non familiers de l'assembleur n'utilisent jamais les mn├®moniques. Un compilateur travaillant uniquement en ┬½┬ĀC┬Ā┬╗, par exemple, produit encore du code machine, mais il ne fonctionne pas avec les mn├®moniques en tant que tels (sauf bascul├® en mode assembleur en ligne).
II-E-2. Quels mn├®moniques sont pris en charge par GoAsm┬Ā?▲
GoAsm prend en charge tous les mn├®moniques correspondant aux instructions ├Ā usage g├®n├®ral, y compris les instructions x87 en virgule flottante, les instructions MMX, 3DNow! (avec les extensions), SSE, SSE2, SSE3 et SSSE4, ainsi que AES, ADX, et quelques autres nouvelles instructions. GoAsm prend en charge les instructions pseudo CMP qui peuvent ├¬tre utilis├®es avec les registres XMM.
GoAsm ne supporte pas certains mn├®moniques qui sont utilis├®s uniquement pour la programmation 16 bits. C'est le cas de IBTS, IRETW, JCXZ, RETF et XBTS.
Enfin, GoAsm ne supporte pas les mn├®moniques qui n├®cessitent des op├®randes suppl├®mentaires, et les cas o├╣ il existe des mn├®moniques plus faciles ├Ā utiliser. Entrent dans cette cat├®gorie┬Ā:
CMPS ; utiliser CMPSB ou CMPSD
INS ; utiliser INSB ou INSD
LODS ; utiliser LODSB ou LODSD
MOVS ; utiliser MOVSB ou MOVSD
OUTS ; utiliser OUTSB ou OUTSD
SCAS ; utiliser SCASB ou SCASD
STOS ; utiliser STOSB ou STOSD
XLAT ; utiliser XLATBIII. D├®buter sur GoAsm▲
III-A. Construction d'un fichier ASM▲
Le fichier ASM est un fichier que vous cr├®ez et ├®ditez en utilisant un ├®diteur de texte ordinaire, comme Paws que vous pouvez t├®l├®charger ├Ā partir de mon site web, www.GoDevTool.com, ou de programmes courants comme Notepad (Bloc-Notes) ou Wordpad qui sont livr├®s avec Windows. Si vous utilisez ce dernier, vous devez vous assurer que vous enregistrez le fichier dans un format qui n'ajoute pas de caract├©res de contr├┤le ou de formatage autres que l'habituelle fin de ligne (retour chariot et saut de ligne). Ceci, parce GoAsm ne s'int├®resse qu'au texte brut. Vous pouvez vous pr├®munir contre ces caract├©res non d├®sir├®s en sauvegardant le fichier comme document ┬½┬Ātexte┬Ā┬╗. Si vous n'adjoignez pas une extension au nom de fichier (l'extension d├®signe les caract├©res apr├©s le ┬½┬Āpoint┬Ā┬╗), alors l'├®diteur peut lui attribuer automatiquement une extension ┬½┬Ā.txt┬Ā┬╗. Cependant, rien ne vous emp├¬che de la changer en renommant le fichier (vous pouvez ex├®cuter cette op├®ration sur l'Explorateur Windows en pratiquant un clic droit sur le nom et en s├®lectionnant la fonction ┬½┬ĀRenommer┬Ā┬╗).
Il se peut que vous ne puissiez visualiser l'extension du fichier sur votre ordinateur. Il s'agit, en ce cas, d'une question de param├®trage de l'Explorateur Windows. Pour ce faire, s├®lectionnez l'├®l├®ment de menu ┬½┬ĀAffichage┬Ā┬╗, ┬½┬ĀOptions┬Ā┬╗, ┬½┬ĀModifiez les options des dossiers et de recherche┬Ā┬╗ puis sur l'onglet ┬½┬ĀAffichage┬Ā┬╗ et, enfin, veillez ├Ā ce que la case ┬½┬ĀMasquer les extensions des fichiers dont le type est connu┬Ā┬╗ soit d├®coch├®e. La proc├®dure peut diff├®rer l├®g├©rement selon la version de Windows.
Il est de tradition chez les programmeurs d'attribuer ├Ā leurs scripts source une extension qui correspond au langage dans lequel il est ├®crit. Par exemple, vous pourriez avoir un fichier assembleur appel├® ┬½┬Āmyprog.asm┬Ā┬╗. De la m├¬me mani├©re, vous trouverez g├®n├®ralement le code source ├®crit en langage C avec l'extension ┬½┬Ā.c┬Ā┬╗ ou ┬½┬Ā.cpp┬Ā┬╗ (pour ┬½┬ĀC ++┬Ā┬╗), ┬½┬Ā.pas┬Ā┬╗ pour Pascal et ainsi de suite. Cependant, ces extensions sont totalement neutres d'un point de vue strictement informatique. GoAsm accepte ainsi les fichiers de toute extension, de m├¬me que ceux qui en sont d├®pourvus.
Le fichier .asm contient vos instructions pour le processeur en mots et nombres. Celles-ci sont converties en code ex├®cutable successivement par l'assembleur puis par l'├®diteur de liens. C'est ce code qui sera reconnu et ex├®cut├® par le processeur. On dit donc que le fichier .asm contient votre ┬½┬Ācode source┬Ā┬╗ ou votre ┬½┬Āscript source┬Ā┬╗.
III-B. Ins├®rer du code et des donn├®es▲
├Ć titre d'exemple, examinons le code et les donn├®es d'un simple programme Windows 32 bits qui ├®crit ┬½┬ĀHello World (from GoAsm)┬Ā┬╗ dans la fen├¬tre MS-DOS de l'invite de commande. Voici comment s'├®crit le fichier asm┬Ā:
DATA SECTION
;
KEEP DD 0 ; variable temporaire
;
CODE SECTION
;
START:
PUSH -11 ; STD_OUTPUT_HANDLE
CALL GetStdHandle ; r├®cup├©re, en EAX, le handle du buffer de l'├®cran actif
PUSH 0, ADDR KEEP ; KEEP re├¦oit la sortie de l'API WriteFile
PUSH 24, 'Hello World (from GoAsm)' ; 24 = longueur de la chaîne
PUSH EAX ; handle correspondant au buffer de l'├®cran actif
CALL WriteFile
XOR EAX, EAX ; retourne EAX = 0 comme recommand├® par Windows
RETNotez que tout ce qui est apr├©s un point-virgule est ignor├® jusqu'├Ā la fin de la ligne, de sorte que vous pouvez ins├®rer des commentaires ├Ā partir de ce signe.
Voir la rubrique op├®rateurs pour d'autres formes de commentaire. Lire le paragraphe Qualit├® des descriptions et commentaires dans l'Annexe K sur l'importance des commentaires en programmation.
La premi├©re ligne de ce fichier ouvre la section de donn├®es par DATA SECTION. On consultera la rubrique sections - d├®claration et utilisation en ce qui concerne l'importance des sections et comment les utiliser.
Dans cette section, nous d├®clarons une zone de donn├®es de quatre octets (DD signifie un ┬½┬ĀDWord┬Ā┬╗ ou ┬½┬Ādouble-mot┬Ā┬╗ qui est de quatre octets) et, comme cette zone va ├¬tre sollicit├®e dans le programme, nous l'identifions avec le nom ┬½┬ĀKEEP┬Ā┬╗ et l'initialisons ├Ā z├®ro. En d'autres termes, nous avons cr├®├® la variable 32 bits ┬½┬ĀKEEP┬Ā┬╗. Lire ├Ā cet ├®gard la section d├®claration de donn├®es pour des explications d├®taill├®es sur ce point.
Nous ouvrons ensuite la section de code avec le label ┬½┬ĀSTART┬Ā┬╗, qui indique au processeur o├╣ commencer l'ex├®cution des instructions du programme. C'est ce qu'on appelle habituellement le ┬½┬Āpoint d'entr├®e┬Ā┬╗. Voir la rubrique code et point d'entr├®e pour de plus amples explications, et notamment sur les variantes admises en mati├©re de point d'entr├®e.
L'instruction suivante PUSH -11 met la valeur d├®cimale -11 sur la pile en pr├®alable ├Ā l'appel de l'API Windows GetStdHandle sur la ligne suivante. Il s'agit l├Ā du seul param├©tre exig├® par cette API. La valeur -11 pr├®cise ici que la recherche du handle du buffer d'├®cran est requise. Ce handle est fourni dans le registre EAX en sortie d'API. Lire l'annexe comprendre la pile pour une explication du fonctionnement de la pile et de l'instruction PUSH. La rubrique comprendre les nombres finis, n├®gatifs, sign├®s et en compl├®ment ├Ā 2 explique, en d├®tail, ce que l'on entend pr├®cis├®ment par ┬½┬Āvaleur d├®cimale -11┬Ā┬╗. Enfin, les d├®butants en Windows liront avec int├®r├¬t l'annexe pour les d├®butants en Windows qui introduit le fonctionnement des API.
L'instruction d'ex├®cution qui suit PUSH -11 transf├©re l'ex├®cution ├Ā l'API GetStdHandle et, ├Ā son retour, le registre EAX se retrouve charg├® avec la valeur de handle recherch├®e. L'ex├®cution se poursuit sur la ligne suivante. Lire, sur ce point, la rubrique transfert de l'ex├®cution ├Ā une proc├®dure.
Apr├©s ce premier appel d'API, on trouve cinq PUSH successifs. Notez que les deux premiers utilisent une syntaxe sp├®ciale o├╣ un seul PUSH permet d'en r├®aliser plusieurs, les op├®randes ├®tant mis ├Ā la suite les uns des autres et s├®par├®s par une virgule. Ici, il s'agit d'une commodit├® d'├®criture permise par GoAsm et n'ayant rien ├Ā voir avec les instructions processeur. Lire ├Ā ce sujet la section instructions r├®p├®t├®es pour en savoir plus. Ces PUSH constituent les param├©tres ├Ā passer ├Ā l'API WriteFile. Ces param├©tres sont, dans l'ordre┬Ā: z├®ro, puis l'adresse de la variable KEEP, puis le nombre 24 d├®cimal qui est la longueur de la cha├«ne (les mots entre guillemets), puis un pointeur vers de d├®but de cette m├¬me cha├«ne et, enfin, le contenu du registre EAX charg├® avec la valeur du handle donn├®e en retour du pr├®c├®dent appel d'API.
En retour de l'appel d'API CALL WriteFile, la valeur z├®ro est mise dans le registre EAX utilisant l'instruction XOR EAX, EAX. C'est la m├¬me chose que MOV EAX,0 mais produit moins d'octets de code. Voir ├Ā ce sujet l'annexe quelques conseils et astuces de programmation.
Enfin RET termine le programme en retournant ├Ā l'appelant (dans ce cas, Windows lui-m├¬me). Voir l'annexe pour les d├®butants en Windows.
III-C. Assemblage du fichier avec GoAsm▲
Apr├©s avoir ├®crit comme il convient le code et les donn├®es de votre fichier ASM, vous ├¬tes maintenant pr├¬t ├Ā finaliser votre programme. Cela se fait en deux temps. Vous devez tout d'abord assembler votre fichier puis le lier. Pour ce faire, vous devez ouvrir une fen├¬tre MS-DOS(1) (invite de commande). Dans ce cas, vous utilisez la ligne de commande┬Ā:
GoAsm /fo HelloWorld.obj filenameo├╣ filename est le nom de votre fichier asm. Voir la section d├®marrage de GoAsm pour savoir comment utiliser la ligne de commande de GoAsm.
GoAsm produit un fichier ┬½┬Āobjet┬Ā┬╗ contenant votre code et les donn├®es. Ce fichier re├¦oit l'extension ┬½┬Ā.obj┬Ā┬╗ et se pr├®sente dans un format adapt├® ├Ā l'├®diteur de liens. Voir plus d'informations sur le fichier objet.
III-D. Lien du fichier objet pour cr├®er le programme EXE▲
L'├®tape finale est de ┬½┬Ālier┬Ā┬╗ votre programme pour cr├®er l'ex├®cutable final. Vous pouvez utiliser le programme GoLink compl├®mentaire ├Ā GoAsm pour ce faire. D├©s lors, la ligne de commande se pr├®sente ainsi┬Ā:
GoLink /console helloworld.obj kernel32.dllAjoutez le commutateur ┬½┬Ā-debug coff┬Ā┬╗ si vous envisagez d'examiner le programme dans le d├®bogueur.
Notez que les appels GetStdHandle et WriteFile s'adressent ├Ā KERNEL32.DLL, ce qui explique que le nom de cette DLL apparaisse dans la ligne de commande de GoLink. Voir pour plus d'informations ├Ā propos des DLL. Voir la rubrique utilisation de GoAsm avec divers linkers si vous souhaitez proc├®der ├Ā l'├®dition des liens autrement qu'avec GoLink. Consulter l'aide de GoLink pour conna├«tre les autres options de cet ├®diteur.
Dans la ligne qui pr├®c├©de, GoLink cr├®e le fichier HelloWorld.exe. Vous pouvez ensuite ex├®cuter ce programme ├Ā partir de la fen├¬tre MS-DOS (invite de commande). Tapez ┬½┬ĀHelloWorld┬Ā┬╗ et appuyez sur Entr├®e. Vous verrez la cha├«ne que vous avez envoy├®e ├Ā l'API WriteFile s'├®crire dans la console.
Revenons maintenant sur les lignes de votre script source.
Dans un premier temps, vous avez demand├® ├Ā Windows le handle de la fen├¬tre de la console, lequel a ├®t├® renvoy├® par l'API GetStdHandle qui l'a recherch├® puis stock├® dans le registre EAX. Dans un second temps, ce handle et la cha├«ne ├Ā ├®crire ont ├®t├® pass├®s ├Ā WriteFile. Exprim├® autrement, vous avez invit├® Windows ├Ā ├®crire la cha├«ne sp├®cifi├®e dans la console. L'information quant ├Ā la mani├©re exacte d'utiliser les API et leur passer les param├©tres appropri├®s est disponible aupr├©s de Microsoft depuis le site MSDN (chercher ┬½┬ĀPlatform SDK┬Ā┬╗). Enfin il est utile de lire la section consacr├®e aux suggestions sur la fa├¦on d'organiser votre travail de programmation.
IV. ├ēl├®ments de base de GoAsm▲
IV-A. D├®marrage de GoAsm▲
La syntaxe de la ligne de commande est┬Ā:
GoAsm [command line switches] filename[.ext]O├╣
- filename est le nom du fichier source┬Ā;
- [command line switches] donne l'emplacement des ├®ventuels commutateurs de la ligne de commande de GoAsm d├®crits ci-apr├©s.
IV-A-1. Commutateur de ligne de commande▲
|
beep sur erreur. |
|
place syst├®matiquement le fichier de sortie dans le r├®pertoire courant. |
|
d├®finit un mot (par exemple /d WINVER=0x400). |
|
fichier de sortie vide autoris├®. |
|
sp├®cifie le fichier sortie avec son chemin d'acc├©s. Par exemple /fo asm\myprog.obj. |
|
conserve le soulignement d'en-t├¬te dans les appels externes ┬½┬ĀC┬Ā┬╗ de la biblioth├©que. |
|
aide (affiche les possibilit├®s pr├®sentes de la ligne de commande). |
|
cr├®e un fichier contenant le listing d'assemblage. |
|
enrichissement pour mslinker. |
|
pas de messages d'erreur. |
|
pas de messages d'information. |
|
aucun message d'avertissement. |
|
aucun message de sortie quel qu'il soit. |
|
partage des fichiers d'en-tête (les fichiers d'en-tête peuvent être ouverts par d'autres programmes lors de l'assemblage). |
|
assemblage pour processeurs AMD64 ou IA-64. |
|
source assembleur 64 bits en mode de compatibilit├® 32 bits. |
Si la sp├®cification du nom du fichier d'entr├®e ne comporte pas d'extension, GoAsm cherche le fichier sans aucune extension. Si ce fichier est introuvable en tant que tel, GoAsm recherche ├Ā nouveau le m├¬me fichier agr├®ment├® d'une extension .asm.
Si aucun chemin d'acc├©s ne pr├®c├©de le nom du fichier d'entr├®e, ce dernier est suppos├® ├¬tre localis├® dans le r├®pertoire courant.
Si aucun nom de fichier n'est pr├®cis├® pour la cr├®ation du fichier objet, celui-ci est cr├®├® avec le m├¬me nom que le fichier d'entr├®e et affect├® de la terminaison .obj. Par exemple MyAsm.asm va cr├®er un fichier appel├® MyAsm.obj.
Le r├®pertoire qui re├¦oit le fichier de sortie est┬Ā:
- le chemin d'acc├©s sp├®cifi├® si /fo est utilis├®, ou si on ne le mentionne pas┬Ā:
- le r├®pertoire courant si /c est sp├®cifi├®, ou si on n'utilise pas ce commutateur┬Ā:
- le chemin d'acc├©s associ├® au fichier d'entr├®e, ou si aucun r├®pertoire n'est donn├®┬Ā:
- le r├®pertoire courant.
Si aucune extension n'est pr├®cis├®e pour le fichier de sortie, .obj est cr├®├®e par d├®faut. Le fichier de listing d'assemblage emploie le m├¬me nom que le fichier de sortie, mais avec l'extension .lst et il est cr├®├®, par ailleurs, dans le m├¬me r├®pertoire que celui-ci.
IV-B. Sections - d├®claration et utilisation▲
IV-B-1. Pourquoi les sections sont n├®cessaires▲
Vous devez d├®clarer une section avant que vous ne commenciez ├Ā coder. La raison en est que le processeur a besoin de conna├«tre les attributs des instructions qui lui sont adress├®es. Notez ├®galement que le syst├©me Windows se repose sur ces attributs pour identifier les parties de votre code. Les attributs les plus courants sont la lecture seule (ne peut pas recevoir d'├®criture), la lecture-├®criture (peut recevoir une ├®criture) et l'ex├®cution (instructions de code). En interne, les processeurs traitent l'instruction de la mani├©re la plus appropri├®e et la plus rapide en rapport avec l'attribut. Par exemple, les instructions de code utilisent le code cache du processeur, le mat├®riau non constitutif de code est assimil├® ├Ā des donn├®es et peut ├¬tre pris en charge par le cache de donn├®es.
Lorsque vous d├®clarez une section dans votre script source, GoAsm d├®finit automatiquement l'attribut de la section. Une fois ceci fait, vous pouvez commencer ├Ā ├®crire le code ou les donn├®es dans votre programme.
IV-B-2. Comment d├®clarer une section▲
En programmation Windows, nous sommes int├®ress├®s par seulement quatre types de sections┬Ā: le code, les donn├®es, les constantes, et les donn├®es non initialis├®es. Vous d├®clarez le code, les donn├®es ou les sections de constantes comme suit┬Ā:
CODE SECTION
DATA SECTION
CONST SECTION
; ou
CONSTANT SECTIONLes mots CODE, DATA, CONST et CONSTANT sont r├®serv├®s ├Ā la d├®claration des sections et une erreur sera signal├®e si ces mots sont utilis├®s ailleurs dans votre source.
GoAsm permet ├®galement de raccourcir les formes de d├®claration de section comme suit┬Ā:
CODE
DATA
CONSTVous pouvez ├®galement utiliser
.CODE
.DATA
.CONSTsi vous le souhaitez.
GoAsm ajoute automatiquement les attributs en fonction du processeur et de Windows. Une section de code re├¦oit les attributs lecture, ex├®cution, code. Une section de donn├®es est dot├®e des attributs lecture, ├®criture, donn├®es initialis├®es. Une section const re├¦oit les attributs lecture, donn├®es initialis├®es (vous ne pourriez pas ├®crire dans une section const). Les donn├®es non initialis├®es poss├©dent les attributs lecture, ├®criture, donn├®es non initialis├®es.
├Ć d├®faut d'ajouter l'attribut SHARED, vous ne pouvez faire fi de ces attributs de votre propre initiative. Ceci est inutile car Windows s'arroge le contr├┤le total sur les attributs de la section lorsqu'elle est charg├®e et ex├®cut├®e. Par exemple, m├¬me si vous donnez ├Ā une section de code l'attribut d'├®criture, Windows ne vous permettra pas d'├®crire dedans. De la m├¬me mani├©re, Windows ne vous permettra pas d'ex├®cuter du code dans une section de donn├®es. Vous pouvez n├®anmoins d├®roger ├Ā ce comportement en appelant l'API VirtualProtect au moment de l'ex├®cution.
Dans GoAsm vous pouvez inclure des donn├®es en lecture seule (read-only) dans une section de code, m├¬me s'il peut en r├®sulter une r├®duction des performances.
D├®clarer une section positionne implicitement certains commutateurs dans GoAsm qui affectent la syntaxe et le codage. Les r├©gles sont les suivantes.
- Tous les labels d'une section de code doivent imp├®rativement se terminer par deux points. Cela permet ├Ā GoAsm de distinguer un label de ce qui n'en est pas un, de veiller ├Ā ce que les mn├®moniques et les directives mal orthographi├®s soient toujours signal├®s comme une erreur.
- Les labels r├®utilisables ne sont autoris├®s que dans une section de code. Si vous les utilisez dans une section de donn├®es, ils seront consid├®r├®s comme des labels uniques et int├®gr├®s ├Ā ce titre dans la table des symboles.
- GoAsm signalera une erreur si une instruction tente d'├®crire dans une section const. La section const est destin├®e aux donn├®es et cha├«nes initialis├®es qui ne sont pas appel├®es ├Ā recevoir une ├®criture.
IV-B-3. Section de donn├®es non initialis├®es▲
Si vous d├®clarez des donn├®es non initialis├®es, GoAsm constitue une section sp├®cifique de donn├®es non initialis├®es dans le fichier-objet. Elle sera nomm├®e ┬½┬Ā.bss┬Ā┬╗ en consid├®ration d'autres outils. GoAsm lui attribue d'office ce nom que vous ne pouvez pas modifier parce que certains linkers s'attendent pr├®cis├®ment ├Ā le trouver. Avec la plupart des linkers, y compris GoLink, la section .bss ne trouve pas sa place dans l'exe final. Au lieu de cela, elle est fusionn├®e avec une section d'attribut lecture/├®criture dans le fichier exe. Les attributs de la section de donn├®es non initialis├®es sont la lecture, l'├®criture, les donn├®es non initialis├®es.
L'avantage de d├®clarer des donn├®es non initialis├®es, plut├┤t que des donn├®es initialis├®es, est que l'ex├®cutable est plus petit. Ceci, parce que l'ex├®cutable se borne ├Ā sp├®cifier la quantit├® de donn├®es non initialis├®es ├Ā r├®server sans leur attribuer la moindre valeur. Les buffers de toute sorte sont souvent constitu├®s ainsi. Voir la section d├®claration des donn├®es non initialis├®es ordinaires.
IV-B-4. Morcellement des sections▲
Rien n'oblige le programmeur ├Ā ├®crire de grandes sections indivisibles. Par exemple, il est tout ├Ā fait envisageable d'avoir une portion de donn├®es suivie d'une portion de code, elle-m├¬me suivie par une nouvelle portion de donn├®es et ainsi de suite, sous r├®serve de prendre soin d'en d├®clarer la nature ├Ā chaque fois avec un des mots-cl├®s suivants┬Ā:
CODE SECTION
DATA SECTION
CONST SECTIONou leur forme abr├®g├®e, le cas ├®ch├®ant. Vous pouvez le faire aussi souvent que vous le souhaitez au travers de votre script source. GoAsm et l'├®diteur de liens se chargent de concat├®ner toutes les instructions destin├®es ├Ā chaque section.
Voir aussi sections - gestion avanc├®e sur les d├®nominations de sections, les sections partag├®es, les sections de commande, et les consid├®rations li├®es ├Ā l'alignement de la section.
IV-C. D├®claration des donn├®es▲
IV-C-1. Qu'est-ce qu'une ┬½┬Ādonn├®e┬Ā┬╗┬Ā?▲
D'une certaine mani├©re toutes les instructions transmises ├Ā un processeur sont des ┬½┬Ādonn├®es┬Ā┬╗. Mais les programmeurs en assembleur utilisent ce mot pour d├®signer une information qui est, soit fixe, soit susceptible d'├¬tre modifi├®e au moment de l'ex├®cution et qui ne peut pas ├¬tre ex├®cut├®e en tant qu'instruction de processeur. Les donn├®es peuvent ├¬tre class├®es en quatre cat├®gories.
- Les donn├®es en lecture seule - read-only - sp├®cifi├®es en tant que telles ├Ā la phase d'assemblage (lorsque le programme est compil├®) et qui sont conserv├®es dans la section const qui a un attribut de lecture seule. On parle alors de ┬½┬Ādonn├®es initialis├®es┬Ā┬╗ parce que leur contenu est fix├® dans le script source. Au moment de l'ex├®cution, ces donn├®es peuvent ├¬tre lues, mais on ne peut ├®crire dessus et modifier ainsi leur contenu. Dans votre script source, vous devez leur attribuer des labels de sorte qu'elles puissent ├¬tre r├®f├®renc├®es facilement.
- Les donn├®es fix├®es au moment de l'assemblage et localis├®es dans la section de donn├®es du fichier ex├®cutable. Encore une fois, le contenu des donn├®es sera fix├® dans votre script source mais, au moment de l'ex├®cution, elles pourront ├¬tre lues ou modifi├®es en utilisant les labels de donn├®e correspondants.
- Les donn├®es non fix├®es au moment de l'assemblage, mais qui sont localis├®es dans une zone qui leur est r├®serv├®e. Il s'agit des ┬½┬Ādonn├®es non initialis├®es┬Ā┬╗ et seule leur taille est recens├®e dans le fichier ex├®cutable. Dans votre script source assembleur vous sp├®cifiez la quantit├® de donn├®es devant ├¬tre r├®serv├®es. Vous pouvez leur attribuer des labels, mais vous ne pouvez pas initialiser leur contenu. L'avantage de ce type de donn├®es est qu'elles ne prennent pas de place dans l'ex├®cutable. Au moment du chargement, les donn├®es sont seulement localis├®es et ne re├¦oivent pas de contenu donn├® ├Ā ce stade. Au moment de l'ex├®cution, les donn├®es de ce type peuvent ├¬tre lues ou ├®crites de la m├¬me mani├©re que leurs homologues de la section de donn├®es.
- Les donn├®es ├®tablies au moment de l'ex├®cution, soit par le programme lui-m├¬me, soit par le syst├©me. Ces donn├®es ne sont pas ├®tablies au moment de la phase d'assemblage de votre script source. Elles le sont, en r├®alit├®, par le syst├©me d'exploitation lorsque votre code est ex├®cut├®.
IV-C-2. D├®claration des donn├®es num├®riques initialis├®es▲
GoAsm se conforme ├Ā la syntaxe assembleur traditionnelle pour d├®clarer des donn├®es dans votre script source.
Dans une section data ou cons, un label ne doit pas ├¬tre termin├® par deux points. Dans une section de code cela est n├®cessaire, pour favoriser l'identification des erreurs de syntaxe. Quelques exemples (utilisant une section de donn├®es)┬Ā:
HELLO1 DB 0 ; 1 octet avec le label "HELLO1" fix├® ├Ā z├®ro
DB 0 ; le second octet fix├® ├Ā z├®ro
HELLO2 DW 34h ; 2 octets (soit un mot) fix├® ├Ā la valeur 34h
HELLO3 DD 12345678h ; 4 octets (un dword) fix├®s ├Ā la valeur 12345678h
HELLO4 DD 12345678D ; 4 octets (un dword) fix├®s ├Ā la valeur d├®cimale 12345678
HELLO5 DD 1.1 ; 4 octets (un dword) fix├®s ├Ā la valeur du nombre r├®el 1.1
HELLO6 DQ 0.0 ; 8 octets (un qword) fix├®s ├Ā la valeur du nombre r├®el 0.0
HELLO7 DQ 123456789ABCDEFh ; 8 octets (un qword) fix├®s ├Ā la valeur 123456789ABCDEFh
HELLO8 DQ 1234567890123456 ; 8 octets (un qword) fix├®s ├Ā la valeur d├®cimale 1234567890123456
HELLO9 DT 1.1E0 ; 10 octets (un tword) fix├®s ├Ā la valeur du nombre r├®el 1.1
HELLOA DT 123456789ABCDEFh ; 10 octets (un tword) fix├®s ├Ā la valeur 123456789ABCDEFhNotez que DB, DW, DD et DQ acceptent les nombres aussi bien dans le format d├®cimal qu'hexad├®cimal┬Ā; DD, DQ et DT acceptent ├®galement les nombres r├®els.
Voir les sections d├®claration des nombres r├®els, chargement direct de l'exposant et de la mantisse et chargement d'un fichier avec INCBIN.
IV-C-3. D├®claration de plusieurs donn├®es sur une m├¬me ligne▲
Une virgule apr├©s un initialiseur signifie qu'un autre initialiseur est attendu afin de d├®clarer d'autres donn├®es. La syntaxe est la suivante┬Ā:
Label DB 0, 0, 0, 0 ; 4 octets fix├®s ├Ā z├®ro
DW 33h, 44h, 55h, 66h ; 4 mots initialis├®s
DD 33h, 44h, 55h, 66h ; 4 dwords initialis├®s
DD 1.1, 2.2 ; 2 DD de nombres r├®els
DQ 1.1, 2.2 ; 2 DQ de nombres r├®els
DQ 3333h, 4444h ; 2 DQ de nombres hexa
DT 1.1, 2.2 ; 2 DT de nombres r├®els
DT 5555h, 6666h ; 2 DT de nombres hexaIV-C-4. D├®claration de donn├®es non initialis├®es ordinaires▲
GoAsm rejoint ici la syntaxe traditionnelle des assembleurs mais, ├Ā l'instar de A386, il ne n├®cessite pas de section non initialis├®e (la section .bss) pour d├®clarer ce type de variable. Au lieu de cela, un simple point d'interrogation garantit que la donn├®e est consid├®r├®e comme non initialis├®e. Quelques exemples (dans les sections texte data ou const)┬Ā:
HELLO1 DB ? ; 1 octet avec le label "HELLO1" enregistr├® comme non initialis├®
HELLO2 DW ? ; 2 octets (word)
HELLO3 DD ? ; 4 octets (dword)
HELLO4 DQ ? ; 8 octets (qword)
HELLO5 DT ? ; 10 octets (tword)Les donn├®es non initialis├®es orphelines ne sont pas permises┬Ā: vous ne pouvez pas m├®langer les donn├®es initialis├®es et non initialis├®es, ├Ā d├®faut de quoi vous provoquez une erreur┬Ā:
DATA6 DD 5 DUP 0
DB ? ; d├®claration non autoris├®e
DB 0En revanche, l'├®criture qui suit est parfaitement correcte┬Ā:
DATA6 DD 5 DUP ? ; 5 dwords pour le client
DB ? ; un octet pour avoir le plat principal
DB ? ; et un octet pour avoir les saucesCeci vous permet de s├®parer les zones de donn├®es non initialis├®es de sorte que chaque zone s├®par├®e puisse avoir son propre commentaire.
Les donn├®es non initialis├®es ne peuvent pas ├¬tre d├®clar├®es tant qu'une section n'a pas ├®t├® ouverte. Vous pouvez d├®clarer des donn├®es non initialis├®es au sein de la section de code, mais les labels doivent se terminer par deux points comme il est de r├©gle pour la section de code, par exemple┬Ā:
HELLO1: DB ? ; 1 octet avec le label "HELLO1" enregistr├® comme non initialis├®
HELLO2: DW ? ; 2 octets (un word)IV-C-5. D├®claration de donn├®es dupliqu├®es (DUP)▲
GoAsm utilise la syntaxe DUP bien connue, mais ne n├®cessite pas d'initialiseur entre parenth├©ses. Quelques exemples (dans la section de donn├®es)┬Ā:
HELLO1 DB 2 DUP 0 ; 2 octets avec le label "HELLO1" tous les deux initialis├®s ├Ā z├®ro
HELLO1A DB 800h DUP ? ; 2K de buffer de donn├®es non initialis├®es
HELLO2 DW 2 DUP 0 ; 4 octets tous fix├®s ├Ā z├®ro
HELLO3 DD 2 DUP ? ; 8 octets dans la section non initialis├®e
HELLO4 DD 2 DUP 1.1 ; nombre r├®el 1.1 dans dword r├®p├®t├® 1 fois
HELLO5 DQ 2 DUP 1.1 ; nombre r├®el 1.1 dans qword r├®p├®t├® 1 fois
HELLO6 DQ 2 DUP 333h ; qword r├®p├®t├® 1 fois
HELLO7 DT 2 DUP 1.1 ; nombre r├®el 1.1 dans tword r├®p├®t├® 1 fois
HELLO8 DT 2 DUP 444h ; tword r├®p├®t├® 1 foisVous pouvez utiliser DUP pour d├®clarer une donn├®e globalement, puis en initialiser individuellement chaque ├®l├®ment┬Ā:
HELLO300 DB 3 DUP <23, 24, 25> ; d├®clare 3 octets et les initialise respectivement ├Ā 23, 24, 25qui fait la m├¬me chose que┬Ā:
HELLO300 DB 23, 24, 25 ; d├®clare 3 octets et les initialise respectivement ├Ā 23, 24, 25Bien qu'il puisse sembler inutile d'y recourir, la syntaxe rend plus facile l'initialisation d'un membre d'une structure si celui-ci contient l'op├®rateur DUP Voir la section initialisation de membres de structure avec d├®clarations de donn├®es DUP.
IV-C-6. Initialisation utilisant des caract├©res en lieu et place de leurs codes ASCII▲
Au lieu de devoir initialiser des caract├©res par le biais de leur code ASCII, vous pouvez obtenir plus directement ce r├®sultat en vous bornant ├Ā d├®clarer les caract├©res entre guillemets. Par exemple┬Ā:
Letters DB 'a' ; au lieu de DB 61h
DW 'xy' ; au lieu de DW 7978h
Sample DD 'form' ; au lieu de DD 6D726F66h
ZooDay DQ 'Saturday' ; au lieu de DQ 7961647275746153hException faite du cas de l'insertion de cha├«nes Unicode, GoAsm ne r├®alise pas de conversion du caract├©re, de sorte que la valeur r├®elle ins├®r├®e dans le fichier objet d├®pendra du jeu de caract├©res courant au moment de l'assemblage.
GoAsm ne m├®morise pas le mot et les d├®clarations de cha├«ne Word et DWord ci-dessus en utilisant le stockage inverse. Il rejoint en cela la pratique de NASM qui a pris le contrepied de MASM en la mati├©re. Cela signifie que l'octet de poids faible dans DW 'xy' est 'x' et que 'y' est l'octet de poids fort. De m├¬me dans DD 'form' correspondant au label Sample, l'octet de plus faible poids est 'f' et ainsi de suite jusqu'├Ā l'octet de plus fort poids qui est 'm'. L'avantage de cette configuration est de vous permettre, par exemple, de transf├®rer tr├©s simplement cette cha├«ne au moyen du codage ci-dessous┬Ā:
MOV EDI, ADDR BUFFER
MOV EAX, [Sample]
STOSDqui ins├©re dans le buffer la cha├«ne 'form'.
Les octets non initialis├®s re├¦oivent la valeur z├®ro. Par exemple┬Ā:
DW 'a' ; le premier octet est 'a', le second est nul
DD 'ab' ; 'a' puis 'b' puis 2 octets ├Ā z├®roOn peut r├®p├®ter les initialisations de valeur de caract├©re, par exemple┬Ā:
DD 3 DUP "Hi"Cela ins├©re 'H' puis 'i' puis deux z├®ros, cette op├®ration ├®tant r├®p├®t├®e ├Ā trois reprises.
IV-C-7. D├®claration de cha├«nes▲
Les cha├«nes peuvent ├¬tre entre guillemets simples ou doubles. En voici quelques exemples d'utilisation┬Ā:
String1 DB 'Ceci est une chaîne'
DB 'Ceci est une chaîne avec des guillemets "internes"'
String2 DB "Une chaîne entre guillemets"
DB "J'appr├®cie le contenu de la cha├«ne"
String3 DB '"Une chaîne elle-même entre guillemets"'
DB "'Une chaîne elle-même entre guillemets simples'"
DB "'Une chaîne avec ses propres guillemets simples'"
String4 DB """Une chaîne avec ses propres guillemets simples et doubles"""
DB '''Une cha├«ne elle-m├¬me avec ses guillemets "internes"'''Dans String4 chaque couple de deux guillemets cons├®cutifs constitue un guillemet qui est partie int├®grante de la cha├«ne en tant que caract├©re affichable. Cette convention vaut uniquement pour les guillemets des deux extr├®mit├®s de la cha├«ne qu'ils encadrent (contrairement ├Ā GoRC, qui agit ├®galement ├Ā l'int├®rieur de la cha├«ne).
IV-C-8. D├®claration d'une cha├«ne sur plusieurs lignes▲
Une virgule apr├©s une cha├«ne signifie qu'un autre initialiseur est attendu lequel peut d├®clarer, soit des donn├®es compl├®mentaires, soit une autre cha├«ne ainsi qu'on peut le voir dans les exemples suivants┬Ā:
String1 DB 'Ceci est une chaîne avec terminateur null', 0
DB 'Premi├©re cha├«ne',0,'Et une autre cha├«ne', 0
String2 DB 22h, "Une cha├«ne avec ses propres guillemets doubles", 22hLes valeurs ASCII que vous pouvez utiliser ici, si le vous souhaitez, sont┬Ā: 22h pour les guillemets doubles et 27h pour les apostrophes.
IV-C-9. Cha├«nes plus longues▲
Dans le cas d'une cha├«ne plus longue, il est possible de la scinder par faute de place sur la ligne et d'en reporter le contenu r├®siduel ├Ā la ligne suivante tout en faisant pr├®c├®der ce contenu de l'op├®rateur DB. Par exemple┬Ā:
LongString1 DB 'Son premier programme semblait tr├©s prometteur'
DB 'jusqu'├Ā ce qu'il ne fonctionne pour la premi├©re fois', 0
LongString2 DB 'Son erreur fondamentale:', 0Dh, 0Ah
DB 'il ne l'a pas test├® en cours de d├®veloppement', 0Les valeurs ASCII 0Dh et 0Ah sont respectivement le retour chariot et le saut de ligne. Ils sont utilis├®s pour commencer une nouvelle ligne lorsque l'ensemble de la cha├«ne est affich├® sur l'├®cran.
IV-C-10. Cha├«nes Unicode▲
En programmation Windows, vous avez parfois besoin de d├®clarer des cha├«nes Unicode dans les sections data ou const, par exemple dans un mod├©le de dialogue. Il y a plusieurs fa├¦ons de proc├®der dans GoAsm qui sont d├®crites en d├®tail dans le chapitre ┬½┬Ā├ēcriture de programmes Unicode┬Ā┬╗ du volume 2. En bref, vous pouvez utiliser l'une ou l'autre des m├®thodes suivantes.
- Reposez-vous sur le format Unicode de base du script source (GoAsm peut lire les fichiers Unicode UTF-16 et UTF-8)┬Ā;
- Utilisez le symbole L suivi d'une apostrophe utilis├® en programmation C, par exemple┬Ā:
DB L'Bonjour comment vas-tu?'- D├®clarez la s├®quence Unicode en utilisant DUS┬Ā:
DUS 'Je suis une cha├«ne Unicode avec une nouvelle ligne et le terminateur null', 0Dh, 0Ah, 0Voir aussi la section ┬½┬ĀPr├®positionnement utilisant la directive STRINGS┬Ā┬╗ dans le volume 2.
IV-C-11. Insertion de blocs de donn├®es par DATABLOCK▲
Pour les blocs de donn├®es volumineux risquant d'encombrer inutilement le fichier source, il existe une alternative consistant ├Ā utiliser INCBIN pour charger le contenu ou une partie du contenu du fichier contenant ces donn├®es. Sinon, vous pouvez utiliser DATABLOCK_BEGIN et DATABLOCK_END s'il s'av├©re plus appropri├® de faire figurer explicitement le bloc de donn├®es dans le fichier source lui-m├¬me.
La syntaxe d'un DATABLOCK est la suivante┬Ā:
MyBlockData DATABLOCK_BEGIN ;comment
.
. les donn├®es sont ins├®r├®es ici
.
DATABLOCK_ENDIci tout le mat├®riau positionn├® entre DATABLOCK_BEGIN et DATABLOCK_END est ins├®r├® dans le fichier de sortie de l'assembleur, et vous pouvez ensuite adresser les donn├®es en utilisant le label MyBlockData.
GoAsm consid├©re que ces donn├®es commencent imm├®diatement apr├©s la fin de la ligne contenant DATABLOCK_BEGIN et s'ach├©vent ├Ā la fin de la ligne pr├®c├®dant imm├®diatement celle contenant DATABLOCK_END.
Les donn├®es sont ins├®r├®es ├Ā l'├®tat brut, c'est-├Ā-dire qu'aucune conversion n'est effectu├®e. Cela signifie que les caract├©res qui ne peuvent pas ├¬tre affich├®s dans un ├®diteur ordinaire tel que les espaces ou les tabulations, par exemple, seront ├®galement charg├®s. Cela signifie aussi que le format des donn├®es et des caract├©res qui peuvent ├¬tre utilis├®s dans les donn├®es ne sont limit├®s que par l'├®diteur que vous utilisez pour ├®crire votre code source.
IV-C-12. Initialisation utilisant les adresses de labels▲
Il est fr├®quent que vous ayez besoin de charger un DWord avec l'adresse d'un label, de telle sorte qu'apr├©s traitement par l'assembleur puis le linker, ledit DWord contienne un pointeur vers ce label. Le label peut ├¬tre, soit un label de donn├®e, soit un label de code. Par exemple┬Ā:
MS1 DB 'Premi├©re cha├«ne ├Ā utiliser', 0
MS2 DB 'Deuxi├©me cha├«ne ├Ā utiliser', 0
Strings DD MS1, MS2 ; Strings contient l'adresse de MS1 et MS2Alors, si vous souhaitez utiliser la cha├«ne MS2, il vous est possible d'├®crire MOV ESI, [Strings+4] au lieu de MOV ESI, ADDR MS2.
En g├®n├®ralisant, tous les tableaux peuvent ├¬tre cr├®├®s en utilisant cette m├®thode et adress├®s au moyen du multiplicateur de registre d'index * (scale), par exemple┬Ā:
MOV ESI, [Strings + EAX * 4]Ici, le registre EAX re├¦oit l'index de la cha├«ne ├Ā utiliser. Lorsque EAX est nul, ESI re├¦oit l'adresse du label de la premi├©re cha├«ne┬Ā; lorsque EAX = 1, ESI re├¦oit l'adresse du label de la premi├©re cha├«ne et ainsi de suite s'il y a plus de cha├«nes.
Voici un exemple en utilisant des labels de code┬Ā:
PROCEDURE_TO_CALL DD FIRSTPROC, SECONDPROC
MOV ESI, ADDR PROCEDURE_TO_CALL ; adresse de la liste de proc├®dures dans ESI
MOV ESI, [ESI+EAX*4] ; adresse du label de la proc├®dure recherch├®e dans ESI
CALL [ESI] ; appel de la proc├®dureIV-D. Code et point d'entr├®e▲
IV-D-1. Qu'est-ce que le ┬½┬Ācode┬Ā┬╗┬Ā?▲
Le code est constitu├® des instructions contenues dans une section nomm├®e ┬½┬ĀCode┬Ā┬╗, qui a les attributs code et execute. Concr├©tement, vous indiquez au processeur laquelle des instructions de code doit ├¬tre ex├®cut├®e. Le processeur lit les instructions octet par octet et les ex├®cute. Chaque octet de code ex├®cutable est appel├® un opcode.
IV-D-2. Que fait le ┬½┬Āpoint d'entr├®e┬Ā┬╗┬Ā?▲
Dans un ex├®cutable ordinaire (fichier .exe), le point d'entr├®e caract├®rise l'adresse o├╣ l'ex├®cution commence imm├®diatement apr├©s le chargement. Dans une DLL (fichier .dll), cela d├®signe l'adresse o├╣ l'ex├®cution prend place pendant le processus de chargement.
IV-D-3. Comment est contr├┤l├®e l'ex├®cution┬Ā?▲
Une fois l'ex├®cution commenc├®e et le point d'entr├®e atteint, votre programme prend le contr├┤le de l'ex├®cution et va se poursuivre ├Ā partir de cette adresse. Assez souvent, bien que cela ne soit pas une obligation, la premi├©re instruction au point d'entr├®e consiste en un CALL, un saut conditionnel ou inconditionnel ├Ā destination de proc├®dures ├®crites plus avant ou d'API.
IV-D-4. Comment ├®tablir un point d'entr├®e┬Ā?▲
De ce qui pr├®c├©de on peut voir que, sauf si votre script source est constitu├® uniquement de donn├®es, il est essentiel de fournir un point d'entr├®e ├Ā votre programme. Dans GoAsm, ceci est r├®alis├® tr├©s simplement en attribuant un label au point d'entr├®e puis en indiquant au linker que ledit label est le point d'entr├®e du programme. On peut ├®galement utiliser le label START - suivi de deux points - mot r├®serv├® de GoAsm d├®finissant explicitement le point d'entr├®e et reconnu comme tel par l'├®diteur de liens.
Les exemples qui suivent proposent deux syntaxes possibles du commutateur ├Ā mettre sur la ligne de commande de GoLink si l'on d├®cide de ne pas utiliser START et de sp├®cifier un label de point d'entr├®e distinct, par exemple, entry┬Ā:
-entry STARTINGADDRESS
/entry STARTINGADDRESSSi vous utilisez ALINK seule la premi├©re m├®thode fonctionne.
L'int├®r├¬t du label r├®serv├® START est d'├®viter de devoir donner au linker une directive sp├®cifique d├®signant le point d'entr├®e. GoLink suppose en effet que celui-ci est constitu├® par label r├®serv├® START sauf avis contraire et lorsqu'il est pr├®sent. Voici comment sp├®cifier START dans votre script source pour d├®signer le point d'entr├®e du programme┬Ā:
START:Cela peut être en majuscules, en minuscules ou en une combinaison des deux.
Nous venons de voir ce qu'il en est en ce qui concerne GoLink. Les linkers concurrents abordent cette question de diff├®rentes mani├©res.
Si vous utilisez le MS linker, vous devez faire pr├®c├®der votre label par un caract├©re de soulignement. Votre label du point d'entr├®e devient donc _START: dans votre script source. Ensuite, vous devez positionner l'une ou l'autre de ces deux instructions sur la ligne de commande de l'├®diteur de liens (sans le caract├©re de soulignement)┬Ā:
-ENTRY START
/ENTRY STARTOn constate ici que le MS linker est con├¦u pour fonctionner avec un compilateur C qui fera pr├®c├®der les labels globaux d'un caract├©re de soulignement. Donc, l'├®diteur de liens cherche l'├®tiquette _START, plut├┤t que START. Les programmeurs en assembleur ont d├╗ s'accommoder de ces bizarreries dans les outils Windows pendant de nombreuses ann├®es, mais maintenant nous avons notre ind├®pendance┬Ā!
Voir aussi la section utilisation de GoAsm avec diff├®rents linkers.
IV-E. Labels uniques, r├®utilisables et ├Ā port├®e param├®trable▲
IV-E-1. Qu'est-ce qu'un ┬½┬Ālabel┬Ā┬╗┬Ā?▲
Un label est un nom que vous attribuez ├Ā un emplacement particulier dans les donn├®es ou dans le code dans la perspective de pouvoir y acc├®der simplement. Il a la m├¬me fonction qu'un signet. Cela vous permet de vous r├®f├®rer ├Ā cet emplacement et d'y acc├®der en utilisant un nom. Un label de donn├®e se r├®f├©re aux donn├®es┬Ā; un label de code fait r├®f├®rence ├Ā un code ex├®cutable. Un symbole est un label qui appara├«t dans la table des symboles du fichier objet et qui peut donc ├¬tre vu par le d├®bogueur si une version de d├®bogage de l'ex├®cutable est constitu├®e.
IV-E-2. Labels uniques▲
Un label unique correspond au cas g├®n├®ral d'un label qui ne peut ├¬tre utilis├® qu'une seule fois dans votre script source et dans les fichiers objet li├®s. Il est dit de port├®e ┬½┬Āglobale┬Ā┬╗, c'est-├Ā-dire qu'au moment de l'├®dition des liens, il peut ├¬tre accessible ├Ā d'autres fichiers objet. G├®n├®ralement, il est d'usage de choisir un nom qui distingue la fonction de donn├®e de la fonction de code, par exemple ┬½┬ĀNAME_LIST┬Ā┬╗ ou ┬½┬ĀCALCULATE_RESULT┬Ā┬╗. Si vous avez param├®tr├® votre linker pour fournir une sortie de d├®bogage, tous les labels uniques seront mis dans la liste des symboles et transmis au d├®bogueur. Dans GoAsm vous ├®tablissez un label unique comme suit┬Ā:
NAMEOFLABEL:Cela ne produit aucun code, mais fixe un signet appel├® NAMEOFLABEL au point des donn├®es ou du code o├╣ il appara├«t. Si vous ├¬tes dans une section de donn├®es, les deux points ne sont pas obligatoires. Il en va de m├¬me si un label donne le nom d'une trame de pile automatis├®e. Par cons├®quent, les lignes suivantes cr├®ent toutes des labels uniques┬Ā:
;(dans la section de donn├®es)
HELLO DB 0 ; label HELLO
BYE: DB 0 ; label BYE
MEAGAIN ; label MEAGAIN
;(dans la section de code)
RICE: ; label RICE
PEAS: FRAME ; label PEAS
BEANS FRAME ; label BEANSVous pouvez voir ├Ā partir de cela que tout mot qui n'est pas r├®put├® ├¬tre une directive, un mn├®monique, une d├®claration ou initialisation de donn├®es, ou un mot r├®serv├® de GoAsm sera consid├®r├® comme un label. GoAsm attend deux points apr├©s un label de section de code. Ceci parce qu'il y a de nombreux mots qui doivent ├¬tre utilis├®s dans une section de code et que, s'ils sont mal orthographi├®s, il est important qu'une erreur soit d├®clar├®e plut├┤t que le mot soit interpr├®t├® ├Ā tort comme un label.
IV-E-3. Labels r├®utilisables▲
Parfois, vous avez besoin d'apposer des labels sur des parties de votre script source avec des noms que vous avez d├®j├Ā utilis├®s auparavant. GoAsm offre deux niveaux de labels r├®utilisables qui peuvent ├¬tre employ├®s dans une section de code┬Ā:
- labels r├®utilisables de port├®e locale commen├¦ant par un point┬Ā;
- labels r├®utilisables de port├®e non limit├®e compos├®s de chiffres ou d'un caract├©re suivi de chiffres.
La port├®e d'un label d├®finit d'o├╣ il peut ├¬tre consult├® en utilisant son propre nom non modifi├®. Regardons de plus pr├©s ces deux types labels r├®utilisables.
IV-E-4. Labels r├®utilisables de port├®e locale▲
Ces types de labels, d'une syntaxe particuli├©re et donc reconnaissables ├Ā ce titre, sont cr├®├®s en utilisant un point suivi d'un label, par exemple┬Ā:
.looptop ; label looptop
.fin ; label finLa limite de la port├®e de ces labels sp├®ciaux est balis├®e par les labels de code uniques pr├®sents dans le script source. En d'autres termes, le label peut ├¬tre saut├® ├Ā condition qu'il n'y ait pas de label unique sur le chemin. Ainsi, ┬Ā:
JZ > .fin
CALCULATE:
.fin
RETIci l'instruction de saut JZ ne trouvera pas .fin parce que le label CALCULATE est un label de code unique plac├® sur le chemin.
Si vous voulez sauter par-dessus un label de code unique pour atteindre un label r├®utilisable de port├®e locale, vous pouvez utiliser un autre label de code unique ou un label r├®utilisable non d├®limit├® comme destination du saut. Il vous est ├®galement possible, quoique de mani├©re plus marginale, d'utiliser le label de port├®e locale dans une trame de pile automatis├®e. Voir, ├Ā ce sujet, labels r├®utilisables ├Ā port├®e d├®finie dans les trames de pile automatis├®es.
Les labels r├®utilisables de port├®e locale sont envoy├®s au d├®bogueur comme des symboles avec leur ┬½┬Āpropri├®taire┬Ā┬╗. Par cons├®quent le symbole envoy├® au d├®bogueur dans l'exemple ci-dessus est CALCULATE.fin, et une autre fa├¦on de sauter par-dessus le label unique serait d'├®crire JZ >CALCULATE.fin.
IV-E-5. Labels r├®utilisables de port├®e non limit├®e▲
Vous rencontrerez souvent dans votre code des sauts ou des boucles d'amplitude faible pour lesquels le choix d'un nom de label m├╗rement r├®fl├®chi n'apporte aucune plus-value ├Ā la compr├®hension du listing. Pour ceux-ci vous pouvez utiliser un label dont le nom ne sera pas transmis au d├®bogueur en tant que symbole. Il est utile, par ailleurs, lors du d├®bogage de limiter la table de symboles aux noms les plus importants dans votre code. Ces labels sont constitu├®s soit uniquement de chiffres, soit d'un caract├©re suivi d'un ou plusieurs chiffres. Vous pouvez ├®galement utiliser une variante avec un point d├®cimal qui facilite l'ajout de nouveaux labels locaux au code existant. Le label lui-m├¬me doit toujours se terminer par deux points. Voici des exemples de syntaxe de labels r├®utilisables non d├®limit├®s┬Ā:
L1:
24:
24.6:Vous pouvez m├¬me utiliser deux points tous seuls pour ces destinations de saut de tr├©s faible port├®e dans votre code.
IV-F. Sauts vers des labels┬Ā: sauts de code courts et longs▲
Il existe plusieurs instructions de saut. Certaines ne vont agir que si les flags sont dans un ├®tat particulier. On les appelle ┬½┬Āinstructions de saut conditionnel┬Ā┬╗. D'autres, telles que l'instruction JMP, sauteront toujours ├Ā la destination sp├®cifi├®e ind├®pendamment de l'├®tat des flags. On trouve ├®galement les instructions de boucle et leur variante conditionnelle qui s'interrompt si ECX = 0. Enfin, il y a l'instruction CALL qui effectue un saut puis un retour au terme de la proc├®dure appel├®e. Toutes ces instructions ont besoin d'un label pr├®cisant leur destination.
IV-F-1. Les indicateurs de direction▲
Afin de rendre votre script source plus lisible, GoAsm propose des indicateurs de direction pour pr├®ciser la direction du saut. L'indicateur de direction ┬½┬Āretour┬Ā┬╗ est facultative. Par exemple, en utilisant des labels r├®utilisables ├Ā port├®e locale┬Ā:
JZ >.fin ; sauter en avant ├Ā .fin
JMP >.exit ; sauter en avant ├Ā .exit
LOOP .looptop ; boucle arri├©re vers .looptop
LOOP <.looptop ; boucle arri├©re vers .looptop (forme alternative)Voici un exemple en utilisant des labels non d├®limit├®s┬Ā:
JZ >L10 ; saut en avant ├Ā L10
JNC L3 ; saut en arri├©re ├Ā L3
JNC L3 ; saut en arri├©re ├Ā L3 (forme alternative)
JMP 100 ; saut en l'arri├©re ├Ā 100IV-F-2. Sauts vers des labels uniques▲
Ceux-ci sont trait├®s diff├®remment, selon que le saut est effectu├® ou non en utilisant un mn├®monique de saut conditionnel.
IV-F-3. Sauts conditionnels ├Ā des labels uniques▲
Vous pouvez coder des sauts conditionnels ├Ā des labels uniques de la m├¬me mani├©re que vous le feriez pour des sauts ├Ā des labels de port├®e locale ou non d├®limit├®e. En d'autres termes, utilisez l'indicateur vers l'avant ┬½┬Ā>┬Ā┬╗ si le saut est plus avant dans le script source. En option, vous pouvez utiliser l'indicateur vers l'arri├©re ┬½┬Ā<┬Ā┬╗ pour signifier que le saut est ├Ā un lieu en amont dans le script source, ou vous pouvez l'omettre. Fondamentalement, GoAsm vous permettra de ne pas sauter d'un fichier en utilisant un saut conditionnel. Ainsi, au lieu de coder┬Ā:
JZ EXTERNALLABELvous pourriez ├®crire
JNZ >
JMP EXTERNALLABELCeci, pour faciliter la v├®rification des erreurs. GoAsm suppose qu'un saut conditionnel est cens├® aboutir ├Ā un endroit ├Ā l'int├®rieur du script source existant.
IV-F-4. Sauts inconditionnels ├Ā destination de labels uniques▲
Vous pouvez utiliser un indicateur de direction pour ces sauts si vous le souhaitez, mais vous n'y ├¬tes pas contraint. L'indicateur de direction ne fera que dire ├Ā GoAsm de rechercher le label dans le script source. GoAsm ne dira pas au linker de chercher le label dans d'autres scripts source. Si vous n'utilisez pas d'indicateur de direction, GoAsm va n├®anmoins trouver le label s'il existe dans le script source, mais, si tel n'est pas le cas, il va dire au linker de le rechercher dans d'autres scripts source. Par exemple┬Ā:
JMP LABEL ; cherche le label dans tous les scripts source
JMP <INTERNALLABEL1 ; ne cherche le label qu'en amont dans le script source
JM >INTERNALLABEL2 ; ne cherche le label qu'en aval dans le script sourceIV-F-5. Sauts vers les deux points▲
La ponctuation consistant en deux points isol├®s est trait├®e comme un label non d├®limit├® et peut ├¬tre utilis├®e pour vos sauts les moins significatifs, par exemple┬Ā:
CALL PROCESS
LOOPZ <ou
CMP EAX,EDX
JZ >
CALL PROCESS
:
RETIV-F-6. L'int├®r├¬t de sauts longs ou courts▲
Un saut court utilise un m├®canisme de d├®placement relatif qui tient seulement sur deux octets. Il invite le processeur ├Ā revenir en arri├©re ou ├Ā aller vers l'avant avec une amplitude de +127 octets ou -128 octets par rapport ├Ā la position courante. L'amplitude du saut est contenue dans le deuxi├©me octet de l'opcode, ce qui en explique la limitation aux valeurs pr├®c├®demment indiqu├®es.
Pour surmonter cette contrainte, il existe une variante de cette instruction contenant six octets. Il s'agit de la forme longue de l'instruction de saut relatif.
L'utilisation de sauts courts non seulement resserre votre code mais en augmente ├®galement la vitesse d'ex├®cution parce que le processeur doit lire et ex├®cuter moins d'octets. Cette consid├®ration pourra ├¬tre d├®terminante dans les structures d'instructions en boucle qui sont ex├®cut├®es plusieurs fois.
IV-F-7. Comment forcer GoAsm ├Ā coder un saut long▲
Utilisez soit l'op├®rateur LONG, soit << ou >>. Par exemple┬Ā:
JZ >>.fin ; long saut avant vers .fin
JZ LONG >.fin ; long saut avant vers .fin (variante)
JC <<A1 ; long saut arri├©re vers A1
JC LONG A1 ; long saut arri├©re vers A1 (variante)
JC LONG <A1 ; long saut arri├©re vers A1 (variante)Notez qu'il n'y a aucune forme longue de l'instruction LOOP et de ses variantes, ni de JECXZ. Si vous avez besoin d'un saut long de ces instructions utiliser ├Ā la place┬Ā:
DEC ECX
JNZ LONG L2 ; saut long rempla├¦ant LOOP
OR ECX, ECX ; test de ECX = 0
JZ LONG >L44 ; saut long rempla├¦ant JECXZIV-F-8. Principes de codage des sauts longs ou courts▲
GoAsm essaie toujours de g├®n├®rer le plus petit code possible, en coh├®rence avec le fait qu'il s'agit d'un assembleur en une passe. Voici les r├©gles observ├®es┬Ā:
- GoAsm codera toujours un saut long si c'est sp├®cifi├® (pour les instructions qui admettent cette possibilit├®)┬Ā;
- pour les sauts en amont vers des labels uniques et port├®e locale, GoAsm codera automatiquement un saut court si c'est possible, sinon, ├Ā d├®faut, un saut long┬Ā;
- pour les sauts en amont vers des labels non d├®limit├®s, GoAsm codera un saut court┬Ā;
- pour les sauts en aval vers des labels non d├®limit├®s et aussi pour des labels de port├®e locale, GoAsm codera un saut court┬Ā;
- pour les sauts en aval vers des labels uniques, GoAsm va coder un saut long.
GoAsm affichera une erreur si un court saut est sp├®cifi├®, mais ne peut ├¬tre atteint. Ceci, pour vous assurer que vous n'avez pas commis d'erreur dans votre script source. Par exemple, vous pourriez avoir cod├® un saut court tout en oubliant d'ajouter la destination du saut ├Ā votre script source.
IV-G. Acc├©s aux labels▲
IV-G-1. Obtention de l'adresse d'un label (ADDR et OFFSET)▲
Les op├®rateurs ADDR et OFFSET permettent d'obtenir l'adresse d'un label. Dans l'ex├®cutable final sous Windows, ils fournissent la distance du label par rapport au d├®but de la section, ainsi que la position de la section dans la m├®moire virtuelle. En d'autres termes, c'est l'adresse du label en m├®moire lorsque l'ex├®cutable est charg├® et s'ex├®cute.
Voici des exemples d'utilisation de labels uniques┬Ā:
MOV ESI, ADDR Process_dabs ; ESI = adresse de code du label Process_dabs
MOV ESI, ADDR Hello2 ; ESI = adresse de la chaîne avec le label Hello2
MOV ESI, ADDR HelloX+10h ; ESI = adresse 16 octets au-del├Ā du label HelloXExemple utilisant un label r├®utilisable de port├®e locale┬Ā:
MOV ESI, ADDR CALCULATE.fin ; ESI = adresse de code du label .fin
; dans la proc├®dure CALCULATEExemple utilisant une structure formelle┬Ā:
MOV ESI, ADDR Lv1.pszText ; ESI = adresse du membre psztext dans
; la structure formelle Lv1Pour le code 64 bits, notez qu'un PUSH, ARG, ou MOV vers la m├®moire d'un ADDR ou d'un OFFSET concernant un label non local (les labels locaux sont g├®r├®s diff├®remment) fera usage du registre R11 et profitera de l'adressage relatif RIP plus court de l'instruction LEA de la mani├©re suivante┬Ā:
LEA R11, ADDR Non_Local_Label
PUSH R11
LEA R11, ADDR Non_Local_Label
MOV [MEMORY64], R11Ce sera ├®galement le cas avec INVOKE en passant les arguments avec ADDR, qui comprend ├®galement l'utilisation de pointeurs vers une cha├«ne ou une donn├®e brute (ex. 'Bonjour' ou <'H', 'i', 0>).
IV-G-2. Lecture de donn├®es ├Ā partir de l'emplacement point├® par un label▲
La lecture des donn├®es ├Ā partir de l'endroit point├® par un label est tout ├Ā fait diff├®rente de l'action consistant ├Ā obtenir l'adresse du m├¬me label. Ici vous lisez la valeur de donn├®es dans le domaine de la m├®moire concern├®e. Cela doit ├¬tre fait ├Ā l'aide des crochets. Exemples┬Ā:
MOV ESI, ADDR Hello1 ; ESI = adresse du label Hello1
MOV EAX, [ESI] ; EAX = valeur m├®moire ├Ā l'emplacement du label Hello1ou, ce qui revient au m├¬me┬Ā:
MOV EAX, [Hello1] ; EAX = valeur m├®moire ├Ā l'emplacement du label Hello1IV-G-3. ├ēcriture ├Ā l'emplacement point├® par un label▲
Ici, vous provoquez une ├®criture de donn├®e comme suit┬Ā:
MOV ESI, ADDR Hello1 ; ESI = adresse du label Hello1
MOV [ESI], EAX ; contenu de EAX dans la m├®moire dword correspondant au label Hello1ou ce qui revient au m├¬me┬Ā:
MOV [Hello1], EAX ; contenu de EAX dans la m├®moire dword correspondant au label Hello1IV-G-4. Lecture et ├®criture sur des labels utilisant un d├®placement▲
Supposons que vous ayez une structure simple de donn├®es d├®clar├®e comme suit┬Ā:
PARAM_DATA DD 0 ; +0h
DD 0 ; +4h
DD 55h ; +8h
DD 0 ; +0Ch
DD 0 ; +10hVous pouvez utiliser le label pour lire et ├®crire dans une partie particuli├©re de la structure en utilisant une valeur de d├®placement conform├®ment ├Ā l'exemple suivant┬Ā:
MOV ESI, ADDR PARAM_DATA ; ESI = offset de PARAM_DATA
MOV EAX, [ESI+8h] ; EAX = lecture du troisi├©me DWORD de PARAM_DATA
MOV [ESI+8h], EDX ; on remplace ce 3e DWORD par le contenu de EDXou ce qui fait la m├¬me chose┬Ā:
MOV EAX, [PARAM_DATA+8h] ; EAX = lecture du troisi├©me DWORD de PARAM_DATA
MOV [PARAM_DATA+8h], EDX ; on remplace ce 3e DWORD par le contenu de EDXLa valeur de d├®placement peut prendre toute valeur jusqu'├Ā 0FFFFFFFFh. Elle peut ├¬tre positive ou n├®gative. Les ├®l├®ments non num├®riques doivent ├¬tre s├®par├®s par le signe plus.
Voir la section structures - diff├®rents types et utilisation.
IV-G-5. Lecture et ├®criture sur des labels utilisant l'indexation▲
Supposons que vous ayez 16 DWords de donn├®es d├®clar├®s comme suit┬Ā:
PARAM_DATA DD 10h DUP 0Vous pouvez utiliser l'indexation (scaling) en compl├®ment du registre d'index comme suit┬Ā:
MOV ESI, ADDR PARAM_DATA
MOV EAX, [ESI+ECX*4] ; EAX = lecture du dword point├® par ESI et index├® par ECX
MOV [ESI+ECX*4], EDX ; insertion de EDX en remplacement du dword lu pr├®c├®demmentou, ce qui revient au m├¬me┬Ā:
MOV EAX, [PARAM_DATA+ECX*4] ; EAX = lecture du dword point├® par ESI et index├® par ECX
MOV [PARAM_DATA+ECX*4], EDX ; insertion de EDX en remplacement du dword lu pr├®c├®demmentVous pouvez utiliser une indexation de 0, 2, 4 ou 8. Les instructions qui suivent sont toutes valides┬Ā:
MOVZX EAX, B[PARAM_DATA+ECX] ; octet point├® par [PARAM_DATA+ECX] avec ext. ├Ā 0 sur EAX
MOVZX EAX, W[PARAM_DATA+ECX*2] ; mot point├® par [PARAM_DATA+ECX*2] avec ext. ├Ā 0 sur EAX
MOV Q[PARAM_DATA+ECX*8], EDX ; insertion EDX dans Qword point├® par [PARAM_DATA+ECX*8]Les lettres B, W et Q pr├®c├®dant le crochet ouvrant sont des abr├®viations sp├®cifiques ├Ā GoAsm d├®crivant respectivement les modificateurs de type Byte Ptr, Word Ptr et Qword Ptr.
Les ├®l├®ments non num├®riques doivent ├¬tre s├®par├®s par le signe plus.
Dans le codage 32 bits, seuls les registres 32 bits ├Ā usage g├®n├®ral peuvent ├¬tre utilis├®s comme registre d'index - EAX, EBX, ECX, EDI, EDX, ESI ou EBP. Vous ne pouvez pas utiliser ESP en tant que registre d'index.
En codage 64 bits, vous pouvez utiliser les registres 32 bits ├Ā usage g├®n├®ral ou les nouveaux registres en mode d'adressage 32 bits (R8D ├Ā R15D). Vous pouvez ├®galement utiliser les extensions 64 bits des registres ├Ā usage g├®n├®ral - RAX, RBX, RCX, RDI, RDX, RSI, ou RBP -, et les nouveaux registres 64 bits R8 ├Ā R15. Vous ne pouvez pas utiliser RSP en tant que registre d'index.
Notez que les instructions ci-dessus qui utilisent PARAM_DATA et l'indexation n'utilisent pas l'adressage relatif RIP, de sorte que la base de l'image doit être bien en dessous 7FFFFFFFh.
IV-G-6. Lecture et ├®criture sur des labels utilisant indexation et d├®placement▲
Supposons que vous ayez 24 DWords de donn├®es d├®clar├®s comme suit, o├╣ le dernier DWord dans chaque cas d├®tient le r├®sultat requis┬Ā:
PARAM_DATA DD 19h, 0, 0, 22222h
DD 1Ah, 0, 0, 44444h
DD 1Bh, 0, 0, 66666h
DD 1Ch, 0, 0, 88888h
DD 1Dh, 0, 0, 0AAAAAh
DD 1Eh, 0, 0, 0CCCCChAlors, vous pouvez utiliser une indexation (scaling) et un d├®placement de la mani├©re suivante┬Ā:
MOV ESI, ADDR PARAM_DATA ; adresse de d├®part de la table de Dwords
CMP EAX, [ESI+ECX*4] ; voir si EAX = dword point├® par cette table
JNZ > L2 ; non
MOV EDX, [ESI+ECX*4+0Ch] ; oui, alors on r├®cup├©re le r├®sultat dans EDXou, plus directement, et ce qui revient au m├¬me┬Ā:
CMP EAX, [PARAM_DATA+ECX*4] ; voir si EAX = dword point├® par cette table
JNZ > L2 ; non
MOV EDX, [PARAM_DATA+ECX*4+0Ch] ; oui, alors on r├®cup├©re le r├®sultat dans EDXVous devez utiliser l'indexation au moyen des seules valeurs 0, 2, 4 ou 8. La valeur de d├®placement peut ├¬tre toute valeur allant jusqu'├Ā 0FFFFFFFFh. Dans votre script source, cette valeur peut ├¬tre positive ou n├®gative. Les ├®l├®ments non num├®riques doivent ├¬tre s├®par├®s par le signe plus.
Dans le codage 32 bits, seuls les registres 32 bits ├Ā usage g├®n├®ral peuvent ├¬tre utilis├®s comme registres d'index - EAX, EBX, ECX, EDI, EDX, ESI ou EBP. Vous ne pouvez pas utiliser ESP en tant que registre d'index.
En codage 64 bits, vous pouvez utiliser les registres 32 bits ├Ā usage g├®n├®ral ou les nouveaux registres en mode d'adressage 32 bits (R8D ├Ā R15D). Vous pouvez ├®galement utiliser les extensions 64 bits des registres ├Ā usage g├®n├®ral - RAX, RBX, RCX, RDI, RDX, RSI, ou RBP - ainsi que les nouveaux registres 64 bits R8 ├Ā R15. Vous ne pouvez pas utiliser RSP en tant que registre d'index.
Notez que les instructions ci-dessus qui utilisent PARAM_DATA et l'indexation n'utilisent pas l'adressage relatif RIP, de sorte que la base de l'image doit être bien en dessous 7FFFFFFFh.
IV-H. Appel (ou Saut) ├Ā des proc├®dures▲
IV-H-1. Qu'est-ce qu'une ┬½┬Āproc├®dure┬Ā┬╗┬Ā?▲
Une proc├®dure est une s├®rie d'instructions de code avec un label auquel l'ex├®cution peut ├¬tre transf├®r├®e. Les proc├®dures peuvent ├®galement ├¬tre nomm├®es ┬½┬Āfonction┬Ā┬╗, ┬½┬Āroutine┬Ā┬╗ ou ┬½┬Āsous-programme┬Ā┬╗. Voici un exemple de proc├®dure courte┬Ā:
PROCESS_HASH: ; label permettant d'atteindre la proc├®dure
XOR EAX, EAX
MOV EDX, ESI
CALL PH23
MOV EDX, 866h ; retour de la proc├®dure avec EDX = 866h
RETIV-H-2. Transfert de l'ex├®cution ├Ā une proc├®dure▲
Habituellement, l'ex├®cution est transf├®r├®e ├Ā la proc├®dure par l'utilisation de l'instruction CALL. Celle-ci impose tout d'abord au processeur de pousser sur la pile (PUSH) la position dans le code juste apr├©s l'instruction CALL, puis de poursuivre l'ex├®cution dans la proc├®dure appel├®e. ├Ć la fin de la proc├®dure, on trouve une instruction RET (abr├®g├® de RETURN) qui invite le processeur ├Ā retirer de la pile (POP) la position dans le code imm├®diatement apr├©s le CALL m├®moris├®e pr├®c├®demment, ├Ā placer cette valeur dans le pointeur d'instructions EIP, puis ├Ā reprendre l'ex├®cution ├Ā partir de ce point.
Exceptionnellement l'ex├®cution peut ├¬tre transf├®r├®e ├Ā la proc├®dure par l'utilisation de l'instruction JMP. ├Ć la fin de la proc├®dure, on peut ├®galement rencontrer une autre instruction JMP, comme dans l'exemple qui suit┬Ā:
PROCESS_HASH:
XOR EAX, EAX
MOV EDX, ESI
CALL PH23 ; transf├©re l'ex├®cution ├Ā la proc├®dure PH23 et retourne apr├©s celle-ci
MOV EDX, 866h ; retour de la proc├®dure avec EDX = 866h
JMP > SOMEWHERE_ELSE
START: ; point d'entr├®e de l'ex├®cution
JMP PROCESS_HASHIV-H-3. Syntaxe de CALL et JMP en direction d'une proc├®dure▲
La mani├©re habituelle de faire un CALL ou un JMP en direction d'une proc├®dure est d'utiliser le label de code marquant le d├®but de la proc├®dure. Par exemple┬Ā:
CALL PROCESS_HASH
JMP PROCESS_HASHParfois, l'adresse de la proc├®dure destination peut ├¬tre conserv├®e en m├®moire, point├®e par un label ou un registre ou m├¬me localis├®e ├Ā un endroit connu dans la m├®moire ainsi que l'illustrent les diff├®rents exemples qui suivent┬Ā:
CALL [PROCADDRESS]
CALL [PROCTABLE+20h]
CALL [ESI]
CALL [ESI+EDX]
JMP [4000000h]Il peut arriver enfin que l'adresse de la proc├®dure destination soit d├®tenue par un registre, auquel cas la syntaxe du CALL ou du JMP peut prendre la forme suivante┬Ā:
CALL EAX
JMP EDIIV-H-4. Syntaxes plus complexes du CALL et du JMP▲
Nous esp├®rons que vous n'aurez jamais ├Ā utiliser l'une des formes qui suivent, mais GoAsm les autorise n├®anmoins (en utilisant soit CALL, soit JMP)┬Ā:
#define Hello PROCESS_HASH
CALL Hello ; trait├® comme un CALL ├Ā PROCESS_HASH
CALL 100h ; trait├® comme un CALL ├Ā une adresse relative
CALL [HELLO3+ECX+EDX*4]
CALL [HELLO3+ECX+EDX*4+9000h]
CALL $$ ; CALL au d├®part du d├®but de la section courante
CALL $+20h ; CALL 20h octets plus loin que la position couranteIV-H-5. CALL et JMP vers des proc├®dures en dehors du fichier objet ou de la section▲
Certains assembleurs vous obligent ├Ā signaler dans votre script source au moyen de la directive EXTRN que la destination d'un appel est quelque part en dehors du fichier objet. Ils imposent ├®galement que la m├¬me destination soit marqu├®e comme GLOBAL ou PUBLIC. GoAsm vous dispense de ces subtilit├®s de syntaxe en consid├®rant que, si la destination d'un l'appel se r├®v├©le introuvable lors de l'assemblage, elle est suppos├®e relever d'un appel externe. Aussi, tous les labels qui ne sont pas locaux ou qui ont des noms r├®utilisables sont suppos├®s ├¬tre ┬½┬Āglobaux┬Ā┬╗. GoAsm fonctionne de la m├¬me mani├©re lorsqu'un appel ou un saut doit ├¬tre effectu├® ├Ā une section de code avec un autre nom.
Donc, si vous voulez appeler une proc├®dure dans un autre script source (lequel produira un autre fichier objet), appelez-la simplement de la mani├©re habituelle. De m├¬me, si vous avez une proc├®dure dans un autre ex├®cutable (g├®n├®ralement une DLL), vous pouvez proc├®der de m├¬me.
Par exemple, supposons que vous ayez ├®crit My.Dll incluant un algorithme de calcul que vous souhaitez utiliser avec le label CALCULATE. On pourrait l'appeler comme suit┬Ā:
CALL CALCULATEDans votre liste des DLL que vous donnerez ├Ā GoLink, vous mentionnerez My.Dll. GoLink cherchera d'abord le label de code CALCULATE dans les fichiers objet, mais regardera ensuite dans les DLL sp├®cifi├®es. La plupart des autres linkers regardent dans les fichiers de biblioth├©que (fichiers .lib) pour les fonctions qu'ils contiennent, ce qui signifie que vous avez ├Ā constituer un fichier lib. De toute fa├¦on, si l'on s'en tient ├Ā la syntaxe GoAsm, vous n'avez plus rien ├Ā faire dans votre script source. Si l'├®diteur de liens ne trouve pas la destination de l'appel, une erreur sera affich├®e.
Cette forme de l'appel est un appel relatif utilisant l'opcode E8.
Vous pouvez ├®galement utiliser cette forme┬Ā:
CALL [CALCULATE]Pour ce type d'appel, GoAsm utilise les opcodes FF15. Il s'agit d'un appel ├Ā une adresse absolue. Dans l'assembleur 32 bits, c'est un appel ├Ā une adresse de 32 bits, mais dans l'assembleur 64 bits, c'est un appel ├Ā une adresse de 64 bits.
Voir aussi┬Ā:
IV-I. Appel des API Windows 32 et 64 bits▲
L'appel des API Windows (qui r├®sident dans les DLL syst├©me de Windows) est tr├©s simple dans le cas o├╣ aucun param├©tre n'est requis. Par exemple dans Windows 32 bits, vous pouvez ├®crire┬Ā:
CALL GetModuleHandleou sa variante plus ├®volu├®e, qui peut ├¬tre utilis├®e soit pour Windows 32 bits ou 64 bits┬Ā:
INVOKE GetModuleHandleIl n'y a rien d'autre ├Ā mettre dans le script source. Dans la mesure o├╣ la fonction appel├®e r├®side en dehors de l'ex├®cutable que vous ├®laborez, il revient ├Ā l'├®diteur de liens de trouver la DLL qui contient la proc├®dure GetModuleHandle et il va y enregistrer le nom de la DLL ├Ā cet effet. GoLink effectuera les recherches n├®cessaires au moyen de la liste des DLL que vous fournissez.
La plupart des API Windows, cependant, attendent des param├©tres (souvent d├®sign├®s ├®galement comme ┬½┬Āarguments┬Ā┬╗) lorsqu'elles sont appel├®es. Il incombe au programmeur de s'assurer que ces param├©tres sont envoy├®s ├Ā l'API correctement. Ils contiennent les informations, ou des pointeurs vers des informations, qui indiquent ├Ā l'API ce qu'elle doit faire. Parfois, ils contiennent des adresses de zone m├®moire o├╣ l'API doit ins├®rer des informations.
La mani├©re de communiquer les param├©tres ├Ā l'API varie selon que vous assembliez en Windows 32 ou 64 bits. Chaque syst├©me d'exploitation utilise en effet des conventions d'appels sp├®cifiques qui affectent la fa├¦on dont les param├©tres sont envoy├®s et utilis├®s. Windows 32 bits utilise la convention d'appel standard (STDCALL) et Windows 64 bits utilise la convention d'appel qualifi├®e de ┬½┬Ārapide┬Ā┬╗ (FASTCALL).
GoAsm propose, dans ce but, les op├®rateurs ARG et INVOKE, qui peuvent ├¬tre utilis├®s indiff├®remment sur les plateformes 32 ou 64 bits. L'assembleur g├®n├©re le code appropri├® selon la convention d'appel utilis├®e. Si vous ├®crivez pour 32 bits avec aucune vell├®it├® de transposition en 64 bits, vous pouvez utiliser PUSH et CALL pour la transmission des param├©tres, mais si vous voulez garantir la portabilit├® de votre code vers Windows 64 bits ult├®rieurement, vous devrez les remplacer par ARG et INVOKE. Dans les codes source 32 et 64 bits vous ├¬tes libre d'utiliser CALL pour appeler des proc├®dures dans vos propres ex├®cutables, ├Ā moins que vous ne leur envoyiez les param├©tres selon l'une des conventions d'appel suivantes.
- Dans la convention d'appel STDCALL utilis├®e dans Windows 32 bits, tous les param├©tres sont mis sur la pile par l'appelant, et le pointeur de pile (ESP) est d├®plac├® vers le haut des param├©tres sur la pile. Ensuite, l'API est appel├®e. Celle-ci utilise les param├©tres sur la pile et avant de revenir, restaure cette derni├©re ├Ā l'├®quilibre en d├®pla├¦ant le pointeur de la pile ├Ā la position qu'il avait avant la mise sur la pile du premier param├©tre.
- Dans la convention d'appel FASTCALL utilis├®e dans Windows 64 bits, les quatre premiers param├©tres sont charg├®s successivement dans les registres RCX, RDX, R8 et R9 au lieu d'├¬tre mis sur la pile. Cependant, les ├®ventuels param├©tres suivants sont mis sur la pile. L'appelant doit faire en sorte que le pointeur de la pile (dans ce cas RSP) soit d├®plac├® vers le haut des param├©tres comme d'habitude, incluant notamment les quatre premiers param├©tres qui sont d├®tenus dans des registres (ce qui revient ├Ā autoriser l'API de les r├®cup├®rer sur la pile comme s'ils avaient ├®t├® mis l├Ā en premier lieu). Une autre diff├®rence est que l'API ne restaure pas la pile ├Ā l'├®quilibre avant de revenir de l'appel. Cette particularit├® facilite les choses pour les quelques API qui ne disposent pas d'un nombre fixe de param├©tres.
Si vous d├®sirez que le m├¬me script source puisse indiff├®remment ├¬tre assembl├® en 32 ou 64 bits, il est indispensable que vous envoyiez les param├©tres ├Ā l'aide de ARG puis que vous appeliez l'API en utilisant INVOKE. Un exemple simple en montre le principe┬Ā:
ARG 40h, RDX, RAX, [hwnd]
INVOKE MessageBoxALors de l'assemblage 32 bits, ARG agit de mani├©re identique ├Ā PUSH, et INVOKE produit le m├¬me effet que CALL. GoAsm accepte une instruction PUSH d'un registre ├Ā usage g├®n├®ral 64 bits, et donc PUSH RDX est trait├® de la m├¬me mani├©re que PUSH EDX au nombre de bits pr├©s, bien ├®videmment. Par cons├®quent, l'appel ci-dessus fonctionne sur les deux plateformes mais re├¦oit une traduction diff├®renci├®e selon le cas┬Ā:
; Plateforme 32 bits
PUSH 40h
PUSH EDX
PUSH EAX
PUSH [hwnd]
CALL MessageBoxA
; Plateforme 64 bits
MOV R9, 40h
MOV R8, RDX
MOV RDX, RAX
MOV RCX, [hwnd]
SUB RSP, 20h
CALL MessageBoxA
ADD RSP, 20hL'assemblage 64 bits produit, comme on peut le voir, un r├®sultat radicalement diff├®rent ├Ā partir du m├¬me code.
Voir le chapitre programmation en 64 bits pour plus de d├®tails.
IV-I-1. Appel des API Windows - Utilisation de INVOKE▲
Il est important ├®videmment d'envoyer les param├©tres ├Ā l'API dans le bon ordre. INVOKE vous aide ├Ā le faire en vous permettant de mettre les param├©tres apr├©s le nom de l'API comme en C. Cela est appr├®ciable aussi lorsque vous travaillez avec la documentation de Windows qui d├®crit toujours les param├©tres des API en utilisant la syntaxe du C. Par exemple, voici comment l'API MessageBox y est d├®crite┬Ā:
int MessageBox(
HWND hwnd, // handle of owner window
LPCTSTR lpText, // address of text in message box
LPCTSTR lpCaption, // address of title of message box
UINT uType // style of message box
);Avec INVOKE, vous pouvez respecter le m├¬me ordre, par exemple┬Ā:
INVOKE MessageBoxA, [hwnd], EAX, EDX, 40hqui ├®quivaut ├Ā┬Ā:
ARG 40h, RDX, RAX, [hwnd]
INVOKE MessageBoxANotez que ARG (comme PUSH) lit les param├©tres d'une fa├¦on, tandis que les param├©tres apr├©s INVOKE sont lus dans l'autre sens.
INVOKE et ses nombreux param├©tres peuvent ├¬tre ├®crits sur plusieurs lignes en utilisant le caract├©re de continuation┬Ā:
INVOKE CreateWindowExA, WS_EX_OVERLAPPEDWINDOW, ADDR szClassName, \
ADDR szWindowName,\
WS_OVERLAPPEDWINDOW+THING,\
100, 16, 400, 0, 0, 0, [hInstance], 0Puisque GoAsm consid├©re les param├©tres de INVOKE ├Ā partir de la fin, les erreurs vers la fin seront trouv├®es en premier.
Lors de l'utilisation de INVOKE, si vous souhaitez ranger vos param├©tres dans un mot d├®fini, alors GoAsm les r├®cup├©rera toujours dans le bon ordre. Par exemple┬Ā:
z_function_params=3,2,1
INVOKE z_function, z_function_paramsproduit le m├¬me code que┬Ā:
ARG 1,2,3
INVOKE z_functionIV-I-2. Appel des API Windows - Versions ANSI et Unicode▲
Les API Windows qui g├©rent des entr├®es ou sorties de caract├©res (g├®n├®ralement sous forme de cha├«nes de caract├©res) ont g├®n├®ralement deux versions diff├®rentes┬Ā: une version ANSI et une version Unicode. La version ANSI g├©re les cha├«nes en ANSI, standard selon lequel un seul octet de valeur 0 ├Ā 255 repr├®sente un caract├©re unique bas├® sur le jeu de caract├©res courant. Ces caract├©res sont parfois appel├®s caract├©res ┬½┬Āmultioctets┬Ā┬╗. De mani├©re on ne peut plus simple, le nom de la version ANSI de l'API se termine par un ┬½┬ĀA┬Ā┬╗ comme dans l'exemple de l'API CreateWindowEx utilis├®e ci-dessus. La version Unicode g├©re les cha├«nes en format Unicode et utilise ├Ā cet effet deux octets par caract├©re sur la base de la table standard des caract├©res Unicode. Ceux-ci sont parfois qualifi├®s de caract├©res ┬½┬Ālarges┬Ā┬╗ (wide). La version Unicode de l'API se terminera logiquement par un ┬½┬ĀW┬Ā┬╗ ├Ā la fin de son nom.
Dans votre script source, vous devez sp├®cifier les API que vous souhaitez appeler en ajoutant un ┬½┬ĀA┬Ā┬╗ ou un ┬½┬ĀW┬Ā┬╗ ├Ā la fin du nom de l'API, selon le cas. Lorsque vous soumettez votre fichier objet au linker et que ce dernier aura ├®t├® incapable de trouver l'API dans un autre ex├®cutable (ou dans les fichiers .lib si vous n'utilisez pas GoLink), c'est probablement parce que vous aurez oubli├® d'ajouter le ┬½┬ĀA┬Ā┬╗ ou le ┬½┬ĀW┬Ā┬╗. Vous pourriez ├®galement avoir omis de fournir ├Ā GoLink le nom de la DLL d├®tenant l'API (ou les fichiers .lib appropri├®s si vous n'utilisez pas GoLink).
Si vous voulez automatiser le bon appel d'API ┬½┬ĀA┬Ā┬╗ ou ┬½┬ĀW┬Ā┬╗, les r├©gles suivantes doivent ├¬tre observ├®es┬Ā:
- le programme est en version ANSI sauf sp├®cification contraire┬Ā;
- la version Unicode peut ├¬tre obtenue, soit en mettant le commutateur /d sur la ligne de commande de GoAsm, soit en ├®crivant la ligne #define UNICODE au d├®but du script source.
Voir le chapitre relatif ├Ā l'├®criture de programmes Unicode dans le volume 2 pour de plus amples informations sur le sujet.
Il n'y a aucune diff├®rence entre l'assemblage 32 et 64 bits ├Ā cet ├®gard pour la simple raison que Windows 64 bits a des versions ANSI et Unicode des API tout comme Windows 32 bits.
IV-J. Les pointeurs de cha├«nes et de donn├®es avec PUSH et ARG▲
IV-J-1. Pointeurs sur des cha├«nes termin├®es par un z├®ro▲
GoAsm permet une extension de PUSH ou ARG qui est tr├©s utile en programmation sous Windows. Souvent, dans ce cas, vous ├¬tes dans la situation d'envoyer ├Ā une API un param├©tre qui est un pointeur vers une cha├«ne se terminant par z├®ro. Supposons, par exemple, l'appel d'API suivant (en 32 bits)┬Ā:
MBTITLE DB 'Hello', 0
MBMESSAGE DB 'Click OK', 0
PUSH 40h, ADDR MBTITLE, ADDR MBMESSAGE, [hwnd]
CALL MessageBoxAPour simplifier cette syntaxe, GoAsm permet d'utiliser PUSH ou ARG comme suit tout en garantissant un r├®sultat identique┬Ā:
PUSH 40h, 'Hello', 'Click OK', [hwnd]
CALL MessageBoxAou, si vous ├®crivez un script source permettant la compatibilit├® entre les plateformes 32 et 64 bits┬Ā:
ARG 40h, 'Hello', 'Click OK', [hwnd]
INVOKE MessageBoxAet, si vous pr├®f├®rez envoyer les param├©tres par INVOKE┬Ā:
INVOKE MessageBoxA, [hwnd], 'Click OK', 'Hello', 40hVous pouvez enfin utiliser cette m├¬me facilit├® avec des cha├«nes Unicode comme suit┬Ā:
ARG 40h, L'Hello', L'Click OK', [hwnd]
INVOKE MessageBoxWou
INVOKE MessageBoxW, [hwnd], L'Click OK', L'Hello', 40hLorsque vous utilisez l'une de ces formes, la cha├«ne sera toujours termin├®e par z├®ro. Il se trouve en effet que GoAsm place la cha├«ne dans la section const s'il y en a une (la section data s'il y en a une, sinon, ├Ā d├®faut, dans la section de code) et y ajoute un terminateur null. Puis, GoAsm cr├®e l'instruction correcte et lui donne un pointeur vers la cha├«ne. Aucun symbole n'est produit ├Ā des fins de d├®bogage.
En assemblage 64 bits, GoAsm garantit que les cha├«nes Unicode sont align├®es sur la limite de mot requise par le syst├©me.
Notez que ceci est similaire ├Ā PUSH ADDR et fera usage du registre R11 tout en tirant avantage de la taille r├®duite de l'adressage relatif RIP de l'instruction LEA.
IV-J-2. Mise en pile de pointeurs dans des donn├®es brutes▲
Vous pouvez faire la m├¬me chose que pr├®c├®demment avec les donn├®es brutes ordinaires (en octets) en utilisant les op├®rateurs < et >. Par exemple┬Ā:
PUSH <23, 24, 25> ; mise en pile d'un pointeur des octets 23,24,25ou
PUSH <23, 6 DUP 20h, 23> ; mise en pile d'un pointeur des octets 23,6 espaces, puis 23ou
PUSH <'Hi', 0Dh, 0Ah, 'There', 0> ; mise en pile d'un pointeur sur la cha├«ne termin├®e
; par un z├®ro sur 2 lignes (RC+LF au milieu)On peut ├®galement utiliser les op├®rateurs < et > de cette mani├©re avec ARG et apr├©s INVOKE. Dans ce cas de figure, GoAsm place la d├®claration des donn├®es entre les op├®rateurs < et > dans la section const s'il y en a une (ou la section data s'il y en a une, sinon ├Ā d├®faut, dans la section de code). Puis GoAsm cr├®e l'instruction appropri├®e et calcule un pointeur vers les donn├®es. Aucun symbole n'est constitu├® ├Ā des fins de d├®bogage.
Notez que lorsque vous utilisez les op├®rateurs < et > de cette mani├©re, aucun terminateur Null n'est ajout├® aux cha├«nes.
Lors de l'assemblage 64 bits, GoAsm garantit que les donn├®es sont align├®es sur une limite de mot rendue n├®cessaire par le syst├©me si les donn├®es contiennent des cha├«nes Unicode.
IV-K. M├®morisation de pointeurs de cha├«ne et donn├®es dans des registres▲
Vous pouvez ├®galement d├®clarer des cha├«nes termin├®es par un z├®ro et des donn├®es tout en ├®tablissant simultan├®ment leurs pointeurs dans des registres ├Ā l'aide de la syntaxe suivante┬Ā:
MOV EAX, ADDR 'This is a string'
MOV EAX, ADDR <'String',0Dh,0Ah>Lorsque GoAsm traite ce type de code, il constitue une cha├«ne termin├®e par un z├®ro - sans que ce dernier ne soit sp├®cifi├® - ou les donn├®es entre les op├®rateurs < et > dans la section const. s'il y en a une (ou la section data si elle existe, sinon, dans la section code). Puis, GoAsm fournit le pointeur des donn├®es ainsi cr├®├®es ├Ā l'instruction. Aucun symbole n'est produit ├Ā des fins de d├®bogage.
Notez que lorsque vous utilisez les op├®rateurs < et >, aucun terminateur Null n'est rajout├® aux cha├«nes.
Notez ├®galement comment ceci diff├©re de la syntaxe relative au chargement de caract├©res imm├®diats dans un registre. Cette diff├®rence r├®side dans l'utilisation de l'op├®rateur ADDR.
Tout ceci fonctionne de la m├¬me fa├¦on en programmation 64 bits, sauf que GoAsm garantit qu'une cha├«ne ou une donn├®e Unicode sont align├®es WORD dans la m├®moire ainsi que le requiert le syst├©me.
Notez que ceci est similaire ├Ā PUSH ADDR et fera usage du registre R11 tout en tirant avantage de la taille r├®duite de l'adressage relatif RIP de l'instruction LEA.
IV-L. Utilisation de caract├©res imm├®diats dans le code▲
GoAsm ne renverse pas l'ordre des Words et DWords m├®moris├®s sous forme de caract├©res imm├®diats comme MASM le pratique. Ainsi, GoAsm utilise-t-il le format suivant┬Ā:
MOV AL, '1'
MOV AX, '12' ; consid├®r├® comme des octets - 1 en AL, 2 en AH
MOV EAX, 'ABCD' ; consid├®r├® comme des octets - A en premier, puis B puis C puis D (AL)Cela facilite l'ajout des cha├«nes courtes ├Ā la m├®moire. Par exemple, pour ajouter l'extension .fil ├Ā un nom de fichier stock├® en m├®moire, vous pouvez coder┬Ā:
MOV [EDI], '.fil' ;ou
MOV EAX, '.fil'
MOV [EDI], EAXet non pas┬Ā:
MOV [EDI], 'lif.' ;ou
MOV EAX, 'lif.'
MOV [EDI], EAXL'instruction CMP (comparaison) travaille de la m├¬me mani├©re┬Ā:
CMP AL, '1'
CMP EAX, 'ABCD'
CMP [EDI], '.fil'Cela ne change pas l'ordre inverse habituel dans les op├®randes qui ne seraient pas entre guillemets. Ainsi lorsque vous souhaitez ajouter un retour chariot, puis un saut de ligne au texte que vous souhaitez r├®utiliser┬Ā:
MOV AX, 0A0Dh
STOSWIci, le retour chariot (0Dh) qui est en AL, est charg├® le premier en m├®moire, puis le saut de ligne (0Ah) dans AH est charg├® en m├®moire d'adresse imm├®diatement sup├®rieure.
Si la cha├«ne est plus courte que le type du registre ou de la m├®moire, des z├®ros absolus de comblement sont ajout├®s automatiquement┬Ā:
MOV EAX, 'ABC' ; code A, puis B, puis C, puis z├®roLors de l'├®criture du code source pour les programmes Unicode vous pouvez garantir que les caract├©res imm├®diats sont Unicode ou, si n├®cessaire, bascul├®s d'ANSI en Unicode. Voir, ├Ā ce sujet, les sections ┬½┬ĀUtilisation de la cha├«ne correcte dans les valeurs imm├®diates sous guillemets┬Ā┬╗ et ┬½┬Ācommutation des cha├«nes sous guillemets et imm├®diates┬Ā┬╗ dans le chapitre du volume 2 consacr├® ├Ā l'Unicode.
En programmation 64 bits, vous pouvez utiliser les registres 64 bits pour y stocker des cha├«nes imm├®diates de 8 caract├©res de long, par exemple┬Ā:
MOV RAX, 'Saturday'Cependant, l'instruction CMP n'admet pas les valeurs imm├®diates sup├®rieures ├Ā 32 bits, de sorte que par exemple
CMP RAX, 'Saturday'affiche une erreur. En mode 64 bits, seules sont autoris├®es les comparaisons entre registre et m├®moire et entre deux registres sur cette variante de l'instruction CMP.
IV-M. Indicateurs de Type▲
IV-M-1. Int├®r├¬t et syntaxe▲
Penchons-nous sur l'instruction
MOV [ESI], 20hElle consiste ├Ā stocker le nombre 20h ├Ā l'adresse m├®moire sp├®cifi├®e par le contenu du registre ESI. Mais une question importante appara├«t imm├®diatement. Le nombre doit-il ├¬tre charg├® comme un octet, un mot, un DWord ou tout autre type de donn├®e┬Ā? De la r├®ponse d├®pend le nombre d'octets de m├®moire - ├Ā partir de l'adresse fournie par ESI - qui doivent ├¬tre modifi├®s. Tous les assembleurs exigent donc ├Ā cet effet un indicateur de type pour lever l'ambigu├»t├® mais avec une syntaxe sensiblement diff├®rente ainsi que le montrent les exemples suivants (en utilisant DWORD comme exemple)┬Ā:
MOV DWORD PTR [ESI], 20h ; MASM
MOV DWORD [ESI], 20h ; NASM
MOV D[ESI], 20h ; A386GoAsm utilise la syntaxe A386 qui n├®cessite beaucoup moins de frappe de sorte que les indicateurs de type rencontr├®s sont┬Ā:
- B signifie Byte (1 octet)┬Ā;
- W signifie Word (2 octets)┬Ā;
- D signifie DWord (4 octets)┬Ā;
- Q signifie QWord (8 octets)┬Ā;
- T signifie TWord (10 octets).
Vous pouvez ├®galement utiliser ces deux indicateurs de type commutable┬Ā:
- S est un indicateur dont la taille varie selon les caract├©res utilis├®s┬Ā: 1 (octet) en ANSI et 2 (octets) en Unicode.
MOV S[EDI], 0 ; ins├©re un simple z├®ro si ANSI, un double z├®ro si Unicode.Voir la section ┬½┬ĀUtilisation de l'indicateur de type commutable pour Unicode/ANSI┬Ā┬╗ dans le chapitre du volume 2 consacr├® ├Ā l'Unicode.
- P est un indicateur dont la taille varie selon le format 32/64 bits (par d├®faut, 4 pour 32 bits, 8 pour 64 bits)┬Ā:
MOV P[RDI], 0 ; 0 sur qword ├Ā RDI si 64 bits, 0 sur dword ├Ā EDI si 32 bitsVoir la section utilisation de l'indicateur de type commutable pour 32/64 bits.
IV-M-2. L'indicateur de type est ├®galement requis pour les r├®f├®rences m├®moire nominatives▲
Comme NASM, GoAsm ne v├®rifie pas les types, de sorte qu'il ne peut conna├«tre la taille d'une op├®ration telle que celle-ci┬Ā:
INC [COUNT]Ici, GoAsm ignore tout de la taille de COUNT qui peut ├¬tre indiff├®remment un octet, un mot (Word), un double-mot (DWord) ou un quadruple mot (QWord) et ceci, bien que la variable ait ├®t├® pr├®alablement d├®clar├®e. Par cons├®quent, vous devez imp├®rativement pr├®ciser le type de l'op├®ration, par exemple┬Ā:
INC B[COUNT]Bien que cette obligation impose un peu plus de travail au programmeur, force est de reconna├«tre que le script source s'en trouve plus facile ├Ā lire et ├Ā comprendre, puisque vous pouvez imm├®diatement voir la taille de l'op├®ration de l'instruction, plut├┤t que de devoir explorer l'ensemble du programme pour vous enqu├®rir de la taille avec laquelle COUNT a ├®t├® d├®clar├®e. Du reste, l'utilisation d'indications de type tenant en une seule lettre compense le c├┤t├® fastidieux induit par la r├®p├®tition de ces indications.
IV-M-3. Quelles instructions requi├©rent un indicateur de type┬Ā?▲
G├®n├®ralement toutes les instructions o├╣ la taille de l'op├®ration n'est pas implicite sont concern├®es. Certains des exemples qui suivent utilisent des r├®f├®rences de m├®moire nominatives alors que d'autres pr├®f├©rent des r├®f├®rences de m├®moire soutenues par des registres┬Ā:
AND B[MAINFLAG], 0FEh
ADC W[EAX], 66h
ADD D[MEM_AREA], 66h
BT D[EBX], 31D
CMP D[HELLOWORD], 0Dh
DEC D[ECX]
DIV B[HELLO]
INC D[EDX]
MOV B[MEM_AREA], 23h
MOVSX EDX, B[EDI]
MUL B[HELLO]
NEG W[ESI]
NOT D[HELLO3]
OR B[MAINFLAG], 1h
SETZ B[BYTETEST]
SHL W[IAMAWORD], 23h
SHL D[IAMADWORD], CL
SUB D[EBP+10h], 20D
TEST B[ESP+4h], 1h
XOR D[IMAWORD], 11111111hEt, en programmation 64 bits, vous pouvez ├®galement voir, par exemple┬Ā:
ADC W[RAX], 66h
BT D[R12], 31D
INC Q[RDX]
NEG W[R15D]IV-M-4. Les instructions qui ne requi├©rent pas d'indicateur de type▲
Entrent dans cette cat├®gorie les op├®rations dont la taille de l'op├®ration est ├®vidente, du fait de l'utilisation d'un registre, par exemple┬Ā:
AND [MAINFLAG], CL
CMP [HELLOWORD], EDI
MOV [IAMABYTE], AL
MOV [IAMADWORD], ESI
OR [MAINFLAG], BH
XCHG CL, [ESI]De fait, aucune des instructions MMX, XMM ou 3DNow! ne n├®cessite un indicateur de type. Il en va de m├¬me pour plusieurs des instructions en virgule flottante x87. Les autres peuvent prendre plus d'une taille d'op├®rande. Il y a aussi plusieurs instructions qui n'acceptent qu'une taille d'op├®rande, de sorte qu'avec celles-ci, l'indicateur de type n'est pas requis. Il en va Ainsi, des instructions CALL, JMP, PUSH et POP qui ne supportent qu'un DWord (en 32 bits). Voir cependant la section relative aux demi-op├®rations de pile concernant l'utilisation de PUSHW et POPW. Enfin, certaines des instructions les moins courantes n'ont pas besoin d'un indicateur de type, par exemple ARPL, BOUND, BSF, BSR, CMOV (sous toutes ses formes), CMPXCHG et CMPXCHG8B.
IV-N. Instructions r├®p├®t├®es▲
Les instructions r├®p├®t├®es sont possibles pour PUSH, POP, INC, DEC, et bien s├╗r lors de la d├®claration des donn├®es, par exemple┬Ā:
PUSH 0, 23h, [hwnd], ADDR lParam, EAX
POP EAX, [EBP+2Ch], [hwnd]
DEC ECX, EDX, [COUNT]
INC [EBP+10h], EDI
DB 23h, 24h, 25hLes instructions ici sont toujours assembl├®es de gauche ├Ā droite.
IV-O. Nombres et arithm├®tique▲
IV-O-1. Nombres▲
La plupart des assembleurs utilisent la syntaxe suivante pour les nombres┬Ā:
66ABCDEh ; nombre hexad├®cimal
34567789 ; nombre d├®cimal
1100011B ; nombre binaire
1.0 ; nombre r├®el
1.0E0 ; nombre r├®el (autre forme)GoAsm accepte ces nombres, mais prend ├®galement en charge les formats suivants┬Ā:
9999999D ; nombre d├®cimal
0x456789 ; nombre hexad├®cimalUn nombre hexad├®cimal qui commence par une lettre (A ├Ā F caract├®risant, par convention, les valeurs d├®cimales de 10 ├Ā 15) doit imp├®rativement ├¬tre pr├®c├®d├® d'un z├®ro, par exemple┬Ā:
0A789ABCDhou
0xA789ABCDIV-O-2. Arithm├®tique ▲
GoAsm peut effectuer des op├®rations arithm├®tiques limit├®es ├Ā l'int├®rieur des d├®clarations de donn├®es, du quantitatif de DUP, des d├®finitions, lors de la d├®claration de d├®finitions, lors de l'utilisation des d├®finitions, et dans des op├®randes des instructions de code. Vous n'├¬tes pas autoris├® ├Ā utiliser le signe de multiplication (ast├®risque) ├Ā l'int├®rieur de crochets autrement que lors de l'utilisation d'un registre d'index.
Soyez prudent en utilisant les op├®rateurs logiques OR, AND et NOT puisque ceux-ci sont ├Ā la fois des mn├®moniques processeur et des directives de l'assembleur. Bien que GoAsm sache les distinguer dans leurs deux acceptions, il vous est possible de recourir ├Ā une ├®criture distinctive en utilisant, pour les directives, les symboles | pour OR, & pour AND, et┬Ā! pour NOT.
Les op├®rations arithm├®tiques entre parenth├©ses sont effectu├®es en premier lieu, sinon les calculs sont effectu├®s strictement de gauche ├Ā droite. Voici quelques exemples┬Ā:
DB 2*3
DB (2+30h)/(2+1)
DD (2000h+40h-20h)/2
DD SIZEOF HELLO/2
DD 444444h & 226222h
DB 20h/2 DUP 44h
DB 6+2 DUP 0
#define globule (2*3)/2
DB globule
DD globule|100h
DD 2D00h>>8
DQ 2D00h<<48
MOV EAX, globule|100h
MOV EAX, SIZEOF HELLO*2
MOV EAX, ADDR HELLO+10h
MOV EAX, 0x68+0x69-0x70
MOV EAX, [MemName+0x68+0x69-0x70]
MOV EAX, [ESI*4+45000h]
MOV EAX, [ESI*4+SIZEOF HELLO/2]
MOV EAX, 8+8*2 ; r├®sultat = 32
MOV EAX, 8+(8*2) ; r├®sultat = 24Le quotient des divisions, lorsque cette op├®ration est utilis├®e, est arrondi selon la r├©gle de l'entier le plus proche ainsi que le montrent les exemples suivants┬Ā:
MOV EAX, 32/3 ; met 11 dans EAX
MOV EAX, 31/3 ; met 10 dans EAX
MOV EAX, 10/4 ; met 3 dans EAXGoAsm consid├©re que les multiplications et divisions effectu├®es dans ce cadre le sont en utilisant des nombres non sign├®s. MUL et DIV sont utilis├®es lors de la compilation et non leurs homologues sign├®s IMUL et IDIV.
IV-O-3. D├®claration des nombres r├®els▲
Les nombres r├®els sont des nombres qui ont la capacit├® de repr├®senter une valeur inf├®rieure ├Ā 1. GoAsm attend des nombres r├®els pr├®sents dans le script source qu'ils prennent la forme d'un nombre ├Ā virgule flottante, techniquement compos├® de plusieurs chiffres et d'un point parmi ceux-ci conform├®ment ├Ā la notation anglo-saxonne qui pr├®vaut ici. Le point doit ├¬tre repr├®sent├® par le caract├©re correspondant au code ASCII 2Eh et peut se situer n'importe o├╣ pourvu qu'il soit unique et positionn├® entre deux chiffres cons├®cutifs. Le nombre r├®el peut, si n├®cessaire, ├¬tre assorti d'un exposant d├®cimal sign├® ├Ā la fin du nombre (en utilisant l'indicateur d'exposant ┬½┬Āe┬Ā┬╗ ou ┬½┬ĀE┬Ā┬╗ conform├®ment ├Ā la norme IEEE relative aux nombres en virgule flottante). Les registres x87 en virgule flottante du processeur peuvent accepter des nombres r├®els dans les r├®solutions 32, 64 ou 80 bits. Le 3DNow! et les instructions SSE travaillent avec des nombres r├®els 32 bits et les instructions SSE2 utilisent des nombres r├®els 64 bits.
Parfois, ces types sont nomm├®s┬Ā:
- 32 bits simple-pr├®cision┬Ā;
- 64 bits double-pr├®cision┬Ā;
- 80 bits double-pr├®cision ├®tendue.
Donc, les nombres r├®els peuvent ├¬tre d├®clar├®s comme DWords (32 bits), QWords (64 bits) ou TWords (80 bits). Voici quelques exemples de d├®clarations de donn├®es en nombres r├®els┬Ā:
DD 1.6789E3
DQ 1.6789E3
DT 1.6789E3
DD 3 DUP 7.6789E-2
DQ 678.27896435E3
DT 1.2Vous pouvez ├®galement d├®clarer directement le nombre PI soit en tant que TWord, QWord ou DWord comme suit┬Ā:
DD PI ; pi comme un dword
DQ PI ; pi comme un qword
DT PI ; pi comme un twordGoAsm tente d'obtenir une pr├®cision maximale dans la fourniture de PI en ├®crivant une valeur connue directement dans la mantisse.
Vous pouvez ├®galement d├®clarer un nombre r├®el comme suit┬Ā:
PUSH 1.1
MOV EAX, 1.1Ces deux formes utilisent un format 32 bits pour le nombre r├®el. La premi├©re place ce nombre sur la pile et la seconde le place dans le registre sp├®cifi├®.
IV-O-4. Pr├®cision de conversion de GoAsm▲
GoAsm utilise des algorithmes sp├®ciaux pour garantir une pr├®cision optimale lors du chargement de la d├®claration de nombre r├®el en tant que donn├®e. Dans le cas de la d├®claration d'un TWord (80 bits) le calcul est effectu├® si n├®cessaire sur un maximum de 92 bits, avant d'├¬tre arrondi puis ins├®r├® dans la mantisse 64 bits. La conversion en un QWord (64 bits) est effectu├®e en utilisant la pr├®cision maximale disponible (53 bits de mantisse) avec un arrondi ├Ā la valeur la plus proche. La conversion en un DWord (32 bits) est effectu├®e en utilisant la pr├®cision maximale disponible (24 bits de mantisse) avec un arrondi ├Ā la valeur la plus proche.
IV-O-5. Chargement direct de l'exposant et de la mantisse▲
Au lieu d'utiliser des nombres r├®els pour charger les registres en virgule flottante, vous pouvez d├®clarer un TWord et charger la mantisse et l'exposant directement en utilisant l'instruction FLD. Pour ce faire, vous aurez besoin de conna├«tre les valeurs de mantisse et d'exposant ├Ā charger (ceux-ci peuvent ├¬tre soit calcul├®s, soit trouv├®s et v├®rifi├®s en utilisant l'une des fonctions de simulation FPU de GoBug). Supposons, par exemple, que vous vouliez une repr├®sentation du nombre ŽĆ aussi pr├®cise que possible et vous savez, par ailleurs, que cette repr├®sentation consiste en un exposant de +0002 et une mantisse de +C90FDAA22168C235h. Vous pouvez donc d├®clarer ce nombre par┬Ā:
DIRECT_PI DT 4000C90FDAA22168C235het le charger en utilisant┬Ā:
FLD T[DIRECT_PI]Consid├®rons maintenant la figure ci-apr├©s qui montre la structure d'un registre de donn├®es x87. Le bit le plus significatif - bit 79 - dans la d├®claration de tword qui pr├®c├©de est le bit de signe indiquant que le nombre r├®el est positif ou n├®gatif. Ici, le nombre est positif puisque ce bit est ├Ā z├®ro. Le reste des quatre premiers chiffres hexad├®cimaux contient l'exposant qui est donc repr├®sent├® sur 15 bits. Pour mieux faire tenir les valeurs d'exposant positives et n├®gatives sur ce format, la valeur nulle est fix├®e ├Ā 3FFEh, ce qui autorise d├©s lors les exposants ├Ā ├®voluer entre -3FEEh et +4001h sans risquer d'atteindre le bit le plus significatif - le bit 79 ├®voqu├® plus haut. Le reste des chiffres hexad├®cimaux - 0 ├Ā 62 inclus - contient la mantisse.

Il est beaucoup plus difficile de charger la mantisse et l'exposant directement ├Ā partir de donn├®es d├®clar├®es en DWord et QWord. Ceci, parce que la r├®partition entre mantisse et exposant dans ce format num├®rique s'affranchit partiellement de la modularit├® 4 bits, base de la notation hexad├®cimale. Il r├®sulte de cette structure particuli├©re une certaine difficult├® ├Ā chiffrer les nombres hexad├®cimaux ├Ā d├®clarer, outre le fait que l'exposant, pour ne rien simplifier, subit un codage qui accentue cette opacit├®.
IV-P. Caract├©res dans GoAsm▲
IV-P-1. Cha├«nes de caract├©res▲
Dans votre script source, vous serez souvent amen├® ├Ā repr├®senter des caract├©res sous diff├®rentes formes. Par exemple┬Ā:
Mess DB 'I am a string of characters',0
PUSH 'This is supposed to be a carat ^'
MOV EAX, '┬Ż$|@'Il faut se demander quelles valeurs r├®elles sont charg├®es par GoAsm ├Ā l'issue du traitement de ces instructions. Au moment de l'assemblage GoAsm consulte votre script de source en utilisant les tables de caract├©res Windows, puis le lit caract├©re par caract├©re. En d'autres termes, GoAsm se voit attribuer la valeur des caract├©res dans le script source par Windows. Lorsque GoAsm charge dans le fichier objet les cha├«nes de caract├©res d├®crites ci-dessus, il charge la m├¬me valeur de caract├©re qui lui est donn├®e par Windows. Dans le cas de conversion de cha├«nes ANSI en cha├«nes Unicode, ces derni├©res sont pass├®s d'abord par l'API MultiByteToWideChar. Cela signifie que la valeur donn├®e ├Ā GoAsm par Windows correspondra au jeu de caract├©res courant (page de code). En cons├®quence, vous devez vous assurer que le jeu de caract├©res utilis├® dans l'ordinateur qui supporte GoAsm est le jeu de caract├©res pour lequel votre programme est con├¦u pour fonctionner.
Si vous utilisez un script source qui est dans un format Unicode (UTF-8 ou UTF-16), alors la question de la page de code dispara├«t. Les caract├©res corrects sont donn├®s par leur valeur Unicode.
IV-P-2. Caract├©res sp├®cifi├®s directement▲
Parfois, vous aurez ├Ā sp├®cifier des caract├©res par leur valeur r├®elle dans la table courante pour pouvoir faire face ├Ā d'├®ventuelles variations de jeux de caract├©res. C'est par exemple le cas pour le symbole repr├®sentant l'op├®rateur logique OR par une barre verticale, lequel peut prendre deux valeurs de code ASCII┬Ā:
CMP AL, 124D ; est-ce que ce code est un OR dans ce jeu de caract├©res ?
JZ >L4 ; oui
CMP AL, 221D ; est-ce que ce code est un OR dans cet autre jeu de caract├©res ?
JZ >L4 ; ouiCette formulation vous permet d'autoriser une possible variation du propre jeu de caract├©res de l'utilisateur. Si n├®cessaire, vous pouvez organiser votre code de telle sorte qu'il teste le jeu de caract├©res de l'utilisateur au moment de l'ex├®cution, et qu'il teste les caract├©res ou utilise les cha├«nes corrig├®es en cons├®quence. Vous pouvez ├®galement tester la langue de la machine de l'utilisateur et fournir des cha├«nes dans la langue correcte. Les API de ressources offrent une solution ├Ā cet ├®gard et cela peut ├¬tre fait automatiquement - voir le manuel du compilateur de ressources GoRC dans le volume 2.
IV-Q. Op├®rateurs▲
Voici certains op├®rateurs qui peuvent ├¬tre utilis├®s dans le script source et qui ont une signification particuli├©re pour GoAsm.
| , | L'instruction n'est pas termin├®e, continuer. |
|
Ligne de commentaire - ignorer tout jusqu'├Ā la fin de la ligne. |
|
Commentaire continu - ignore ce qui est entre les ast├®risques. |
|
L'instruction ou la donn├®e se poursuivent sur la ligne suivante. |
|
Le nombre est n├®gatif. |
|
Inverse le nombre (comme NOT). |
|
Inverse le nombre. |
|
Idem. |
|
Signe plus. |
|
Signe moins. |
|
Symbole de multiplication. |
|
Symbole de division. |
|
OR bit ├Ā bit. |
|
OR bit ├Ā bit. |
|
AND bit ├Ā bit. |
|
AND bit ├Ā bit. |
|
D├®calage ├Ā gauche d'un bit sur le nombre sp├®cifi├®. |
|
D├®calage ├Ā droite d'un bit sur le nombre sp├®cifi├®. |
|
Ex├®cute le calcul prioritairement entre les parenth├©ses. |
## dans une d├®finition a une signification sp├®ciale. Voir la section utilisation du double-di├©se dans les d├®finitions.
V. Fonctionnalit├®s avanc├®es▲
V-A. Structures - diff├®rents types et utilisation▲
V-A-1. Qu'est-ce qu'une ┬½┬Āstructure┬Ā┬╗┬Ā?▲
Les structures sont des zones de donn├®es de taille fixe qui contiennent des donn├®es r├®parties dans divers composants (├®l├®ments de structure). Elles peuvent aller de dispositions tr├©s souples ├Ā d'autres, tr├©s formalis├®es, avec m├¬me des structures au sein d'autres structures (structures imbriqu├®es). Elles peuvent ├¬tre des zones de donn├®es r├®sultant d'une d├®claration de donn├®es ordinaire ou de mod├©les STRUCT. Les structures sont tr├©s importantes en programmation Windows et GoAsm en supporte tous les types.
Voir aussi le paragraphe suivant concernant les unions.
V-A-2. Utilisation de structures simples en programmation Windows▲
Consid├®rons la structure LV_COLUMN qui est utilis├®e pour organiser les colonnes dans un contr├┤le ListView. Le code suivant envoie le message LVM_INSERTCOLUMN (valeur 101Bh) au contr├┤le ListView pour constituer une nouvelle colonne avec le num├®ro d'index correspondant dans EAX. Les d├®tails des colonnes sont contenus dans la structure LV_COLUMN. Voici comment ils pourraient ├¬tre utilis├®s en code 32 bits┬Ā:
PUSH ADDR LV_COLUMN, EAX, 101Bh, hListView
CALL SendMessageA ; ins├©re la colonne index├®e par EAXRegardons maintenant de plus pr├©s la structure LV_COLUMN. Dans le fichier d'en-t├¬te de Windows Commctrl.h (version pre- Win_IE 300) qui contient des informations sur la structure, elle est d├®crite comme une structure de six DWords. En un sens, donc, la structure peut ├¬tre consid├®r├®e comme une succession de six DWords qui peuvent ├¬tre d├®clar├®s tr├©s simplement comme suit┬Ā:
LV_COLUMN DD 6 DUP 0Cependant, dans l'information de Windows, il appara├«t que chacun des six doubles-mots a un nom qui donne une id├®e de ce pour quoi il est utilis├®, ce qui est utile. De plus, le premier DWord s'av├©re ├¬tre un masque qui identifie lesquels des ├®l├®ments suivants de la structure sont valides. Ce masque est important car une version ult├®rieure de la structure r├®v├©le, par exemple, la pr├®sence de deux autres membres, ce qui impose de facto un masque diff├®rent. Donc, il pourrait ├¬tre pr├®f├®rable de d├®clarer une structure de donn├®es de ce genre de telle sorte que le masque puisse ├¬tre initialis├® avec une valeur, et que vous puissiez voir les noms dans votre script source┬Ā:
LV_COLUMN
DD 0Fh ; +0h mask
DD 2h ; +4h fmt=LVCFMT_CENTER=2
DD 0 ; +8h cx
DD 0 ; +0Ch pszText
DD 0 ; +10h cchTextMax
DD 0 ; +14h iSubItemIci, remarquons que, tandis que nous d├®clarions la structure de donn├®es, nous en avons profit├® pour initialiser deux des membres avec des valeurs qui ne changeront pas et que nous avons inclus dans les commentaires l'offset des diff├®rents membres, leurs noms ainsi que d'autres informations.
V-A-3. Lecture et ├®criture dans une structure simple▲
Il est tr├©s facile de lire et d'├®crire sur la structure simple d├®crite pr├®c├®demment┬Ā:
MOV EDI, ADDR LV_COLUMN
MOV ESI, ADDR ColumnText ; r├®cup├©re en ESI la colonne de texte ├Ā utiliser
MOV [EDI+0Ch], ESI ; et la communique au membre appropri├® de la structure
MOV D[EDI+8h], 50D ; et ├®tablit la largeur ├Ā 50 pixelsou, vous pouvez utiliser┬Ā:
MOV ESI, ADDR ColumnText ; r├®cup├©re en ESI la colonne de texte ├Ā utiliser
MOV [LV_COLUMN+0Ch], ESI ; et la communique au membre appropri├® de la structure
MOV D[LV_COLUMN+8h], 50D ; et ├®tablit la largeur ├Ā 50 pixelsV-A-4. Structures plus formelles utilisant STRUCT▲
Certains programmeurs pr├®f├©rent ├¬tre plus formels dans l'utilisation des structures en utilisant notamment un mod├©le de structure. Cela se fait en deux ├®tapes. La premi├©re consiste ├Ā ├®laborer un mod├©le en utilisant STRUCT et en lui donnant un nom. ├Ć ce stade, les donn├®es ne sont pas encore d├®clar├®es.
Voici un exemple de mod├©le de structure portant le nom LV_COLUMN┬Ā:
LV_COLUMN STRUCT
mask DD 0Fh ; mask
fmt DD 2h ; LVCFMT_CENTER=2
cx DD 0
pszText DD 0
cchTextMax DD 0
iSubItem DD 0
ENDSDeux commentaires ont ├®t├® ajout├®s ici pour faciliter la compr├®hension de l'initialisation de deux membres de la structure. Noter que ENDS (litt├®ralement END STRUCT) marque la fin du mod├©le. Vous pouvez ├®galement marquer cette fin en lui donnant le nom de la structure suivi de ENDS comme ci-dessous┬Ā:
LV_COLUMN ENDSLa seconde ├®tape consiste ensuite ├Ā utiliser le mod├©le. Vous y parvenez en le nommant et en faisant pr├®c├®der ce nom d'un label, par exemple┬Ā:
Lv1 LV_COLUMN├Ć ce stade, vous venez de d├®clarer six doubles-mots en utilisant le mod├©le de la structure LV_COLUMN et vous avez donn├®, ├Ā la d├®claration de la structure, le label Lv1.
V-A-5. Les symboles cr├®├®s par les structures formelles▲
Dans GoAsm, des symboles sont cr├®├®s pour le label de la structure elle-m├¬me et ├®galement pour chaque membre nomm├® de la structure. Ceux-ci peuvent ensuite ├¬tre r├®f├®renc├®s directement et transmis aussi comme tels au d├®bogueur.
Ainsi┬Ā:
RECT STRUCT
left DD
top DD
right DD
bottom DD
ENDS
rc RECTcr├®e les symboles┬Ā:
- rc
- rc.left
- rc.top
- rc.right
- rc.bottom
V-A-6. Lecture et ├®criture sur la structure formelle▲
L'utilisation de la structure formelle vous permet d'├¬tre plus explicite dans votre script source lors de la lecture et l'├®criture dans la structure. Par exemple┬Ā:
MOV ESI, ADDR ColumnText ; r├®cup├©re en ESI la colonne de texte ├Ā utiliser,
MOV [Lv1.pszText], ESI ; ... la communique au membre appropri├® de la structure
MOV D[Lv1.cx], 50D ; ... et ├®tablit la largeur ├Ā 50 pixelsou m├¬me
MOV ESI, ADDR ColumnText ; r├®cup├©re en ESI la colonne de texte ├Ā utiliser
MOV EDX, ADDR Lv1.pszText ; r├®cup├©re en EDX l'adresse du membre psztext
MOV [EDX], ESI ; et charge le texte ├Ā utiliser
MOV EDX, ADDR Lv1.cx ; r├®cup├©re en EDX l'adresse du membre cx
MOV D[EDX], 50D ; et ├®tablit la largeur ├Ā 50 pixelsMais, rien ne vous emp├¬che de recourir ├Ā une ├®criture plus classique qui produit, pour autant, le m├¬me r├®sultat┬Ā:
MOV ESI, ADDR ColumnText ; r├®cup├©re en ESI la colonne de texte ├Ā utiliser,
MOV [Lv1+0Ch], ESI ; ... la communique au membre appropri├® de la structure
MOV D[Lv1+8h], 50D ; ... et ├®tablit la largeur ├Ā 50 pixelsBien qu'elle se r├®v├©le plus complexe ├Ā mettre en ┼ōuvre, la premi├©re m├®thode vous permet de suivre votre code dans le d├®bogueur symbolique. Les symboles de la structure y appara├«tront en entier, c'est-├Ā-dire en associant label de structure et nom du membre, ce qui procure un gain de lisibilit├® ├®vident. En effet, GoAsm cr├®e des symboles pour tous les membres de la structure et transmet ceux-ci au linker. Il me semble que cette possibilit├® est sp├®cifique ├Ā GoAsm et qu'elle est absente des autres assembleurs.
V-A-7. R├®cup├®ration de l'offset des membres d'une m├¬me structure▲
Il peut arriver que vous ayez ├Ā conna├«tre l'offset d'un membre au sein d'une structure. Il vous suffit pour cela de vous r├®f├®rer au nom de la structure auquel vous ajoutez un point puis le nom du membre concern├®. Par exemple, si┬Ā:
POINT STRUCT
left DD 0
right DD 0
ENDSalors, l'instruction MOV EBX, POINT.right charge la valeur 4 dans EBX, qui est la distance de l'├®l├®ment par rapport au d├®but de la structure.
Cette fa├¦on de r├®cup├®rer un offset est parfois utile pour obtenir des informations envoy├®es par Windows dans une structure. ├Ć titre d'exemple, la proc├®dure de callback OFNHookProc re├¦oit de Windows de l'information dans un message de WM_NOTIFY. Le param├©tre lParam contient un pointeur vers une structure OFNOTIFY. Il s'agit d'une structure imbriqu├®e de la forme suivante┬Ā:
OFNOTIFY STRUCT
hdr NMHDR
lpOFN DD
pszFile DD
ENDSdans laquelle la structure NMHDR est┬Ā:
NMHDR STRUCT
hwndFrom DD
idFrom DD
code DD
ENDSDonc, au sein de votre proc├®dure de fen├¬tre, vous pouvez obtenir la valeur du membre idFrom dans le NMHDR (identifiant du contr├┤le d'envoi du message) comme suit┬Ā:
MOV ESI, [EBP+14h] ; r├®cup├©re en ESI le pointeur de la structure OFNOTIFY
MOV EAX, [ESI+OFNOTIFY.hdr.idFrom]
MOV EDX, [ESI+OFNOTIFY.pszFile]En fait, il advient ici que OFNOTIFY.hdr.idFrom contient la valeur 4┬Ā; NOTIFY.pszFile contient la valeur 10h. Ce sont leurs offsets corrects par rapport au d├®but de la structure OFNOTIFY. Bien s├╗r, les structures concern├®es doivent ├¬tre connues de GoAsm. Cela se fait en incluant les mod├©les de structure dans le script source assembleur, quelque part en amont dans le fichier.
V-A-8. Red├®finition de l'initialisation de la structure▲
Supposons que vous ayez une structure appel├®e RECT comme suit┬Ā:
RECT STRUCT
left DD 10
top DD 10
right DD 120
bottom DD 90
ENDSVous pouvez remplacer l'initialisation de la structure en utilisant les op├®rateurs < et >, { et }. Par exemple┬Ā:
rc1 RECT <0, 20, 120, 300>r├®initialise les doubles-mots dans la structure de donn├®es ├Ā 0, 20, 120 et 300 respectivement.
Vous pouvez utiliser le point d'interrogation et la virgule, ou tout simplement la virgule pour ignorer certains membres, par exemple┬Ā:
rc1 RECT <0, ?, ?, 300>
rc1 RECT <0, , , 300>Ici vous remplacez seulement les premier et quatri├©me membres de la structure.
En utilisant des accolades, vous pouvez nommer explicitement les membres que vous souhaitez r├®initialiser┬Ā:
rc1 RECT {left=2, top=5}Vous pouvez m├¬me m├®langer les deux m├®thodes┬Ā:
rc1 RECT <{left=2, top=5}, 300h>Lors de l'utilisation des accolades, il n'est pas n├®cessaire de sp├®cifier les noms complets de symbole (dans l'exemple ci-dessus, ces noms complets seraient ┬½┬Ārc1.left┬Ā┬╗ et ┬½┬Ārc1.top┬Ā┬╗). Au lieu de cela vous pouvez vous limiter au seul nom du membre (┬½┬Āleft┬Ā┬╗ et ┬½┬Ātop┬Ā┬╗ dans notre cas). La r├®initialisation est ├®galement effectu├®e dans les structures imbriqu├®es. Aussi, si vous utilisez les m├¬mes noms pour les membres au sein d'une structure imbriqu├®e, il est possible d'initialiser plusieurs membres ├Ā la fois en utilisant une accolade de r├®initialisation.
V-A-9. Initialisation de membres de structure avec d├®clarations de donn├®es DUP▲
Si les membres d'une structure sont ├®tablis en utilisant l'op├®rateur DUP, vous pouvez proc├®der simplement ├Ā leur initialisation en utilisant une cha├«ne ou en sp├®cifiant chaque ├®l├®ment au sein des d├®limiteurs < et >┬Ā:
UP STRUCT
DB 27 DUP 0
DB 2 DUP 0
ENDS
Pent UP <'My cat was born on 23 April',<23h,4h>>L'exemple qui suit d├®crit la structure GUID et une initialisation typique pour une COM┬Ā:
GUID STRUCT
Data1 dd ?
Data2 dw ?
Data3 dw ?
Data4 db 8 dup ?
GUID ENDS
IID_IShellLink GUID <0000214eeh, 00000h, 00000h, <0c0h, 00h, 00h, 00h, 00h, 00h, 00h, 46h>>V-A-10. Quelques r├©gles de syntaxe concernant STRUCT▲
Une r├©gle importante veut que, dans la mesure o├╣ GoAsm est un assembleur ├Ā une seule passe, les mod├©les de structure soient imp├®rativement ├®crits dans le script source avant qu'ils ne soient utilis├®s. En effet, l'assembleur ne peut pas conna├«tre ├Ā l'avance la taille de la structure. GoAsm est plut├┤t plus tol├®rant avec la syntaxe de STRUCT que d'autres assembleurs. Par exemple, STRUC a la m├¬me signification que STRUCT. De m├¬me, il n'y a pas besoin de fournir des valeurs initiales du tout, et il n'y a pas d'importance ├Ā ce que les membres ne soient pas nomm├®s, ainsi qu'en attestent les exemples suivants qui sont parfaitement valides en d├®pit des apparences┬Ā:
RECT STRUCT
left DD
top DD
right DD
bottom DD
ENDSet
RECT STRUCT
left DD 0
DD 2 DUP 0
bottom DD 0
ENDSmais aussi
RECT STRUCT DD 4 DUP 0 ENDSsont des d├®clarations de structure tout aussi valides les unes que les autres. Toutefois, lorsque les membres sont nomm├®s, ils doivent l'├¬tre sur une nouvelle ligne.
Vous pouvez r├®utiliser le nom de membres de la structure, pourvu que le nom de la structure soit diff├®rent, par exemple┬Ā:
RECT STRUCT
left DD 0
top DD 0
right DD 0
bottom DD 0
ENDS
RECT2 STRUCT
left DD 0
top DD 0
right DD 0
bottom DD 0
ENDSSi vous utilisez┬Ā? dans l'initialisation des membres de la structure, vous obtenez le m├¬me effet qu'avec la valeur z├®ro. Cela ne se traduit pas, en tout cas, par des donn├®es enregistr├®es comme non initialis├®es, comme ce serait le cas avec une d├®claration de donn├®es ordinaire. De la sorte,
RECT STRUCT
left DD ?
top DD ?
right DD ?
bottom DD ?
ENDS
rc1 RECTest parfaitement valable, mais les donn├®es vont dans la section de donn├®es avec initialisation automatique ├Ā z├®ro, comme si des z├®ros avaient ├®t├® utilis├®s.
Dans un mod├©le de structure, vous pouvez mettre des donn├®es suppl├®mentaires sur une m├¬me ligne de la mani├©re habituelle. Voici un mod├©le de structure de quatre DWords utilisant cette facilit├®┬Ā:
RECT STRUCT
lefttop DD 0, 0
rightbottom DD 0,0
ENDSV-A-11. D├®clarations de structure r├®p├®t├®es▲
Ce proc├®d├® peut ├¬tre utile pour cr├®er des tableaux et des tables utilisant des mod├©les de structure. Par exemple┬Ā:
RECT <>, <>, <>, <>cr├®e quatre structures RECT (quatre DWords dans chaque). Dans la mesure o├╣ aucun label n'a ├®t├® utilis├® devant RECT, aucun symbole ne sera cr├®├® et transmis au d├®bogueur. Dans cet exemple┬Ā:
Buffer RECT <0,0,10,10>, <5,5,20,20>, <8,8,30,30>un tableau est constitu├® de trois structures RECT (quatre mots chacune) initialis├®es selon les valeurs indiqu├®es. Des symboles ne seront ├®labor├®s que pour la toute premi├©re structure. Ceci afin d'├®viter la duplication des noms de symboles.
Si vous voulez que les membres de la matrice aient des noms de symboles uniques, il vous est possible de proc├®der, par exemple, comme suit┬Ā:
Buffer1 RECT <0, 0, 10, 10>
Buffer2 RECT <5, 5, 20, 20>
Buffer3 RECT <8, 8, 30, 30>ou
Buffer RECT3 <0, 0, 10, 10, 5, 5, 20, 20, 8, 8, 30, 30>o├╣ RECT3 est une structure de trois RECT.
Si vous n'avez pas besoin d'initialiser les structures, vous pouvez les r├®p├®ter en utilisant, soit┬Ā:
Buffer RECT <>, <>, <>ce qui cr├®e trois structures RECT, soit┬Ā:
Buffer RECT, RECT, RECTqui fait la même chose.
Vous pouvez ├®galement utiliser des DUP pour r├®p├®ter des structures, par exemple┬Ā:
ThreeRects RECT 3 DUP <>
FiveRects RECT 5 DUP <23, 24, 25, 26>>Dans le deuxi├©me exemple, chaque RECT est initialis├® ├Ā la m├¬me valeur. L'initialisation de structures dupliqu├®es, de cette mani├©re, ne peut seulement ├¬tre faite qu'au plus haut niveau et non dans des structures imbriqu├®es.
V-A-12. Structures imbriqu├®es utilisant STRUCT▲
Les structures peuvent ├¬tre imbriqu├®s en utilisant une structure ├Ā l'int├®rieur d'une autre, de sorte que┬Ā:
RECT STRUCT
left DD 0
top DD 0
right DD 0
bottom DD 0
ENDS
StructTest STRUCT
a DD 6
b RECT
c DD 7
d DD 8
ENDSDans ce cas, Hello StructTest cr├®e sept DWords. Les symboles cr├®├®s (et pass├®s au d├®bogueur) sont┬Ā:
- Hello
- Hello.a
- Hello.b
- Hello.b.left
- Hello.b.top
- Hello.b.right
- Hello.b.bottom
- Hello.c
- Hello.d
et peuvent ├¬tre lus ou ├®crits de la mani├©re habituelle, par exemple┬Ā:
MOV D[Hello.b.left], 100h ; construction d'un rectangle commen├¦ant ├Ā 256 pixelsDe m├¬me que les membres d'une structure, les structures imbriqu├®es n'ont pas n├®cessairement besoin d'├¬tre nomm├®es, de sorte que ce qui suit est parfaitement valable┬Ā:
StructTest STRUCT
DD 6
RECT
c DD 7
d DD 8
ENDSV-A-12-a. Structures imbriqu├®es internes▲
Les structures peuvent ├¬tre imbriqu├®es en d├®clarant une structure au sein d'une structure, de sorte que
StructTest STRUCT
a DD 6
b STRUCT
left DD 0
top DD 0
right DD 0
bottom DD 0
ENDS
c DD 7
d DD 8
ENDSPuis
Hello StructTestproduisent le m├¬me r├®sultat que StructTest dans l'exemple pr├®c├®dent. La seule diff├®rence r├®side dans le fait que la structure b n'est pas disponible pour une utilisation ailleurs.
V-A-13. Outrepasser l'initialisation dans les structures imbriqu├®es▲
Vous devez utiliser avec prudence les d├®limiteurs < et > pour initialiser les membres corrects de la structure imbriqu├®e. Chaque d├®limiteur < permettra d'aller plus loin dans l'imbrication tandis que chaque d├®limiteur > permettra d'en sortir un peu plus. Au sortir d'une imbrication, une virgule est attendue apr├©s le d├®limiteur >. Donc, dans la structure imbriqu├®e StructTest ├®voqu├®e pr├®c├®demment┬Ā:
rc1 StructTest <23, <10,20,120,300>, 44, 55>va non seulement initialiser la structure principale mais ├®galement son membre b imbriqu├®. En revanche┬Ā:
rc1 StructTest <, <10,20,120,?>, 44, 55>outrepassera seulement l'initialisation de certains membres, de m├¬me que la formulation suivante qui est rigoureusement ├®quivalente┬Ā:
rc1 StructTest <, <10,20,120,>, 44, 55>Enfin, l'├®criture qui suit n'apportera aucune modification au membre b imbriqu├®┬Ā:
rc1 StructTest <, , 44, 55>Une bonne fa├¦on de suivre la coh├®rence des d├®limiteurs est de visualiser mentalement les membres que vous ne voulez pas modifier par un point d'interrogation. Vous pouvez m├¬me les ins├®rer dans l'expression pour en faciliter la lecture. Par exemple le dernier exemple peut ├¬tre ├®crit┬Ā:
rc1 StructTest <?, ?,4 4, 55>V-A-14. Priorit├® d'outrepassement▲
Plus grand est le niveau d'outrepassement, plus grande sera sa priorit├®. Supposons, par exemple, que vous ayez ces mod├©les de structure┬Ā:
RECT STRUCT
left DD 1
top DD 2
right DD 3
bottom DD 4
ENDS
StructTest STRUCT
a DD 6
b RECT <3333h, 4444h, 5555h,>
c DD 7
d DD 8
ENDSPuis
Hello StructTest <, <,0Bh,0Ch,>, , >Alors, RECT sera initialis├® ├Ā 3333h, 0Bh, 0Ch, 4.
Outrepasser le nom des membres en utilisant les accolades {} b├®n├®ficie d'une priorit├® plus ├®lev├®e que de le faire en utilisant les d├®limiteurs < et >.
V-A-15. Utilisation de cha├«nes dans les structures▲
Vous pouvez utiliser des cha├«nes dans les structures de la m├¬me mani├©re que vous le feriez dans une d├®claration de donn├®es ordinaire, par exemple┬Ā:
StringStruct STRUCT
DB 'I am a lonely string in a struct', 0
DB 'I will keep you company', 0
ENDSV-A-16. Structures avec des cha├«nes┬Ā: initialisation et outrepassement▲
Si une structure est d├®clar├®e avec┬Ā?, alors elle peut ├¬tre de n'importe quelle taille lorsqu'elle est utilis├®e avec des cha├«nes. Par exemple┬Ā:
Rect STRUCT
a DB ?
DB 0
b DB ?
DB 0
ENDS
RC1 Rect <'Hello', , 'Goodbye'>fixera la structure Rect en des cha├«nes termin├®es par un z├®ro, de cinq et sept octets respectivement.
Lorsque la taille du membre d'une structure est d├®j├Ā d├®finie, par exemple┬Ā:
Rect STRUCT
a DB 'Hello'
DB 0
b DB 'Goodbye'
DB 0
ENDSalors, l'outrepassement de l'initialisation ne changera pas la taille des membres, de sorte que par exemple┬Ā:
RC1 Rect <'Goodbye',,'Hello'>se traduira par la cha├«ne tronqu├®e 'Goodb' au label Rect.a et par la cha├«ne 'Hello' au label Rect.b, le reste de cette derni├©re ├®tant combl├®e avec deux z├®ros.
L'initialisation des membres des structures ├®tablie ├Ā l'aide DUP peut ├®galement ├¬tre surpass├®e par des cha├«nes. Par exemple┬Ā:
UP STRUCT
DB 20 DUP 0
ENDS
Pent UP <"Hello">se traduit par la cha├«ne 'Hello' suivie par 15 z├®ros.
Voir aussi la section ┬½┬ĀUtilisation des cha├«nes Unicode dans les structures┬Ā┬╗ du volume 2, dans le chapitre consacr├® ├Ā l'Unicode.
V-A-17. Assemblage conditionnel dans les structures▲
Vous pouvez utiliser l'assemblage conditionnel directement dans une structure, par exemple┬Ā:
NMHDR STRUCT
hwndFrom DD
idFrom DD
code DD
ENDS
NMTTDISPINFO STRUCT
hdr NMHDR
lpszText DD
#if STRINGS UNICODE
szText DW 80 DUP ?
#else
szText DB 80 DUP ?
#endif
hinst DD
uFlags DD
lParam DD
ENDS
DATA
Use1 NMTTDISPINFO
Use2 NMTTDISPINFO <<>, , "Hello", , , , >La deuxi├©me utilisation de la structure va assembler la cha├«ne 'Hello', soit en Unicode, soit en ANSI selon le param├®trage, en cons├®quence, de la directive STRINGS.
Voir la section relative ├Ā l'assemblage conditionnel.
V-B. Unions▲
V-B-1. D├®finition▲
Les unions, comme les structures, sont des zones de donn├®es de taille fixe qui contiennent des donn├®es dans divers composants (les membres d'union). Comme pour les structures, aucune zone de donn├®es n'est effectivement cr├®├®e lorsque vous d├®clarez un mod├©le d'union. Cette d├®claration se fait lorsque vous utilisez le mod├©le. Les unions diff├©rent des structures en ce que chaque membre de l'union commence ├Ā la m├¬me adresse dans la m├®moire. Les unions se r├®v├©lent utiles par exemple si vous souhaitez utiliser des labels diff├®rents pour traiter la m├¬me zone de donn├®es. Le label que vous adressez au moment de l'ex├®cution pourrait alors compter sur des ├®ventualit├®s telles que la version du syst├©me d'exploitation sur lequel le programme est en cours d'ex├®cution. La taille d'une union est toujours r├®gl├®e sur celle de la plus grande d├®claration de donn├®es en son sein. Vous pouvez m├®langer les unions avec des structures pour former des mod├©les complexes. Vous pouvez d├®clarer des unions dans les donn├®es locales et les r├®p├®ter de la m├¬me mani├©re que vous le pouvez pour les structures.
Consid├®rons, par exemple, le mod├©le d'union d├®clar├® comme suit┬Ā:
Thing UNION
Cat DD 0
Dog DW 0
Rat DB 0
ENDSVous pouvez utiliser ce mod├©le en ├®crivant┬Ā:
Hungry ThingCeci d├®finit alors ├Ā part une zone de donn├®es de quatre octets (DWord). Mais, pourquoi seulement quatre octets┬Ā? Tout simplement parce que chaque membre commence ├Ā la m├¬me place et que l'on prend seulement en consid├®ration la taille du plus grand d'entre eux. La fin du mod├©le de l'union est marqu├®e, au choix, par ENDS ou ENDUNION si vous pr├®f├®rez.
Les symboles cr├®├®s par cette union sont┬Ā:
- Hungry
- Hungry.Cat
- Hungry.Dog
- Hungry.Rat
Et vous pouvez adresser ces labels de la mani├©re habituelle, par exemple┬Ā:
MOV [Hungry.Cat], EAX
MOV AL, [Hungry.Dog]
MOV ESI,[Hungry.Rat]Ce qui, bien s├╗r, puisque chaque membre commence ├Ā la m├¬me place, est identique ├Ā┬Ā:
MOV [Hungry.Cat], EAX
MOV AL, [Hungry.Cat]
MOV ESI, [Hungry.Cat]]V-B-2. Unions imbriqu├®es▲
Vous pouvez imbriquer des unions dans des structures, des structures dans des unions ou des unions dans des unions. Par exemple
Laugh STRUCT
Balm DW 0
Ointment DB 0
ENDS
;
Zebra UNION
Tiger DD 0
Hyaena Laugh
ENDS
;
Lion STRUCT
BagPuss DB 3 DUP 0
Striped Zebra
ENDS
;
Fierce Lionqui produit les symboles et offsets correspondants suivants dans Fierce┬Ā:
|
+0 |
|
+0 |
|
+3 |
|
+3 |
|
+3 |
|
+3 |
|
+5 |
V-B-3. Unions imbriqu├®es en interne▲
Les unions peuvent ├¬tre imbriqu├®es en les d├®clarant dans une structure ou une union, tel que le montre l'exemple suivant┬Ā:
Lion STRUCT
BagPuss DB 3 DUP 0
Striped UNION
Tiger DD 0
Hyaena STRUCT
Balm DW 0
Ointment DB 0
ENDS
ENDS
ENDS
;
Fierce Lionproduit le m├¬me r├®sultat que l'exemple pr├®c├®dent. La seule diff├®rence est que Laugh et Zebra ne sont pas disponibles pour ├¬tre utilis├®s ailleurs.
V-B-4. Initialisation des membres d'union▲
De la m├¬me mani├©re que dans les structures, vous pouvez utiliser les op├®rateurs < et > pour initialiser les unions avec des cha├«nes ou des valeurs num├®riques, par exemple┬Ā:
Cat UNION
Ginger DB
Tortie DW
Grey DD
Tabby DQ
ENDS
Hungry Cat <"a string for Ginger">
Anxious Cat <, 4444h> ; initialise le mot
Sleepy Cat <, , 55555555h> ; initialise le double-mot
Insistent Cat <, , , 6666666666666666h> ; initialise le quadruple-motIl est encore plus difficile, lorsque vous utilisez les unions, de suivre les op├®rateurs < et >. En lieu et place et ├Ā votre convenance, vous pouvez sp├®cifier le nom du membre inclus entre les op├®rateurs { et }, ou vous pouvez les initialiser lors du lancement de l'ex├®cution, par exemple┬Ā:
Scaredy Cat {Ginger="a string for Ginger"}
GString DB "a string for the Grey cat"
MOV [Scaredy.Grey], ADDR GString ; charge un pointeur vers GStringRappelez-vous que, dans la mesure o├╣ les membres d'unions sont au m├¬me endroit, une initialisation ult├®rieure peut en ├®craser une pr├®c├®dente.
Le point d'interrogation en option (?) est utile pour montrer que vous ne voulez pas effacer un remplacement pr├®c├®dent.
Exemple┬Ā:
Laugh STRUCT
Balm DW 6666h
Ointment DB
ENDS
;
Zebra UNION
Tiger DD 88888888h
Hyaena Laugh
ENDS
;
Lion STRUCT
BagPuss DB
DB
DB
Striped Zebra
ENDS
;
Fierce Lion <{Ointment=0AAh} 22h, 33h, 44h, <?,<?,55h>>>qui initialise la zone de donn├®es de la mani├©re suivante┬Ā:
At Fierce.BagPuss (at offset +0) 22h,33h,44h
Then at Fierce.Striped.Tiger (at offset +3) 66h,66h,0AAh,88hIl appara├«t ici que le DWord Tiger ├Ā +3 dans l'union Zebra a ├®t├® initialis├® ├Ā 88888888h mais qu'il a ensuite ├®t├® remplac├® par les valeurs de Balm et Ointment (qui ├®taient dans la m├¬me union). Seul le dernier octet a surv├®cu.
V-C. D├®finitions┬Ā: Equates, macros et #define▲
V-C-1. Quand faire quelque chose signifie quelque chose d'autre▲
Equates, macros et #defines donnent un sens ├Ā un mot. En d'autres termes, le mot est d├®fini. Une fois d├®fini, et ├Ā partir de ce point dans le script source, la d├®finition est utilis├®e en lieu et place du mot d'origine si le contexte le permet. Si le mot tel que d├®fini d├®signe┬Ā:
- un nombre, alors les programmeurs en assembleur appellent la d├®finition une ┬½┬Āequate┬Ā┬╗ parce que, traditionnellement, le mot est d├®fini en utilisant les op├®rateurs EQU ou =┬Ā;
- une cha├«ne, alors traditionnellement, on parle d'une ┬½┬Āequate┬Ā┬╗ texte┬Ā;
- quelque chose de plus ├®labor├® qu'un nombre ou une cha├«ne - une s├®rie d'instructions, par exemple - alors les programmeurs appellent cela une ┬½┬Āmacro┬Ā┬╗. Ceci parce que, selon un usage r├®pandu, le mot est d├®fini en utilisant l'op├®rateur MACRO.
Lors de l'utilisation GoAsm, pour les d├®finitions qui peuvent ├¬tre construites sur une seule ligne, vous aimeriez utiliser EQU, =, ou #define comme vous le feriez en langage C. Il suffit d'utiliser celui des trois que vous aimez le mieux. Vous pouvez utiliser le caract├©re de continuation (┬½┬Ā\┬Ā┬╗) pour permettre aux d├®finitions de s'├®tendre sur plus d'une ligne, mais il est pr├®f├®rable d'utiliser MACRO ŌĆ” ENDM ├Ā la place, de mani├©re ├Ā ├®viter d'├®ventuels probl├©mes de syntaxe.
Dans la mesure o├╣ GoAsm est un assembleur qui ne travaille qu'en une seule passe, vous devez vous assurer que vos d├®finitions ne sont pas utilis├®es avant qu'elles ne soient d├®clar├®es dans le script source. Une fois qu'un mot a ├®t├® d├®fini, vous pouvez modifier sa d├®finition mais GoAsm vous en avertira car une telle intervention peut ne pas ├¬tre intentionnelle.
Voici quelques exemples de mise en ┼ōuvre de d├®finitions.
V-C-2. D├®finitions de mots repr├®sentatifs de nombres ou cha├«nes (exemples de donn├®es)▲
Voici trois exemples d├®finissant un mot comme une valeur constante. Le premier utilise =, le second utilise EQU et le troisi├©me, #define. Ils ont tous les trois le m├¬me effet.
WS_CHILD=40000000h
WS_CHILD EQU 40000000h
#define WS_CHILD 40000000hOutre une constante num├®rique, vous pouvez utiliser une expression arithm├®tique, des cha├«nes ou m├¬me d'autres d├®finitions lorsque vous d├®finissez un mot. En voici quelques exemples┬Ā:
SKIP_VALUE EQU 20h|40h
#define SKIP_VALUE 20h|40h
HelloText='Hello world'
#define HelloText "Hello world"
MANIA=SKIP_VALUE+WS_CHILDSi vous ne donnez pas de valeur ├Ā l'equate, celle-ci prend la valeur 1 par d├®faut, qui correspond ├Ā TRUE dans la philosophie Windows. Par exemple┬Ā:
NT_VERSION=
NT_VERSION EQU
#define NT_VERSIONUne fois un mot d├®fini, vous pouvez l'utiliser dans presque toute situation o├╣ la d├®finition est valide, par exemple┬Ā:
DB HelloText
PUSH WS_CHILD|WS_VISIBLE|SS_OWNERDRAW
MOV EAX, WS_CHILD
MOV EAX, [ESI+SKIP_VALUE]
MOV EAX, MANIA+800hV-C-3. D├®finition de mots en substitution d'instructions de code▲
Voici un exemple de la fa├¦on dont vous pouvez attribuer ├Ā un mot tout ou partie de la fonctionnalit├® d'une instruction de code┬Ā:
#define lParam [EBP+14h]Vous pouvez utiliser alors la d├®finition ainsi cr├®├®e de la mani├©re suivante┬Ā:
MOV lParam, EAX ; identique ├Ā MOV [EBP+14h], EAXIci, on peut dire, d'une certaine mani├©re, que le texte ┬½┬Ā[EBP+14h]┬Ā┬╗ a tout simplement ├®t├® remplac├® par lparam dans le script source.
V-C-4. Utilisation d'arguments dans la d├®finition de mots▲
Les arguments sont des valeurs qui sont donn├®es lorsque les d├®finitions sont utilis├®es. Ces valeurs sont ensuite utilis├®es dans la d├®finition ou la macro elles-m├¬mes. Ainsi┬Ā:
RECTB(%a,%b,%c,%d) = DD %a,%b,%c,%dEnsuite, vous pouvez d├®clarer quatre DWords initialis├®s comme sp├®cifi├® dans les arguments┬Ā:
rc1 RECTB (10, 10, 100, 200) ; identique ├Ā DD 10,10,100,200Voici maintenant un autre exemple utilisant #define┬Ā:
#define DBDATA(%a,%b) DB %a DUP %b
DBDATA(3,'x') ; identique ├Ā DB 3 DUP 'x'Il existe une r├©gle de syntaxe importante lorsque vous utilisez des arguments dans les d├®finitions┬Ā: il ne doit pas y avoir d'espace entre le nom de la d├®finition et l'ouverture de parenth├©se qui pr├®c├©de l'├®nonc├® des arguments.
Ainsi┬Ā:
RECTB(%a,%b,%c,%d)est correct, mais
RECTB (%a,%b,%c,%d)est erron├®. Cette contrainte syntaxique, d├®routante ├Ā certains ├®gards, garantit que GoAsm reconna├«t les param├©tres entre parenth├©ses en tant qu'arguments et seulement en tant que tels.
Vous devez ├®galement vous assurer que les noms des arguments sont inhabituels et ne risquent donc pas de se retrouver dans tout autre mat├®riau utilis├® dans la d├®finition ou la macro. Cela ├®vite que d'autres choses soient remplac├®es par inadvertance. D'o├╣ le signe de pourcentage utilis├® dans les exemples ci-dessus.
V-C-5. D├®finitions r├®parties sur plusieurs lignes▲
La d├®finition peut occuper plusieurs lignes pour en accro├«tre la lisibilit├® et, notamment, pour vous permettre d'ajouter des commentaires. Par exemple┬Ā:
#define WS_POPUP 0x80000000L
#define WS_BORDER 0x00800000L
#define WS_SYSMENU 0x00080000L
#define WS_POPUPWINDOW (WS_POPUP | \
WS_BORDER | \
WS_SYSMENU)Ce dernier exemple a ├®t├® pris directement sur le fichier d'en-t├¬te de Windows Winuser.h et vous pouvez voir qu'il ├®pouse la syntaxe typique du C. GoAsm ne peut que s'en r├®jouir et tol├©re, de surcro├«t, l'absence ├®ventuelle des parenth├©ses┬Ā:
#define WS_POPUPWINDOW WS_POPUP | \
WS_BORDER | \
WS_SYSMENUVous pouvez pr├®f├®rer utiliser MACRO ŌĆ” ENDM ├Ā la place du caract├©re de continuation, auquel cas l'exemple ci-dessus peut ├¬tre r├®crit sous la forme┬Ā:
WS_POPUPWINDOW MACRO WS_POPUP |
WS_BORDER |
WS_SYSMENU
ENDMV-C-6. D├®finitions multiligne┬Ā: exemple de trame de pile (callback windows)▲
Ceci s'applique uniquement ├Ā la programmation 32 bits.
Vous pouvez utiliser la m├®thode de d├®finition multiligne pour constituer un mot signifiant plusieurs lignes d'instructions de code. Par exemple┬Ā:
OPEN_STACKFRAME(a) = PUSH EBP \
MOV EBP, ESP \
SUB ESP, a*4 \
PUSH EBX, EDI, ESI
CLOSE_STACKFRAME = POP ESI, EDI, EBX \
MOV ESP, EBP \
POP EBPEn utilisant MACRO ŌĆ” ENDM, cela donne┬Ā:
OPEN_STACKFRAME(a) MACRO PUSH EBP
MOV EBP, ESP
SUB ESP, a*4
PUSH EBX, EDI, ESI
ENDM
CLOSE_STACKFRAME MACRO POP ESI, EDI, EBX
MOV ESP, EBP
POP EBP
ENDMDans cet exemple, le mot OPEN_STACKFRAME est d├®fini pour ├®laborer une trame de pile qui pourrait typiquement ├¬tre utilis├®e dans une proc├®dure de fen├¬tres appel├®e par le syst├©me Windows. Il poss├©de un argument qui d├®tient le nombre de mots dans la trame de pile permettant d'accepter des donn├®es locales (le pointeur de pile est d├®plac├® par ce param├©tre de sorte que la pile puisse ├¬tre utilis├®e pour stocker les donn├®es locales). Le mot CLOSE_STACKFRAME ferme, quant ├Ā lui, la trame de pile. Voici maintenant comment utiliser ces d├®finitions. Dans la section de code┬Ā:
WndProc: ; nom de cette proc├®dure
OPEN_STACKFRAME (6) ; cr├®ation d'un espace pour 6 dwords de donn├®es locales
;----------------- insertion du code de la proc├®dure de fen├¬tre ici
CLOSE_STACKFRAME
RET 10h ; retrait de la pile des 4 param├©tres envoy├®s par WindowsAjoutons maintenant un peu de raffinement de sorte que la pile puisse ├¬tre accessible de mani├©re plus compr├®hensible┬Ā:
lParam = [EBP+14h] ;
wParam = [EBP+10h] ; on se tient pr├¬t ├Ā acc├®der aux param├©tres qui
uMsg = [EBP+0Ch] ; sont envoy├®s par Windows ├Ā la proc├®dure de fen├¬tre
hwnd = [EBP+8h] ;
;
hDC = [EBP-4h] ; certains noms d'├®l├®ments de donn├®es
hBrush = [EBP-8h] ; sont souvent utilis├®es dans des
hPen = [EBP-0Ch] ; proc├®dures de fen├¬tre diff├®rentes
DATA1 = [EBP-10h] ;
DATA2 = [EBP-14h] ; espace pour plus de donn├®es locales
DATA3 = [EBP-18h] ;├Ć l'int├®rieur de la trame de pile constitu├®e ici, les param├©tres envoy├®s par Windows (hwnd, uMsg, wParam et lParam) seront toujours sur la pile de EBP+14h ├Ā EBP+8h. ├Ć EBP+4h, nous trouvons l'adresse de retour du CALL. En EBP nous avons la valeur pr├®c├®dente de EBP que nous avons pouss├®e au moment de la constitution de la trame de pile. Puis, de EBP-4h ├Ā EBP-18h, nous avons l'espace d├®volu ├Ā nos donn├®es locales qui, dans cet exemple, peuvent ├¬tre accessibles en utilisant les d├®finitions hDC, hBrush, hPen, DATA1, DATA2 et DATA3 (ou tout nom que vous voudrez bien leur attribuer). ├Ć EBP-1Ch nous avons la valeur de EBX quand ce registre a ├®t├® pouss├® en pile lorsque la trame de cette derni├©re a ├®t├® ├®labor├®e. De m├¬me EDI est en EBP-20h et ESI en EBP-24h. Toutes ces valeurs sont prot├®g├®es tandis que la trame de pile reste ouverte (elles ne seront pas ├®cras├®es par d'autres fonctions avant la fin du callback). Pour acc├®der aux donn├®es dans la trame de pile, vous devez vous assurer que vous ne modifiez EBP en aucune mani├©re (ou si vous le faites, vous le restaurez ├Ā sa valeur initiale). Vous ne devez pas acc├®der aux donn├®es par leur nom. Dans cet exemple, MOV EAX, [hBrush] est la m├¬me chose que MOV EAX, [EBP-8h]. Ceci est une question de style et de choix personnel. En utilisant ces m├®thodes, vous pouvez ├®tablir autant de donn├®es locales que vous le souhaitez, et si vous vous en tenez ├Ā une m├®thode fixe comme celle-ci, vous saurez toujours o├╣ sont vos donn├®es locales. Dans cet exemple, le premier DWord des donn├®es locales est toujours ├Ā EBP-4h. Soustraire 4 de cette valeur pour acc├®der ├Ā chaque DWord suppl├®mentaire de donn├®es locales.
Il y a beaucoup d'autres fa├¦ons de travailler avec la pile dans les callbacks. Voir, ├Ā ce sujet, les sections trames de pile pour Callback en 32 et 64 bits, et trames de pile automatis├®es utilisant FRAME ŌĆ” ENDF, LOCALS et USEDATA.
Voir aussi comprendre la pile (parties 1 et 2) dans les annexes.
V-C-7. Assemblage conditionnel dans les macros▲
Si vous utilisez l'assemblage conditionnel dans vos d├®finitions il est recommand├® d'utiliser MACRO ŌĆ” ENDM au lieu de la m├®thode des caract├©res de continuation mentionn├®e plus haut.
Voici un exemple┬Ā:
STRINGS UNICODE
CODE
;
#define REPORT
;
MBMACRO(%lpTextW) MACRO
#ifdef REPORT
INVOKE MessageBoxW, 0, addr %lpTextW, "Report", 40h
#endif
ENDM
;
MBMACRO("Ce code a ├®t├® assembl├® !")Dans le code ci-dessus, la bo├«te de message (Message Box) est affich├®e de mani├©re classique via l'API MessageBox. On a vu pr├®c├®demment que la ligne #define REPORT sans autre param├©tre donne ├Ā REPORT la valeur 1 (TRUE). Cette situation autorise l'affichage. Mais si REPORT ├®tait suivi d'une valeur, alors il n'y aurait pas de message affich├®. La cha├«ne ┬½┬ĀCe code a ├®t├® assembl├®┬Ā!┬Ā┬╗ est envoy├®e comme un argument ├Ā la macro.
Voir la section assemblage conditionnel.
V-C-8. Comptage des arguments avec ARGCOUNT▲
Ceci s'applique uniquement ├Ā la programmation 32 bits.
ARGCOUNT renvoie le nombre d'arguments donn├®s lorsque la d├®finition est utilis├®e, ce qui peut ├¬tre utilis├® avec l'assemblage conditionnel dans les d├®finitions. Par exemple, consid├®rons la macro nomm├®e macro26 ainsi d├®finie┬Ā:
macro26(%a,%b,%c,%d,%e,%f) = #if ARGCOUNT=6 \
PUSH %f \
#endif \
#if ARGCOUNT >=5 \
PUSH %e \
#endif \
#if ARGCOUNT >=4 \
PUSH %d \
#endif \
#if ARGCOUNT >=3 \
PUSH %c \
#endif \
#if ARGCOUNT >=2 \
PUSH %b \
#endif \
#if ARGCOUNT >=1 \
PUSH %a \
#endifImaginons maintenant que nous utilisions macro26 comme suit┬Ā:
macro26(4,3,2,1)Dans ce cas, ARGCOUNT prendrait la valeur 4 et le code r├®sultant correspondrait exactement ├Ā l'instruction multiple suivante┬Ā:
PUSH 1, 2, 3, 4Dans l'exemple ci-dessus, les deux premiers PUSH sont ignor├®s parce que ARGCOUNT est ni 6 (dans le premier test) ni sup├®rieur ou ├®gal ├Ā 5 (dans le second test).
Cela peut ├¬tre am├®lior├® pour ├®tablir une macro d'appel de fonction ┬½┬ĀC┬Ā┬╗ o├╣ la pile est effac├®e apr├©s l'appel (le nombre correct d'octets est ajout├® au pointeur de pile ESP apr├©s l'appel)┬Ā:
macro26(%x,%a,%b,%c,%d,%e,%f) = #if ARGCOUNT=7 \
PUSH %f \
#endif \
#if ARGCOUNT >=6 \
PUSH %e \
#endif \
#if ARGCOUNT >=5 \
PUSH %d \
#endif \
#if ARGCOUNT >=4 \
PUSH %c \
#endif \
#if ARGCOUNT >=3 \
PUSH %b \
#endif \
#if ARGCOUNT >=2 \
PUSH %a \
#endif \
CALL %x \
ADD ESP, ARGCOUNT-1*4et ici, on peut voir une autre mani├©re d'y arriver┬Ā:
cinvoke(funcname,%1,%2,%3,%4,%5) = \
#if ARGCOUNT=1 \
invoke funcname \
#elif ARGCOUNT=2 \
invoke funcname, %1 \
#elif ARGCOUNT=3 \
invoke funcname, %1, %2 \
#elif ARGCOUNT=4 \
invoke funcname, %1, %2, %3 \
#elif ARGCOUNT=5 \
invoke funcname, %1, %2, %3, %4 \
#elif ARGCOUNT=6 \
invoke funcname, %1, %2, %3, %4, %5 \
#endif \
#if ARGCOUNT>1 \
ADD ESP, ARGCOUNT-1*4 \
#endifLesquels pourraient alors ├¬tre utilis├®s comme suit┬Ā:
cinvoke(_cprintf,23,24,25,26,27)
macro26(_cprintf,23,24,25,26,27)Si vous ne souhaitez utiliser le caract├©re de continuation, vous pouvez utiliser MACRO ŌĆ” ENDM en lieu et place.
V-C-9. Utilisation des doubles-di├©ses dans les d├®finitions▲
Un double-di├©se dans une d├®finition a pour fonction de joindre deux ├®l├®ments en supprimant tous les espaces entre les deux. Cela vous permet de cr├®er un seul mot ├Ā partir d'un ou plusieurs composants, par exemple┬Ā:
LVERS=0030
MVERS=0044h
VERSION=LVERS##MVERS
;
MOV EAX, VERSIONIci, VERSION est d├®fini par le nombre 00300044h.
V-C-10. L'utilisation des d├®finitions et ses limites▲
Certains programmeurs utilisent des d├®finitions aussi souvent que possible. ├Ć mon avis, cela rend le script source plus difficile ├Ā lire. Aussi convient-il de d├®terminer dans quelle mesure quelqu'un d'autre que le concepteur pourrait ├¬tre amen├® ├Ā parcourir le code source et ├Ā en comprendre les tenants et les aboutissants ├Ā supposer, bien ├®videmment, que cela soit souhaitableŌĆ” Si cette personne doit souvent se r├®f├®rer ├Ā d'autres fichiers ou ├Ā des listes de d├®finitions pour ce faire, alors le codage manquera, ├Ā l'├®vidence, de clart├®. Utilis├®es cependant avec mod├®ration en programmation Windows, les d├®finitions peuvent se r├®v├®ler utiles pour expliciter le script source. Par exemple┬Ā:
PUSH WS_CHILD|WS_VISIBLE|SS_OWNERDRAWest plus parlant que┬Ā:
PUSH 5000000Dhbien qu'un commentaire appropri├® puisse, en l'esp├©ce, ├®clairer utilement cette instruction sans qu'il soit n├®cessaire d'utiliser une d├®finition┬Ā:
PUSH 5000000Dh ; WS_CHILD, WS_VISIBLE, SS_OWNERDRAWEn revanche, la formulation qui suit nuit ├Ā la clart├® du code et doit donc ├¬tre ├®vit├®e┬Ā:
#define wParam EBP+10h
MOV EAX, [wParam] ; identique ├Ā MOV EAX, [EBP+10h]On notera en effet que la r├®f├®rence [wParam] fait appara├«tre wParam comme un label, ce qui n'est justement pas le cas ici. Mieux vaut ├®crire en l'occurrence┬Ā:
#define wParam [EBP+10h]
MOV EAX, wParamCeci est plus clair ainsi parce que, dans GoAsm, la seule chose que vous pouvez aborder de cette mani├©re sans l'aide des crochets est une d├®finition.
Ce qui suit est ├®galement contestable et doit ├¬tre ├®vit├® ├Ā tout prix┬Ā:
#define GET_LPARAM MOV EAX, [EBP+14h]
GET_LPARAMUne meilleure pratique de programmation sugg├©re d'├®crire┬Ā:
CALL GET_LPARAMet de r├®aliser correctement cet appel sous forme de fonction. Cependant lors de la manipulation de la pile, il est tr├©s difficile d'utiliser une proc├®dure dans la mesure o├╣ CALL et RET modifient eux-m├¬mes la pile. Donc, dans ce cas, il peut ├¬tre pratique d'utiliser une d├®finition si la clart├® du script source n'en souffre pas. Voir, ├Ā ce titre, les exemples OPEN_STACKFRAME et CLOSE_STACKFRAME propos├®s pr├®c├®demment.
Enfin, il semble qu'il y ait peu d'int├®r├¬t ├Ā ├®crire┬Ā:
THOUSAND = 1000D
MOV EAX, THOUSANDalors qu'une formulation plus directe serait tout aussi claire┬Ā:
MOV EAX, 1000D├Ć titre d'illustration et en guise de conclusion, imaginez que vous souhaitiez que votre script source soit compr├®hensible par des non-Anglophones. Dans ce cas, il vous serait parfaitement possible de traduire tous les mn├®moniques du processeur en utilisant des equates pour parvenir ├Ā vos fins. Voir ├Ā ce sujet la section ┬½┬ĀUtilisation de mots d├®finis dans les fichiers Unicode┬Ā┬╗ dans le chapitre du volume 2 consacr├® ├Ā l'Unicode.
V-D. Importation┬Ā: utilisation des biblioth├©ques run-time▲
Avec GoAsm, il est facile d'utiliser la biblioth├©que run-time du C. Elle consiste en un certain nombre de fonctions contenues dans Crtdll.dll ou Msvcrt.dll (ou leurs variantes) qui se trouvent habituellement sur un ordinateur Windows dans le dossier syst├©me. L'information sur cette biblioth├©que est disponible sur le site Microsoft developer site (MSDN). La principale chose ├Ā retenir lors de l'utilisation de ces fonctions est que m├¬me si vous envoyez des param├©tres ├Ā la fonction au moyen de la pile, la fonction ne restaure pas celle-ci. Par cons├®quent, vous aurez besoin de le faire vous-m├¬me en utilisant l'instruction ADD ESP, x apr├©s l'appel, x ├®tant le nombre d'octets utilis├®s pour les param├©tres.
V-E. Import┬Ā: donn├®es, par ordinal, par DLL sp├®cifiques▲
V-E-1. Import de donn├®es▲
Au moment de l'ex├®cution, les donn├®es ne peuvent ├¬tre import├®es qu'indirectement. Cela veut dire que vous ne pouvez importer qu'un pointeur vers des donn├®es. Cependant, en utilisant ce pointeur, vous pouvez obtenir les donn├®es elles-m├¬mes.
Par exemple, en supposant que DATA_VALUE est un export de donn├®es dans un autre programme vous obtenez, avec GoAsm, le pointeur et la donn├®e comme suit┬Ā:
MOV EBX, [DATA_VALUE] ; pointeur vers DATA_VALUE dans EBX
MOV EAX, [EBX] ; on r├®cup├©re la donn├®e dans EAX ├Ā partir de ce pointeurDe la m├¬me mani├©re que pour l'importation des proc├®dures d'autres programmes au moment de l'├®dition de liens, vous donnez au linker (GoLink, en l'occurrence) le nom de l'ex├®cutable contenant l'import.
V-E-2. Import direct par ordinal▲
Le type d'import auquel nous sommes confront├®s en utilisant la proc├®dure CALL importera la proc├®dure par son nom. De mani├©re plus d├®taill├®e lorsque le chargeur Windows d├®marre le programme, il parcourt les DLL pour les importations requises par le programme. Il le fait en comparant les noms des exportations dll aux noms des imports du programme. Pour acc├®l├®rer ce processus avec les Dll priv├®es l'exportation et l'importation par ordinal sont parfois utilis├®es. Par ce biais, le chargeur peut trouver la bonne importation en utilisant un index dans une table de la DLL. Notez qu'il est imprudent de le faire dans le cas des DLL du syst├©me Windows puisque l'uniformit├® des nombres ordinaux des exportations n'est pas garantie selon les diff├®rentes versions de DLL.
En utilisant GoAsm et son compl├®ment GoLink, vous pouvez importer par ordinal par cette syntaxe simple┬Ā:
CALL MyDll:6Cette proc├®dure va appeler le num├®ro 6 dans MyDll.dll. Notez que l'extension ┬½┬Ādll┬Ā┬╗ est implicite si aucune extension n'est mentionn├®e. Supposons que vous vouliez une DLL pour appeler une fonction dans l'ex├®cutable principal par ordinal. Dans ce cas, vous pourriez utiliser┬Ā:
CALL Main.exe:15qui appellera la 15e fonction de Main.exe.
Les appels ordinaux utilisant la forme absolue (c'est-├Ā-dire utilisant les opcodes FF15) emploient, quant ├Ā eux, la syntaxe qui suit┬Ā:
CALL [Main.exe:15]Vous n'avez pas ├Ā inclure le chemin d'acc├©s au fichier dans le CALL. GoLink r├®alise une recherche ├®tendue des fichiers sp├®cifi├®s, mais s'il ├®tait toutefois n├®cessaire de fournir un chemin ce serait dans le cadre de l'├®diteur de liens plut├┤t qu'au niveau du CALL du script de l'assembleur.
├ēvidemment, pour utiliser cette m├®thode d'appel d'une fonction par ordinal vous devez vous assurer que le nombre ordinal de la fonction est fix├®. Voir la section export par ordinal.
Note┬Ā: ce qui pr├®c├©de s'applique uniquement ├Ā GoLink.
Il y a une autre fa├¦on d'utiliser les ordinaux en utilisant LoadLibrary pour charger la DLL (ou retourner un handle si elle est d├®j├Ā charg├®e), puis en appelant GetProcAddress en passant la valeur ordinale pour obtenir la valeur de la proc├®dure ├Ā appeler. Enfin, vous appelez la proc├®dure telle que fournie par GetProcAddress.
V-E-3. Import par des DLL sp├®cifiques ▲
Occasionnellement, vous voudrez peut-├¬tre forcer le linker ├Ā utiliser une importation en provenance d'une DLL particuli├©re. Vous pourriez avoir besoin de proc├®der de la sorte si deux DLL voire plus (d├®sign├®es au linker au moment de la phase d'├®dition de liens) comportent des fonctions portant le m├¬me nom. Il est donc possible, dans ce cas, de forcer GoLink ├Ā ├®tablir des liens avec une DLL particuli├©re en utilisant la syntaxe┬Ā:
CALL NameOfDll:NameOfAPICeci s'applique uniquement ├Ā GoLink.
V-F. Export de proc├®dures et de donn├®es▲
Vous pouvez faire en sorte que vos proc├®dures et donn├®es soient disponibles pour d'autres ex├®cutables en les exportant. Dans Windows, il est habituel que les DLL soient utilis├®es pour les exportations, mais parfois une DLL a besoin d'appeler une proc├®dure ou d'utiliser les donn├®es d'un fichier Exe et, dans ce cas, ce dernier exporte ├®galement. L'export peut ├¬tre fait soit au moment de l'├®dition de liens (vous indiquez au linker les symboles ├Ā exporter), soit au moment de l'assemblage avec GoAsm. Dans ce dernier cas, GoAsm donne alors au linker les informations d'export via la section .drectve dans le fichier objet (├Ā noter que tous les linkers ne supportent pas cette particularit├®).
Il y a deux fa├¦ons de d├®clarer les exports dans GoAsm. Vous pouvez les d├®clarer tous au d├®but de votre fichier (avant qu'une quelconque section soit d├®clar├®e) ou les d├®clarer dans votre code source au fur et ├Ā mesure que vous avancez dans son ├®criture. Vous pouvez utiliser l'une ou l'autre de ces m├®thodes selon votre propre pr├®f├®rence.
Voici un exemple de d├®claration de toutes les exportations avant que les sections ne soient d├®clar├®es┬Ā:
EXPORTS CALCULATE, ADJUST_DATA, DATA_VALUEVoici un exemple de d├®claration d'export en cours de d├®veloppement┬Ā:
EXPORT CALCULATE:
CMP EAX, EDX ; code pour la
JZ >4 ; proc├®dureCe code exporte le label ├Ā la proc├®dure CALCULATE.
Si vous pr├®f├®rez, vous pouvez avoir les deux mots sur des lignes s├®par├®es comme, par exemple┬Ā:
EXPORT
CALCULATE:
CMP EAX, EDX ; code pour la
JZ >4 ; proc├®dureV-F-1. Export de donn├®es▲
Les donn├®es ne peuvent ├¬tre export├®es qu'indirectement. Seul, un pointeur vers ces donn├®es peut ├¬tre export├®. Par l'utilisation de ce pointeur, le programme d'importation peut toutefois obtenir lui-m├¬me les donn├®es.
Vous pouvez utiliser exactement la m├¬me m├®thode pour exporter un label de donn├®e que celle utilis├®e pour un label de code. Il n'y a pas besoin de d├®clarer le label comme ├®tant de donn├®es ou de code. Il en est ainsi parce que la t├óche de v├®rification de l'appartenance du label ├Ā une section de donn├®es ou ├Ā une section de code incombe ├Ā l'├®diteur de liens. Voici un exemple d'export du label de donn├®e┬Ā:
EXPORT DATA_VALUE DD 0Cette instruction exporte l'├®tiquette de donn├®es DATA_VALUE. Le destinataire peut obtenir la valeur de DATA_VALUE de la mani├©re suivante┬Ā:
MOV EBX, [DATA_VALUE] ; EBX = pointeur vers DATA_VALUE
MOV EAX, [EBX] ; EAX = valeur de DATA_VALUEV-F-2. Export par ordinal▲
Normalement, les exports sont nominatifs. Lorsque le chargeur Windows d├®marre le programme, il parcourt les DLL pour y chercher les importations requises par le programme. Cela se fait en confrontant les noms des exportations des DLL aux noms des importations du programme. Pour acc├®l├®rer ce processus avec DLL private, l'exportation et l'importation par ordinal sont parfois utilis├®es. Dans ce cas, le chargeur peut trouver la bonne importation en utilisant simplement un index destin├® ├Ā une table dans la DLL. Notez qu'il est imprudent de le faire dans le cas des DLL du syst├©me Windows puisque les nombres ordinaux des exportations peuvent varier selon les versions de DLL.
Pour utiliser cette m├®thode, il est clairement imp├®ratif que le programme d'exportation sp├®cifie une valeur ordinale pour une exportation particuli├©re et que l'├®diteur de liens ne puisse y apporter aucune modification. Encore une fois, en utilisant GoAsm vous pouvez sp├®cifier la valeur ordinale correcte et la passer au linker via la section .drectve (cependant, les linkers ne supportent pas tous cette pratique).
Voici comment sp├®cifier une exportation par ordinal si les exportations sont list├®es avant que les sections ne soient d├®clar├®es┬Ā:
EXPORTS CALCULATE:2, DATA_VALUE:6Ici, le linker sera charg├® d'utiliser les ordinaux 2 et 6 pour les exportations. Si vous utilisez la m├®thode alternative de d├®clarer les exportations (au sein d'une section) vous pouvez utiliser par exemple┬Ā:
EXPORT:2 CALCULATE:ou dans le cas de donn├®es┬Ā:
EXPORT:6 DATA_VALUE DD 0V-F-3. Export anonyme par ordinal▲
L'export par ordinal n'emp├¬che pas le nom de l'export d'appara├«tre dans l'ex├®cutable final. Il en est ainsi parce que c'est le programme d'importation qui d├®cide d'importer par ordinal ou par nom. Tout ce que le programme d'exportation peut faire se limite ├Ā fixer la valeur ordinale. Cependant, il peut arriver que le programmeur ne souhaite pas qu'un nom pour l'exportation apparaisse dans l'ex├®cutable final. On peut observer de telles exportations ┬½┬Āsans nom┬Ā┬╗ dans les DLL syst├©me par exemple, probablement dans le but de masquer le travail effectu├® par des fonctions particuli├©res. Il est possible de recourir ├Ā ce proc├®d├® dans GoAsm en ajoutant la d├®claration NONAME ├Ā la fin de l'exportation. Par exemple┬Ā:
EXPORT:2:NONAME
CALCULATE:Ici, la valeur du label de code CALCULATE sera export├®e comme nombre ordinal 2, mais le nom de l'exportation n'appara├«tra pas dans l'ex├®cutable final. Cela signifie que si un autre programme essayait d'appeler la fonction CALCULATE, il enregistrerait un ├®chec. La fonction peut seulement ├¬tre appel├®e par ordinal.
V-G. Sauvegarde et restauration des flags et des registres avec USES ŌĆ” ENDU▲
L'instruction USES suivie d'une liste de registres provoque la mise en pile (PUSH) de ces derniers selon l'ordre dans lequel ils apparaissent dans la liste. Puis, jusqu'├Ā ce que ENDU soit rencontr├® dans le script source (ou ENDUSES si vous pr├®f├®rez), tout RET rencontr├® provoquera le d├®pilage (POP) des m├¬mes registres dans l'ordre inverse. Par exemple┬Ā:
ProcX:
USES EAX, EBX, ECX ; pr├¬t ├Ā mettre les registres en pile (PUSH)
CMP EAX, ESI ; le premier mn├®monique rencontr├® rend les PUSHes effectifs
;
; code de la proc├®dure
;
.finnc
CLC ; met ├Ā z├®ro le flag de carry
RET ; on retire tous les registres de la pile en ordre inverse du USES (POP)
; avant d'ex├®cuter le RET
.finc
STC ; met ├Ā 1 le flag de carry
RET ; on retire tous les registres de la pile en ordre inverse du USES (POP)
; avant d'ex├®cuter le RET
ENDU ; on d├®sactive cette action de POP automatique lors d'un RETVous pouvez ├®galement automatiquement empiler (PUSH) et d├®piler (POP) les flags en utilisant l'instruction FLAGS qui est un mot r├®serv├® dans GoAsm┬Ā:
USES FLAGSVous ne pouvez modifier ou compl├®ter la liste des registres ├Ā pr├®server ├Ā l'int├®rieur m├¬me de la proc├®dure. Pour ce faire, vous devez recourir ├Ā une instruction ENDU suivie d'une liste USES actualis├®e. Si vous avez besoin d'un RET ne d├®clenchant pas une restitution automatis├®e des registres, vous devez utiliser RETN qui a la fonctionnalit├® d'un RET ┬½┬Ānormal┬Ā┬╗. Notez que RETN est une directive de l'assembleur et non une instruction processeur.
En programmation 64 bits, vous pouvez utiliser non seulement la version ├®tendue des registres g├®n├®raux (de RAX ├Ā RSP) mais aussi les nouveaux registres 64 bits (R8 ├Ā R15). Vous pouvez ├®galement utiliser les versions 32 bits des registres g├®n├®raux (EAX ├Ā ESP). Ceci, parce que l'opcode du PUSH est identique, qu'il s'agisse de registres 32 ou 64 bits. Donc, si vous assemblez en 32 ou 64 bits,
USES RAX, RBX, RCXproduira le même code que
USES EAX, EBX, ECXCela contribue ├Ā la transportabilit├® de votre code entre les deux plateformes.
V-H. Trames de pile pour Callback en 32 et 64 bits▲
Voir ├®galement l'annexe comprendre la pile - partie 1 et partie 2.
V-H-1. Introduction▲
En programmation Windows, les trames de pile sont n├®cessaires pour les proc├®dures de fen├¬tre, les proc├®dures d'hame├¦onnage (hooking), le sur-classement et le sous-classement, les proc├®dures de chargement et de d├®chargement de DLL et autres callbacks. Les proc├®dures callback sont toutes appel├®es par Windows, en utilisant le propre thread de votre programme.
Dans GoAsm, la cr├®ation et l'utilisation de trames de pile sont enti├©rement automatis├®es lorsque vous utilisez FRAME ŌĆ” ENDF.
Voir la section trames de pile automatis├®es pour savoir comment l'utiliser en pratique.
Entre Windows 32 et 64 bits, les trames de pile sont diff├®rentes et doivent donc ├¬tre trait├®es de mani├©re sp├®cifique. Mais la syntaxe pour utiliser FRAME ŌĆ” ENDF ainsi que leurs instructions d'accompagnement telles que LOCALS et USEDATA ŌĆ” ENDU est la m├¬me sur les deux plateformes. Pour cette raison, lorsque vous utilisez FRAME ŌĆ” ENDF il est possible d'utiliser le m├¬me script source pour les deux. Voir le chapitre ├®criture de programmes 64 bits pour plus d'informations sur la programmation 64 bits en g├®n├®ral.
V-H-2. Trames de pile en Windows 32 bits▲
Le travail d├®volu ├Ā la trame de pile est dict├® par la convention d'appel utilis├®e. Windows 32 bits utilise la convention d'appel standard (STDCALL). Dans ce contexte, la trame de pile dans une proc├®dure de fen├¬tre doit accomplir quatre actions┬Ā:
- acc├®der aux param├©tres envoy├®s par Windows (qui sont justement envoy├®s sur la pile)┬Ā;
- r├®tablissement de l'├®quilibre de la pile avant de retourner ├Ā l'appelant┬Ā;
- allocation d'un espace sur la pile pour les donn├®es locales┬Ā;
- pr├®servation pour Windows du contenu des registres EBX, ESI, EDI et EBP si ces derniers sont appel├®s ├Ā ├¬tre modifi├®s.
Ces quatre actions sont aussi importantes les unes que les autres.
V-H-2-a. Acc├©s aux param├©tres ├Ā partir de la pile▲
Windows pousse les param├©tres sur la pile avant d'appeler votre proc├®dure de fen├¬tre, de la m├¬me mani├©re que vous le faites avant d'appeler une API dans vos programmes. Lorsque Windows appelle une proc├®dure de fen├¬tre, il envoie les param├©tres suivants sous forme de DWords plac├®s sur la pile (les mots utilis├®s ici sont ceux couramment utilis├®s pour les nommer)┬Ā:
| hwnd | handle de la fenêtre |
| uMsg | identificateur de message |
| wParam | donn├®e |
| lParam | donn├®e |
Votre proc├®dure de fen├¬tre a besoin d'acc├®der ├Ā ces param├©tres. Une fa├¦on de le faire est de les extraire de la pile par des POP successifs en tant que donn├®es statiques, mais il est plus judicieux (et plus s├╗r) de conserver ces param├©tres sur la pile et de les adresser directement. Cela vaut d'autant mieux que les proc├®dures de fen├¬tres s'appellent elles-m├¬mes parfois. Cela peut sembler ├®trange, mais un exemple suffira ├Ā s'en convaincre.
Supposons que votre proc├®dure ait besoin de remplir la fen├¬tre avec un mat├®riau appropri├® au bon moment. Ceci s'appelle ┬½┬Āpeindre┬Ā┬╗ la fen├¬tre. Cela se fait en r├®ponse au message Windows WM_PAINT (num├®ro de message 0Fh). Maintenant, la bonne fa├¦on de r├®pondre ├Ā ce message consiste tout d'abord ├Ā appeler l'API BeginPaint, puis ├Ā peindre la fen├¬tre, puis appeler enfin l'API EndPoint. Une des choses que BeginPaint fait est de pr├®parer la fen├¬tre pour la peinture. Ce faisant, elle envoie un autre message ├Ā votre proc├®dure de fen├¬tre, cette fois WM_ERASEBKGND (num├®ro de message 14h). Ainsi, alors que votre proc├®dure de fen├¬tre est aux prises avec ce deuxi├©me message, elle n'est pas encore revenue de l'API BeginPaint. Apr├©s que le deuxi├©me message a ├®t├® trait├®, BeginPaint sera de retour. Ainsi, la proc├®dure de fen├¬tre est-elle r├®cursive, ce qui revient ├Ā dire qu'elle peut revenir sur elle-m├¬me. Pour chaque message (sauf pour hwnd) les param├©tres seront diff├®rents. Si ces derniers sont maintenus sur la pile, cela signifie que chaque fois que la proc├®dure de fen├¬tre sera appel├®e les param├©tres seront conserv├®s sur une partie diff├®rente de la pile et ne pourront pas ├¬tre ├®cras├®s.
Voici, ├Ā titre d'exemple, une trame de pile typique sur 32 bits┬Ā:
TypicalStackFrame:
PUSH EBP ; sauvegarde de EBP qui va ├¬tre alt├®r├® ŌöÉ appel├®
MOV EBP, ESP ; EBP m├®morise la valeur courante du pointeur de pile Ōöś "prologue"
; ; POINT "X"
; ; code pour isoler le message WM_PAINT
PUSH ADDR PAINTSTRUCT
PUSH [hwnd]
CALL BeginPaint ; API pr├¬t ├Ā peindre la fen├¬tre
; ; peinture de la fenêtre et appel de l'API EndPaint
;
MOV ESP, EBP ; r├®tablissement ancienne valeur du pointeur de pile ŌöÉ appel├®
POP EBP ; restauration de EBP Ōöé "├®pilogue"
RET 10h ; retour ├Ā l'appelant en ajustant le pointeur de pile ŌöśPendant toute r├®cursion, ESP sera chang├® dans la mesure o├╣ une utilisation ult├®rieure de la pile interviendra. En revanche, EBP sera toujours sauvegard├® et restaur├® par cette proc├®dure de sorte qu'il pourra toujours ├¬tre invoqu├® pour acc├®der ├Ā la partie correcte de la pile afin que le message soit trait├®.
Cette particularit├® sera probablement mieux illustr├®e en approfondissant le fonctionnement de la pile dans l'exemple qui pr├®c├©de. Dans une proc├®dure de fen├¬tre typique r├®pondant au message WM_ERASEBKGND, prenons un instantan├® de la pile lorsque l'ex├®cution est au point ┬½┬ĀX┬Ā┬╗. La pile va alors ressembler ├Ā ceci (j'ai pass├® sous silence une bonne partie de l'utilisation de la pile par souci de clart├®)┬Ā:

Ici, les param├©tres lParam, wParam, uMsg et hwnd qui sont sur la pile de EBP+3Ch ├Ā EBP+30h sont ceux envoy├®s ├Ā la proc├®dure de fen├¬tre sur le message WM_PAINT. Puis, ├Ā EBP+2Ch nous trouvons l'adresse de l'appelant qui envoie le message WM_PAINT (ce sera un appel en provenance d'une DLL Windows). ├Ć EBP+28h se situe la valeur de EBP enregistr├®e sur la premi├©re instruction d'entr├®e dans la proc├®dure de fen├¬tre sur le message WM_PAINT. Entre EBP+24h et EBP+1Ch on trouve l'utilisation de la pile de votre proc├®dure de fen├¬tre avant que vous n'appeliez l'API BeginPaint. Concr├©tement, ces emplacements seraient occup├®s par deux PUSHes, puis l'adresse de retour sur l'appel de l'API (dans votre proc├®dure de fen├¬tre) mise sur la pile. Le quatri├©me PUSH ici pourrait ├¬tre quelque chose pouss├® sur la pile par BeginPaint lui-m├¬me avant d'envoyer le message WM_ERASEBKGND. En pratique, il pourrait y avoir beaucoup plus d'utilisation de la pile ├Ā l'int├®rieur BeginPaint ici. La prochaine chose que vous voyez ├Ā EBP+14h est ├Ā nouveau lParam. Mais celui-ci est diff├®rent de son homologue situ├® ├Ā EBP+3Ch. Il s'agit du lParam envoy├® avec WM_ERASEBKGND. Le reste des entr├®es ├Ā la valeur actuelle de EBP sont en rapport avec le message WM_ERASEBKGRND.
Voyons maintenant ce qui se produit au retour de BeginPaint. Puisque nous savons que BeginPaint restaurera toujours EBP ├Ā la valeur qui ├®tait la sienne ├Ā l'entr├®e de l'API, nous savons que EBP au retour pointera vers la pile ├Ā EBP+28h dans la trame de pile ci-dessus. ├Ć partir de ce point, vous pouvez voir que les param├©tres ant├®rieurs (ceux envoy├®s avec WM_PAINT) peuvent ├¬tre consult├®s ├Ā l'aide de EBP+8h, EBP+0Ch, EBP+10h et EBP+14h comme avant. Ils ont ├®t├® pr├®serv├®s et n'ont pas ├®t├® ├®cras├®s par l'appel ├Ā BeginPaint et par la r├®cursion dans la proc├®dure de fen├¬tre.
V-H-2-b. Restauration de la pile ├Ā l'├®quilibre avant de retourner ├Ā l'appelant▲
C'est ├®galement le travail de la proc├®dure de Windows que de restaurer la pile ├Ā l'├®quilibre avant qu'elle ne retourne ├Ā l'appelant. Cela implique de d├®placer le pointeur de pile ├Ā une valeur sup├®rieure et multiple de quatre octets (soit un double-mot) pour chaque argument envoy├® (chaque PUSH de l'appelant a r├®duit la valeur de ESP de quatre octets afin qu'il pointe sur un emplacement plus ├®lev├® sur la pile). C'est exactement ce que Windows fait lui-m├¬me lorsque vous appelez une API. Par exemple, dans
PUSH ADDR PAINTSTRUCT
PUSH [hwnd]
CALL BeginPaint ; fait en sorte qu'on puisse ├¬tre pr├¬t ├Ā peindre la fen├¬trele pointeur de pile (ESP) a ├®t├® r├®duit de 8 octets en raison des deux PUSHes avant l'appel de l'API BeginPaint. Mais apr├©s le retour de BeginPaint, le pointeur de la pile r├®cup├©re sa valeur d'origine d'avant les deux PUSHes. Ce r├®tablissement est d├╗ au fait que la pile a ├®t├® incr├®ment├®e de 8 octets en sortie de BeginPaint avant de retourner ├Ā votre code.
La plupart des proc├®dures Windows n├®cessitent quatre param├©tres, de sorte que le pointeur de pile doit ├¬tre incr├®ment├® de 16 octets pour la restaurer. D'autres types de callback ont des nombres diff├®rents de param├©tres. Le SDK de Windows donne les informations appropri├®es sur ceux-ci.
L'appelant peut utiliser ADD ESP, 10h pour ajouter les 16 octets n├®cessaires en retour d'appel, mais le plus simple est de confier ce r├®ajustement ├Ā la proc├®dure elle-m├¬me qui d├®placera donc le pointeur de la pile avant de retourner ├Ā l'appelant en utilisant l'instruction RET suivie d'un nombre, par exemple RET 10h. Cette instruction obtient par un POP l'adresse de retour de l'appelant, incr├®mente le pointeur de pile (registre ESP) du nombre d'octets n├®cessaires - dans ce cas 16 -, puis renvoie finalement l'ex├®cution ├Ā l'adresse de retour de l'appelant.
V-H-2-c. Cr├®ation d'un espace sur la pile pour les donn├®es locales▲
Une autre t├óche importante d├®volue ├Ā la proc├®dure callback est d'allouer, en cas de besoin, un espace aux donn├®es locales. Il s'agit de donn├®es qui sont conserv├®es dans la pile pendant que l'ex├®cution se poursuit dans la proc├®dure callback. Elles sont perdues lorsque l'ex├®cution quitte la proc├®dure. Nous avons d├®j├Ā vu comment les donn├®es sur la pile (sous la forme de param├©tres) sont conserv├®es en constituant une trame de pile. L'espace pour les donn├®es locales utilise le m├¬me principe. Supposons que nous ayons besoin d'espace pour trois DWords sur la pile parce que nous voulons pr├®server ces donn├®es cependant que la proc├®dure de fen├¬tre est en r├®cursion. Le code ├Ā utiliser pourrait ├¬tre le suivant┬Ā:
TypicalStackFrame:
PUSH EBP ; sauvegarde de EBP qui va ├¬tre alt├®r├® ŌöÉ
MOV EBP, ESP ; EBP m├®morise la valeur courante du pointeur de pile Ōöé "prologue"
SUB ESP, 0Ch ; on constitue un espace pour les donn├®es locales Ōöś
; ; POINT "X"
;
; ; code de la proc├®dure de fen├¬tre
;
MOV ESP, EBP ; r├®tablissement ancienne valeur du pointeur de pile ŌöÉ
POP EBP ; restauration de EBP Ōöé "├®pilogue"
RET 10h ; retour ├Ā l'appelant en ajustant le pointeur de pile ŌöśIci, nous avons d├®plac├® le pointeur de pile de 12 octets, ce qui est exactement la m├¬me chose que si nous avions proc├®d├® ├Ā trois PUSH successifs. Ceci permet d'obtenir une zone de la pile qui ne peut ├¬tre utilis├®e ├Ā d'autres fins.
En utilisant FRAME ŌĆ” ENDF vous pouvez cr├®er automatiquement la trame de pile.
Voici une utilisation typique de FRAME ŌĆ” ENDF qui fait la m├¬me chose que TypicalStackFrame ci-dessus et fournit des noms pour les param├©tres qui sont envoy├®s ├Ā la proc├®dure de fen├¬tre et des noms pour chaque DWord de donn├®e locale┬Ā:
WndProc FRAME hwnd, uMsg, wParam, lParam
LOCALS hDC, hInst, KEEP
; ; POINT "X"
;
; ; le code vient ici
;
RET
ENDFLa pile courante appara├«t comme ceci au point ┬½┬ĀX┬Ā┬╗┬Ā:
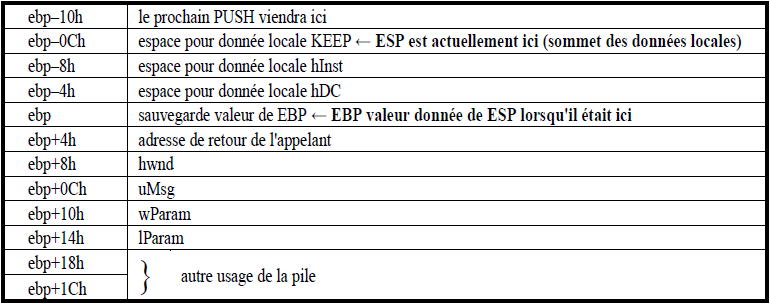
Bien s├╗r, si le pointeur de pile est soumis ├Ā ces d├®placements, il va de soi qu'il doit ├¬tre restaur├® en sortie. Mais cette fois, l'op├®ration est automatique, car EBP est tout simplement restaur├® ├Ā sa valeur avant de retourner ├Ā l'appelant, et EBP avait du reste ├®t├® enregistr├® avant le d├®placement du pointeur de pile pour faire de la place ├Ā des donn├®es locales.
V-H-2-d. Pr├®servation pour Windows des registres EBX, ESI, EDI et EBP▲
Enfin, il est important de rappeler que votre proc├®dure de fen├¬tre se doit de pr├®server les registres EBX, ESI, EDI et EBP. EBP est d├®j├Ā m├®moris├® puis restaur├® respectivement par les codes de prologue et d'├®pilogue. Quant ├Ā EBX, ESI et EDI, il est prudent de les sauvegarder puis les restaurer syst├®matiquement m├¬me s'ils ne sont pas modifi├®s par votre proc├®dure de fen├¬tre afin de pr├®venir une ├®ventuelle modification ult├®rieure de votre code impactant un ou plusieurs de ces registres. Au reste, vous pouvez compter sur le fait quasi certain qu'une API Windows pr├®servera ces registres. Cette caract├®ristique est particuli├©rement utile dans la programmation assembleur parce que vous pouvez conserver les handles utiles ainsi que d'autres valeurs dans ces registres tout en appelant des API. Vous pouvez facilement pr├®server EBX, ESI et EDI en recourant ├Ā l'instruction USES, ainsi que le montre l'exemple suivant┬Ā:
WndProc FRAME hwnd, uMsg, wParam, lParam
USES EBX, ESI, EDI
LOCALS hDC, hInst, KEEP
;
; ; le code est plac├® ici
;
RET
ENDFV-H-3. Trames de piles avec Windows 64 bits ▲
Le travail qui incombe ├Ā la trame de pile est dict├® par la convention d'appel utilis├®e. Windows 64 bits utilise la convention d'appel dite rapide (FASTCALL). Au lieu que l'appelant mette les param├©tres sur la pile comme dans la convention STDCALL, les quatre premiers param├©tres sont mis dans les registres RCX, RDX, R8 et R9. Les ├®ventuels param├©tres compl├®mentaires sont mis sur la pile. Ainsi, la proc├®dure de fen├¬tre doit-elle ex├®cuter les t├óches qui suivent┬Ā:
- enregistrer sur la pile les param├©tres envoy├®s dans les registres et acc├®der ├Ā tous les param├©tres suppl├®mentaires envoy├®s par Windows sur la pile┬Ā;
- fournir un espace sur la pile pour les donn├®es locales┬Ā;
- pr├®server pour Windows les registres dits ┬½┬Ānon volatils┬Ā┬╗ d├©s qu'ils sont modifi├®s. Il s'agit de RBP, RBX, RDI, RSI, R12 ├Ā R15 et XMM6 ├Ā XMM15.
Il n'est pas n├®cessaire que la proc├®dure de fen├¬tre restaure l'├®quilibre de la pile, avant de retourner ├Ā l'appelant. Ce travail est fait par l'appelant.
V-H-3-a. Enregistrement et acc├©s aux param├©tres▲
Les registres RCX, RDX, R8 et R9 sont qualifi├®s de ┬½┬Āvolatils┬Ā┬╗ dans le sens o├╣ Windows ne garantit pas le maintien de leur int├®grit├® au travers d'un appel d'API. Pour autant, ils accueillent les quatre premiers param├©tres d'un appel d'API. Cela signifie que d├©s que votre proc├®dure de fen├¬tre fait un appel d'API, il est possible que les param├©tres soient ├®cras├®es. Pour cette raison, il est n├®cessaire d'en conserver trace quelque part. L'utilisation des registres non volatils pourrait ├¬tre une solution, mais la documentation de Windows recommande qu'ils soient maintenus sur la pile. Apparemment, cela se g├©re dans les API elles-m├¬mes. Dans la convention d'appel FASTCALL telle que document├®e et mise en ┼ōuvre dans Windows 64 bits, l'appelant est tenu de d├®placer RSP n├®gativement de 32 octets avant de faire l'appel afin de fournir un espace sur la pile pour que les param├©tres soient sauvegard├®s. L'espace de pile ainsi r├®serv├® est appel├® - qui l'e├╗t cru┬Ā? - ┬½┬Āespace r├®serv├®┬Ā┬╗. Chaque param├©tre a son propre espace r├®serv├® connu. ├ēvidemment, on pourrait se demander pourquoi FASTCALL a ├®t├® choisi puisque les param├©tres se retrouvent, de toute fa├¦on, sur la pile. Il se dit que cette situation traduirait une intention non aboutie de la part des programmeurs┬Ā!
Pour faire face ├Ā l'obligation d'enregistrer les param├©tres envoy├®s dans les registres, lorsque vous utilisez FRAME ŌĆ” ENDF sur une plateforme 64 bits, il faut savoir que GoAsm g├®n├©re automatiquement des instructions qui prennent l'allure suivante au d├®but de la trame de la pile┬Ā:
MOV [RSP+8h], RCX
MOV [RSP+10h], RDX
MOV [RSP+18h], R8
MOV [RSP+20h], R9
PUSH RBP
MOV RBP, RSPCe code met les param├©tres dans leur espace r├®serv├® sur la pile. S'il y a moins de quatre param├©tres, ces instructions ne sont pas toutes ├®mises. Notez que le cinqui├©me param├©tre, s'il existe, est d├®j├Ā sur la pile ├Ā [RSP+28h], le sixi├©me param├©tre ├Ā [RSP+30h], etc. Les deux derni├©res instructions r├®tablissent RBP dans sa fonction de pointeur vers les donn├®es apr├©s l'avoir pr├®alablement sauvegard├® de telle sorte qu'il puisse ├¬tre restaur├® ult├®rieurement.
Dans l'├®pilogue vous vous attendez ├Ā voir quelque chose comme┬Ā:
LEA RSP, [RBP]
POP RBP
RETL'instruction LEA est utilis├®e ici ├Ā la place d'un simple MOV RSP, RBP de mani├©re ├Ā aider le gestionnaire d'exception Windows ├Ā identifier l'├®pilogue.
V-H-3-b. Construire un espace sur la pile pour les donn├®es locales▲
Cela fonctionne exactement de la m├¬me mani├©re que pour une trame de pile 32 bits sauf que chaque ├®l├®ment de donn├®e locale doit ├¬tre au moins de la taille d'un QWord. Ainsi, pour trois QWords de donn├®es locales, l'instruction destin├®e ├Ā cr├®er la place n├®cessaire devrait s'├®crire SUB RSP, 18h.
V-H-3-c. Pr├®servation des registres non volatils pour Windows▲
RBP est d├®j├Ā sauvegard├® par le code du prologue puis restaur├® par celui de l'├®pilogue. Comme pour les registres ├Ā usage g├®n├®ral, si les registres RBX, RDI, RSI et R12 ├Ā R15 sont modifi├®s par la proc├®dure de fen├¬tre, ils auront besoin de voir leur valeur initiale restaur├®e. La meilleure fa├¦on de le faire est d'utiliser l'instruction USES qui les copie sur la pile. Les registres XMM6 ├Ā XMM15 peuvent ├¬tre sauvegard├®s et restaur├®s en bloc, en utilisant les instructions du processeur FXSAVE et FXRSTOR qui n'agissent toutefois qu'au niveau de l'Unit├® de Calcul en virgule flottante (FPU).
Consid├®rons maintenant l'utilisation assez classique de FRAME ŌĆ” ENDF qui suit┬Ā:
WndProc FRAME hwnd, uMsg, wParam, lParam
USES RBX, RSI, RDI
LOCALS hDC, BUFFER[256]:B
; ; POINT 'X'
; ; le code s'├®crit ici
;
RET
ENDFVoici maintenant comment la trame de pile se pr├®sente en assemblage 64 bits, en utilisant les valeurs de RSP et RBP au d├®but du code au POINT 'X' (notez que RBP affiche 32 octets de moins que RSP affichait en entrant dans la proc├®dure┬Ā: ce d├®calage est d├╗ aux instructions PUSH portant successivement sur les registres RBP, RBX, RSI et RDI)┬Ā:
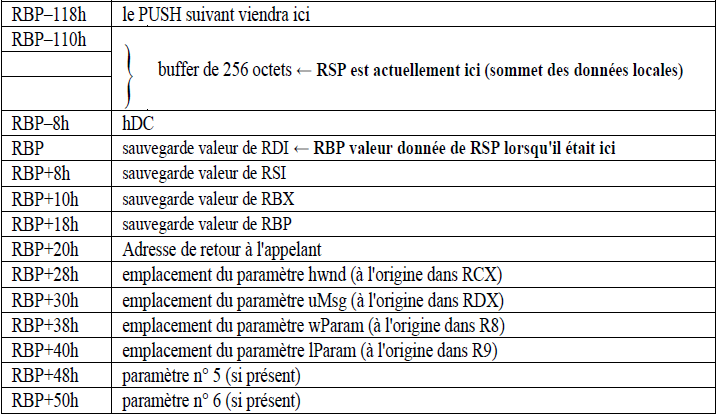
V-I. Trames de pile automatis├®es utilisant FRAME ŌĆ” ENDF, LOCALS et USEDATA▲
V-I-1. Introduction▲
V-I-1-a. Les bases▲
FRAME ŌĆ” ENDF, impl├®ment├® dans GoAsm, est similaire au PROC ŌĆ” ENDP utilis├® dans MASM tout en offrant beaucoup plus de possibilit├®s. Les sous-programmes peuvent ├®galement utiliser les donn├®es sur la pile en utilisant USEDATA ŌĆ” ENDU. Et vous pouvez d├®clarer des donn├®es locales dynamiquement. Cela vous permet, ├Ā l'int├®rieur d'une proc├®dure de fen├¬tre, de d├®clarer uniquement les donn├®es locales qui sont effectivement n├®cessaires ├Ā un message particulier. Vous pouvez utiliser des mots d├®finis localement qui op├©reront uniquement ├Ā l'int├®rieur de l'espace d├®limit├® par FRAME ŌĆ” ENDF ou des zones de USEDATA ŌĆ” ENDU qui leur sont associ├®es.
La syntaxe est plus claire et le script source est beaucoup plus facile ├Ā comprendre, car il n'y a pas de contr├┤le de type ou de param├©tre.
Voici une mani├©re de proc├®der si vous utilisez FRAME ŌĆ” ENDF pour constituer une trame de pile automatis├®e┬Ā:
WndProc FRAME hwnd, uMsg, wParam, lParam
USES EBX, ESI, EDI
LOCALS hDC, BUFFER[256]:B
;
; ; le code s'├®crit ici
;
RET
ENDFLorsque vous utilisez FRAME ŌĆ” ENDF de cette mani├©re, GoAsm cr├®e une trame de pile ├Ā votre insu. Pour cette raison, il convient d'├¬tre un peu m├®fiant. Les programmeurs en assembleur aiment savoir tout ce qui se passe, et c'est d'ailleurs la raison majeure pour laquelle ils utilisent ce langage┬Ā! Nous allons donc d├®crire cette question en d├®tail bien qu'il ne soit pas n├®cessaire d'en conna├«tre les tenants et les aboutissants avec pr├®cision.
Si vous l'estimez n├®cessaire, vous pouvez passer sur ces d├®tails et vous int├®resser plut├┤t au fonctionnement de FRAME ŌĆ” ENDF dans l'exemple de programme Hello World 3 propos├® en annexe.
Dans le code ci-dessus, FRAME prescrit ├Ā GoAsm de constituer une trame de pile automatis├®e dont ENDF marquerait la fin. Les mots apr├©s FRAME sont les param├©tres. Dans notre cas, il y a quatre param├©tres qui ont pour nom ceux qui sont indiqu├®s. Il n'y a pas besoin d'ajouter quoi que ce soit d'autre puisque GoAsm conna├«t la taille des param├©tres. En codage 32 bits, ils sont toujours en format DWord┬Ā; en codage 64 bits, ils sont toujours en format QWord.
USES d├®signe ├Ā GoAsm les registres qui ont besoin d'├¬tre pr├®serv├®s dans la trame. Ici, nous utilisons des registres 32 bits, mais en assemblage 64 bits, l'instruction se lit comme USES RBX, RSI, RDI sans avoir ├Ā modifier le code source (dans le cas de PUSH registre c'est le m├¬me opcode qui est g├®n├®r├® pour chacune des deux plateformes).
LOCALS vous permet de d├®clarer un label pour les donn├®es locales dans la trame. GoAsm ajoute la taille de ces donn├®es locales et r├®serve l'espace ├Ā cet effet sur la pile. Lors de la d├®claration des donn├®es locales, DWord est la valeur par d├®faut en assemblage 32 bits, QWord est la valeur par d├®faut en assemblage 64 bits. La valeur par d├®faut est utilis├®e si vous ne sp├®cifiez pas une taille pour les donn├®es. Ainsi dans l'exemple, hDC est une valeur DWord. Il y a aussi une zone sur la pile appel├®e BUFFER (tampon). Celle-ci est de 256 octets en raison de la notation [256]:B. Au lieu de B, vous pourriez utiliser W, D, Q ou T pour, respectivement, Word, DWord, QWord ou Ten-Word. Vous pouvez ├®galement utiliser le nom d'une structure ainsi que le d├®crit la section utilisation des structures comme donn├®es locales dans une trame de pile.
GoAsm cr├®e automatiquement le code de prologue comme d├®crit dans les sections 32 bits ou 64 bits ci-dessus. GoAsm va ajouter le code d'├®pilogue ├Ā chaque fois qu'il rencontre un RET dans la trame d├®limit├®e par FRAME ŌĆ” ENDF.
V-I-1-b. Acc├©s aux param├©tres et aux donn├®es locales ├Ā l'int├®rieur d'une trame automatis├®e▲
Dans une trame constitu├®e de cette fa├¦on vous pouvez acc├®der aux param├©tres envoy├®s ├Ā la proc├®dure de fen├¬tre. Dans l'exemple suivant ├®crit pour Windows 32 bits, les offsets accol├®s ├Ā EBP qui sont g├®n├®r├®s par GoAsm sont donn├®s sur l'hypoth├©se qu'il n'y a pas de d├®claration USES (le codage 64 bits est tr├©s similaire mais utilise RBP et chaque poste de pile occupe 8 octets au lieu de 4)┬Ā:
PUSH [hwnd] ; ├®quivaut ├Ā PUSH [EBP+8h]
MOV EAX, [uMsg] ; ├®quivaut ├Ā MOV EAX, [EBP+0Ch]
MOV EBX, ADDR wParam ; ├®quivaut ├Ā LEA EBX, [EBP+10h]
PUSH ADDR lParam ; ├®quivaut ├Ā PUSH EBP suivi de ADD D[ESP], 14h
MOV EBX, [hDC] ; ├®quivaut ├Ā MOV EBX, [EBP-10h]
MOV EBX, ADDR BUFFER ; ├®quivaut ├Ā LEA EBX, [EBP-110h]Dans cette portion de code, on voit que GoAsm se charge de trouver sur la pile la bonne position de la variable ├Ā laquelle vous souhaitez acc├®der afin d'en lire ou modifier le contenu. D├©s lors, votre seul souci se r├®duit ├Ā conna├«tre le nom de la variable tout en faisant l'impasse sur sa position au sein de la pile. Si vous utilisez l'option /l sur la ligne de commande, vous pouvez vous rendre compte par vous-m├¬me de la r├®alit├® de ce codage en consultant le fichier-listing. Sinon, vous pouvez ├®galement l'observer en utilisant le d├®bogueur.
Notez que l'adresse du buffer est donn├®e ├Ā son point le plus n├®gatif. Il est donc correct de coder┬Ā:
MOV D[BUFFER+10h], 44hsi vous ins├®rez la valeur 44h ├Ā un DWord dont l'octet le moins significatif est ├Ā 16 octets du d├®but du buffer.
Notez que GoAsm d├®finit la valeur de EBP apr├©s avoir pouss├® en pile (PUSHing) les registres mentionn├®s dans la d├®claration USES. Cette disposition permet ├Ā l'ensemble des donn├®es locales d'├¬tre ajust├® dynamiquement sur une base sp├®cifique ├Ā un message. Mais cela signifie aussi que, si vous avez une d├®claration USES dans un FRAME, l'offset des param├©tres par rapport ├Ā EBP sera plus grand que le contraire. Ainsi, si vous mettez en pile (PUSH) trois registres dans une FRAME avec une d├®claration USES comme suit┬Ā:
USES EBX, EDI, ESIalors, EBP sera mis en pile plus loin et au-del├Ā des param├©tres avec un d├®calage de 12 octets. Donc, dans cet exemple, hwnd serait ├Ā [EBP+14h], Msg ├Ā [EBP+18h], wParam ├Ā [EBP+1Ch] et lParam ├Ā [EBP+20h]. Lors du codage vous ne devez pas vous soucier de la position exacte des param├©tres relatifs ├Ā EBP, mais vous devez ├¬tre au courant de cette particularit├® si vous examinez votre code dans le d├®bogueur. Voir aussi la section ce que vous pouvez voir dans le d├®bogueur.
V-I-1-c. Utilisation de structures comme donn├®es locales dans une trame de pile▲
Dans l'exemple qui suit, les donn├®es locales de taille adapt├®e ├Ā la structure RECT, pr├®alablement d├®clar├®e dans votre script source, sont ├®tablies sur la pile.
RECT STRUCT
left DD 0
top DD 0
right DD 0
bottom DD 0
ENDS
;
WndProc FRAME hwnd, uMsg, wParam, lParam
LOCALS hDC, rc1:RECT
;
; ; le code s'├®crit ici
;
RET
ENDFChaque ├®l├®ment de la structure RECT est accessible de la m├¬me fa├¦on que si elle ├®tait en donn├®es statiques. Par exemple (en utilisant encore des exemples 32 bits)┬Ā:
MOV EAX, [rc1.right] ; ├®quivaut ├Ā MOV EAX, [EBP-0Ch]
MOV EAX, [ESI+RECT.right] ; ├®quivaut ├Ā MOV EAX, [ESI+8h]
MOV EAX, SIZEOF RECT ; ├®quivaut ├Ā MOV EAX, 10h
MOV EAX, ADDR rc1.right ; ├®quivaut ├Ā LEA EAX, [EBP-0Ch]
PUSH [rc1.right] ; ├®quivaut ├Ā PUSH [EBP-0Ch]
PUSH ADDR rc1.right ; ├®quivaut ├Ā PUSH EBP suivi de ADD D[ESP], -0Ch
PUSH ADDR rc1 ; ├®quivaut ├Ā PUSH EBP suivi de ADD D[ESP], -14hV-I-2. Pratique des trames de pile automatis├®es▲
V-I-2-a. Quelques consid├®rations pratiques▲
La mani├©re par laquelle vous voudrez utiliser les facilit├®s offertes par FRAME ŌĆ” ENDF sera une question de choix personnel comme nous allons le voir┬Ā:
- Vous pouvez englober tout votre code de proc├®dure de fen├¬tre dans une trame FRAME ŌĆ” ENDF. Dans ce cas, vous devrez vous assurer que les sous-routines utilisent un RET ┬½┬Ānormal┬Ā┬╗ en utilisant RETN. Vous pouvez souhaiter maintenir la trame FRAME ŌĆ” ENDF aussi compacte que possible, mais acc├®der encore aux param├©tres et donn├®es locales de l'ext├®rieur. Ce sera possible en sp├®cifiant une zone USEDATA ŌĆ” ENDU.
- Vous pouvez d├®clarer des donn├®es locales sous forme de message sp├®cifique plut├┤t que pour la trame de pile dans son ensemble. Vous pouvez le faire en positionnant la d├®claration LOCAL.
- Vous pouvez souhaiter combiner ces m├®thodes avec une table de messages pour cr├®er une proc├®dure de fen├¬tre r├®duite.
- Enfin, vous pouvez vouloir lib├®rer les zones de donn├®es locales et construire ensuite de nouvelles zones de donn├®es locales avec l'instruction LOCALFREE.
V-I-2-b. Appel de proc├®dures ├Ā l'int├®rieur d'une trame de pile - Usage de RETN▲
Vous pouvez avoir autant de points de retour de la proc├®dure FRAME utilisant RET que vous le souhaitez. Chacun va produire un code d'├®pilogue qui sera ex├®cut├® au moment de quitter la trame de pile. Cependant, cela signifie ├®galement que, si vous avez des proc├®dures additionnelles ├Ā l'int├®rieur de la trame de pile, vous devez veiller ├Ā les conclure par RETN (RET ┬½┬Ānormal┬Ā┬╗) pour ├®viter la cr├®ation de code d'├®pilogue pour celles-ci. Il en r├®sulterait en effet des d├®pilages inappropri├®s, source irr├®m├®diable de plantageŌĆ”
Seule la proc├®dure FRAME principale peut ├¬tre appel├®e depuis l'ext├®rieur de celle-ci. L'appel ├Ā d'autres proc├®dures peut entra├«ner des r├®sultats impr├®visibles. Ceci, parce que les proc├®dures dans l'enveloppe FRAME ŌĆ” ENDF s'attendent ├Ā adresser des param├©tres et des donn├®es locales en utilisant le pointeur de pile (RBP ou EBP) alors qu'il n'a pas ├®t├® initialis├® en cas d'appel de l'ext├®rieur.
Voici un exemple concret┬Ā:
WndProc FRAME hwnd, uMsg, wParam, lParam
USES EBX, ESI, EDI
LOCAL hDC, BUFFER[256]:B
MOV EAX, [uMsg] ; r├®cup├®ration du message envoy├® par Windows
CMP EAX, 0Fh ; on regarde si c'est WM_PAINT
JNZ >L2 ; non
CALL WINDOW_PAINT ; on peint la fenêtre
XOR EAX, EAX ; renvoie z├®ro pour montrer que le message est trait├®
RET ; restauration de la pile et retour ├Ā Windows
;
L2:
ARG [lParam], [wParam], [uMsg], [hwnd]
INVOKE DefWindowProcA ; permet ├Ā Windows de traiter avec le message
RET ; restauration de la pile et retour ├Ā Windows
;
WINDOW_PAINT:
; code pour peindre la fenêtre
RETN ; ex├®cute un retour ordinaire de la proc├®dure de peinture
;
ENDF ; stoppe toute action FRAME ├Ā partir de ce point.V-I-2-c. Appel de proc├®dures ├Ā l'ext├®rieur d'une trame de pile▲
V-I-2-c-1. Utilisation de USEDATAŌĆ”ENDU▲
Vous pouvez pr├®f├®rer conserver une trame plus compacte et ne proc├®der ├Ā des CALL qu'en direction de l'ext├®rieur de celle-ci pour accro├«tre la compacit├® de votre code et en am├®liorer ainsi la lisibilit├®. Vous pouvez le faire tout en conservant l'acc├©s aux param├©tres et aux donn├®es locales dans la trame en utilisant la d├®claration de USEDATA suivie du nom de la trame concern├®e. Par exemple, le message WM_PAINT dans la trame ci-dessus pourrait appeler cette proc├®dure┬Ā:
PAINT:
USEDATA WndProc
INVOKE BeginPaint, [hwnd], ADDR lpPaint ; r├®cup├©re en EAX le DC ├Ā utiliser
MOV [hDC], EAX
INVOKE Ellipse, [hDC], [lpPaint.rcPaint.left], \
[lpPaint.rcPaint.top], \
[lpPaint.rcPaint.right], \
[lpPaint.rcPaint.bottom]
INVOKE EndPaint, [hwnd], ADDR lpPaint
XOR EAX, EAX
RET
ENDUNous venons de lister ici le code de la proc├®dure PAINT qui utilise les donn├®es locales dans la FRAME appel├®e WndProc. Tout ce code est ext├®rieur ├Ā l'enveloppe FRAME ŌĆ” ENDF.
Vous pouvez ├®galement utiliser USEDATA pour acc├®der aux donn├®es locales dans d'autres zones USEDATA ŌĆ” ENDU.
Assurez-vous que USEDATA est utilis├®e post├®rieurement dans le script source ├Ā toutes les d├®clarations de param├©tres et de donn├®es locales sur lesquels elle repose. Ceci est d├╗ au fait que GoAsm est un assembleur travaillant en une seule passe et qu'il a besoin, pour ce faire, de trouver la position de ces donn├®es pleinement d├®finie.
Si une proc├®dure appel├®e ├Ā partir d'une zone FRAME ou USEDATA n'a besoin d'acc├®der ├Ā aucun param├©tre, donn├®e locale, ou mot d├®finis localement, alors elle ne doit pas avoir sa propre d├®claration USEDATA.
V-I-2-c-2. Points de sortie multiples ou proc├®dure ├Ā l'int├®rieur d'une zone USEDATA ŌĆ” ENDU▲
Tout comme lors de l'utilisation de FRAME ŌĆ” ENDF, vous pouvez avoir autant de points de retour de la proc├®dure USEDATA utilisant RET que vous le souhaitez. Chacun va produire le code d'├®pilogue appropri├® qui est ex├®cut├® au moment de quitter la zone USEDATA. Cependant, cela signifie ├®galement que si vous avez des proc├®dures suppl├®mentaires au sein de la zone USEDATA vous devez veiller ├Ā utiliser RETN (RET ┬½┬Ānormal┬Ā┬╗) pour ├®viter que l'assembleur ne leur cr├®e un code d'├®pilogue.
Seule la premi├©re proc├®dure USEDATA doit ├¬tre appel├®e depuis l'ext├®rieur de la zone USEDATA ŌĆ” ENDU. Ceci, parce que le code appropri├® pour acc├®der ├Ā la pile ne sera mis en place que pour cette premi├©re proc├®dure.
V-I-3. Utilisation avanc├®e des trames de pile automatis├®es▲
V-I-3-a. D├®claration de donn├®e locale ├Ā message sp├®cifique▲
V-I-3-a-1. Positionnement de l'instruction LOCAL ▲
Dans les exemples expos├®s jusqu'ici, la zone des donn├®es locales localis├®e sur la pile avait ├®t├® d├®clar├®e globalement pour le FRAME. Mais vous pouvez pr├®f├®rer mettre en place tout ou partie des donn├®es locales sur une base de message sp├®cifique. Voici un exemple de cette fa├¦on de faire┬Ā:
WndProc FRAME hwnd, uMsg, wParam, lParam
USES EBX, ESI, EDI
LOCAL hDC ; d├®clare hDC pour un usage de trame ├®tendue
MOV EAX, [uMsg] ; r├®cup├®ration du message envoy├® par Windows
CMP EAX, 0Fh ; est-ce WM_PAINT ?
JNZ >L2 ; non
CALL WINDOW_PAINT ; c'est WM_PAINT, alors on peint la fenêtre
XOR EAX, EAX ; on retourne z├®ro pour signifier que le message a ├®t├® trait├®
RET ; restauration de la pile et retour ├Ā Windows
;
L2:
ARG [lParam], [wParam], [uMsg], [hwnd]
INVOKE DefWindowProcA ; permet ├Ā Windows de traiter avec le message
RET ; restauration de la pile et retour ├Ā Windows
;
ENDF ; arr├¬te toute action de FRAME ├Ā partir de ce point
;
WINDOW_PAINT:
USEDATA WndProc ; utilise les param├©tres et les donn├®es locales de WndProc
LOCAL ps:PAINTSTRUCT ; construit des zones de donn├®es locales
LOCAL BUFFER[1024]:B ; sp├®cifiquement ├Ā ce message
;
ARG ADDR ps, [hwnd]
INVOKE BeginPaint ; pr├¬t ├Ā peindre la fen├¬tre
MOV [hDC], EAX ; sauvegarde le contexte de p├®riph├®rique dans la donn├®e locale hDC
; code pour peindre la fenêtre
RET ; effectue un retour ordinaire de la proc├®dure de peinture
ENDU ; met fin ├Ā l'utilisation de la trame de donn├®es WndProcV-I-3-b. Cr├®ation d'une proc├®dure de fen├¬tre r├®duite▲
En utilisant les m├®thodes d├®crites, vous pouvez cr├®er une proc├®dure de fen├¬tre en utilisant une table de messages. La proc├®dure de fen├¬tre en tant que telle n'a pas besoin d'├¬tre plus complexe que ceci┬Ā:
WndProc FRAME hwnd, uMsg, wParam, lParam
MOV EAX, [uMsg]
MOV ECX, SIZEOF MESSAGES/8
MOV EDX, OFFSET MESSAGES
:
DEC ECX
JS >.notfound
CMP [EDX+ECX*8], EAX ; est-ce le message correct ?
JNZ < ; non, on va voir le suivant...
CALL [EDX+ECX*8+4] ; appel de la proc├®dure correcte pour le message
JNC >.exit
.notfound
INVOKE DefWindowProcA, [hwnd], [uMsg], [wParam], [lParam]
.exit
RET
ENDFQuelque part dans les sections data ou const, on pourrait imaginer le tableau suivant pour les messages (dans la pratique, il y en aurait beaucoup plus que cela)┬Ā:
MESSAGES DD 1h, CREATE ; la valeur du message puis l'adresse du code
DD 2h, DESTROY
DD 0Fh, PAINT
NextLabel:Puis, dans la section de code (et apr├©s WndProc) vous pourriez avoir le code suivant pour le traitement de ces messages┬Ā:
CREATE:
USEDATA WndProc ; utiliser les donn├®es de la pile dans la trame
; de la proc├®dure de fen├¬tre
USES EBX, EDI, ESI ; pr├®servation des registres pour Windows
LOCALS LocalData ; ├®tablissement de la zone de donn├®es locales requise
;
; code ├Ā ex├®cuter sur le message WM_CREATE
;
XOR EAX, EAX ; retourne NC et EAX = 0 pour continuer ├Ā cr├®er la fen├¬tre
RET ; restauration des registres puis RET
ENDU ; arr├¬t de toute action automatique et acc├©s aux donn├®esDans la proc├®dure de fen├¬tre r├®duite, DefWindowProc n'est pas appel├®e ├Ā moins que le message ne se trouve pas dans la table de messages ou que le code du message retourne le flag de Carry ├Ā 1. Certains messages doivent appeler DefWindowProc m├¬me s'ils sont trait├®s par la proc├®dure de fen├¬tre - Voir le SDK Windows ├Ā ce sujet.
V-I-3-c. Mots d├®finis localement utilisant #localdef ou LOCALEQU▲
Dans une zone FRAME ŌĆ” ENDF vous pouvez utiliser des mots d├®finis localement. La d├®finition peut ├¬tre effectu├®e soit dans la zone FRAME ŌĆ” ENDF elle-m├¬me, soit dans une zone USEDATA ŌĆ” ENDU associ├®e.
Leur champ d'application est limit├® aux zones d'action de FRAME ou USEDATA. Voir la section h├®ritage et port├®e d'action avec USEDATA ŌĆ” ENDU pour plus de d├®tails sur la fa├¦on dont cela fonctionne en pratique.
Vous d├®finissez ces mots locaux en utilisant #localdef (ou LOCALEQU si vous pr├®f├®rez - ils font la m├¬me chose).
Par exemple┬Ā:
FrameProc1 FRAME Param
#localdef THING1 23h
THING2 LOCALEQU 88h
;
MOV EAX, THING1 ; d├®finition locale 23h
MOV EAX, THING2 ; d├®finition locale 88h
;
RET
ENDF
;
MyFunction44: USEDATA FrameProc1
#localdef THING3 0CCh
;
MOV EAX, THING1 ; la d├®finition locale devrait ├¬tre 23h
MOV EAX, THING2 ; la d├®finition locale devrait ├¬tre 88h
;
RET
ENDUDans l'exemple ci-dessus, si THING1 et THING2 sont d├®finis globalement (en utilisant #define ou EQU), cette d├®finition est ignor├®e (la d├®finition locale est prioritaire).
#undef a une priorit├® de port├®e locale. Si le mot appel├® ├Ā ├¬tre ind├®fini se trouve sur localement, alors #undef s'applique ├Ā lui. Sinon, #undef s'appliquera ├Ā un label global.
V-I-3-d. Port├®e d'un label r├®utilisable dans les trames de pile automatis├®es▲
On peut acc├®der aux labels r├®utilisables commen├¦ant par un point n'importe o├╣ au sein d'une trame de pile automatis├®e (qui peut ├¬tre ├®tablie ├Ā l'aide FRAME ŌĆ” ENDF). D'autres labels uniques au sein de la trame sont ignor├®s pour cet usage de sorte que, par exemple┬Ā:
ExampleProc FRAME Param
CMP EDX, EAX
JZ >.fin
LABEL1:
XOR EAX,EAX
.fin
RET
ENDF
LABEL2:Ici, le saut vers le label .fin fonctionnera encore malgr├® l'existence de LABEL1. En effet, le label .fin porte sur toute la trame et pas seulement sur le code entre LABEL1 et LABEL2. En d'autres termes, l'utilisation de FRAME ŌĆ” ENDF ├®tend le champ d'application d'un label r├®utilisable ├Ā l'ensemble de la trame.
V-I-3-e. H├®ritage et port├®e avec USEDATA ŌĆ” ENDU▲
Une zone USERDATA ŌĆ” ENDU peut ├¬tre associ├®e soit directement avec une FRAME, soit avec une autre zone USERDATA ŌĆ” ENDU.
Cela permet aux utilisateurs exp├®riment├®s de s├®lectionner les donn├®es locales et les mots d├®finis qu'une zone USEDATA peut utiliser.
La disposition habituelle est d'avoir, pour chaque zone de USEDATA, un enfant de FRAME┬Ā:
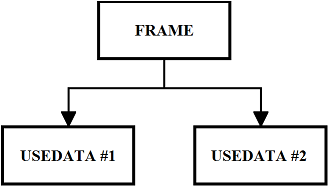
FrameExample FRAME Param
LOCAL LocalLabel1
#localdef CONSTANT 23h
;
RET
ENDF
;
Usedata#1: USEDATA FrameExample
MOV EAX, [LocalLabel1]
MOV EAX, CONSTANT
MOV EAX, [Param]
RET
ENDU
;
Usedata#2: USEDATA FrameExample
LOCAL Specific
#localdef SPECIFIC_CONSTANT 444444h
MOV EAX, [LocalLabel1]
MOV EAX, CONSTANT
MOV EAX, [Param]
MOV EAX, [Specific]
MOV EAX, SPECIFIC_CONSTANT
RET
ENDUIci chaque zone USEDATA peut acc├®der aux param├©tres de FRAME, aux donn├®es locales et aux mots d├®finis. Notez cependant que Usedata#2 a ses propres donn├®es locales et mots d├®finis. Ceux-l├Ā seuls peuvent ├¬tre r├®f├®renc├®s dans Usedata#2. Si Usedata#1 avait essay├® d'y acc├®der (ou le code dans FrameExample, d'ailleurs), ils n'auraient pas ├®t├® trouv├®s.
Dans la repr├®sentation qui suit, la premi├©re zone USEDATA est l'├®manation de FRAME et la seconde zone USEDATA est sa sous-├®manation.
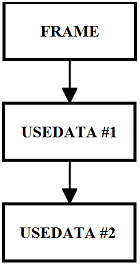
FrameExample FRAME Param
LOCAL LocalLabel1
#localdef CONSTANT 23h
;
R ET
ENDF
;
Usedata#1: USEDATA FrameExample
LOCAL Specific
#localdef SPECIFIC_CONSTANT 444444h
RET
ENDU
;
Usedata#2: USEDATA Usedata#1
MOV EAX, [LocalLabel1]
MOV EAX, CONSTANT
MOV EAX, [Param]
MOV EAX, [Specific]
MOV EAX, SPECIFIC_CONSTANT
RET
ENDUIci, bien que chaque zone USERDATA puisse acc├®der aux param├©tres de la trame, aux donn├®es locales et aux mots d├®finis, Usedata#2 peut ├®galement faire r├®f├®rence ├Ā des donn├®es locales et des mots d├®finis localement dans Usedata#1.
V-I-3-f. Diffusion des donn├®es locales et constitution de nouvelles donn├®es locales▲
V-I-3-f-1. Utilisation de LOCALFREE▲
LOCALFREE est disponible uniquement pour les programmes 32 bits et n'est pas support├® par les modes x86 ou x64 en raison de l'information d'utilisation de la pile en prologue enregistr├®e pour la gestion des exceptions.
Vous pouvez utiliser LOCALFREE pour lib├®rer les zones de donn├®es locales pour en constituer de nouvelles. Cela peut aider ├Ā ├®conomiser de la m├®moire si vous utilisez beaucoup la pile. LOCALFREE rendra une donn├®e locale existante d├®clar├®e dans une FRAME ou une zone USEDATA ŌĆ” ENDU, dans laquelle elle appara├«t, inaccessible ├Ā tout le code plac├® en aval dans votre script source. Il n'affectera pas les donn├®es locales dans d'autres zones FRAME ou USEDATA. Lorsque GoAsm rencontre LOCALFREE dans le script source, il provoque la restauration de ESP/RSP ├Ā sa valeur dans la zone FRAME ou USEDATA avant que toute donn├®e locale n'ait ├®t├® d├®clar├®e. Vous pouvez ensuite d├®clarer de nouvelles donn├®es locales ├Ā l'aide de LOCAL ou LOCALS.
Utilisez LOCALFREE uniquement lorsque la pile est ├Ā l'├®quilibre. Ne l'utilisez pas s'il y a des PUSHes en suspens qui doivent ├¬tre POPp├®s. En effet, le changement d'ESP/RSP effacera en pratique tout PUSH en suspens.
├Ć la fin d'une proc├®dure vous n'avez pas besoin d'utiliser LOCALFREE puisque la pile est restaur├®e automatiquement sur un RET, de toute fa├¦on.
Voici un exemple de la fa├¦on d'utiliser LOCALFREE┬Ā:
CREATE:
USEDATA WndProc ; utilisation des donn├®es de la pile dans la trame
; de la proc├®dure de fen├¬tre
USES RBX, RDI, RSI ; pr├®servation des registres pour Windows
LOCALS BUFFER[4000]:B ; ├®tablissement d'un grand buffer sur la pile
;
; part de code correspondant ├Ā l'ex├®cution sur le message WM_CREATE
;
LOCALFREE ; effacement du grand buffer
LOCALS BUFFER[256]:B ; ├®tablissement d'un buffer plus petit sur la pile
;
; part de code correspondant ├Ā l'ex├®cution sur le message WM_CREATE
;
XOR RAX, RAX ; retourne NC et RAX=0 pour continuer la cr├®ation de la fen├¬tre
RET ; restauration des registres puis RET
ENDU ; met fin ├Ā toute action automatique et acc├©s aux donn├®esV-I-4. Consid├®rations syntaxiques▲
V-I-4-a. Quelques points de syntaxe lors de l'utilisation de FRAME ŌĆ” ENDF▲
- La syntaxe de FRAME ŌĆ” ENDF est comme suit, avec les ├®ventuelles variations mentionn├®es ci-dessous┬Ā:
CodeLabel:
FRAME Parameter List ; si des param├©tres sont n├®cessaires
USES Register List ; s'il est n├®cessaire de sauvegarder des registres
LOCAL Local List ; si des variables locales sont requises
;
ret
ENDF- Une instruction FRAME doit ├¬tre pr├®c├®d├®e par un label, soit imm├®diatement avant sur la m├¬me ligne, soit sur la ligne qui pr├®c├©de. Il s'agit du ┬½┬Ānom de trame┬Ā┬╗.
- Une seule d├®claration FRAME par trame est autoris├®e.
- Tous les param├©tres doivent ├¬tre imm├®diatement apr├©s la d├®claration FRAME, s├®par├®s par des virgules. Pour poursuivre, le cas ├®ch├®ant, sur la ligne suivante, utiliser le caract├©re de continuation ┬½┬Ā\┬Ā┬╗.
- Vous pouvez automatiquement sauvegarder et restaurer les registres ├Ā l'int├®rieur d'une trame avec l'instruction USES. ENDF arr├¬te l'action de USES.
- Les sauts ne peuvent ├¬tre que dans le FRAME lui-m├¬me. En effet, un FRAME a son propre code d'├®pilogue unique qui doit ├¬tre mis en ┼ōuvre.
- Les CALLs peuvent s'adresser ├Ā l'ext├®rieur de la trame. Si vous avez besoin d'acc├®der aux param├©tres de la trame comme les donn├®es locales ou des mots d├®finis, utilisez USEDATA.
- Si vous appelez une fonction dans la m├¬me trame, cette fonction doit utiliser RETN (RET ┬½┬Ānormal┬Ā┬╗) au lieu de RET. Cela emp├¬che la g├®n├®ration d'un code d'├®pilogue au moment de quitter la fonction.
- Les donn├®es locales doivent ├¬tre d├®clar├®es en utilisant une ou plusieurs instructions LOCAL. Apr├©s la premi├©re instruction de code suivante, vous ne serez pas en mesure d'utiliser LOCAL ├Ā nouveau ├Ā moins que vous n'ayez lib├®r├® les donn├®es locales existantes en utilisant l'instruction LOCALFREE.
- LOCALFREE doit être suivie d'une instruction LOCAL ou LOCALS.
- Vous ne pouvez utiliser l'instruction LOCALFREE que si la pile est ├Ā l'├®quilibre (pas de PUSH en suspens devant ├¬tre corrig├® par un POP).
- LOCALFREE n'est pas autoris├® dans les modes x86 ou x64.
- Vous pouvez utiliser LOCALS ├Ā la place de LOCAL si vous pr├®f├®rez.
- Vous ne pouvez pas avoir une d├®claration USEDATA ├Ā l'int├®rieur d'une trame.
- Les labels de port├®e locale (dont le nom commence par un point) vont travailler n'importe o├╣ dans le cadre FRAME ŌĆ” ENDF. Leur limite de port├®e est la trame et l'instruction ENDF elles-m├¬mes, et, en tout cas, aucun autre label qui appara├«t dans la trame.
- Fermez la trame ├Ā l'aide de ENDF (ou ENDFRAME si vous pr├®f├®rez), et ├®ventuellement, faites pr├®c├®der cette instruction par le nom de la trame concern├®e.
- Dans la mesure o├╣ GoAsm est un assembleur travaillant en une seule passe, les donn├®es locales doivent ├¬tre d├®clar├®es dans le script source avant d'envisager leur utilisation.
- Puisque GoAsm s'appuie sur EBP/RBP dans une trame pour acc├®der aux param├©tres et donn├®es locales sur la pile, ne pas modifier ces registres dans la trame ou les proc├®dures appel├®es par la trame ├Ā moins que cet acc├©s ne soit pas n├®cessaire dans la proc├®dure. Si EBP/RBP est chang├® toujours restaurer sa valeur par la suite.
- Une trame peut en appeler une autre et lui passer ainsi les param├©tres sur la pile, mais, dans la mesure o├╣ EBP/RBP seront modifi├®s dans ce processus, les donn├®es originales de la pile ne seront pas accessibles dans la trame appel├®e.
V-I-4-b. Quelques points de syntaxe lors de l'utilisation de USEDATA ŌĆ” ENDU▲
- La syntaxe de USEDATA ŌĆ” ENDU est comme suit, avec les ├®ventuelles variations mentionn├®es ci-dessous┬Ā:
CodeLabel:
USEDATA SourceData
USES Register List ; si les registres ont besoin d'├¬tre sauvegard├®s
LOCAL Local List ; si des variables locales sont requises
;
ret
ENDU- Une instruction USEDATA doit ├¬tre pr├®c├®d├®e par un label, soit imm├®diatement avant, soit sur la ligne qui pr├®c├©de. Il s'agit du ┬½┬Ānom USEDATA┬Ā┬╗.
- SourceData peut ├¬tre un nom de trame ou le nom d'une proc├®dure USEDATA.
- Si SourceData est un nom de trame, les param├©tres et les donn├®es locales ├®tablies dans la trame seront accessibles dans la zone USEDATA ŌĆ” ENDU.
- Si SourceData est le nom d'une proc├®dure USEDATA, alors tous les param├©tres de donn├®es locales et de mots d├®finis qui ├®taient accessibles au sein de cette proc├®dure peuvent ├¬tre consult├®s.
- Vous pouvez automatiquement sauvegarder et restaurer des registres dans une zone USEDATA avec l'instruction USES ŌĆ” ENDU arr├¬te l'action de USES.
- Les sauts ne peuvent ├¬tre que dans la zone USEDATA elle-m├¬me. En effet, une zone USEDATA a son propre code d'├®pilogue unique qui doit ├¬tre mis en ┼ōuvre.
- Les CALLs peuvent s'adresser ├Ā l'ext├®rieur de la zone de USEDATA. Si vous avez besoin d'acc├®der aux param├©tres de donn├®es locales ou de mots d├®finis de la zone USEDATA, constituez une autre zone USEDATA ŌĆ” ENDU.
- Si vous appelez une fonction dans la m├¬me zone USEDATA, cette fonction doit utiliser RETN (RET ┬½┬Ānormal┬Ā┬╗) au lieu de RET. Cela emp├¬che la g├®n├®ration du code d'├®pilogue au moment de quitter la fonction.
- Les donn├®es locales doivent ├¬tre d├®clar├®es en utilisant une ou plusieurs instructions LOCAL. Apr├©s la premi├©re instruction de code suivante, vous ne serez pas en mesure d'utiliser LOCAL ├Ā nouveau ├Ā moins que vous n'ayez lib├®r├® les donn├®es locales existantes en utilisant l'instruction LOCALFREE.
- LOCALFREE doit être suivie d'une instruction LOCAL ou LOCALS.
- Vous ne pouvez utiliser l'instruction LOCALFREE que si la pile est ├Ā l'├®quilibre (pas de PUSH en suspens devant ├¬tre corrig├® par un POP).
- LOCALFREE n'est pas autoris├® dans les modes x86 ou x64.
- Vous pouvez utiliser LOCALS ├Ā la place de LOCAL si vous pr├®f├®rez.
- Une proc├®dure USEDATA peut en appeler une autre sans perte de donn├®es puisque EBP/RBP n'est pas modifi├®.
- Les labels de port├®e locale (dont le nom commence par un point) fonctionnent normalement dans les zones USEDATA. Les labels de codes constituent leur fronti├©re de port├®e.
- Au lieu d'utiliser ENDU pour fermer la zone USEDATA, vous pouvez utiliser ENDUSEDATA en lieu et place. En option, pour des questions de clart├® du script, le nom du USEDATA peut pr├®c├®der cette d├®claration.
- Dans la mesure o├╣ GoAsm est un assembleur travaillant en une seule passe, les donn├®es locales doivent ├¬tre d├®clar├®es dans le script source avant d'envisager leur utilisation.
- Puisque GoAsm s'appuie sur EBP/RBP dans une zone USEDATA pour acc├®der aux param├©tres et aux donn├®es locales sur la pile, ne pas modifier ces registres dans la zone USEDATA ou les proc├®dures appel├®es au sein de la zone USEDATA ├Ā moins que cet acc├©s ne soit pas n├®cessaire dans la proc├®dure. Si EBP/RBP est chang├® toujours restaurer sa valeur par la suite.
V-I-4-c. Ce que vous pouvez voir dans le d├®bogueur▲
Pour ├®tablir et utiliser des trames de pile automatis├®es, GoAsm g├®n├©re du code suppl├®mentaire. Lorsque vous examinez votre code dans le d├®bogueur ce code suppl├®mentaire peut ├¬tre source de confusion et g├¬ner l'identification du code que vous recherchez. Une fa├¦on de voir ce que GoAsm a ins├®r├® est de regarder le fichier listing produit ├Ā l'issue de l'assemblage (option /l dans la ligne de commande).
Voici une br├©ve description de quelques lignes de code suppl├®mentaires que vous pourrez observer.
Dans les trames 32 bits (FRAME), GoAsm commence par mettre en pile EBP et les registres mentionn├®s par USES, puis met la valeur du pointeur de pile ESP dans EBP par MOV EBP, ESP. Sur un RET, cet ordre est invers├®, de sorte que vous verrez MOV ESP, EBP suivi par un ou plusieurs POPs de registre. Un espace est constitu├® pour les donn├®es locales par un simple SUB ESP, x o├╣ x repr├®sente le chiffrage en octets de l'espace requis pour les donn├®es locales.
Dans des trames 64 bits (FRAME), GoAsm commence par m├®moriser sur la pile les param├©tres n┬░┬Ā1 ├Ā n┬░┬Ā4 ├Ā l'aide d'une instruction telle que MOV [RSP+8h], RCX comme d├®crit pr├®c├®demment. Puis apr├©s avoir mis en pile RBP et registres pr├®vus par USES, MOV RBP, RSP est utilis├®e pour allouer ├Ā RBP la capacit├® d'adresser la trame de pile. En sortant de FRAME, l'instruction LEA RSP, [RBP] est utilis├®e pour restaurer RSP pr├¬t ├Ā effectuer un POP des registres et, finalement, un RET.
Le code tel que MOV EAX, [EBP-34h] ou LEA, [EBP-56h] ou PUSH EBP, ADD D[ESP], -60h (ou leurs ├®quivalents utilisant des registres de 64 bits) sera g├®n├®r├® au moment de l'acc├©s aux donn├®es locales. Les valeurs d'offset seront positives lors de l'acc├©s aux param├©tres.
Dans les zones USEDATA, comme GoAsm ne conna├«t pas, au moment de l'assemblage, le nombre d'utilisations de la pile qu'il y a eu avant l'appel ├Ā la proc├®dure USEDATA, il constitue une sorte de bouclier de 100h octets (200h octets en assemblage 64 bits) pour garantir que pareille utilisation de la pile est prot├®g├®e contre les sur-├®critures. Pour cette raison, le nombre de d├®calages utilis├®s lors de l'acc├©s aux donn├®es locales peut ├¬tre plus grand que pr├®vu.
Les utilisateurs exp├®riment├®s pourront proc├®der comme pour ajuster la taille de l'├®cran. Cela peut ├¬tre fait en utilisant cette syntaxe, par exemple┬Ā:
USEDATA WndProc SHIELDSIZE:20h ; en assemblage 32 bits
USEDATA WndProc SHIELDSIZE:40h ; en assemblage 64 bitsCeci restreint la protection ├Ā seulement huit valeurs pouss├®es en pile (huit DWords en assemblage 32 bits, huit QWords en assemblage 64 bits), ce qui serait appropri├® si vous ├®tiez certain qu'au moment de l'ex├®cution il n'y aurait jamais plus de sept PUSHes et un CALL avant la d├®claration de donn├®es locale dans la proc├®dure USEDATA. Rappelez-vous que vous devez compter tous les PUSHs avant le CALL, le CALL lui-m├¬me et tous les sous-appels, ainsi que tout PUSH caus├® par la d├®claration des utilisations dans la proc├®dure de USEDATA. Une fois que SHIELDSIZE est d├®finie, il reste ├Ā cette valeur pendant le reste du script source jusqu'├Ā leur modification.
Dans les zones USEDATA, la valeur du pointeur de pile n'est pas conserv├®e dans le registre EBP/RBP car celui-ci h├®berge d├®j├Ā le pointeur de la pile ├Ā l'entr├®e dans la trame. Au lieu de cela, GoAsm maintient la valeur du pointeur de pile ├Ā un endroit convenable sur la pile. Cela se fait lorsque les premi├©res donn├®es locales de la zone USEDATA sont d├®clar├®es. De mani├©re ├Ā le faire en toute s├®curit├®, GoAsm ajoute plusieurs lignes de code aboutissant ├Ā MOV EAX, [EAX-4h] (ou MOV RAX, [RAX-8h] en assemblage 64 bits). GoAsm utilise EAX/RAX au cours de ce processus, mais restaure sa valeur apr├©s coup, de sorte que vous pouvez toujours l'utiliser pour transmettre des informations ├Ā la proc├®dure. Sur un RET vous verrez la valeur du ESP/RSP en cours de restauration en utilisant POP ESP ou POP RSP selon le cas.
LOCALFREE provoquera aussi une restauration du pointeur de pile.
Les instructions USES provoqueront des PUSHs des registres concern├®s avant que ESP/RSP ne soit sauvegard├® et des POPs de registres apr├©s sa restauration.
V-J. Assemblage conditionnel▲
V-J-1. Qu'est-ce que l'assemblage conditionnel et pourquoi est-il utilis├®┬Ā?▲
L'assemblage conditionnel vous permet de s├®lectionner, lors de la phase d'assemblage, la partie de votre script source que vous souhaitez voir assembl├®e. Cela peut ├¬tre utile si, par exemple, vous voulez constituer diff├®rentes versions de votre programme ├Ā partir d'un m├¬me script source.
V-J-2. Les directives conditionnelles▲
Dans ce domaine, GoAsm utilise simplement la syntaxe du langage C qui est bas├®e sur les directives #if, #ifdef, #else, #elif (ou #elseif) et #endif. La syntaxe de la structure de base d'une directive conditionnelle dans sa forme la plus simple est la suivante┬Ā:
#if condition
text A
#endifIci, si la condition est VRAIE, le texte A sera assembl├®. A contrario, si la condition est FAUSSE, l'assembleur ignorera le texte A et poursuivra la compilation ├Ā partir de #endif.
Vous pouvez ajouter quelque chose ├Ā faire si la condition est FAUSSE de cette mani├©re┬Ā:
#if condition
text A
#else
text B
#endifIci, si la condition est VRAIE, texte A sera assembl├®, mais pas texte B.
A contrario, si la condition est FAUSSE, texte A sera ignor├® et seul texte B sera assembl├®.
Le #endif indique la fin de la trame conditionnelle, de sorte que tout le texte au-del├Ā sera assembl├® normalement.
La d├®claration #else doit toujours pr├®c├®der #endif.
Vous pouvez ajouter une condition suppl├®mentaire ├Ā la structure┬Ā:
#if condition1
text A
#elif condition2
text B
#endifIci, si condition1 est VRAIE, texte A sera assembl├®, texte B sera ignor├® et l'assemblage se poursuivra ├Ā partir du #endif. Toutefois, si condition1 est FAUSSE, texte A ignor├® jusqu'├Ā #elif pr├®c├®dant le test de condition2. Si donc condition2 est VRAIE, texte B sera assembl├®.
Notez, au passage, que ┬½┬Ā#elif┬Ā┬╗ est identique ├Ā ┬½┬Ā#elseif┬Ā┬╗.
L'ajout du #else ├Ā la trame conditionnelle ci-dessus produit┬Ā:
#if condition1
text A
#elif condition2
text B
#else
text C
#endifIci, si condition1 est VRAIE, texte A sera assembl├® tandis que texte B et texte C seront ignor├®s et l'assemblage se poursuivra ├Ā partir du #endif. Toutefois, si condition1 est FAUSSE, texte A sera ignor├® jusqu'├Ā #elif testant condition2. Si donc condition2 est VRAIE, texte B sera assembl├® et texte C ignor├®┬Ā; si, toutefois condition2 est FAUSSE, texte B sera ignor├® jusqu'au #else qui fera que texte C sera assembl├®.
Vous pouvez avoir autant de #elif (ou #elseif) que vous le souhaitez dans chaque trame conditionnelle, mais il ne peut y avoir qu'un #else par trame, et chaque #if doit avoir un #endif correspondant. Certains programmeurs imbriquent les trames conditionnelles, mais cela peut devenir tr├©s confus et ne peut constituer une bonne pratique de programmation. Si toutefois ce choix est retenu, il est recommand├® que vous ├®tiquetiez chaque #endif avec un commentaire de sorte que vous puissiez voir ├Ā quel #if il se r├®f├©re.
V-J-3. Types d'instructions #if▲
#ifdef identifiero├╣ identifier est un mot qui peut ├¬tre d├®fini dans le script source ou dans un fichier d'inclusion. Cette d├®claration renvoie VRAI si identifier est d├®fini et FAUX dans le cas contraire. identifier doit ├¬tre un mot et pas un nombre, ni une cha├«ne entre guillemets.
#ifndef identifiercomme ci-dessus, mais cette d├®claration retourne FAUX si identifier est d├®fini et VRAI s'il n'est pas d├®fini.
#if expressiono├╣ expression peut ├¬tre un nombre, la d├®claration retournant alors FAUX pour 0, et VRAI pour les valeurs non nulles.
o├╣ expression peut ├¬tre un identifier qui ├®value un nombre.
o├╣ expression peut ├¬tre l'op├®rateur d├®fini utilis├® comme suit┬Ā:
defined identifier
defined(identifier)qui renvoie VRAI (1) si l'identifiant est d├®fini, et FAUX (0) s'il n'est pas d├®fini, de mani├©re similaire ├Ā #ifdef.
L'op├®rateur┬Ā! (point d'exclamation) peut ├¬tre utilis├® devant ces expressions simples pour inverser le r├®sultat de la condition, de sorte que par exemple┬Ā:
#if┬Ā!0 retournerait VRAI, et
#if┬Ā!defined identifier retournerait FAUX (0) si identifier ├®tait d├®fini, et VRAI (1) dans le cas contraire, de mani├©re similaire ├Ā #ifndef.
o├╣ expression peut ├¬tre plus complexe et rev├¬tir la forme┬Ā:
identifier op├®rateur-relationnel value
identifier doit ├¬tre un mot d├®fini ailleurs dans le fichier, dans un fichier inclus ou dans la ligne de commande. Il ne peut pas ├¬tre un nombre.
L'op├®rateur relationnel peut ├¬tre l'un des ├®l├®ments suivants┬Ā:
|
sup├®rieur ou ├®gal ├Ā |
|
inf├®rieur ou ├®gal ├Ā |
|
├®gal ├Ā |
|
├®gal ├Ā |
|
diff├®rent de |
|
sup├®rieur ├Ā |
|
inf├®rieur ├Ā |
value peut ├¬tre un nombre ou un mot qui est d├®fini ailleurs dans le fichier, dans un fichier inclus ou dans la ligne de commande, qui ├®value un nombre.
o├╣ expression peut ├¬tre plus complexe, combinant plusieurs expressions avec l'op├®rateur AND conditionnel && ou l'op├®rateur conditionnel OR ||:
expression1 && expression2
expression1 || expression2o├╣ expression1 et expression2 sont l'un des types d'expressions pr├®c├®dents.
L'instruction && renvoie VRAI si expression1 et expression2 sont VRAIES.
Si expression1 est fausse, alors expression2 est pas ├®valu├®e.
L'instruction || renvoie VRAI si expression1 ou expression2 est VRAIE.
Si expression1 est VRAIE, alors expression2 n'est pas ├®valu├®e.
Notez que, pour les expressions multiples avec plusieurs op├®rateurs conditionnels, l'├®valuation de la d├®claration est effectu├®e avec un traitement simple de gauche ├Ā droite. Normalement && a pr├®s├®ance sur ||. Donc si vous placez ces expressions conditionnelles avec && en premier, vous devez obtenir des r├®sultats similaires.
V-J-4. Exemples d'assemblage conditionnel▲
#define HELLO
;
#ifdef HELLO
BSWAP EAX ; inverse l'ordre des octets dans EAX si HELLO est d├®fini
#endif
#if HELLO==3
OUTPUT DD 3h ; si HELLO est d├®fini comme 3, d├®clarer le label de donn├®e OUTPUT ├Ā 3
#elif WINVER>=400h
OUTPUT DD 4h ; donn├®e alternative data si WINVER est ├®gal ou plus grand que 400h
#else
OUTPUT DD 5h ; donn├®e alternative si aucun des cas ci-dessus n'est av├®r├®
#endifVous pouvez d├®finir un mot dans la ligne de commande permettant de d├®clencher la prise en compte des bonnes parties de votre script source pour l'assemblage. Par exemple┬Ā:
GoASM /l /d WINVER=401h MyProg.ASMou simplement
GoASM /l /d VERSIONA MyProg.ASMsignifie que le mot VERSIONA sera d├®fini et qu'il pourra ├¬tre test├® par #ifdef.
Voir ├®galement┬Ā:
V-K. Inclusion de fichiers - #include et INCBIN▲
L'inclusion de fichiers contenant du code assembleur ou simplement des structures et des d├®finitions peut ├¬tre une alternative int├®ressante pour opacifier votre script source en le rendant difficile ├Ā lire et ├Ā suivre. En effet, il faut du temps au lecteur pour se plonger dans le fichier num├®ro 2 pour comprendre le dossier num├®ro 1 et r├®ciproquement. N├®anmoins les fichiers contenant des structures et des d├®finitions Windows sont populaires et GoAsm offre un support complet pour inclure des fichiers.
GoAsm distingue deux types de fichiers ├Ā inclure┬Ā:
| Type | Effet |
| Fichiers avec une extension en ┬½┬Āa┬Ā┬╗ ou ┬½┬ĀA┬Ā┬╗, par exemple MyInclude.asm, ou simplement MyInclude.a |
Avec ce type de fichier, au moment o├╣ l'inclusion est d├®clar├®e dans votre script source, l'assemblage est d├®tourn├® dans le fichier d'inclusion. Et si vous produisez un fichier listing ├Ā l'aide de l'option /l, vous constaterez que le contenu du fichier inclus appara├«t dans le listing g├®n├®ral du programme. Ne pas utiliser ce type de fichier si votre fichier ├Ā inclure ne contient que des d├®finitions, structures et autres. Cela va ralentir GoAsm inutilement, car il va chercher des mn├®moniques et instructions assembleur dans ledit fichier. |
| Fichiers sans extension en ┬½┬Āa┬Ā┬╗ ou ┬½┬ĀA┬Ā┬╗, par exemple MyInclude.inc, ou simplement MyInclude |
Avec ce type de fichier, aucun assemblage n'est effectu├® dans le fichier d'inclusion. Seules les d├®finitions et les structures dans ce fichier sont examin├®es et enregistr├®es. Si vous produisez un fichier listing ├Ā l'aide de l'option /l, vous constaterez que le contenu du fichier inclus n'y appara├«tra pas. Utilisez cette extension si votre fichier d'inclusion ne contient que des d├®finitions, des structures et fonctionnalit├®s similaires (commun├®ment appel├®s fichiers d'en-t├¬te). GoAsm fera un enregistrement de tout cela dans le cas o├╣ ils seraient appel├®s plus tard dans le script source principal. Pour cette raison, un grand fichier d'inclusion va ralentir GoAsm. Normalement GoAsm ne permet pas d'ouvrir des fichiers ├Ā inclure qui ne seraient pas dot├®s d'une extension en ┬½┬Āa┬Ā┬╗ ou ┬½┬ĀA┬Ā┬╗. Une telle restriction contribue ├Ā faciliter la v├®rification des erreurs. Mais il vous est possible de contourner cette fonctionnalit├® si vous voulez permettre, par exemple, aux m├¬mes fichiers d'en-t├¬te d'├¬tre disponibles dans un environnement de compilation parall├©le. Pour ce faire, il vous suffit de sp├®cifier le commutateur /sh (fichiers ┬½┬Āshare header┬Ā┬╗) dans la ligne de commande. |
V-K-1. Syntaxe pour #include▲
#include path\filename
path\filename peut ├¬tre, soit┬Ā:
- une cha├«ne entre guillemets┬Ā;
- une cha├«ne sans guillemets┬Ā;
- une cha├«ne de caract├©res encadr├®e par les symboles ┬½┬Ā<┬Ā┬╗ et ┬½┬Ā>┬Ā┬╗.
GoAsm va chercher le fichier en utilisant le chemin d'acc├©s sp├®cifi├®. Si aucun chemin n'est sp├®cifi├®, il va le chercher dans le r├®pertoire courant. Si le fichier reste malgr├® tout introuvable, il va le chercher dans le r├®pertoire fourni par la cha├«ne d'environnement INCLUDE. Vous pouvez param├®trer la cha├«ne d'environnement INCLUDE en utilisant la commande DOS SET dans la fen├¬tre MS-DOS (invite de commande), ou en appelant l'API SetEnvironmentVariable. Vous pouvez ├®galement utiliser le panneau de configuration (param├©tres syst├©me avanc├®s, variables d'environnement) si votre syst├©me d'exploitation le permet, le tout suivi d'un red├®marrage.
Il peut y avoir une cha├«ne d'environnement diff├®rente pour chaque r├®pertoire ou sous-r├®pertoire. Assurez-vous que la cha├«ne d'environnement que vous souhaitez utiliser est dans le r├®pertoire courant.
Vous pouvez imbriquer des #include file mais il est de bonne pratique d'├®viter cela autant que possible.
V-K-2. Chargement d'un fichier avec INCBIN▲
INCBIN vous permet de charger des morceaux de mat├®riau ├Ā partir d'un fichier directement dans une section de donn├®es ou de code sans autre traitement. Vous pouvez choisir le nombre d'octets ├Ā sauter d├©s le d├®but du fichier et/ou la quantit├® ├Ā charger ├Ā partir du fichier. Voici des exemples de la fa├¦on d'utiliser INCBIN┬Ā:
DATA SECTION
BULKDATA INCBIN MyFile.txt ; charge l'ensemble de MyFile.txt dans la section de
; donn├®es avec le label BULKDATA
INCBIN MyFile.txt, 100 ; ├®vite les 100 premiers octets mais charge le reste du fichier
INCBIN MyFile.txt, 100, 300 ; ├®vite les 100 premiers octets mais charge 300 octetsVoir ├®galement la section insertion de blocs de donn├®es.
V-L. Fusion (merging) - Utilisation de biblioth├©ques de code statiques (.lib)▲
V-L-1. Que sont les ┬½┬Ābiblioth├©ques de code statiques┬Ā┬╗┬Ā?▲
Les biblioth├©ques de code statiques sont des fichiers avec l'extension ┬½┬Ā.lib┬Ā┬╗ contenant un ou plusieurs fichiers objet COFF. Ces fichiers objet contiennent du code et des donn├®es relatifs ├Ā des fonctions pr├¬tes ├Ā l'emploi. Le mat├®riau ├Ā l'int├®rieur du fichier de biblioth├©que est au format binaire (code machine), et non du code source. Les fichiers de biblioth├©que contiennent un index avec une liste des fonctions et les labels de code et de donn├®es qu'ils utilisent. Les biblioth├©ques de code statiques doivent ├¬tre distingu├®es des biblioth├©ques li├®es dynamiquement (DLL) et de biblioth├©ques d'importation qui contiennent simplement une liste des fonctions export├®es par DLL.
V-L-2. Comment utiliser une biblioth├©que de code statique┬Ā?▲
Dans GoAsm, vous pouvez utiliser du code et des donn├®es pr├¬ts ├Ā l'emploi dans des biblioth├©ques de code statiques simplement en appelant la fonction requise dans votre script source, en mentionnant le nom de la biblioth├©que contenant cette fonction. Par exemple┬Ā:
CALL zlibstat.lib:compressVous pouvez ├®galement utiliser des equates pour simplifier le libell├® du CALL, par exemple┬Ā:
LIB1=c:\prog\libs\zlibstat.lib
CALL LIB1:compressEn utilisant INVOKE, ces exemples deviennent┬Ā:
INVOKE zlibstat.lib:compress, [pCompHeap], ADDR ComprSize, [pHeap], [DataSize]
INVOKE LIB1:compress, [pCompHeap], ADDR ComprSize, [pHeap], [DataSize]Si votre chemin d'acc├©s contient des espaces, vous devez mettre le chemin d'acc├©s et le nom de fichier entre guillemets.
V-L-3. Qu'advient-il lorsque vous appelez une fonction issue d'une biblioth├©que┬Ā?▲
Le codage qui pr├®c├©de enjoint ├Ā GoAsm de charger le code et les donn├®es associ├®s et de les fusionner avec le fichier de sortie de GoAsm (fichier objet) lors de l'assemblage. Vous pouvez ensuite envoyer le fichier de sortie au linker de la mani├©re habituelle, mais l'├®diteur de liens n'est pas concern├® du tout par le code et les donn├®es source (le fichier de biblioth├©que)┬Ā: l'ensemble du code et des donn├®es associ├®es ├Ā la fonction ont d├®j├Ā ├®t├® charg├®s par GoAsm. Le seul travail suppl├®mentaire que vous pourriez avoir besoin de faire au moment de la phase d'├®dition de liens est de veiller ├Ā ce que le linker soit inform├® de toutes les DLL suppl├®mentaires n├®cessit├®es par les fonctions pr├¬tes ├Ā l'emploi. Par exemple, une fonction pr├¬te ├Ā l'emploi peut appeler une API Windows dans OLEAUT32.dll. Afin d'├®viter une erreur de ┬½┬Āsymbole introuvable┬Ā┬╗, il est indispensable de mentionner cette DLL dans la ligne de commande de GoLink. Si vous utilisez un autre ├®diteur de liens, vous devez ajouter la biblioth├©que d'importation pour OLEAUT32.dll ├Ā la liste des biblioth├©ques d'importation donn├®e ├Ā l'├®diteur de liens.
V-L-4. Et la m├®thode Microsoft dans tout ├¦a┬Ā?▲
La m├®thode de GoAsm concernant l'utilisation de biblioth├©ques de code statiques diff├©re tr├©s sensiblement de celle utilis├®e par les outils Microsoft. Le MS Linker ajoute le code et les donn├®es au moment de l'├®dition des liens. Si vous pr├®f├®rez, vous pouvez toujours utiliser cette m├®thode avec GoAsm. Pour ce faire vous devez charger les fichiers de sortie de GoAsm dans MS Link et demander ├Ā ce dernier de rechercher les fonctions dans la biblioth├©que de code statique appropri├®e.
Voir la section utilisation de GoAsm avec diff├®rents linkers.
V-L-5. Comment GoAsm trouve le fichier LIB appropri├®▲
Si le chemin d'acc├©s du fichier .lib n'est pas donn├® dans l'appel, GoAsm conduira ses recherches dans le r├®pertoire courant et dans celui donn├® dans l'environnement LIB. Vous pouvez param├®trer la cha├«ne d'environnement LIB ├Ā l'aide de la commande DOS SET dans la fen├¬tre MS-DOS (invite de commande), en appelant l'API SetEnvironmentVariable ou en utilisant le panneau de configuration (param├©tres syst├©me avanc├®s, variables d'environnement) si votre syst├©me d'exploitation le permet, le tout suivi d'un red├®marrage.
Il peut y avoir une cha├«ne d'environnement diff├®rente pour chaque r├®pertoire ou sous-r├®pertoire. Assurez-vous que la cha├«ne d'environnement que vous souhaitez utiliser est dans le r├®pertoire courant.
Vous avez besoin de sp├®cifier une seule fois le chemin d'acc├©s du fichier lib dans votre script source (dans un appel ├Ā un fichier lib) et GoAsm l'utilisera automatiquement pour tous les fichiers lib sp├®cifi├®s du m├¬me nom.
V-L-6. Usage de JMP au lieu de CALL/INVOKE▲
Vous pouvez effectuer un saut vers une fonction de la mani├©re suivante┬Ā:
JMP MyLib.lib:MainProcCette m├®thode peut ├¬tre employ├®e si, par exemple, le code de la biblioth├©que contient un call ├Ā l'API ExitProcess pour mettre fin au programme.
V-L-7. Visualisation du contenu d'un fichier LIB▲
Il est tr├©s utile de pouvoir identifier les fonctions disponibles dans les biblioth├©ques de code statiques. Il existe un certain nombre d'outils disponibles ├Ā cet effet, mais l'un des plus utiles est PEView de Wayne J. Radburn, qui vous permet de visualiser le contenu de diff├®rents fichiers y compris les fichiers lib. Vous pouvez voir ├Ā partir de cet outil que les membres individuels des biblioth├©ques de code statiques sont toujours des fichiers ┬½┬Ā.obj┬Ā┬╗, mais que les membres individuels de biblioth├©ques import├®es sont toujours des fichiers ┬½┬Ā.dll┬Ā┬╗.
DUMPBIN est un utilitaire Microsoft qui est g├®n├®ralement associ├® ├Ā MASM et aux compilateurs C. La ligne de commande LINK -dump (utilisant donc l'├®diteur de liens Microsoft) est fonctionnellement identique et fournit une liste d'options si elle est utilis├®e sans autres param├©tres ├®galement. Il existe diverses options, mais par exemple,
DUMPBIN /LINKER MEMBER: 1 MYLIB.LIB> MyLib.dmpdonnera (dans le fichier MyLib.dmp) des informations sur le premier membre du fichier de biblioth├©que et DUMPBIN /ALL MyLib.lib donnera des informations sur tous les membres.
PEDUMP, enfin, est un utilitaire ├®crit par Matt Pietrek qui peut visualiser, octet par octet, le contenu d'un fichier PE (y compris un fichier lib) d'une mani├©re ordonn├®e (voir ├®galement LIBDUMP du m├¬me auteur).
V-L-8. Vos propres fichiers LIB▲
L'utilitaire Microsoft LIB.EXE, qui repose sur LINK.EXE et aussi MsPDB50.dll, permet d'├®laborer des fichiers de biblioth├©que de code statique. Supposons que vous ayez un fichier objet appel├® calculate.obj qui contient une fonction que vous souhaitez r├®utiliser. Il vous est possible d'en faire une biblioth├©que au moyen de la syntaxe de ligne de commande suivante, par exemple┬Ā:
LIB calculate.objVous obtiendrez ainsi calculate.lib. Et, pour ajouter un autre fichier objet ├Ā cette m├¬me biblioth├©que, vous pouvez proc├®der comme suit┬Ā:
LIB calculate.lib added.objCela va ajouter added.obj ├Ā la biblioth├©que calculate.lib. Ceci est utile si vous voulez garder vos fonctions dans les biblioth├©ques, afin qu'elles puissent ├¬tre r├®utilis├®es sans avoir ├Ā ├®crire ├Ā nouveau le code dans vos scripts source. Ces biblioth├©ques seront ├®galement utiles pour distribuer vos fonctions tout en conservant votre code source ├Ā votre seule discr├®tion. LIB.EXE et ses composants font partie des outils MSDN qui peuvent ├¬tre t├®l├®charg├®s gratuitement ├Ā partir du site Microsoft MSDN (partie du SDK). Le t├®l├®chargement exact ne cesse de changer de sorte que des t├ótonnements seront peut-├¬tre n├®cessaires pour obtenir ces fichiers. Il est fort probable ├®galement que LIB soit rang├® du c├┤t├® d'outils de compilation tels que VC++ ou MASM.
V-L-9. Augmentation de taille de la biblioth├©que de code statique▲
L'appel d'une fonction dans une biblioth├©que de code statique agrandit le fichier de sortie GoAsm au prorata du code et des donn├®es associ├®s de la fonction. Souvent, du reste, la fonction d├®pend elle-m├¬me d'autres fonctions au sein du m├¬me fichier de la biblioth├©que, ce qui entra├«ne encore plus de code et de donn├®es ├Ā charger. Vous pouvez visualiser ce qui est charg├® en utilisant le commutateur /l (├®dition d'un fichier listing) dans la ligne de commande de GoAsm et en examinant le fichier listing r├®sultant. Malheureusement, certains code et donn├®es peuvent ├¬tre charg├®s tout en n'├®tant pas effectivement utilis├®s. Vous pouvez n├®anmoins visualiser les labels de code et de donn├®es inutilis├®s ├Ā l'aide du commutateur /unused de GoLink.
V-L-10. Callbacks et d├®pendance ├Ā l'├®gard des donn├®es▲
Certaines fonctions de fichiers de biblioth├©que s'attendent ├Ā trouver des labels sp├®cifiques de code et de donn├®es ├Ā l'ex├®cutable qui doivent donc imp├®rativement faire partie de votre script source. Par exemple la proc├®dure de callback RegisterDialogClasses et ses variables de donn├®es associ├®es doivent ├¬tre ├®tablies dans votre script source afin d'utiliser SCRNSAVE.LIB pour faire un ├®conomiseur d'├®cran.
V-L-11. Cas des donn├®es sans code▲
Les biblioth├©ques sont destin├®es ├Ā donner acc├©s ├Ā des fonctions au moment de la compilation plut├┤t que simplement des donn├®es. Toutefois, si vous voulez charger une biblioth├©que particuli├©re au moment de la compilation de sorte que vous puissiez acc├®der ├Ā ses donn├®es, vous pouvez appeler un label de code appropri├® dans un code inutilis├® figurant dans votre script source (le label de code n'est jamais appel├®). Par exemple┬Ā:
CALCULATE1:
; lignes de code ici
RET
CALL Lib1:DUMMY ; garantit que Lib1 est charg├® au moment de la compilation
CALCULATE2:
; lignes de code ici
RETV-L-12. Int├®gration du code et des donn├®es, priorit├®s attribu├®es aux labels de m├¬me nom▲
Si vous constituez vos propres fichiers lib, il vous sera utile de comprendre comment le code et les donn├®es de biblioth├©que sont int├®gr├®s au code et aux donn├®es r├®sultant du script source principal. Lors de l'utilisation des biblioth├©ques de code, il est courant de rencontrer des noms de labels identiques, et si cela se produit lors du chargement d'une biblioth├©que, GoAsm utilise seulement l'information associ├®e au tout premier label et ignore celle relative aux autres labels de m├¬me nom.
Supposons, par exemple, que vous ayez une zone de donn├®es appel├® ┬½┬ĀBUFFER┬Ā┬╗ d├®clar├®e soit dans le script source principal, soit dans la biblioth├©que. Il peut y avoir plusieurs fonctions dans le script source principal ou dans les diff├®rents composants de biblioth├©que ou m├¬me dans d'autres biblioth├©ques qui pourraient utiliser BUFFER.
Alors, o├╣ BUFFER devrait-il ├¬tre d├®clar├® et ce que se passerait-il s'il l'├®tait plus d'une fois┬Ā? Une question similaire se pose avec les fonctions. Le code pour celles-ci peut ├¬tre dans le script source principal ou dans une biblioth├©que. Il peut ├¬tre dupliqu├® en plusieurs endroits. La r├®ponse ├Ā ces questions se trouve dans les r├©gles de priorit├®.
Ces r├©gles sont les suivantes┬Ā:
- Le script source principal GoAsm et tous fichiers inclus avec extension en ┬½┬Āa┬Ā┬╗ ont toujours la priorit├®. En d'autres termes, tout label de code ou d├®claration des donn├®es dans les scripts trouveront toujours leur chemin dans le fichier de sortie GoAsm avec le code et les donn├®es auxquels ils apposent des labels┬Ā;
- Sous r├®serve du 1 ci-dessus, les appels formels de la biblioth├©que (utilisant le format library:functionname) ont priorit├® dans l'ordre dans lequel ils sont appel├®s.
Ces r├©gles signifient que les biblioth├©ques de code sont en mesure d'appeler des fonctions et d'utiliser les donn├®es dans les scripts source directement (sans aucune aide de l'├®diteur de liens). Elles signifient ├®galement que tous les labels dans une biblioth├©que qui a d├®j├Ā ├®t├® utilis├®e dans le script source ou dans une biblioth├©que qui a d├®j├Ā ├®t├® appel├®e seront ignor├®s. Supposons par exemple que BUFFER soit d├®clar├® dans le script source avec une taille de 256 octets. Si library1 le d├®clare ├Ā son tour ├Ā 128 octets, ce label est ignor├® et BUFFER sera de 256 octets dans le fichier de sortie. Et de plus, bien que la zone de donn├®es r├®serv├®e ├Ā BUFFER dans library1 soit charg├®e dans le fichier de sortie, le label BUFFER ne la pointera pas et s'en tiendra ├Ā la zone d├®clar├®e dans le script source. Maintenant, si un appel plus tard, Library2 d├®clare BUFFER ├Ā 1024 octets, encore une fois cette zone de donn├®es ira dans le fichier de sortie, mais BUFFER continuera ├Ā pointer la zone de donn├®es d'origine. La raison pour laquelle GoAsm traite ainsi les labels de m├¬me nom est double. Tout d'abord, il serait impossible pour un assembleur (ou un linker d'ailleurs) de d├®terminer quel label est prioritaire au vu de sa taille. En effet, dans GoAsm au moment de l'assemblage et, plus certainement, au moment de l'├®dition de liens, la taille d'une zone particuli├©re point├®e par un label n'est pas connue avec certitude. Ceci, parce que lesdites zones sont parfois agrandies par des zones de code et de donn├®es d├®pourvues de label, ou parfois d'autres labels sont utilis├®s comme pointeurs vers une position interm├®diaire dans la zone.
Les r├©gles ont aussi une signification vis-├Ā-vis de l'ordre dans lequel sont dispos├®es les donn├®es. Supposons que votre biblioth├©que repose sur des donn├®es d├®tenues dans un tampon et ├®galement sur des donn├®es d├®bordant parfois dans une zone ├®largie nomm├®e BUFFER_EXT et d├®clar├®e imm├®diatement apr├©s BUFFER dans la biblioth├©que. Maintenant, dans l'exemple ci-dessus BUFFER ne pointerait pas en r├®alit├® vers l'endroit attendu (juste avant BUFFER_EXT). Au contraire, il pointerait vers la premi├©re d├®claration de BUFFER ailleurs dans la section de donn├®es.
Au terme de cette r├®flexion, je sugg├©rerais donc que les r├©gles suivantes soient respect├®es lors de la cr├®ation de fichiers lib┬Ā:
- Utilisez uniquement des labels de m├¬me nom dans le script source et dans la biblioth├©que si ces labels sont appel├®s ├Ā pointer vers la m├¬me chose au m├¬me endroit, ├Ā savoir, ├Ā la premi├©re d├®clar├®e en tant que label┬Ā;
- Si des labels de donn├®e de m├¬me nom doivent ├¬tre utilis├®s dans diff├®rentes fonctions dans le fichier lib, il faut savoir que la taille de la zone de donn├®es qu'ils identifient sera fix├®e par la premi├©re d├®clar├®e en tant que label. Aussi, ne vous attendez pas ├Ā ce que la zone de donn├®es que le label identifie soit plac├®e dans une position particuli├©re dans l'ex├®cutable.
V-L-13. Utilisation de fichiers-objet uniques▲
Actuellement, GoAsm ne supporte pas d'appeler les m├¬mes fonctions de la biblioth├©que ├Ā partir de plus d'un module (script source). Si tel est le cas, vous verrez appara├«tre des erreurs ┬½┬ĀDuplication de symbole┬Ā┬╗ en provenance de l'├®diteur de liens. Pour contourner ce probl├©me, vous devez concentrer tous les appels ├Ā la biblioth├©que sur la m├¬me fonction dans une biblioth├©que en un seul script source. Dans des versions ult├®rieures de GoAsm et de GoLink un support pourrait ├¬tre ajout├® pour les appels vers la m├¬me fonction de biblioth├©que de plus d'un script source en cas d'utilit├® av├®r├®e pour les utilisateurs.
V-M. Unicode▲
GoAsm et son programme compl├®mentaire GoRC (compilateur de ressources) lisent tous les deux des fichiers Unicode UTF-16 et UTF-8, peuvent prendre leurs commandes en Unicode et produire leur sortie en Unicode. Cela signifie que si vous utilisez un ├®diteur Unicode, il est possible d'utiliser des noms de fichiers, des commentaires, des labels de code et de donn├®es, des mots d├®finis (equates, macros et structs), des exportations et aussi des cha├«nes de donn├®es, tous en Unicode. GoAsm dispose d'un certain nombre de fonctionnalit├®s pour vous aider ├Ā ├®crire des programmes en Unicode ou m├¬me cr├®er une version Unicode et ANSI de votre programme source ├Ā partir d'un seul script. Voir le chapitre ┬½┬Ā├®criture de programmes Unicode┬Ā┬╗ du volume 2 pour plus d'informations sur tous ces sujets.
V-N. Assemblage 64 bits▲
L'utilisation du commutateur /x64 dans la ligne de commande de GoAsm bascule l'assemblage en mode 64 bits, et permet de produire un fichier objet COFF 64 bits au format PE+. GoRC (le compilateur de ressources) et GoLink (l'├®diteur de liens) peuvent ├®galement travailler en 64 bits et produire des ex├®cutables destin├®s ├Ā fonctionner sous Windows 64 bits pour les processeurs AMD64 et EM64T. Bien que le code ex├®cutable 32 bits diff├©re sensiblement de son homologue 64 bits et dans la mesure o├╣ les principes de base utilis├®s dans l'├®criture du code source restent les m├¬mes, il est possible d'utiliser le m├¬me code source pour les deux plateformes. Ce qui fait que le code existant source 32 bits peut ├¬tre port├® ├Ā 64 bits. AdaptAsm.exe peut m├¬me aider ├Ā effectuer cette conversion, le cas ├®ch├®ant.
Voir┬Ā:
V-O. Mode compatible x86 (assemblage 32 bits utilisant un source 64 bits)▲
L'utilisation du commutateur /x86 dans la ligne de commande de GoAsm bascule l'assemblage en mode de compatibilit├® x86 et vous permet de traiter un code source utilisant les registres ├Ā usage g├®n├®ral ├®tendus RAX, RBX, RCX, RDX, RDI, RSI, RBP et RER. Dans ce mode, ces registres sont lus par GoAsm comme s'ils ├®taient EAX, EBX, ECX, EDX, EDI, ESI, EBP et ESP. Cela vous permet d'utiliser des instructions comme┬Ā:
MOV RSI, ADDR String
MOV [RDI], AL
MOV RAX, [hInst]Ces instructions et d'autres semblables vont travailler ├Ā la fois dans les modes de compatibilit├® x64 et x86.
En plus de cela, dans le mode de compatibilit├® x86┬Ā:
- ┬½┬Āx86┬Ā┬╗ devient un mot d├®fini et identifiable pour l'assemblage conditionnel ├Ā l'aide de #if (non sensible ├Ā la casse)┬Ā;
- ARG RAX devient PUSH EAX
- ARG ADDR WNDCLASS devient PUSH ADDR WNDCLASS┬Ā;
- ARG 800h devient PUSH 800h┬Ā;
- ARG [hInst] devient PUSH [hInst]┬Ā;
- INVOKE fonctionne comme STDCALL┬Ā;
- JCXZ instruction fonctionne comme JECXZ.
Notez que le commutateur /x86 ne doit pas ├¬tre utilis├® dans la ligne de commande pour assembler du code source Win32 (ne l'utiliser que pour du code source commutable 32/64 bits).
M├¬me en mode de compatibilit├® x86, vous ne pouvez pas utiliser les nouveaux registres AMD64/EM64RT, R8 ├Ā R15, XMM 8 ├Ā XMM 15, ni les formats d'adressage des nouveaux registres SIL, DIL, BPL, SPL, R8W ├Ā R15W ou R8D ├Ā R15D. En effet, ils ne sont pas disponibles pour une utilisation par un ex├®cutable 32 bits.
Tout code source incompatible avec un ex├®cutable 32 bits doit ├¬tre ├®limin├® au moment de la phase d'assemblage au moyen des techniques d'assemblage conditionnel.
Voir appel des API Windows en 32 bits et 64 bits dans le manuel GoAsm pour plus d'informations ├Ā propos de ARG et INVOKE.
Voir le fichier Hello64World3 comme exemple de code source qui peut produire, soit une fen├¬tre ┬½┬ĀHello World┬Ā┬╗ ├Ā partir d'un programme simple Win32, soit son ├®quivalent en Win64.
Voir aussi le chapitre programmation en 64 bits pour s'informer des diff├®rences entre les programmes 32 et 64 bits.
V-P. Sections - Gestion avanc├®e▲
V-P-1. Attribuer un nom aux sections▲
Le fichier objet attend un nom pour chaque section et GoAsm le fournit par d├®faut. Exprim├® autrement, il n'est pas n├®cessaire du tout de nommer les sections. Les noms par d├®faut utilis├®s par GoAsm sont ┬½┬Ācode┬Ā┬╗ pour une section de code, ┬½┬Ādata┬Ā┬╗ pour une section de donn├®es et ┬½┬Āconst┬Ā┬╗ pour une section const (ou constante).
Vous pouvez, si vous le souhaitez, baptiser une section en faisant suivre la d├®claration de la section par un nom choisi par vous, par exemple┬Ā:
DATA SECTION MySectou
DATA SECTION "Hello are you well?"Chaque section dot├®e d'un nom sera unique. Par cons├®quent, vous pouvez cr├®er autant de sections que vous le d├®sirez en attribuant ├Ā chacune un nom diff├®rent. En temps normal, cependant, vous aurez besoin d'une seule section de donn├®es, d'une section de code et d'une section de const. Dans les programmes plus importants vous pouvez souhaiter avoir plus d'une section. Il est possible que cela puisse rendre le d├®bogage un peu plus facile. Bien que GoAsm vous permette d'utiliser un nom de section de plus de huit caract├©res, l'├®diteur de liens le limitera ├Ā huit caract├©res lorsqu'il constituera l'ex├®cutable.
V-P-2. Ajout de l'attribut ┬½┬Āshared┬Ā┬╗▲
L'attribut shared (flag 10000000h), lorsqu'il est utilis├® dans la section de donn├®es d'une DLL, invite le chargeur de Windows ├Ā fournir une seule copie des donn├®es contenues dans cette section ├Ā chaque ex├®cutable utilisant la DLL. Sans ce flag, chaque ex├®cutable obtiendrait une copie distincte des donn├®es. Cela pourrait ├¬tre le moyen pour un ex├®cutable d'envoyer des donn├®es ├Ā un autre, sans avoir ├Ā utiliser le mappage de fichiers. Pour d├®finir cet attribut ajouter le mot ┬½┬Āshared┬Ā┬╗ juste apr├©s la d├®claration du nom de section, par exemple┬Ā:
DATA SECTION "MyData" SHAREDNoter qu'une section partag├®e (shared) doit avoir un nom unique attribu├® de la mani├©re indiqu├®e ci-dessus. Vous ne voudrez probablement pas utiliser l'un des noms de section par d├®faut, ├Ā savoir ┬½┬Ādata┬Ā┬╗, ┬½┬Ācode┬Ā┬╗ ou ┬½┬Āconst┬Ā┬╗, puisqu'ils sont normalement r├®serv├®s ├Ā des sections non partag├®es.
GoAsm traite toute donn├®e non initialis├®e comme initialis├®e ├Ā z├®ro dans une section partag├®e. Cela ├®vite les probl├©mes qui pourraient se poser si une donn├®e non initialis├®e non partag├®e est ├®galement requise dans un module (il ne peut y avoir qu'une section de donn├®es non initialis├®e dans un fichier objet)┬Ā; ou encore des probl├©mes qui se poseraient au moment de l'├®dition de liens en l'absence de section appropri├®e ├Ā laquelle attacher ces donn├®es non initialis├®es partag├®es.
V-P-3. Ordre des sections▲
GoAsm ins├©re les sections dans le fichier objet dans l'ordre o├╣ elles apparaissent dans le script source. Il est normalement de la responsabilit├® de l'├®diteur de liens d'ordonner les sections dans l'ex├®cutable final. Si l'├®diteur de liens est param├®tr├® pour suivre le m├¬me ordre que celui des fichiers objet, vous pouvez modifier l'ordre des sections dans l'ex├®cutable final en changeant l'ordre de leur d├®claration dans le script source. Dans les sections elles-m├¬mes, vous pouvez demander ├Ā l'├®diteur de liens d'ordonner les ├®l├®ments de donn├®es brutes individuelles d'une certaine mani├©re en ajoutant le suffixe $ au nom de la section. Par exemple┬Ā:
CODE SECTION 'Asm$b'
;
CODE SECTION 'Asm$a'
;Ici, le linker veillera ├Ā ce que le code de la section intitul├®e Asm$a apparaisse dans l'ex├®cutable avant celui de la section intitul├®e Asm$b. En fait, l'├®diteur de liens regroupera le code dans une m├¬me section (appel├®e Asm) et dans l'ordre attendu. Le caract├©re situ├® imm├®diatement apr├©s le signe dollar est utilis├® uniquement pour pr├®ciser l'ordre souhait├® et, lorsque l'on compare les noms de section, l'├®diteur de liens ne consid├©rera seulement que les caract├©res pr├®c├®dant le symbole dollar. Enfin, puisque, dans l'ex├®cutable, les sections ne peuvent pas avoir des noms de plus de huit caract├©res vous devez limiter, dans la pratique, le nombre de caract├©res devant le signe dollar ├Ā 8.
V-P-4. Alignement d'une section▲
Les sections ont un alignement par d├®faut de 16 octets. En d'autres termes, elles commencent sur une adresse multiple de 16. Cette valeur peut ├¬tre modifi├®e pour un fichier objet pour contr├┤ler comment l'├®diteur de liens aligne le contenu de telle section avec le contenu de telle autre section en provenance d'autres fichiers objet. Pour sp├®cifier un alignement de section diff├®rent, ajouter la mention ALIGN value juste apr├©s la d├®claration de section, o├╣ value est la taille de l'alignement requis en octets et prendre les valeurs 1, 2, 4, 8, 16, 32, 64, 128, 256, 512, 1024, 2048, 4096, ou 8192 (ce qui correspond ├Ā la forme 2n). Cela peut ├¬tre utile pour les projets avec plusieurs fichiers sources qui ont besoin de construire diff├®rents tableaux d'informations, par exemple les tables de SEH dans des projets 64 bits┬Ā:
CONST SECTION '.xdata' ALIGN 8
;
;UNWIND_INFO
;
CONST SECTION '.pdata' ALIGN 4
;
;RUNTIME_FUNCTION
;V-Q. Adaptation de fichiers source existants ├Ā GoAsm▲
├Ć l'origine, AdaptAsm.exe a ├®t├® ├®crit dans le but d'all├®ger les t├óches de modification de syntaxe rendues n├®cessaires pour adapter des fichiers source existants issus d'autres assembleurs ├Ā la syntaxe 32 bits de GoAsm. AdaptAsm.exe peut maintenant aider ├Ā l'adaptation de la syntaxe 32 bits GoAsm (ou peut-├¬tre un autre assembleur) en syntaxe 64 bits. Pour plus de d├®tails sur ce sujet, voir la section utilisation de AdaptAsm pour aider ├Ā convertir en format 64 bits.
AdaptAsm s'utilise ├Ā partir de la simple ligne de commande suivante┬Ā:
AdaptAsm [command line switches] inputfile[.ext]Si aucune extension du nom du fichier d'entr├®e n'est sp├®cifi├®e, l'extension .asm est pr├®sum├®e.
Si aucune extension du nom du fichier de sortie n'est sp├®cifi├®e, l'extension .adt est pr├®sum├®e.
Les commutateurs de ligne de commande sont┬Ā:
|
affiche l'aide. |
|
adapte un fichier A386. |
|
adapte un fichier MASM. |
|
adapte un fichier NASM. |
|
sp├®cifie le chemin d'acc├©s du fichier de sortie. Ex┬Ā: AdaptAsm /fo GoAsm\adapted.asm. |
|
cr├®e un fichier de sortie avec l'extension .log. |
|
supprimer l'alerte pr├®c├®dant toute ├®criture sur le fichier d'entr├®e. |
|
adapte le fichier ├Ā la plateforme 64 bits. |
Vous pouvez assimiler un fichier TASM ├Ā un fichier MASM s'il est ├®crit dans le mode MASM. Je n'ai pas inclus de version concernant le mode id├®al TASM.
AdaptAsm cr├®e le fichier de sortie en utilisant le m├¬me nom et le m├¬me chemin d'acc├©s que ceux du fichier d'entr├®e, mais avec l'extension .adt (sauf si un nom et un chemin diff├®rent sont sp├®cifi├®s). Le fichier de sortie rend compte, en son d├®but, du nombre de modifications rendues n├®cessaires et ex├®cut├®es par la fonction d'adaptation.
AdaptAsm ne peut pas ├®crire dans le fichier source, sauf si le fichier de sortie porte le m├¬me nom, extension comprise. M├¬me dans ce cas, il vous sera demand├® de confirmer votre souhait d'├®craser le fichier, sauf bien ├®videmment si le commutateur /o a ├®t├® mentionn├® dans la ligne de commande. Je vous sugg├©re de n'opter pour le remplacement du fichier d'origine que si vous en d├®tenez une copie quelque part. Je n'ai pas ├®crit d'antidote┬Ā!
Si le commutateur /l est sp├®cifi├®, AdaptAsm produit un fichier de sortie de m├¬me nom et de m├¬me r├®pertoire que le fichier de sortie mais avec l'extension .log. Cela montre les changements qui ont ├®t├® faits. Les num├®ros de ligne fournis font r├®f├®rence aux num├®ros de lignes du fichier d'entr├®e.
V-Q-1. Ce que fait Ad convertit diff├®rents fichiers source▲
| Pour l'effet du commutateur /x64 voir utilisation de AdaptAsm pour faciliter la conversion en programmes 64 bits | |||
| Action |
fichiers utilisant |
fichiers utilisant |
fichiers utilisant |
|
Sauf si le mot est d├®fini (par ex. au moyen d'un equate), les crochets sont ajout├®s ├Ā toutes les r├®f├®rences de m├®moire o├╣ ils ne sont pas d├®j├Ā pr├®sents, par exemple┬Ā: MOV EBX, MEM_REFERENCE devient MOV EBX, [MEM_REFERENCE] mais MOV EBX, OFFSET MEM_REFERENCE est laiss├® seul. |
oui | oui | non |
|
Met les r├®f├®rences m├®moire agr├®ment├®es de crochets dans la forme correcte, par exemple┬Ā: MOV DX, sHEXw[ECX*2] devient MOV DX, [sHEXw+ECX*2]. |
oui | oui | non |
| Ajoute ADDR ├Ā des r├®f├®rences m├®moire NASM qui ne disposent pas des crochets. | non | non | oui |
| Les indicateurs de type et les remplacements BYTE, BYTE PTR, WORD, WORD PTR, DWORD, DWORD PTR, QWORD, QWORD PTR, et TWORD, TWORD PTR sont remplac├®s respectivement par les raccourcis ├®quivalents B, W, D, Q et T. | oui | oui | oui |
|
Renverse l'ordre de tous les messages imm├®diats entre guillemets afin qu'ils soient lus dans le bon sens, par exemple┬Ā: MOV [ESI], 'exe.' devient MOV [ESI], '.exe' MOV EAX, 'morf' devient MOV EAX, 'from' DW 'GJ' devient DW 'JG' DD 'dcba' devient DD 'abcd'. |
oui | oui | non |
| Change HELLO LABEL en HELLO:. | oui | oui | non |
| Le label local @@: de MASM et les sauts correspondants @F et @B sont convertis au format GoAsm. Ils re├¦oivent des num├®ros de s├®quence dans le fichier et, le cas ├®ch├®ant, l'indicateur de sens ┬½┬Ā>┬Ā┬╗ est ajout├® dans les instructions de saut. | non | oui | non |
| Les labels locaux de NASM pr├®c├®d├®es d'un point - par exemple ┬½┬Ā.23┬Ā┬╗ - sont convertis au format GoAsm. Le nombre reste inchang├®, mais le cas ├®ch├®ant, l'indicateur de sens ┬½┬Ā>┬Ā┬╗ est ajout├® dans l'instruction de saut. | non | non | oui |
| Dans les instructions de saut, les indicateurs de proximit├® NEAR et SHORT sont enlev├®s car plus du tout utilis├®s. | oui | oui | oui |
|
Remplace les registres FPU d├®sign├®s seulement par un chiffre (0 ├Ā 7) par la syntaxe ST0 ├Ā ST7. Par exemple┬Ā: FDIV 0, 1 devient FDIV ST0, ST1. |
oui | non | non |
|
Change les registres FPU exprim├®s sous la forme ST(0) ├Ā ST(7) en ST0 to ST7, par exemple┬Ā: FDIV ST(0), ST(1) devient FDIV ST0, ST1. |
non | oui | non |
|
Les d├®clarations de donn├®es effectu├®es par BYTE, ACHAR, SBYTE, sont chang├®es en DB. Les d├®clarations de donn├®es effectu├®es par WORD, SWORD, SHORTINT sont modifi├®es en DW. |
non | oui | non |
|
Les d├®clarations de donn├®es effectu├®es par BYTE, ACHAR, SBYTE, sont chang├®es en DB. Les d├®clarations de donn├®es effectu├®es par WORD, SWORD, SHORTINT sont modifi├®es en DW. Les d├®clarations de donn├®es effectu├®es par DWORD, HDC, ATOM, BOOL, HDWP, HPEN, HRGN, HSTR, HWND, LONG, LPFN, UINT, HFILE, HFONT, HICON, HHOOK, HMENU, HRSRC, HTASK, LPINT, LPSTR, LPVOID, WCHAR, HACCEL, HANDLE, HBRUSH, HLOCAL, LPARAM, LPBOOL, LPCSTR, LPLONG, LPTSTR, LPVOID, LPWORD, SDWORD, WPARAM, HBITMAP, HCURSOR, HGDIOBJ, HGLOBAL, INTEGER, LONGINT, LPBYTE, LPCTSTR, LPCVOID, LPDWORD, LRESULT, POINTER, WNDPROC, COLORREF, HPALETTE, HINSTANCE, HINTERNET, HMETAFILE, HTREEITEM, HCOLORSPACE, LOCALHANDLE, GLOBALHANDLE, HENHMETAFILE sont toutes chang├®es en DD. Les d├®clarations de donn├®es effectu├®es par QWORD et DWORDLONG sont chang├®es en DQ. Les d├®clarations de donn├®es effectu├®es par TWORD sont chang├®es en DT. |
non | oui | non |
| La duplication de syntaxe de donn├®es TIMES utilis├®e dans NASM est chang├®e par la m├®thode DUP de d├®claration de donn├®es multiple. De m├¬me, RESB / RESW / RESD utilis├®s dans NASM pour r├®server les donn├®es non initialis├®es sont remplac├®s par la m├®thode DUP? de d├®claration des donn├®es non initialis├®es. | non | non | oui |
| TEXTEQU est chang├® dans sa version de type ┬½┬ĀC┬Ā┬╗ #define. Les equates EQU et = ne sont pas chang├®es car support├®es par GoAsm. | non | oui | non |
| La directive INCLUDE est remplac├®e par #INCLUDE. | oui | oui | oui |
| La directive %INCLUDE est remplac├®e par #INCLUDE. | non | non | oui |
|
La s├®rie de directives IF / ELSE / ELSEIF / ENDIF / IFDEF (assemblage conditionnel) est remplac├®e par #IF / #ELSE / #ELSEIF / #ENDIF / #IFDEF. Les directives .IF /.ELSE /.ELSEIF /.ENDIF / .IFDEF et .WHILE et .BREAK ne sont pas trait├®es. Elles doivent ├¬tre ├®limin├®es et le process r├®├®crit manuellement en cons├®quence. |
non | oui | non |
|
La s├®rie de directives %IF / %ELSE / %ELSEIF / %ENDIF / %IFDEF (assemblage conditionnel) est remplac├®e par #IF / #ELSE / #ELSEIF / #ENDIF / #IFDEF. La directive %DEFINE est remplac├®e par #DEFINE. |
non | non | oui |
| Commentaires sur toutes les lignes commen├¦ant par EXTERNE ou EXTERN, GLOBAL, ou PUBLIC. | oui | oui | oui |
| PROC est remplac├® par FRAME et ENDP par ENDF. Dans le code de MASM, les param├©tres et la d├®claration USES sont ├®quivalents ├Ā la syntaxe GoAsm. | oui | oui | non |
| La taille des donn├®es LOCAL dans une trame de pile automatis├®e est remplac├®e par des versions plus abr├®g├®es dans GoAsm (B, W, Q, T) et D est supprim├® compl├©tement car correspondant ├Ā la valeur par d├®faut dans GoAsm. | non | oui | non |
| Change EVEN en ALIGN. | oui | oui | oui |
| Plusieurs lignes qui ne supportent pas de commentaire, par exemple NAME, TITLE, SUBTITLE, SUBTTL, PROTO lines etc. | oui | oui | oui |
| Plusieurs lignes que GoAsm ne prend pas en charge sont tout simplement supprim├®es. Par exemple .ERR, .EXIT, .LIST, .286 etc. | oui | oui | oui |
| Le mot COMMENT est remplac├® par un point-virgule. | oui | oui | oui |
V-Q-2. Ce que AdaptAsm ne fait pasŌĆ”▲
Malgr├® le traitement de votre script de source par AdaptAsm vous devrez┬Ā:
- V├®rifier la d├®claration des sections. La syntaxe primaire de GoAsm est DATA SECTION, CODE SECTION, CONST SECTION ou CONSTANT SECTION, mais CODE (ou .CODE), DATA (ou .DATA), et CONST (ou .CONST) sont ├®galement accept├®s.
- Ajouter des indicateurs de type aux instructions o├╣ ce type ne va pas de soi pour GoAsm.
- Convertir les macros ├Ā la syntaxe GoAsm (si vous avez encore besoin d'elles avec GoAsm).
- Si vous utilisez MASM, vos initialisations de structure peuvent utiliser, soit les d├®limiteurs <ŌĆ”>, soit les d├®limiteurs {ŌĆ”}. Pour GoAsm vous devez vous assurer que seuls les d├®limiteurs <ŌĆ”> sont utilis├®s ├Ā cet effet (les d├®limiteurs {ŌĆ”} ├®tant r├®serv├®s ├Ā l'initialisation des membres individuels comme dans TASM - voir plus).
- Si vous utilisez NASM, convertir vos mod├©les de structure ├Ā la syntaxe GoAsm.
- Si vous utilisez NASM, v├®rifier tous les sauts de labels locaux d├®finis ├Ā l'int├®rieur de labels non locaux (par ex. JZ MyProc.34) et renommer si n├®cessaire.
- V├®rifier tous les labels de la section de code qui ont deux points (AdaptAsm ne le fait pas, de peur de l'ajout inopin├® de deux points ├Ā un non-label).
- V├®rifiez que AdaptAsm n'a pas ajout├® des crochets pour encadrer des equates, des noms de macro et de STRUC. AdaptAsm tente n├®anmoins d'obtenir une liste compl├©te de ceux-ci et d'├®viter de leur donner ainsi des crochets dans la mesure du possible.
- V├®rifiez si tous les CALLs ou JMPs qui comporteraient des r├®f├®rences de m├®moire entre crochets (ce qui serait inhabituel). AdaptAsm n'ajouter pas de crochets pour ces instructions.
- Convertir toutes les instructions MASM REPEAT, .REPEAT, REPT, .UNTIL, .UNTILCXZ WHILE, .WHILE, .ENDW, .IF / .ELSE / .ELSEIF / .ENDIF par les instructions traditionnelles de l'assembleur CMP, TEST, LOOP et des instructions de saut.
- V├®rifiez que toutes les lignes utilisant des remplacements de segment (segment overrides) sont correctement cod├®es.
- Remplacer toute utilisation de SIZESTR par le proc├®d├® de codage utilisant l'op├®rateur $ (position du pointeur d'instructions courant).
- Si vous avez utilis├® TYPEDEF, sa suppression et son remplacement par un script appropri├® sont indispensables.
- Si vous utilisez mod├©les de structures MASM, veiller ├Ā ce que les symboles ┬½┬Āsup├®rieur ├Ā┬Ā┬╗ et ┬½┬Āinf├®rieur ├Ā┬Ā┬╗ sont utilis├®s ├Ā la place des accolades pour une initialisation s├®quentielle.
- Si vous utilisez mod├©les de structures MASM, veiller ├Ā ce que les symboles ┬½┬Āsup├®rieur ├Ā┬Ā┬╗ et ┬½┬Āinf├®rieur ├Ā┬Ā┬╗ sont utilis├®s ├Ā la place des accolades pour une initialisation s├®quentielle.
- Comme il n'y a pas de priorit├® des op├®rateurs dans GoAsm, v├®rifier toutes les op├®rations arithm├®tiques s'appuyant sur une priorit├® particuli├©re. Par exemple, MOV EAX, 8+8*2 ├®quivaut ├Ā 32 avec GoAsm.
- Lors de la conversion PROC ŌĆ” ENDP en trames de pile automatis├®es FRAME ŌĆ” ENDF, GoAsm ignore l'attribut STDCALL, qui est la norme dans Windows 32 bits. Il devrait de toute fa├¦on ├¬tre retir├® pour Windows 64 bits qui utilise FASTCALL (GoAsm commute automatiquement entre les deux). Si vous avez utilis├® d'autres attributs apr├©s PROC vous pouvez probablement les supprimer enti├©rement - GoAsm les laisse seuls - en les v├®rifiant ├Ā la main.
Bien que AdaptAsm explore les fichiers ┬½┬Āinclude┬Ā┬╗ afin d'obtenir des renseignements sur les equates, les macros et des mod├©les de structure, il n'adapte pas ces fichiers. S'il y a du code ou des donn├®es dans ces fichiers, vous devez les soumettre individuellement ├Ā AdaptAsm de la m├¬me mani├©re que pour le script principal.
VI. Divers▲
VI-A. Instructions PUSH sp├®ciales▲
VI-A-1. Demi-op├®rations de pile▲
Ne s'applique qu'├Ā la programmation 32 bits.
Dans Win32, les donn├®es sur la pile sont g├®r├®es en DWords, et la valeur du pointeur ESP est toujours sur une limite DWord apr├©s une op├®ration PUSH ou POP. GoAsm prend cependant en charge des demi-op├®rations de pile, qui consistent ├Ā effectuer des PUSH et des POP sur deux octets seulement au lieu de quatre. Lorsque vous utilisez ces instructions, vous devez effectuer un PUSH ou un POP une seconde fois pour maintenir ESP ├Ā un multiple de DWord. Pour rendre la syntaxe explicite, GoAsm requiert l'utilisation de PUSHW et POPW pour ces op├®rations de demi-pile. PUSH et POP ne peuvent pas ├¬tre utilis├®s car ils effectuent syst├®matiquement une op├®ration de pile DWord. ├Ć titre d'exemple, les instructions de demi-pile peuvent ├¬tre utilis├®es en r├®ponse au message WM_LBUTTONDOWN┬Ā:
MOUSEX_POS DD 0
MOUSEY_POS DD 0
PUSH [EBP+14h] ; met lParam sur la pile
POPW [MOUSEX_POS] ; extrait de la pile le mot le moins significatif
POPW [MOUSEY_POS] ; puis le mot le moins significatifOu lorsque vous utilisez certaines API qui re├¦oivent certaines donn├®es de la pile respectivement dans le mot de poids fort et celui de poids faible┬Ā:
PUSH ADDR lpFileTime
PUSHW [wFatTime]
PUSHW [wFatDate]
CALL DosDateTimeToFileTimeGoAsm supporte ├®galement les instructions PUSHAW, PUSHFW et POPFW, POPAW, bien que vous ne devriez normalement pas y recourir dans la mesure o├╣ GoAsm est utilis├® uniquement en programmation 32 bits.
VI-A-2. Sauvegarde en pile des flags et restauration▲
Au lieu d'utiliser PUSHF et POPF pour, respectivement, sauvegarder en pile et restituer les flags (mot d'├®tat), vous pouvez recourir, si vous pr├®f├®rez, ├Ā┬Ā:
PUSH FLAGSet
POP FLAGSCette fonctionnalit├® peut ├®galement ├¬tre utilis├®e avec INVOKE et USES.
FLAGS est donc un mot r├®serv├® de GoAsm et ne peut ├¬tre utilis├® comme un label.
Voir ├®galement┬Ā:
VI-B. Changements de segment▲
En programmation Windows, les remplacements de segments sont tr├©s rarement utilis├®s et g├®n├®ralement limit├®s au registre de segment FS.
Dans GoAsm, le remplacement de segment peut se situer avant ou apr├©s le mn├®monique, et rev├¬tir les formes suivantes┬Ā:
FS OR D[24h], 100h
OR FS D[24h], 100h
FS MOV [ESI], EAX
MOV FS[ESI], EAXPour autant, les remplacements de segments ne peuvent pas ├¬tre dans une position o├╣ ils risqueraient d'├¬tre confondus avec un registre de segment, pas plus qu'ils ne peuvent d'ailleurs se situer ├Ā l'int├®rieur des crochets, de sorte que les configurations suivantes sont ├Ā proscrire imp├®rativement┬Ā:
PUSH FS[0] ; utiliser plut├┤t FS PUSH [0]
POP FS[0] ; utiliser plut├┤t FS POP [0]
MOV [FS:0], EAX ; utiliser plut├┤t FS MOV [0], EAXVI-C. Utilisation de l'information du script source▲
L'information du script source suivante est disponible au moment de la compilation┬Ā:
@line ; ligne courante en cours d'assemblage
@filename ; nom de fichier du script source principal en cours d'assemblage
@filecur ; fichier courant en cours d'assemblageCes mots sont insensibles ├Ā la casse des caract├©res utilis├®s. @filecur montre le fichier suivant courant dans un include de fichier en ┬½┬Āa┬Ā┬╗, alors que @filename montre le nom du tout premier script source soumis ├Ā GoAsm au d├®marrage.
@line fournit un entier de 32 bits qui peut ├¬tre utilis├® comme suit┬Ā:
MOV EAX, @line ; EAX r├®cup├©re le num├®ro de ligne
PUSH @line ; le num├®ro de ligne est pouss├® en pile
DD @line ; le num├®ro de ligne est d├®clar├® en m├®moire@filename et @filecur fournissent des pointeurs vers une cha├«ne contenant le nom et peuvent ├¬tre utilis├®s comme suit┬Ā:
PUSH @filename ; pointeur vers cha├«ne termin├®e par un z├®ro
DB @filename ; cha├«ne non termin├®e par un z├®ro
DB @filename, 0 ; cha├«ne termin├®e par un z├®roVI-D. Utilisation des compteurs d'emplacement $ et $$▲
VI-D-1. Signification des compteurs d'emplacement▲
- $position au point d'utilisation en m├®moire dans l'ex├®cutable tel que charg├® par Windows┬Ā;
- $$position au d├®but de la section en cours dans la m├®moire dans l'ex├®cutable tel que charg├® par Windows.
Parce que ces deux op├®rateurs donnent des positions en m├®moire dans l'ex├®cutable tel que charg├® par Windows, leur valeur n'est pas connue pendant la phase d'assemblage par GoAsm, ni par le linker pendant la phase d'├®dition des liens. Ils agissent ├Ā cet ├®gard comme un label de code ou de donn├®es. Lorsque vous les utilisez, ils ne poss├©dent pas de valeur, mais ils peuvent ├¬tre soustraits les uns aux autres ou ├Ā des r├®f├®rences de m├®moire au sein de la m├¬me section pour produire une valeur. En effet, leurs valeurs relatives sont connues.
VI-D-2. Utilisation des compteurs d'emplacement▲
Le compteur d'emplacement $ est utile, par exemple, pour obtenir la taille d'une cha├«ne┬Ā:
HELLO DB 'He finally got the courage to talk to her', 0
LENGTHOF_HELLO DB $-HELLONotez que le compteur d'emplacement $ marque ├Ā la fois la position du label LENGTHOF_HELLO et la position de la fin de la cha├«ne HELLO, de sorte que la longueur de la cha├«ne sera obtenue par simple soustraction au compteur $ de l'emplacement du label HELLO.
Voici maintenant un exemple o├╣ l'on obtient la taille d'un tableau de DWords en utilisant une m├®thode de calcul l├®g├©rement diff├®rente aboutissant ├Ā ce que la taille soit contenue dans le premier DWord de la table elle-m├¬me┬Ā:
MESSAGES DD ENDOF_MESSAGES-$
DD MESS1, MESS2, MESS3, MESS4, MESS5
ENDOF_MESSAGES:qui est la m├¬me chose que┬Ā:
MESSAGES DD ENDOF_MESSAGES-MESSAGES
DD MESS1, MESS2, MESS3, MESS4, MESS5
ENDOF_MESSAGES:On voit ici que le premier DWord de la table de valeurs contient la valeur 24 puisque le premier mot est compt├® ├®galement. Avec un peu d'arithm├®tique, vous pouvez en d├®duire le nombre de valeurs contenues dans le tableau (ici, au nombre de cinq)┬Ā:
MESSAGES DD (ENDOF_MESSAGES-$-4)/4
DD MESS1, MESS2, MESS3, MESS4, MESS5
ENDOF_MESSAGES:Dans cette instruction┬Ā:
LABEL400:
JMP $+20h ; poursuit l'ex├®cution 20h octets plus loinLe compteur d'emplacement $ refl├©te la position de LABEL400 qui est la m├¬me que le d├®but de l'instruction JMP. Par cons├®quent, les cinq octets constitutifs du codage de l'instruction JMP elle-m├¬me (saut relatif utilisant l'opcode E9) doivent ├¬tre pris en compte dans le calcul.
Voici quelques autres exemples d'utilisation dans la section de code┬Ā:
CALL $$ ; call vers le d├®but de la section courante
MOV EAX, $-$$ ; EAX = distance de l'emplacement actuel par rapport
; au d├®but de la section couranteVoici quelques autres exemples d'utilisation de $ et $$ dans une section de donn├®es┬Ā:
HELLOZ DD $$ ; HELLOZ contient la position du d├®but de la section
DB 100-($-$$) DUP 0 ; bloc de z├®ros de la variable HELLOZ jusqu'├Ā l'offset 100Lorsqu'il est utilis├® dans une d├®finition, le compteur d'emplacement se r├®f├©re ├Ā l'emplacement o├╣ la d├®finition est utilis├®e plut├┤t qu'├Ā celui o├╣ elle est d├®clar├®e. Par exemple, dans ce qui suit, $$ se r├®f├©re au d├®but de la section de code dans la mesure o├╣ la d├®finition de globule est utilis├®e dans la section de code┬Ā:
#define globule $$+2+3
CODE SECTION
MOV EAX, globuleVI-E. Alignement et utilisation de ALIGN▲
VI-E-1. Qu'est-ce qu'un ┬½┬Āalignement┬Ā┬╗┬Ā?▲
Toutes les zones de la m├®moire ont certaines limites et des points d'alignement, m├¬me si l'on consid├©re les adresses virtuelles utilis├®es par Windows. Prenez les adresses virtuelles 400000h et 410000h o├╣, en g├®n├®ral, vous trouverez peut-├¬tre les sections de code et de donn├®es de votre programme charg├®es par Windows. Ces deux adresses peuvent ├¬tre consid├®r├®es comme pouvant partir ├Ā la fronti├©re d'un mot, d'un DWord, d'un paragraphe (16 octets) ou m├¬me ├Ā la fronti├©re d'entit├®s de 400h (qui valent 1K) ou de 10000h (qui correspondent ├Ā 64 Ko). En revanche, les adresses 400001h et 410001h ne peuvent s'aligner sur aucun des formats pr├®c├®dents. Les adresses 400002h et 410002h pourront ├¬tre cal├®es sur une limite de mot. Elles seront donc qualifi├®es de ┬½┬Āword aligned┬Ā┬╗. 400004h et 410004h correspondront ├Ā des limites Word et DWord┬Ā; 400010h et 410010h, ├Ā des limites Word, DWord et paragraphe. Ces derni├©res adresses sont donc correctement d├®crites comme ├®tant align├®es Word, DWord et paragraphe.
Une approche plus simple consiste ├Ā s'int├®resser ├Ā la divisibilit├® des adresses pour en d├®terminer l'alignement┬Ā:
| Adresse | Alignement | Caract├®ristiques adresse hexa |
| divisible par 2 | Word | le quartet de plus faible poids est pair |
| divisible par 4 | DWord | le quartet de plus faible poids est divisible par 4 |
| divisible par 16 | Para | le quartet de plus faible poids est nul |
En assembleur, vous pouvez imposer l'alignement des donn├®es et du code. Nous allons examiner d'abord l'alignement des donn├®es puis nous nous int├®resserons bri├©vement ├Ā l'alignement du code.
VI-E-2. N├®cessit├® d'un alignement des donn├®es▲
Il y a deux raisons qui militent en faveur d'un alignement de vos donn├®es┬Ā:
- la premi├©re consiste ├Ā satisfaire Windows┬Ā;
- la deuxi├©me est d'essayer d'obtenir un peu de vitesse suppl├®mentaire dans l'ex├®cution de vos programmes. Certaines instructions du processeur voient en effet leurs performances accrues par un judicieux alignement des donn├®es.
VI-E-2-a. Alignements impos├®s par Windows▲
Dans Windows 32 bits (NT/2000/XP et Vista fonctionnant comme Win32), de nombreux pointeurs de donn├®es ├Ā destination des API n├®cessitent un alignement DWord, et souvent, cette exigence n'est pas document├®e.
M├¬me sous Windows 9x, plusieurs pointeurs doivent ├¬tre align├®s DWord par exemple les structures DLGITEMTEMPLATES et DLGITEMTEMPLATESEX. De plus, le menu, la classe, le titre et les donn├®es de police d'un DLGTEMPLATE doivent ├¬tre align├®s Word et les structures utilis├®es dans les API de gestion de r├®seau doivent ├¬tre align├®es DWord.
Certains membres de structures bitmap doivent ├¬tre align├®s en interne. XP impose que la hauteur et la largeur des bitmaps compatibles soient toujours divisibles par quatre afin de garantir que chaque ligne soit correctement align├®e.
Certaines instructions SSE et SSE2 exigent un alignement de 16 octets de la zone de m├®moire ├Ā laquelle ils ont affaire. C'est le cas, par exemple, des instructions FXSAVE, FXRSTOR, MOVAPD, MOVAPS et MOVDQA.
Dans Windows 64 bits les exigences d'alignement sont encore plus strictes. Il est essentiel de veiller ├Ā ce que les membres de structure soient align├®s sur leur ┬½┬Āfronti├©re naturelle┬Ā┬╗. Ainsi, un mot doit-il ├¬tre sur une limite Word, une valeur DWord sur une limite DWord, une valeur QWord sur une limite QWord, etc. Cela ne fonctionne que si la structure elle-m├¬me est bien align├®e sur la limite correcte. Fondamentalement, la structure doit ├¬tre align├®e sur la limite naturelle de son membre le plus important. Il est ├®galement important que la m├¬me structure se termine sur la fin de la limite naturelle de son membre le plus important en ajoutant, le cas ├®ch├®ant, des octets de bourrage. Toujours dans Windows 64 bits, le pointeur de pile RSP doit aussi toujours ├¬tre align├® selon une modularit├® de 16 octets lors d'un appel d'API. Voir la section exigences en mati├©re d'alignement dans le chapitre consacr├® ├Ā la programmation 64 bits.
Quelle que soit la plateforme (32 bits ou 64 bits), les r├®sultats sont impr├®visibles si l'alignement est incorrect, allant de la simple non-apparition de contr├┤les, ├Ā la sortie pure et simple du programme.
VI-E-2-b. Alignements am├®liorant la vitesse d'ex├®cution▲
L'alignement qui permet d'obtenir une vitesse d'ex├®cution optimale varie d'un processeur ├Ā l'autre mais g├®n├®ralement, il est de bon usage que les donn├®es soient align├®es dans la m├®moire en fonction de la taille dans laquelle elles op├©rent. Par exemple un alignement DWord est plausible pour une table de DWords. En th├®orie, les QWords et TWords doit ├¬tre align├®s QWord pour une performance optimale.
VI-E-3. R├®alisation d'un alignement de donn├®es correct▲
En Win32, GoAsm aligne automatiquement les structures sur une limite DWord, ├Ā la fois quand elles sont d├®clar├®es comme donn├®es locales et dans la section de donn├®es. Ainsi, vous pouvez ├¬tre certain que toutes vos structures fonctionneront. Cependant, vous pouvez ajouter un alignement suppl├®mentaire ├Ā ces structures qui sont d├®clar├®es dans la section de donn├®es en utilisant l'op├®rateur ALIGN. Vous pouvez ├®galement choisir d'utiliser ALIGN sur les donn├®es ordinaires (hors structures) pour obtenir la meilleure performance possible.
Un bon alignement peut g├®n├®ralement ├¬tre r├®alis├® automatiquement en d├®clarant les donn├®es par s├®quence de taille dans la section de donn├®es. Vous pourriez ainsi d├®clarer tous les QWords d'abord, puis les DWords, les mots, les octets et, enfin, les cha├«nes. Les TWords contenant 10 octets peuvent bouleverser cet ordonnancement. Il est donc souhaitable de les d├®clarer en premier puis de corriger l'alignement en utilisant ALIGN.
En Win64, GoAsm aligne automatiquement les structures et leurs membres en fonction de la limite naturelle de ces structures et de leurs membres. GoAsm bourre aussi la taille de la structure en fonction des besoins. Enfin, GoAsm aligne automatiquement le pointeur de pile en pr├®alable ├Ā un appel d'API.
Voir le chapitre programmation en 64 bits pour plus d'information et voir comment cela fonctionne en pratique.
VI-E-4. Alignement du code ▲
Le bon alignement du code rel├©ve plus de l'impond├®rable et d├®pend v├®ritablement du processeur ex├®cutant le code. Rick Booth aborde le sujet dans son livre ┬½┬ĀInner Loops┬Ā┬╗ (┬½┬Āboucles internes┬Ā┬╗) publi├® par Addison Wesley.
J'ai inclus quelques tests de vitesse dans TestBug, qui montrent la diff├®rence qui peut r├®sulter d'un bon alignement lors des op├®rations de lecture, d'├®criture ou de comparaison du contenu de la m├®moire ├Ā une valeur.
VI-E-5. Utilisation de ALIGN▲
GoAsm reconna├«t l'op├®rateur ALIGN value, o├╣ value est la taille de l'alignement requis en octets. D├©s lors, GoAsm alignera les donn├®es ou le code qui suivent ├Ā la limite correcte pour assurer l'alignement. Par exemple┬Ā:
ALIGN 4 ; la donn├®e suivante sera align├®e sur un dword
ALIGN 16 ; (ou ALIGN 10h) aligne ce qui suit sur un paragraphe de 16 octetsAfin de r├®aliser l'alignement dans une section de code, GoAsm effectue un ┬½┬Ābourrage┬Ā┬╗ d'octets au moyen d'une succession d'instructions NOP (opcode 90h) qui ont la particularit├® de n'ex├®cuter aucune op├®ration. Pour une section de donn├®es ou const, GoAsm se livre ├®galement ├Ā un ┬½┬Ābourrage┬Ā┬╗ mais utilisant ici des z├®ros dispos├®s ├Ā la bonne place.
Voir aussi sections - Gestion avanc├®e s'agissant de l'alignement de la section.
VI-F. Utilisation de SIZEOF▲
L'op├®rateur SIZEOF peut ├¬tre utilis├® comme ADDR ou OFFSET, mais au lieu de donner l'adresse d'un label de code ou de donn├®es, il donne sa taille en octets. Comme GoAsm est un assembleur travaillant en une seule passe, SIZEOF ne renvoie la valeur appropri├®e que pour un label qui commence et se termine avant cet op├®rateur dans le script source. SIZEOF peut ├¬tre utilis├® soit pour des donn├®es ordinaires et du code, soit pour des donn├®es locales.
VI-F-1. Utilisation de SIZEOF sur les labels de donn├®e▲
Voici quelques exemples illustrant la mani├©re dont SIZEOF peut ├¬tre utilis├® (o├╣ Hello est un label de donn├®e)┬Ā:
MOV EAX, SIZEOF Hello
MOV EAX, SIZEOF(Hello)
MOV EAX, [ESI+SIZEOF Hello]
SUB ESP, SIZEOF Hello
DD SIZEOF Hello
Label DB SIZEOF Hello DUP 0
MOV EAX, SIZEOF Hello+4
MOV EAX, SIZEOF Hello-4
MOV EAX, SIZEOF Hello/2
MOV EAX, SIZEOF Hello*2Lorsqu'il agit sur un label de donn├®e dans un ensemble de donn├®es brutes, l'op├®rateur SIZEOF calcule la distance entre le label mentionn├® et le label suivant ou la fin de la section si celle-ci s'av├©re plus proche, comme le montre l'exemple suivant┬Ā:
Hello DB 0
DD 0
Hello2 DB 0alors,
MOV EAX, SIZEOF Hellocharge dans EAX la valeur 5.
VI-F-2. Utilisation de SIZEOF avec des cha├«nes▲
Vous pouvez utiliser SIZEOF avec des cha├«nes (en remplacement du LENGTHOF de MASM). Par exemple┬Ā:
WrongB DB 'You pressed the wrong button!, '0alors,
MOV EAX, SIZEOF WrongBrenvoie la longueur de la chaîne, terminateur null compris.
VI-F-3. Utilisation de SIZEOF sur les labels de code▲
Dans cet exemple┬Ā:
START:
XOR EAX, EAX
XOR EAX, EAX
XOR EAX, EAX
XOR EAX, EAX
LABEL:
MOV EAX, SIZEOF STARTLa valeur 8 sera charg├®e dans EAX. C'est la taille des quatre instructions XOR EAX, EAX.
VI-F-4. Utilisation de SIZEOF avec les structures▲
Vous pouvez utiliser SIZEOF avec des structures pour en retourner la taille. Par exemple, si vous avez
Rect STRUCT
left DD
top DD
right DD
bottom DD
ENDS
rc Rectalors, les instructions
MOV EAX, SIZEOF Rectet
MOV EAX, SIZEOF rcchargent toutes les deux la valeur 16 dans EAX.
VI-F-4-a. Utilisation de SIZEOF avec des membres de structures▲
Vous pouvez utiliser SIZEOF pour retourner la taille de membres d'une structure qui est calcul├®e dans ce cas par rapport au label suivant. Par exemple, si vous avez
Rect STRUCT
left DD
DD
right DD
bottom DD
ENDS
rc Rectalors, les instructions
MOV EAX, SIZEOF rc.leftet
MOV EAX, SIZEOF Rect.leftretournent toutes les deux la valeur 8.
VI-F-5. Utilisation de SIZEOF avec des unions et des membres d'union ▲
Vous pouvez utiliser SIZEOF pour retourner la taille d'une union ou de l'un de ses membres, mais gardez ├Ā l'esprit que chaque membre retournera la m├¬me taille (c'est-├Ā-dire la plus grande taille de membre). Ainsi┬Ā:
Sleep STRUCT
DW 2222h
DB 0h
ENDS
Ness UNION
Possums DB L'Balance'
Koalas Sleep
Devils DB 'Roar'
ENDS
Happy Ness
SizeLabel DD SIZEOF Happy
DD SIZEOF Ness
DD SIZEOF Happy.Possums
DD SIZEOF Happy.Koalas
DD SIZEOF Happy.DevilsChaque DWord dans SizeLabel contient 14, qui est la taille du plus grand membre de l'union, ├Ā savoir Happy.Possums, qui contient une cha├«ne Unicode de 14 octets de long.
VI-F-6. Influence de l'initialisation d'une structure sur sa taille▲
Lors du processus d'obtention de la taille, les arguments qui pourraient ├¬tre utilis├®s pour modifier la taille de la structure sont ignor├®s. Consid├®rons, par exemple, la structure suivante┬Ā:
StringStruct STRUCT
DB ?
ENDSDans cette situation, l'instruction
MOV EAX, SIZEOF StringStructretourne une taille de 1 octet dans EAX, m├¬me si la structure avait pr├®alablement ├®t├® mise en ┼ōuvre ├Ā l'aide de┬Ā:
LongString StringStruct <'Je hais les structures'>qui agrandit la structure de 22 octets dans cette mise en ┼ōuvre. De m├¬me, si la longueur de la cha├«ne repose sur la r├®solution d'une d├®finition, par exemple┬Ā:
StringStruct STRUCT
DB LONGSTRING
ENDSalors
MOV EAX, SIZEOF StringStructretournerait ├®galement une taille de 1 octet dans EAX, quelle que soit la valeur de LONGSTRING.
Les tailles de structure susceptibles de varier avec les d├®finitions sont, par exemple, de la forme┬Ā:
Rect STRUCT
DB TWELVE DUP 0
ENDSEt, dans ce cas, la taille de la structure sera effectivement modifiable.
VI-F-7. Initialisation d'une structure avec SIZEOF▲
Vous pouvez initialiser une structure avec sa propre taille ou la taille d'autre chose, par exemple┬Ā:
PARAM_STRUCT STRUCT
DD 0
DD 0
DD 0
ENDS
ps1 PARAM_STRUCT <SIZEOF PARAM_STRUCT,,>VI-F-8. Utilisation de SIZEOF avec des donn├®es locales▲
La taille des donn├®es locales est retourn├®e, par exemple┬Ā:
MyWndProc FRAME
LOCALS hDC, DemonFlag:B, Buffer[256]:B, MyRect:RECT
MOV EAX, SIZEOF hDC ; 4 en 32 bits, 8 en 64 bits (taille par d├®faut)
MOV EAX, SIZEOF DemonFlag ; 1
MOV EAX, SIZEOF Buffer ; 256
MOV EAX, SIZEOF MyRect ; 16
RET
ENDFLa taille retourn├®e ignore tout comblement op├®r├® par GoAsm pour aligner les donn├®es locales correctement sur la pile (toutes les donn├®es locales sont align├®es DWord en assemblage 32 bits et align├®es QWord en assemblage 64 bits).
Voir aussi la section utilisation de l'instruction LOCALS.
VI-G. Utilisation des branchements pr├®dictifs▲
VI-G-1. Qu'est-ce qu'une pr├®diction de branchement┬Ā?▲
Les processeurs modernes (par exemple les Pentium du haut de gamme) sont capables d'am├®liorer sensiblement leur vitesse d'ex├®cution en pr├®disant la prochaine instruction qui sera ex├®cut├®e apr├©s une instruction de saut conditionnel. Par exemple┬Ā:
CMP EDX, EAX ; compare EDX et EAX
JZ >L1 ; saut au label L1 si EDX = EAX
; autres instructions
L1:Le processeur ne peut ├¬tre certain ├Ā 100┬Ā%, ├Ā l'avance, que EDX sera ├®gal ├Ā EAX au moment o├╣ l'instruction de comparaison est ex├®cut├®e. Il pourrait pr├®dire que cela est peu probable, auquel cas, il d├®ciderait que les instructions situ├®es imm├®diatement apr├©s le saut conditionnel doivent ├¬tre ex├®cut├®es ├Ā la suite. Si cette pr├®diction s'av├©re exacte, ces instructions seront donc ex├®cut├®es imm├®diatement et sans aucune perte de temps. Dans le cas contraire, il y aurait une certaine perte de temps ├Ā passer ├Ā l'instruction correcte (juste apr├©s L1) en lieu et place. Diff├®rents algorithmes de pr├®diction de branchement sont utilis├®s par le processeur, y compris certains qui sont capables de tirer parti de leurs erreurs. Une des pr├®dictions de base utilis├®es comme point de d├®part postule que┬Ā:
- tous les sauts conditionnels avant ne pourront avoir lieu┬Ā;
- tous les sauts conditionnels arri├©re (boucles arri├©re) auront lieu.
Il est ├®tabli que, dans un code normal, les sauts conditionnels arri├©re seront effectifs avec une probabilit├® de 80┬Ā%, alors que les sauts conditionnels avant seront plus rares. Il est dit que, globalement, la pr├®diction par d├®faut est correcte dans 65┬Ā% du temps. Donc pr├®dire si oui ou non le saut conditionnel aura lieu peut acc├®l├®rer le code, en particulier sur une s├®rie de boucles de retour. En tant que programmeur en assembleur, vous pouvez produire du code rapide en tenant compte des m├®canismes de pr├®diction par d├®faut du processeur que vous programmez d'autant plus finement que vous ├¬tes en mesure de contr├┤ler compl├©tement votre code.
VI-G-2. Les pr├®dicteurs de branchement 2Eh et 3Eh▲
Dans le P4 (et peut-├¬tre dans certains processeurs ant├®rieurs), vous pouvez donner au processeur un ┬½┬Āconseil┬Ā┬╗ quant ├Ā savoir si oui ou non la branche est susceptible de se produire.
On utilise ├Ā cet effet les octets de pr├®diction de branchement 2EH et 3Eh qui sont ins├®r├®s imm├®diatement avant l'instruction de saut conditionnel. Respectivement, ils signifient ce qui suit┬Ā:
- 2Eh pr├®dit que le branchement ne s'ex├®cutera pas la plupart du temps┬Ā;
- 3Eh pr├®dit que le branchement s'ex├®cutera la plupart du temps.
L'utilisation du pr├®dicteur de branchement 2Eh serait utile (par exemple), si vous aviez un branchement arri├©re correspondant ├Ā un saut conditionnel qui ne se produit que dans le cas d'une erreur pr├®sum├®e rare. Nous avons vu que le processeur, dans son mode de fonctionnement de base, pr├®voit normalement que le branchement arri├©re est consid├®r├® comme ├®tant susceptible de se produire, ce qui ralentit le code puisque nous attendons pr├®cis├®ment le contraire. C'est l├Ā que l'insertion du pr├®dicteur 2Eh intervient pour neutraliser, ├Ā point nomm├®, cet automatisme.
Le pr├®dicteur de branchement 3Eh serait utile (exceptionnellement) si vous souhaitez cr├®er une boucle o├╣ le saut conditionnel serait au d├®but d'un fragment de code et la destination du saut plus avant dans le code. Cette boucle devrait normalement fonctionner plus lentement qu'une boucle de type normal en raison de la pr├®vision par d├®faut, par le processeur, que le branchement avant est peu probable, ├Ā moins que le processeur ne soit capable de tirer parti de ses erreurs de pr├®vision initiales.
VI-G-3. Insertion de pr├®dicteurs de branchement▲
Intel ne propose aucun mn├®monique pour ins├®rer les octets de pr├®diction de branchement. Vous pouvez proc├®der comme suit┬Ā:
DB 2Eh ; ou
DB 3EhSi vous pr├®f├®rez, vous pouvez ins├®rer les octets pr├®diction de branchement automatiquement. ├Ć cet effet, GoAsm utilise la syntaxe qui suit pour ins├®rer l'octet de pr├®diction de branchement appropri├® pour le processeur P4┬Ā:
hint.nobranch ; ins├©re 2Eh
hint.branch ; ins├©re 3EhPour en revenir au premier exemple, si EDX est normalement ├®gal ├Ā EAX, alors ce code sera plus rapide sur le P4 en ajoutant la pr├®diction de branchement suivante┬Ā:
CMP EDX, EAX ; compare EDX et EAX
hint.branch JZ >L1 ; effectue normalement le branchement ├Ā L1
; autres instructions
L1:J'ai inclus un test de vitesse dans TestBug qui d├®montre l'am├®lioration de la vitesse obtenue en utilisant ce m├®canisme de pr├®diction de branchement. Il appara├«t par exemple que le code s'ex├®cute environ 1,5 fois plus rapidement sur un processeur par la mise en ┼ōuvre de ce proc├®d├®.
VI-H. Syntaxe des registres FPU, MMX et XMM▲
| Registres | Syntaxe GoAsm |
| FPU x87 (virgule flottante) | ST0, ST1, ST2, ST3, ST4, ST5, ST6 et ST7 |
| Registres MMX et 3DNow! | MM0, MM1, MM2, MM3, MM4, MM5, MM6 et MM7 |
| Registres XMM | XMM0, XMM1, XMM2, XMM3, XMM4, XMM5, XMM6 et XMM7 |
| Les huit nouveaux registres XMM des processeurs 64 bits |
XMM8, XMM9, XMM10, XMM11, XMM12, XMM13, XMM14 et XMM15 |
Lire ├®criture des programmes 64 bits pour conna├«tre les autres nouveaux registres et leurs m├®thodes d'adressage.
VI-H-1. L'opcode ┬½┬ĀWait┬Ā┬╗ (9Bh)▲
Puisque GoAsm ne fonctionne que sur les processeurs modernes int├®grant l'unit├® de calcul en virgule flottante, il ├®met l'opcode ┬½┬ĀWait┬Ā┬╗ seulement pour les instructions suivantes┬Ā:
|
FCLEX FINIT FWAIT FSAVE |
FSETPM FSTCW FSTENV FSTSW |
VI-I. Information sur la dur├®e d'assemblage (GOASM_REPORTTIME)▲
GoAsm peut vous indiquer le temps qu'il a fallu pour assembler les diff├®rentes parties de votre script source si vous portez le mot GOASM_REPORTTIME une ou plusieurs fois dans le texte. Le temps restitu├® par GOASM_REPORTTIME est┬Ā:
- celui ├®coul├® depuis la sp├®cification GOASM_REPORTTIME pr├®c├®dente (ou le d├®but de l'assemblage)┬Ā;
- celui qui est n├®cessaire pour atteindre la prochaine sp├®cification GOASM_REPORTTIME (ou la fin de l'assemblage).
Ces dur├®es excluent les phases de mise en place et de nettoyage.
GOASM_REPORTTIME est utile si vous voulez examiner diff├®rentes configurations du script source et en d├®duire celles qui permettront d'acc├®l├®rer l'assemblage, ou pour identifier une ├®ventuelle partie du script qui ralentirait ├Ā elle seule l'assemblage.
VI-J. Autres interruptions GoAsm▲
Vous pouvez envoyer un message ├Ā la console ├Ā l'occurrence d'un ├®v├®nement lors de l'assemblage (qui peut ├®ventuellement ├¬tre activ├® par assemblage conditionnel) en utilisant, par exemple┬Ā:
GOASM_ECHO L'Assembleur a atteint de nouveaux sommetsLe mat├®riau ├Ā ├®crire dans la console n'a pas ├Ā ├¬tre entre guillemets, bien qu'il puisse l'├¬tre ├®galement.
Enfin, vous pouvez forcer GoAsm ├Ā arr├¬ter l'assemblage et ├Ā en sortir par┬Ā:
GOASM_EXITVI-K. Fichier-listing d'assemblage GoAsm▲
GoAsm produit un fichier-listing si on lui demande de le faire avec le commutateur /l dans la ligne de commande. Le fichier utilise les m├¬mes nom et r├®pertoire que le fichier objet de sortie, mais il est pourvu de l'extension .lst. Il est dans le m├¬me format que celui de votre fichier source (un fichier source Unicode se traduira par un fichier-listing Unicode). Le volume 2 d├®crit, de mani├©re plus pr├®cise, la programmation en Unicode.
Le listing montre, d'une part les opcodes qui ont ├®t├® g├®n├®r├®s ├Ā la suite de chaque instruction sur le c├┤t├® gauche de la page, d'autre part l'instruction et les commentaires sur le c├┤t├® droit de la page. Si une ligne est trop longue pour ├¬tre repr├®sent├®e, elle est purement et simplement tronqu├®e. Dans le cas des opcodes un symbole en forme d'ellipse avertit qu'une troncature est intervenue. Les r├®f├®rences de m├®moire qui requi├©rent une relocalisation (c'est-├Ā-dire une valeur sera ins├®r├®e soit par GoAsm, soit par le linker) sont sp├®cifi├®es entre crochets. Cependant, la relocation ins├®r├®e ne sera pas affich├®e.
Les d├®finitions sont pr├®sent├®es telles que d├®finies ou ├®tendues.
Les fichiers d'inclusion pourvus d'un ┬½┬Āa┬Ā┬╗ ou ┬½┬ĀA┬Ā┬╗ dans l'extension sont trait├®s en tant que partie du script source et leur contenu sera inclus dans le listing. Le contenu des fichiers inclus pourvus d'autres extensions ne seront pas inclus dans le listing.
Faites-moi savoir s'il y a quelque chose d'autre que vous aimeriez que le fichier-listing affiche ou si vous souhaitez en modifier le format.
VI-L. Messages d'erreur et d'avertissement de GoAsm▲
GoAsm donne toute l'information relative aux erreurs et alertes sur la ligne de commande. Si GoAsm constate une erreur dans le script source, il cessera l'assemblage et interrompra le traitement avec le code de retour TRUE (EAX = 1). GoAsm affiche alors dans la fen├¬tre MS-DOS (invite de commande) la ligne et l'origine (le script source) de l'erreur survenue, une description de l'erreur, et peut ├®galement visualiser le mot ou la ligne de texte incrimin├®s. Si le mot ou la ligne sont d├®finis, il peut montrer l'origine de la d├®finition. Certaines erreurs dans les fichiers inclus ┬½┬Ānon a┬Ā┬╗ (ceux qui ne sont pas consid├®r├®s comme faisant partie du script source) sont tout simplement ignor├®es, d'autres sont pr├®sent├®es comme des alertes, en fonction de la nature de l'erreur.
Si vous utilisez le commutateur /b, vous entendrez ├®galement un bip sur une erreur.
Je n'ai pas opt├® pour la facult├® offerte ├Ā l'assembleur de continuer en d├®pit d'une erreur, consid├®rant que celle-ci se traduit souvent par d'autres erreurs induisant un ph├®nom├©ne cumulatif, le tout tendant ├Ā obscurcir en d├®finitive la cause originelle. J'ai trouv├® que cette r├®ponse ├Ā une simple erreur est tout ├Ā fait ad├®quate ├Ā la lumi├©re de la syntaxe simplifi├®e de GoAsm dont on esp├©re r├®duire les erreurs dans votre script source de toute fa├¦on. En plus de cela, si vous ├®crivez votre code de mani├©re incr├®mentale, j'ai bon espoir que les erreurs seront peu nombreuses.
Je me suis ├®galement prononc├® contre l'id├®e consistant ├Ā recenser les erreurs dans un fichier s├®par├®, car il serait l├®gitimement fastidieux d'avoir ├Ā ouvrir un autre fichier afin d'y lire les erreurs plut├┤t que de lire directement cette information sur la ligne de commande. Du reste, vous pouvez parfaitement rediriger toutes les sorties GoAsm dans un fichier que vous pourrez lire plus tard en utilisant la commande DOS de redirection, par exemple┬Ā:
GoAsm Test.asm >output.filUne autre fa├¦on de contr├┤ler la sortie d'erreurs et d'avertissements GoAsm est d'utiliser les commutateurs suivants sur la ligne de commande┬Ā:
|
bip sur erreur. |
|
pas de messages d'erreur. |
|
pas de messages l'information. |
|
pas de messages d'avertissement. |
|
aucun message de sortie du tout. |
Un simple avertissement sera d├®livr├® si un mot a ├®t├® d├®fini plus d'une fois dans la ligne de commande ou dans le script source, mais l'assemblage sera autoris├® ├Ā continuer pour autant. En effet, il serait inhabituel de d├®finir un mot plus d'une fois et il se peut ├®galement que ce soit une erreur de programmation. Il est parfaitement possible d'annuler une d├®finition pr├®c├®dente en utilisant #undef pour que le mot puisse ├¬tre d├®fini. Dans ce cas, aucun avertissement n'est donn├®.
Vous obtiendrez ├®galement un avertissement si┬Ā:
- vous essayez d'inclure le m├¬me fichier deux fois ├Ā moins que ce ne soit le type de fichier d'inclusion qui contienne lui-m├¬me script source, dans ce cas, il y aura une erreur ├Ā la place┬Ā;
- vous essayez de d├®clarer plus de 1 Mo de donn├®es en double┬Ā;
- (dans certains cas) si vous utilisez un indicateur de type alors que ce n'est pas n├®cessaire.
Dans un fichier batch, vous pouvez capter le retour d'erreur avec ERRORLEVEL et en d├®duire une action. Par exemple, dans ce qui suit, le processus est interrompu s'il y a un retour d'erreur┬Ā:
GoAsm MyFile.asm
IF ERRORLEVEL 1 PAUSEVI-M. Utilisation de GoAsm avec diff├®rents linkers▲
VI-M-1. Utilisation de GoLink▲
GoLink est un ├®diteur de liens libre ├®crit par moi et disponible ├Ā partir de mon site web www.GoDevTool.com. Il accepte les fichiers objet au format PE produits par GoAsm (ou d'autres assembleurs et compilateurs) et les fichiers RES ou OBJ issus de GoRC pour produire un fichier ex├®cutable.
GoLink pr├®sente certains avantages par rapport aux autres linkers. En particulier il est con├¦u pour collaborer ├®troitement avec GoAsm sur les importations et les exportations, et peut rendre compte des donn├®es et labels de code redondants lors de l'├®dition de liens des fichiers produits par GoAsm. Mais ses principaux avantages sont qu'il fonctionne rapidement en r├®duisant les ┬½┬Ābagages┬Ā┬╗. Les fichiers sont r├®duits au minimum. Les fichiers LIB ont ├®t├® supprim├®s. Au lieu de cela, GoLink regarde les ex├®cutables actuellement stock├®s sur l'ordinateur au moment de l'├®dition de liens pour obtenir ses informations sur les importations requises par l'ex├®cutable qu'il constitue. Comme la plupart d'entre eux sont dans la m├®moire de toute fa├¦on s'il s'agit de DLL syst├©me, cela peut ├¬tre fait rapidement.
Voir le chapitre consacr├® ├Ā GoLink pour une information compl├©te sur cet ├®diteur et la mani├©re de l'utiliser (Volume 2). Notez que l'action de GoAsm puis celles de GoLink peuvent utilement ├¬tre automatis├®es ├Ā l'aide d'un fichier batch (avec l'extension .bat) visant ├Ā cr├®er un ex├®cutable. En voici un exemple simple┬Ā:
GoAsm MyProg.asm
GoLink MyProg.obj Kernel32.dll User32.dllLe lancement de ce fichier batch va aboutir ├Ā la cr├®ation du fichier Windows PE myprog.exe avec les importations en provenance des DLL mentionn├®es. L'adresse d'entr├®e START est implicite mais cela peut ├¬tre sp├®cifi├®.
Vous pouvez utiliser un fichier de commandes avec GoLink par exemple┬Ā:
GoLink @command.filAu lieu (ou en plus) de sp├®cifier les DLL dans la ligne de commande de GoLink ou les fichiers, vous pouvez utiliser #DYNAMICLINKFILE dans le code source GoAsm. La syntaxe est┬Ā:
#dynamiclinkfile path/filename, path/filenameLa virgule est facultative. L'ensemble r├®pertoire/nom de fichier peut ├¬tre entre guillemets. Un ou plusieurs ensembles r├®pertoire/nom de fichier peuvent ├¬tre sp├®cifi├®s. Vous n'├¬tes pas oblig├® de fournir le chemin d'acc├©s lors de la sp├®cification de fichiers syst├©me car GoLink consulte automatiquement le contenu des r├®pertoires syst├©me. Le nom du fichier doit ├¬tre stipul├® avec son extension qui peut ├¬tre .dll, .ocx, .exe ou .drv.
Le nom de fichier est envoy├® ├Ā GoLink dans la section .drectve du fichier objet cr├®├® par GoAsm. Il est utilis├® pour donner des informations et des directives ├Ā l'├®diteur de liens, mais n'a aucune incidence sur l'ex├®cutable final.
Vous devez utiliser GoLink ├Ā partir de la version 26.5 pour que cela fonctionne.
Il y a plusieurs autres commutateurs et options dans la ligne de commande lors de l'utilisation GoLink. Pour plus de d├®tails consulter le fichier d'aide Golink, GoLink.htm.
VI-M-2. Utilisation de ALINK▲
ALINK est un ├®diteur de liens libre de Anthony Williams. La sortie de ALINK est plut├┤t fournie, ce qui fait qu'il s'av├©re pr├®f├®rable de la rediriger vers un fichier que vous pourrez regarder plus tard. Je vous sugg├©re de constituer ├Ā cet effet un fichier batch avec une extension .bat contenant les lignes suivantes┬Ā:
GoAsm MyProg.asm
ALINK @Respons.fil >link.optVous ex├®cutez ce fichier batch en saisissant son nom sur la ligne de commande dans une fen├¬tre MS-DOS (invite de commande) et en appuyant sur Entr├®e.
Respons.fil est un fichier avec les instructions ├Ā l'├®diteur de liens qui pourraient ├¬tre les suivantes (├Ā titre d'exemple)┬Ā:
-m ; produit un fichier map
-oPE ; produit un fichier au format PE
-o MyProg.Exe ; impose le nom du fichier de sortie
-entry START ; pr├®cise le point d'entr├®e
-debug ; signifie que des symboles debug doivent ├¬tre constitu├®s
kernel32.lib ;
COMCTL32.lib ; un fichier lib pour chaque API
COMDLG32.lib ; qui est appel├® dans votre programme.
user32.lib ; fait usage de ALIB qui est
gdi32.lib ; un composant du package ALINK.
shell32.lib ;
MyProg.obj ; le fichier d'entr├®eVous pouvez organiser votre travail en laissant les diff├®rents fichiers n├®cessaires entrepos├®s dans des dossiers diff├®rents. Dans ce cas, vous devez inclure les chemins d'acc├©s correspondants dans les instructions donn├®es ├Ā GoAsm et ├Ā ALINK.
VI-M-3. Utilisation de l'├®diteur de liens Microsoft▲
L'├®diteur de liens Microsoft est disponible gratuitement dans le SDK Microsoft ou en t├®l├®chargeant le package MASM. Voir www.godevtool.com/ pour plus d'informations ou essayez diff├®rents liens vers d'autres sites. L'├®diteur de liens Microsoft est plus difficile ├Ā utiliser car il pr├®voit que le label d'adresse de d├®marrage de programme et les appels externes soient ┬½┬Āenrichis┬Ā┬╗ de la mani├©re dont ils sont ├®mis par les compilateurs C et par MASM. L'enrichissement attendu pr├®voit, en l'occurrence, un caract├©re de soulignement pr├®c├®dant le label et (dans le cas d'un appel de fonction) le symbole @ suivi du nombre d'octets pouss├®s sur la pile lorsque la fonction est appel├®e. Normalement GoAsm n'utilise pas d'enrichissement parce que mon objectif a ├®t├® de tout simplifier autant que possible.
VI-M-3-a. Enrichissement automatique avec le commutateur /ms▲
Vous pouvez demander ├Ā GoAsm de fournir automatiquement l'enrichissement n├®cessaire en utilisant le commutateur /ms dans la ligne de commande (en 32 bits seulement mais cette fonction est inactiv├®e avec l'utilisation du commutateur /x64). Cette configuration invitera GoAsm ├Ā enrichir tous les labels de code, des CALL et INVOKE.
Dans chacun de ces cas, l'enrichissement est sous cette forme┬Ā:
_CodeLabel@xo├╣ le label est d├®clar├® comme CodeLabel et o├╣ x est le nombre d'octets utilis├®s par les param├©tres de CodeLabel. Enrichi de cette mani├©re, CodeLabel est disponible pour d'autres fichiers objet devant ├¬tre li├®s par le MS linker (et peuvent donc ├¬tre appel├®es ├Ā partir de ces autres fichiers objet). Et si CodeLabel r├®side dans une DLL, le MS Linker va le reconna├«tre en tant que tel ├Ā partir d'un fichier .lib fabriqu├® ├Ā partir de la DLL et qui lui est donn├® au moment de la phase d'├®dition de liens.
Au moment de l'├®dition des liens, le MS linker attend que la valeur de ┬½┬Ā@x┬Ā┬╗ corresponde exactement entre l'appelant et l'appel├®. Ceci est donc une forme limit├®e de contr├┤le de param├©tre. Lorsque le commutateur /ms est utilis├®, GoAsm doit donc compter le nombre de param├©tres utilis├®s par le label de code afin d'obtenir la valeur de ┬½┬Ā@x┬Ā┬╗ correcte. Pour ce faire, dans le cas des labels de FRAMEs, GoAsm compte le nombre de param├©tres d├®clar├®s dans la trame et ajuste l'enrichissement en cons├®quence. Dans le cas d'un appel utilisant INVOKE, GoAsm compte ├Ā nouveau le nombre de param├©tres utilis├®s.
Cependant, GoAsm ne peut pas compter le nombre de param├©tres pour un appel utilisant CALL et suppose qu'il n'y en a pas. Pour cette raison, s'il y a des param├©tres, vous devez imp├®rativement utiliser INVOKE pour que l'enrichissement puisse fonctionner correctement (et non pas un PUSH xxx ordinaire suivi d'un CALL). Notez ├®galement que si vous utilisez ARG avant INVOKE, chaque argument doit poss├®der sa propre ligne (ce qui ├®limine toute repr├®sentation telle que ARG 1,2,3).
Ainsi, si vous utilisez le code suivant avec le commutateur /ms sur la ligne de commande de GoAsm┬Ā:
HelloProc FRAME hwnd, arg1, arg2
INVOKE MessageBoxA, [hwnd], 'Click OK', 'Hello', 40halors, GoAsm va ins├®rer le symbole HelloProc dans le fichier objet sous la forme
_HelloProc@12et mettre la fonction appel├®e dans le fichier objet sous la forme
_MessageBoxA@16En effet, GoAsm sait que 12 octets sont sur la pile dans le cas de HelloProc et que 16 octets sont pouss├®s sur la pile avant que MessageBoxA ne soit appel├®e.
├Ć partir de la version 0.49 de GoAsm, les labels de codes ordinaires sans param├©tres sont ├®galement enrichis. Ceci doit permettre que de tels labels de code puissent ├¬tre reconnus ├Ā l'ext├®rieur au moment de l'├®dition des liens de sorte qu'ils puissent ├¬tre appel├®s par d'autres fichiers objet cr├®├®s par des outils MS. On leur donne un nombre d'octets de param├©tre nul. Cela comprend l'├®tiquette donnant elle-m├¬me l'adresse de d├®part. Donc, supposons que votre adresse de d├®part dans votre script source soit START: (non pr├®c├®d├®e par un caract├©re de soulignement). Elle se trouve maintenant enrichie sous la forme┬Ā:
_START@0et, pour proc├®der ├Ā une ├®dition de liens correcte avec MS Linker, vous devrez inclure ce qui suit dans sa ligne de commande ou le fichier┬Ā:
-ENTRY START@0VI-M-3-b. Enrichissement manuel▲
Vous pouvez ├®galement utiliser le MS linker en effectuant les modifications manuelles suivantes sur votre script source┬Ā:
- Assurez-vous que le label donnant l'adresse de d├®marrage du programme commence bien par un caract├©re de soulignement. Mais omettez ce caract├©re de soulignement lorsque vous le d├®clarez au MS Linker.
- Si vous avez plus d'un fichier objet ├Ā envoyer au MS Linker, et qu'il y a des fonctions dans un fichier objet appel├®es ├Ā partir d'un autre fichier objet, enrichir les labels correspondant ├Ā ces fonctions. Les labels de code ordinaires sans param├©tres auront besoin d'un caract├©re de soulignement avant et de @0 ├Ā la fin du nom. Les labels de code avec des param├©tres ont besoin d'un caract├©re de soulignement en t├¬te et de @x apr├©s le nom o├╣ x est le nombre d'octets de param├©tres (chaque param├©tre comprenant quatre octets).
- Enrichissez tous les appels de l'API avec un caract├©re de soulignement en t├¬te et @x apr├©s le nom, x ├®tant le nombre d'octets pouss├®s sur la pile lorsque l'API est appel├®e (chaque PUSH occupant quatre octets).
Par exemple┬Ā:
PUSH 12h
CALL _GetKeyState@4 ; test si la touche Alt est press├®eL'API GetKeyState ne requiert qu'un seul param├©tre, ce qui fait que quatre octets sont mis sur la pile.
Si vous faites une DLL, vous aurez besoin d'utiliser un label pour l'adresse de d├®part enrichie de la m├¬me mani├©re, par exemple┬Ā:
_DLLENTRY@12:Ceci indique que le label DLLENTRY est appel├® avec 12 octets pouss├®s sur la pile, soit trois DWords.
Apr├©s avoir effectu├® ces changements dans votre script source, vous ├¬tes pr├¬t ├Ā constituer un fichier batch avec l'extension .bat pour l'assembler, puis traiter le fichier r├®sultant dans l'├®diteur de liens. En voici une r├®daction possible┬Ā:
GoAsm MyProg.asm
LINK @Respons.filVous lancez le fichier batch en saisissant son nom en regard de l'invite de commande MS-DOS puis en validant sur Entr├®e. Le fichier Respons.fil pourrait contenir les lignes suivantes┬Ā:
/OUT:MyProg.Exe ; donne le nom du fichier de sortie
/MAP ; produit un fichier map
/SUBSYSTEM:WINDOWS ; ├®labore un ex├®cutable Windows GDI
/ENTRY:START ; correspond au _START du script source!
/DEBUG:FULL ; faire une sortie debug
/DEBUGTYPE:COFF ; faire des symboles COFF embarqu├®s
MyProg.obj ; le fichier d'entr├®e
comctl32.lib ;
user32.lib ; fichiers lib pour chaque API
gdi32.lib ; qui appelle votre programme, ces
kernel32.lib ; fichiers sont livr├®s avec le linkerVI-M-3-c. D├®finitions facilitant l'interfa├¦age avec l'├®diteur de liens Microsoft▲
Pour donner ├Ā votre code source une meilleure apparence en utilisant l'├®diteur de liens Microsoft vous pouvez faire en sorte que les appels d'API soient enrichis de mani├©re appropri├®e en d├®finissant le nom de l'API pour une utilisation tout au long de votre code, par exemple┬Ā:
GetKeyState=_GetKeyState@4
CALL GetKeyStateou, pour appeler l'API plus directement, vous pouvez utiliser┬Ā:
GetKeyState=__imp__GetKeyState@4
CALL [GetKeyState]VI-M-4. Conservation de symboles de soulignement dans les appels de biblioth├©que avec le commutateur /gl▲
Certains ├®diteurs de liens, tels que MinGW Linker, attendent au moins un symbole de soulignement pour les appels vers les fonctions C. Si dans GoAsm vous appelez une fonction dans une biblioth├©que de code statique, cette biblioth├©que peut faire des appels ├Ā des fonctions C. Mais GoAsm ├®limine normalement le symbole de soulignement dans la perspective que vous allez normalement utiliser GoLink. Mais si vous utilisez un ├®diteur de liens de ce type, il faut que le soulignement soit conserv├®. C'est pr├®cis├®ment la fonction du commutateur /gl dans la ligne de commande.
VII. Programmation en 64 bits▲
Ce chapitre est destin├® ├Ā ceux qui souhaitent ├®crire des programmes 64 bits pour les processeurs AMD64 et Intel IA 32/64 fonctionnant en x64 (Windows 64 bits), en utilisant GoAsm (assembleur), GoRC (compilateur de ressources) et GoLink (linker). Il peut ├®galement int├®resser ceux qui ├®crivent des programmes en assembleur 64 bits pour Windows avec d'autres outils.
VII-A. Introduction ├Ā la programmation 64 bits▲
VII-A-1. Programmer en 64 bits, c'est simple┬Ā!▲
Malgr├® les diff├®rences entre les processeurs 64 bits et leurs homologues 32 bits et entre les syst├©mes d'exploitation x64 (Win64) et Win32, l'├®criture des programmes Windows 64 bits est aussi facile qu'elle l'├®tait dans Win32 avec l'assembleur GoAsm.
En fait, vous pouvez utiliser sans h├®sitation le m├¬me code source pour cr├®er un ex├®cutable pour les deux plateformes si vous vous conformez ├Ā l'ensemble de r├©gles d├®crites plus avant dans ce chapitre.
Vous pouvez ├®galement convertir un code source 32 bits existant en 64 bits sachant qu'une partie du travail n├®cessaire ├Ā cet effet peut ├¬tre fait automatiquement en utilisant le convertisseur AdaptAsm.
VII-A-2. Diff├®rences entre les ex├®cutables 32 bits et 64 bits▲
Bien que les ex├®cutables 32 bits et 64 bits s'appuient sur le m├¬me format PE (Portable Executable), il existe un certain nombre de diff├®rences importantes. Leur ampleur a pour cons├®quence que le code 32 bits ne pourra fonctionner sur Win64 qu'en utilisant le Windows du sous-syst├©me Windows (WOW64). Cela fonctionne par l'interception des appels d'API de l'ex├®cutable et la conversion des param├©tres en accord avec les exigences de Win64. En revanche, le code 64 bits ne fonctionnera pas du tout sur les plateformes 32 bits.
L'ex├®cutable contient un flag qui indique au syst├©me au moment du chargement s'il est en 32 ou 64 bits. Si le chargeur x64 voit un ex├®cutable 32 bits, WOW64 se lance automatiquement. Cela signifie qu'il est impossible de faire cohabiter dans le m├¬me ex├®cutable du code 32 et 64 bits.
Il r├®sulte de ce qui pr├®c├©de que le programmeur doit choisir entre┬Ā:
- faire une version de l'application (Win32) qui fonctionnera sur les deux plateformes┬Ā;
- faire deux versions de l'application, une pour Win32, l'autre pour Win64.
Pour ceux qui sont int├®ress├®s par le format de fichier PE, voici un r├®sum├® des principales diff├®rences entre les ex├®cutables 32 bits et 64 bits.
- Le format de fichier PE pour les fichiers Win64 se nomme ┬½┬ĀPE +┬╗.
- La taille du champ d'en-tête optionnel dans l'en-tête COFF est 0F0h dans un fichier PE+ et 0E0h dans un fichier PE.
- Le ┬½┬Ātype de machine┬Ā┬╗ dans l'en-t├¬te COFF n'est pas 14CH (comme pour les processeurs x86), mais 8664h (pour le processeur AMD64).
- Le ┬½┬Ānombre magique┬Ā┬╗ au d├®but de l'en-t├¬te optionnel est 20Bh au lieu de 10Bh.
- La ┬½┬Āmajorsubsystemversion┬Ā┬╗ dans un fichier PE+ est de 5 au lieu de 4 dans un fichier PE.
- ┬½┬ĀL'image┬Ā┬╗ ex├®cutable (le code/data tel que charg├® en m├®moire) d'un fichier Win64 est limit├®e en taille ├Ā 2 Go. En effet, les processeurs AMD64 / EM64T utilisent l'adressage relatif pour la plupart des instructions, et l'adresse relative est conserv├®e dans un DWord. Un DWord suffit seulement ├Ā g├®rer une valeur relative de ┬▒ 2 Go.
- La table d'adresses d'importation (o├╣ le chargeur remplace les adresses des appels externes telles que les adresses des API dans les DLL syst├©me) est ├®largie ├Ā 64 bits, tout comme la table d'importation. En effet, l'adresse d'appels externes pourrait ├¬tre n'importe o├╣ dans la m├®moire.
- La base d'image pr├®f├®r├®e, les champs SizeofStackReserve, SizeofStackCommit, SizeofHeapReserve et SizeofHeapCommit dans l'en-t├¬te optionnel sont ├®largis de 4 ├Ā 8 octets.
- L'adresse de base par d├®faut dans Win64 est 400000h comme dans les fichiers Win32.
- Les ex├®cutables 64 bits qui assurent correctement en Win64 int├®gral une gestion d'exception compl├©te contiennent une section .pdata g├®rant les tables n├®cessaires ├Ā cet effet.
Vous pouvez explorer les arcanes d'un fichier PE en utilisant l'utilitaire PEView de Wayne J. Radburn.
VII-A-3. Diff├®rences entre Win32 et Win64 (pour AMD64/EM64T)▲
Voici les principales diff├®rences entre Win32 et Win64 susceptibles d'int├®resser le programmeur en assembleur ou Windows┬Ā:
- Convention d'appel┬Ā:┬ĀWin32 utilise la convention STDCALL alors que Win64 utilise la convention FASTCALL.
Dans STDCALL tous les param├©tres envoy├®s ├Ā une API sont pouss├®s successivement sur la pile (avec un PUSH). Dans Win32 le pointeur de pile (ESP) est r├®duit de quatre octets ├Ā chaque PUSH. En STDCALL il est de la responsabilit├® de l'API de restaurer l'├®quilibre de la pile en sortie.
En FASTCALL, les quatre premiers param├©tres sont envoy├®s ├Ā l'API par l'interm├®diaire de registres (dans l'ordre┬Ā: RCX, RDX, R8 puis R9), mais le cinqui├©me param├©tre et les suivants sont classiquement mis en pile par des PUSH. Dans Win64, le pointeur de pile (RSP) est r├®duit de huit octets ├Ā chaque PUSH. Contrairement ├Ā STDCALL, il n'est pas de la responsabilit├® de l'API de r├®tablir l'├®quilibre de la pile en fin d'ex├®cution. Cette t├óche incombe ├Ā l'appelant de l'API. Ce dernier doit ├®galement veiller ├Ā ce qu'il y ait un espace suffisant sur la pile pour que l'API puisse y stocker les param├©tres pass├®s dans les registres. En pratique, cela est obtenu en r├®duisant le pointeur de pile de 32 octets juste avant l'appel.
Notez que dans GoAsm tout le travail requis par la convention d'appel FASTCALL se fait automatiquement si vous utilisez INVOKE ou ARG suivie de INVOKE. Voir la section concernant le codage pour se conformer ├Ā la convention d'appel FASTCALL. L'utilisation de ARG et INVOKE est d├®crite en d├®tail dans le corps du manuel GoAsm.
Notez que GoAsm ne fait pas encore ceci pour les param├©tres qui doivent ├¬tre envoy├®s dans les registres XMM (i.e. dans instructions en virgule flottante).
- Windows utilise la convention FASTCALL pour appeler les proc├®dures de fen├¬tre et autres proc├®dures callback dans votre application. Cela signifie que vos proc├®dures de fen├¬tre vont r├®cup├®rer les param├©tres d'une mani├©re diff├®rente sous Win64. En outre, les proc├®dures de fen├¬tre n'ont plus ├Ā restaurer la pile ├Ā l'├®quilibre en sortie.
Notez que GoAsm mettra en ┼ōuvre ces choses automatiquement si vous utilisez FRAME ŌĆ” ENDF qui est d├®crite en d├®tail dans le corpus du manuel GoAsm.
- Toutes les fonctions utilisant une trame de pile (y compris les proc├®dures de fen├¬tres) doivent respecter certaines r├©gles si elles souhaitent faire usage de la gestion d'exceptions. Les outils doivent ├®galement ajouter des enregistrements de trame d'exception ├Ā l'ex├®cutable. Ces aspects seront ├®galement g├®r├®s automatiquement par les outils ┬½┬ĀGo┬Ā┬╗.
Notez cependant qu'ils ne sont pas encore disponibles ├Ā ce jour.
- Volatilit├® des registres. En Win32, les proc├®dures de fen├¬tres et autres proc├®dures callback doivent restaurer le contenu des registres EBP, EBX, EDI et ESI avant de retourner ├Ā l'appelant (si la valeur de ces registres est modifi├®e). Cette fonction est assur├®e par les API Windows (ces registres ne changent pas lorsque vous appelez une API). C'est pour cette raison qu'ils re├¦oivent le qualificatif de registres ┬½┬Ānon volatils┬Ā┬╗. Dans Win64, cette cat├®gorie de registres est ├®tendue ├Ā RBP, RAX, RDI, RSI, R12 ├Ā R15 et XMM6 ├Ā XMM15.
Les registres dits ┬½┬Āvolatils┬Ā┬╗ sont ceux qui peuvent ├¬tre modifi├®s par les API, et dont vous n'avez pas besoin pour sauvegarder et restaurer dans vos proc├®dures de fen├¬tre et autres proc├®dures callback. Dans Win32, les registres volatils ├Ā usage g├®n├®ral ├®taient EAX, ECX et EDX. Ceux-ci sont maintenant ├®tendus ├Ā RAX, RCX, RDX, et R8 ├Ā R11.
- Vous pourriez ne pas avoir pr├®vu cela, mais dans l'assemblage 64 bits pour AMD64, les pointeurs de code et de donn├®es dont les adresses sont dans l'ex├®cutable ne sont encore qu'├Ā 32 bits. Cela rejoint le fait que l'adressage relatif RIP limite la taille de l'ex├®cutable ├Ā 2 Go. Les pointeurs vers des adresses externes, telles que les fonctions de DLL, sont ├Ā 64 bits afin que la fonction puisse se situer n'importe o├╣ dans la m├®moire. Voir, ├Ā ce sujet la section tailles des adresses de call.
- En Win64 la taille de donn├®e de tous les handles et pointeurs est maintenant de 64 bits au lieu de 32 bits. Voir ├Ā ce sujet la section modifications des types de donn├®es Windows.
- En Win64 il y a des exigences plus strictes pour l'alignement de la pile, des donn├®es, et pour les structures (voir la section alignement et comblement automatiques des structures et de leurs membres).
- Les API Windows ont ├®t├® modifi├®es pour fonctionner en 64 bits. Il y a, cependant, un petit nombre de nouvelles API pour g├®rer les exigences suppl├®mentaires de fonctionnement en 64 bits. En voici la liste┬Ā:
- GetClassLongPtr┬Ā;
- GetWindowLongPtr┬Ā;
- SetClassLongPtr┬Ā;
- SetWindowLongPtr.
Notez que, comme dans Win32, vous pouvez ├®crire vos applications soit avec la version ANSI (cas le plus courant), soit avec la version Unicode des API. Voir le chapitre ┬½┬Ā├ēcriture des programmes Unicode┬Ā┬╗ du volume 2.
VII-A-4. Diff├®rences entre les processeurs x86 et x64▲
Les principales diff├®rences r├®sident dans l'extension de la gamme registres disponibles, des modifications apport├®es ├Ā quelques instructions et l'utilisation de l'adressage relatif RIP. Les notes ci-dessous font r├®f├®rence au processeur AMD64 en mode 64 bits. Dans ce mode ce processeur peut ├®galement faire fonctionner des ex├®cutables 32 bits.
VII-A-5. Registres▲
L'AMD64 ajoute plusieurs nouveaux registres ├Ā ceux disponibles dans la s├®rie de processeurs x86, et propose ├®galement de nouvelles fa├¦ons d'aborder les registres existants.
- Les registres ├Ā ┬½┬Āusage g├®n├®ral┬Ā┬╗ EAX, EBX, ECX, EDX, ESI, EDI, EBP et ESP sont tous ├®largis ├Ā 64 bits et prennent respectivement pour nom RAX, RBX, RCX, RDX, RSI, RDI, RBP et RSP.
- Vous pouvez toujours acc├®der au DWord de poids faible de ces registres (i.e. les 32 bits moins significatifs) en utilisant les noms originels EAX, EBX, ECX, EDX, ESI, EDI, EBP et ESP.
- Vous pouvez toujours acc├®der au mot de plus faible poids de ces registres (i.e. les 16 bits moins significatifs) en utilisant les noms originels AX, BX, CX, DX, SI, DI, BP et SP.
- Vous pouvez toujours acc├®der au premier octet de RAX, RBX, RCX et RDX (i.e. les 8 bits les moins significatifs) en utilisant les noms existants AL, BL, CL, DL comme dans le processeur x86. De plus, il vous est d├®sormais possible de communiquer avec l'octet de plus faible poids des registres ┬½┬Ād'index┬Ā┬╗ en utilisant SIL, DIL, BPL et SPL. SIL correspond, par exemple, aux 8 bits les moins significatifs du registre d'index RSI.
- De m├¬me, vous pouvez toujours acc├®der au deuxi├©me octet (bits 8 ├Ā 15) de RAX, RBX, RCX et RDX en utilisant les noms existants AH, BH, CH, DH comme dans le processeur x86. Cependant, les opcodes pour ce faire ont ├®t├® modifi├®s dans le processeur AMD64. Ils entrent en conflit maintenant avec les opcodes d├®signant la version 8 bits des registres ├®tendus R8 ├Ā R15. Vous ne pouvez donc pas utiliser AH, BH, CH, DH et R8B ├Ā R15B dans la m├¬me instruction.
- Il y a huit nouveaux registres 64 bits (les ┬½┬Āregistres ├®tendus┬Ā┬╗) nomm├®s R8 et R15.
- Le DWord de plus faible poids de ces registres (i.e. les 32 bits les moins significatifs) est accessible sous la forme R8D ├Ā R15D.
- Le mot de plus faible poids de ces registres (i.e. les 16 bits les moins significatifs) est accessible sous la forme R8W ├Ā R15W.
- L'octet de plus faible poids de ces registres (i.e. les 8 bits les moins significatifs) est accessible sous la forme R8B ├Ā R15B.
- Il y a huit nouveaux registres XMM (128 bits) nomm├®s XMM 8 ├Ā XMM 15.
- Les registres MMX 64 bits (MM0 ├Ā MM7) sont toujours disponibles. Comme dans le processeur x86, ils sont ├®galement utilis├®s en tant que registres ├Ā virgule flottante (ST0 ├Ā ST7) pour les instructions x87 en virgule flottante.
- Le pointeur d'instruction est maintenant dans le registre 64 bits RIP.
VII-A-6. Instructions▲
- Certaines instructions ne sont pas disponibles dans le mode 64 bits. Les opcodes sont maintenant utilis├®s ├Ā d'autres fins. La liste compl├©te est fournie dans les manuels AMD et Intel et comprend AAA, AAD, AAM, AAS, DAA, DAS, PUSH CS, ainsi que les op├®rations PUSH et POP sur les registres de segment DS, ES et SS.
- La port├®e des instructions est ├®largie pour accueillir les nouveaux registres et les nouvelles formes d'adresse, par exemple┬Ā:
MOV RAX, immediate ; m├®morise un nombre 64 bits dans un registre 64 bits
JRCXZ >L1 ; si RCX = 0 saut vers l'avant au label L1- Les instructions de cha├«ne sont maintenant agrandies pour permettre l'adressage 64 bits pour, par exemple┬Ā:
LODSB ; ├®quivaut maintenant ├Ā MOV AL, [RSI] puis INC RSI
LODSW ; ├®quivaut maintenant ├Ā MOV AX, [RSI] puis ADD RSI, 2
LODSD ; ├®quivaut maintenant ├Ā MOV EAX, [RSI] puis ADD RSI, 4
LODSQ ; NOUVEAU ! ├®quivaut ├Ā MOV RAX, [RSI] puis ADD RSI, 8
CMPSB ; ├®quivaut maintenant ├Ā CMP B[RSI], B[RDI] puis INC RSI, RDI
CMPSQ ; NOUVEAU ! ├®quivaut ├Ā CMP Q[RSI], Q[RDI] puis ADD RSI, 8 et ADD RDI, 8
MOVSW ; ├®quivaut maintenant ├Ā MOV W[RDI], W[RSI] puis ADD RSI, 2 et ADD RDI, 2
MOVSQ ; NOUVEAU ! ├®quivaut ├Ā MOV Q[RDI], Q[RSI] puis ADD RSI, 8 et ADD RDI, 8
SCASD ; ├®quivaut maintenant ├Ā CMP [RDI], EAX puis ADD RDI, 4
SCASQ ; NOUVEAU ! ├®quivaut ├Ā CMP [RDI], RAX puis ADD RDI, 8
STOSQ ; NOUVEAU ! ├®quivaut ├Ā MOV [RDI], RAX puis ADD RDI, 8Les pr├®fixes de r├®p├®tition REP, REPZ et REPZ utilisent RCX en lieu et place de ECX. Les instructions de boucle LOOP, LOOPZ et LOOPNZ font de m├¬me. L'instruction de consultation de table XLAT utilise RBX plut├┤t que EBX.
- En dehors de ce qui pr├®c├©de, la seule nouvelle instruction notable utilisable par les programmeurs est MOVSXD qui peut d├®placer de 32 bits de donn├®es ├Ā partir d'un registre ou de la m├®moire vers un registre 64 bits, avec extension du bit de signe 31 dans tous les bits sup├®rieurs. On note aussi un ensemble de nouvelles instructions syst├©me.
- Dans l'AMD64, chaque instruction PUSH et POP d├®place le pointeur de pile de 8 octets au lieu de 4 octets comme dans le processeur x86. Cela signifie que l'instruction PUSH registre 32 bits n'est plus admise sur le processeur AMD64. Pour aider ├Ā la compatibilit├® du code source, GoAsm traite (par exemple) PUSH EAX comme ├®quivalent ├Ā PUSH RAX. En mode /x86, GoAsm traite PUSH RAX comme ├®quivalent ├Ā PUSH EAX. Ces interpr├®tations automatiques de l'├®criture initiale exigent une grande attention de la part du programmeur.
- PUSH immediate sur l'AMD64 prend une valeur imm├®diate limit├®e ├Ā 32 bits (nombre), en ├®tend le signe du bit 31 en copiant ce dernier du bit 32 au bit 63 inclus, puis pousse en pile l'ensemble 64 bits ainsi constitu├®. Il n'y a en effet aucune instruction capable de pousser directement une valeur imm├®diate 64 bits sur la pile. Pour cette raison, l'instruction PUSH ADDR CHOSE n'est pas reconnue sur l'AMD64 (la valeur de d├®calage est trait├®e comme ├®tant imm├®diate). Le probl├©me ici est que la valeur imm├®diate courante de tout d├®calage est inconnue jusqu'au moment de l'├®dition de liens et qu'au moment de l'assemblage il est impossible pour l'assembleur de savoir si ce d├®calage est au-dessus 7FFFFFFFh et qu'il serait ainsi touch├® par l'extension de signe.
Par cons├®quent, dans GoAsm, PUSH ADDR CHOSE fait usage du registre R11 et profite de l'adressage relatif RIP plus court de LEA avec le codage suivant┬Ā:
LEA R11, [CHOSE]
PUSH R11- Les instructions 3DNow! sont toujours disponibles dans le AMD64. On ne sait pas si elles sont maintenant disponibles sur les processeurs compatibles avec la technologie Intel EM64T.
VII-A-7. L'adressage relatif RIP▲
Certaines instructions du processeur AMD64 qui adressent le code ou les donn├®es, utilisent l'adressage relatif RIP pour ce faire. L'adresse relative est contenue alors dans un DWord qui fait partie de l'instruction. Lorsque vous utilisez ce type d'adressage, le processeur ajoute trois valeurs┬Ā:
- le contenu du DWord contenant l'adresse relative┬Ā;
- la longueur de l'instruction┬Ā;
- la valeur de RIP (le pointeur d'instruction courant) au d├®but de l'instruction.
La valeur r├®sultante est alors consid├®r├®e comme l'adresse absolue de donn├®e ou de code devant ├¬tre trait├®e par l'instruction. Dans la mesure o├╣ l'adresse relative peut ├¬tre n├®gative, il est possible d'adresser la donn├®e ou le code plus t├┤t, ou plus tard, dans la repr├®sentation de RIP. La gamme est d'environ ┬▒ 2┬ĀGo, en fonction de la taille de l'instruction. Si l'on consid├©re que l'adressage relatif ne peut s'exercer au-del├Ā de cette plage, cela constitue la limite pratique de taille des repr├®sentations 64 bits.
L'adressage relatif RIP agit ├Ā l'insu de l'utilisateur. Le processeur utilise ce mode si les opcodes contiennent certaines valeurs (dans l'octet ModRM, le champ Mod est ├®gal ├Ā 00 binaire, et le champ r/m est ├®gal ├Ā 101 binaire). Vous ne pouvez pas en prendre le contr├┤le, sauf en changeant le type d'instructions que vous utilisez. En g├®n├®ral, voici les r├©gles qui d├®terminent si oui ou non une instruction utilise l'adressage relative RIP.
- Les adresses dans les donn├®es ne peuvent pas utiliser l'adressage relatif RIP puisque la valeur de ce registre ne peut ├¬tre connue au moment o├╣ ces adresses sont d├®finies. Au lieu de cela, une adresse absolue pour l'insertion est calcul├®e au moment de l'├®dition des liens. Ainsi, les instructions suivantes n'utilisent pas l'adressage relatif RIP, mais lui pr├®f├©rent l'adressage absolu┬Ā:
MyDataLabel1 DQ MyDataLabel3 ; adresse du label de donn├®e
MyDataLabel2 DQ MyCodeLabel ; adresse du label de code
MyDataLabel3 DQ $ ; utilisation du pointeur courant de donn├®e
MyDataLabel4 DD MyDataLabel3 ; adresse du label de donn├®e
MyDataLabel5 DT MyCodeLabel ; adresse du label de code
MyDataLabel6 DD $ ; utilisation du pointeur courant de donn├®eNotez que, dans la pratique, l'adresse absolue est contenue dans un DWord et non dans un QWord. Voil├Ā pourquoi, dans les exemples qui pr├®c├©dent, les adresses de donn├®e et de code peuvent ├¬tre contenues dans une d├®claration de donn├®es DWord. Cette restriction est possible parce que la taille pratique de l'image est limit├®e ├Ā 2┬ĀGo de toute fa├¦on en raison des restrictions impos├®es par l'adressage relatif RIP.
- Les offsets convertis en valeurs imm├®diates soit au moment de l'assemblage, soit au moment de l'├®dition des liens utilisent l'adressage absolu plut├┤t que l'adressage relatif. Par exemple, les instructions suivantes n'utilisent pas l'adressage relatif RIP, mais lui pr├®f├©rent l'adressage absolu┬Ā:
MOV RAX, ADDR MyDataLabel3 ; adresse du label de donn├®e copi├®e dans un registre
MOV MM0, ADDR MyCodeLabel ; adresse du label de code copi├®e dans un registre
MOV Q[RSP], ADDR MyDataLabel3 ; adresse du label de donn├®e copi├®e dans une adresse m├®moire
MOV Q[RSP], ADDR MyCodeLabel ; adresse du label de code copi├®e dans une adresse m├®moireCependant, GoAsm code en fait MOV RAX, ADDR MyDataLabel3 et les instructions similaires en utilisant l'instruction LEA plus courte, qui utilise l'adressage relatif RIP.
├Ć noter ├®galement que pour un MOV ├Ā destination de la m├®moire d'un ADDR, GoAsm utilise le registre R11 et tire avantage de l'adressage relatif RIP plus court de LEA avec le codage suivant┬Ā:
LEA R11, ADDR Non_Local_Label
MOV [Memory64], R11- Voici des exemples d'autres instructions qui utilisent l'adressage relatif RIP┬Ā:
MOV RAX, [MyDataLabel3+55h] ; adresse du label de donn├®e
RCL Q[MyDataLabel3], 1 ; adresse du label de donn├®e
MOV Q[MyDataLabel3], 20h ; adresse du label de donn├®e
PAVGUSB MM3, [MyDataLabel3] ; instruction 3DNow!
CALL ExitProcess ; adresse du label de code (API syst├©me)
JMP InternalCodeLabel ; adresse du label de code ├Ā l'int├®rieur du module
CALL InternalCodeLabel ; adresse du label de code ├Ā l'int├®rieur du module
CALL ExternalCodeLabel ; adresse du label de code ├Ā l'ext├®rieur du module
PUSH [MyData] ; sauvegarde du contenu d'un label de donn├®e
POP [MyData] ; restauration du contenu d'un label de donn├®eNotez que, dans le cas d'un appel externe, l'adresse relative pointe sur la table d'adresses d'importation (Import Address Table). Dans la mesure o├╣ cette table est maintenant ├®tendue ├Ā 64 bits, il est possible d'appeler un label de code partout dans la m├®moire.
- LEA utilise l'adressage relatif RIP. Par exemple┬Ā:
LEA RBX, MyDataLabel3 ; charge dans RBX l'adresse du label de donn├®e- L'adressage relatif RIP n'est pas utilis├® lorsque le label de donn├®e ou de code est compl├®t├® par un registre d'index. Bien que cela puisse sembler ├®trange, la raison semble ├¬tre que l'ajout d'informations sur le registre sur l'opcode signifie que le processeur ne peut plus reconna├«tre l'instruction en tant qu'utilisatrice de l'adressage relatif RIP (dans l'octet ModRM, le champ Mod n'est plus ├®gal ├Ā 00 binaire, et le champ r/m n'est plus ├®gal ├Ā 101 binaire). Cela signifie que les instructions suivantes utilisent des adresses absolues plut├┤t que relatives┬Ā:
MOV RAX, [ESI+MyData]
RCL Q[EBX+MyData], 1
MOV Q[RSI*2+MyData], 44444444h
PAVGUSB MM3, [R12+MyData]
LEA RBX, MyData+RSI
CALL [MyCall+RDI]
JMP [MyJump2+RDI]
PUSH [MyCall+RSI]
POP [MyCall+R12]Dans la mesure o├╣ l'adressage relatif RIP n'est pas utilis├® ici, la Base Image doit ├¬tre inf├®rieure ├Ā 7FFFFFFF pour que ces types d'instructions fonctionnent correctement. Ces instructions doivent ├¬tre r├®am├®nag├®es si vous utilisez une plus grande Base Image, sauf ├Ā pratiquer l'├®dition de liens avec l'option /LARGEADDRESSAWARE.
Ayant ├Ā l'esprit que la taille de l'image est limit├®e ├Ā 2┬ĀGo par les dispositions ci-dessus, on pourrait penser que les avantages de l'adressage relatif RIP sont quelque peu limit├®s. Le seul int├®r├¬t de cette pratique semble r├®sider dans le fait qu'elle r├®duit le nombre de relocations qui devraient ├¬tre effectu├®es par le chargeur si une DLL venait ├Ā ├¬tre charg├®e ├Ā une adresse inattendue. Le chargeur aurait alors besoin d'ajuster toutes les adresses absolues en fonction de la base de l'image r├®elle, alors que des adresses relatives n'auraient pas ├Ā ├¬tre modifi├®es car elles se r├®f├©rent ├Ā d'autres parties de l'image virtuelle de l'ex├®cutable. Cependant, il est de bonne pratique pour le programmeur de choisir une base d'image appropri├®e au moment de l'├®dition de liens pour ├®viter la n├®cessit├® de relocations dans une DLL en premier lieu. Un bon exemple de ceci est celui des DLL syst├©me. Elles ont toutes une base d'image diff├®rente qui permet d'├®viter efficacement des conflits potentiels de l'image dans la m├®moire qui n├®cessiterait la r├®installation au moment du chargement.
VII-A-8. Taille des adresses de Call▲
Lors de l'assemblage 64 bits, un simple CALL ├Ā un label de code, par exemple
CALL CALCULATEsera cod├® E8 en tant qu'appel relatif RIP utilisant un DWord pour fournir le d├®calage de RIP. La destination de cet appel pourrait ├¬tre un label de code interne (c'est-├Ā-dire une proc├®dure ou une fonction au sein de l'ex├®cutable lui-m├¬me). Ou elle pourrait ├¬tre un label de code externe, comme une API dans une DLL syst├©me ou un label de code export├® par un autre EXE ou une DLL. La premi├©re destination de l'appel d'un label de code externe est la Table d'Adresses d'Importation (Import Address Table) qui fait partie de l'ex├®cutable lui-m├¬me. Cette table est ├®crite par le chargeur lorsque l'ex├®cutable commence. Par cons├®quent, pendant l'ex├®cution, la table contient les adresses absolues dans la m├®moire virtuelle de la destination ├®ventuelle de l'appel. Dans un ex├®cutable 64 bits, la table contient des valeurs 64 bits, de sorte que l'appel relatif RIP cod├® E8 est capable d'appeler une proc├®dure ou une fonction partout dans la m├®moire.
L'appel ├Ā une adresse m├®moire identifi├®e par un label de donn├®e, contenue dans un registre ou dans un emplacement m├®moire point├® par un registre est trait├®, en revanche, de mani├©re diff├®rente. Il n'est pas achemin├® par l'interm├®diaire de la Table d'Adresses d'Importation. Cet appel doit ├®galement permettre d'autoriser la destination de l'appel partout dans la m├®moire. Pour ce faire, il doit utiliser une adresse absolue 64 bits. Voici quelques exemples de ces types d'appels┬Ā:
CALL RAX
CALL EAX ; produit le même code que CALL RAX
CALL [Table+8h]
CALL [RSI]
CALL [ESI] ; produit le m├¬me code que CALL [RSI]Ici, vous devez tenir compte du fait que l'appel est dirig├® vers un QWord et non vers un DWord.
Voir la section quelques pi├©ges ├Ā ├®viter lors de la conversion du code source existant.
VII-B. Modifications apport├®es aux types de donn├®es Windows▲
Voici une liste des changements apport├®s aux types de donn├®es entre 32 et 64 bits.
VII-B-1. Tous les handles passent de DWORD ├Ā QWORD▲
Par exemple┬Ā:
- HACCEL, HINSTANCE, HBRUSH, HBITMAP
HCOLORSPACE, HCURSOR, HDC, HFONT
HICON, HINSTANCE, HKEY, HLOCAL
HMENU, HMODULE, HPEN, HPALETTE, HWND
(+ les autres commen├¦ant par H)
Exceptions┬Ā:
- HRESULT, HFILE demeurent des DWords, et HALF_PTR (voir ci-dessous).
VII-B-2. Tous les pointeurs passent de DWORD ├Ā QWORD▲
Par exemple┬Ā:
- LPCSTR, LPCTSTR, LPLONG, LPSTR
(+ les autres commen├¦ant par LP)
PBOOL, PHANDLE, PHKEY, PVOID
(+ les autres commen├¦ant par P)
DWORD_PTR, ULONG_PTR, UINT_PTR
(+ les autres s'achevant par _PTR)
et LRESULT
Exceptions┬Ā:
- HALF_PTR, et UHALF_PTR qui sont maintenant des DWords au lieu de Words.
POINTER_32, qui reste un pointeur 32 bits.
VII-B-3. WPARAM et LPARAM deviennent des QWORD au lieu de DWORD▲
Voici une liste des types de donn├®es qui demeurent inchang├®s┬Ā:
|
|
VII-B-4. Utilisation de l'indicateur de type commutable▲
La modification ci-dessus du type d'une donn├®e peut n├®cessiter la modification correspondante d'un indicateur de type. La lettre P est r├®serv├®e en tant qu'indicateur de type param├®trable dans toutes les situations o├╣ GoAsm pourrait s'attendre ├Ā en trouver un. Les choses peuvent se pr├®senter de la mani├©re suivante┬Ā:
#if x64
P = 8
#else
P = 4
#endifP peut prendre une valeur correspondant ├Ā l'un quelconque des indicateurs de type pr├®d├®finis tels que B, W, D, Q ou T. Concr├©tement, P contient le nombre d'octets du type. Dans l'exemple ci-dessus, P repr├®sente le type Q (valeur 8) ou D (valeur 4). Par cons├®quent, vous pouvez contr├┤ler la taille de l'instruction avec elle, par exemple┬Ā:
MOV P[RDI], 0 ; RAZ du qword ├Ā RDI si 64-bit, du dword ├Ā EDI si 32-bit
LOCAL POINTERS[10]:P ; fait un pointeur de buffer local de 80 octets si 64 bits,
; de 40 bits si 32 bitsVII-C. Exigences en mati├©re d'alignement▲
Les exigences du syst├©me dans Win64 en mati├©re d'alignement du pointeur de pile, des donn├®es et des membres de structure sont beaucoup plus strictes que dans Win32. Un mauvais alignement peut causer, au mieux une perte de performance, au pire, une exception ou une sortie inopin├®e du programme.
VII-C-1. Alignement de la pile▲
Le pointeur de pile (RSP) doit ├¬tre align├® sur une modularit├® de 16 octets lors d'un appel d'API. Cependant, cet alignement est g├®r├® automatiquement par GoAsm si vous utilisez INVOKE. Voir sur ce point la section alignement automatique de la pile.
VII-C-2. Alignement des donn├®es▲
Toutes les donn├®es doivent ├¬tre align├®es sur une ┬½┬Āfronti├©re naturelle┬Ā┬╗. Donc, un octet peut ├¬tre align├® sur un octet, un mot sur deux octets, un DWord sur quatre octets et un QWord sur huit octets. Un TWord devrait ├®galement ├¬tre align├® sur un QWord. GoAsm proc├©de ├Ā un alignement automatique lorsque vous d├®clarez des donn├®es locales (dans une zone FRAME ou USEDATA). Mais il sera n├®cessaire que vous organisiez vos propres d├®clarations de donn├®es pour garantir que les donn├®es seront correctement align├®es. La meilleure fa├¦on d'y parvenir est de d├®clarer tout d'abord tous les QWords, puis tous les DWords, puis tous les Words et, enfin, tous les octets. Les TWords (10 octets) ├®ventuels pourraient cependant mettre ├Ā mal l'alignement des d├®clarations suivantes, de sorte qu'il est recommand├® de les d├®clarer en tout premier lieu, puis de d├®clarer les types inf├®rieurs dans l'ordre d├®croissant (QWord, puis, DWord, etc.) en ayant soin de les faire pr├®c├®der par la directive d'alignement ALIGN 8.
S'agissant des cha├«nes et en conformit├® avec les r├©gles ci-dessus, les cha├«nes Unicode doivent ├¬tre align├®es sur deux octets, alors que les cha├«nes ANSI peuvent l'├¬tre sur un octet.
Lorsque des structures sont utilis├®es, elles doivent ├¬tre align├®es sur la ┬½┬Āfronti├©re naturelle┬Ā┬╗ du plus grand membre. Tous les membres de la structure doivent ├®galement ├¬tre align├®s correctement, et la structure elle-m├¬me doit ├¬tre combl├®e, le cas ├®ch├®ant, par des octets de bourrage de mani├©re ├Ā ce qu'elle puisse se terminer sur une limite naturelle (le syst├©me peut ├¬tre amen├® ├Ā ├®crire dans cette zone). En raison de l'importance fondamentale de cette contrainte, GoAsm aligne automatiquement les structures depuis la version 0.56 (b├¬ta). Voir la section Alignement et comblement automatiques des structures et de leurs membres.
VII-D. Structures Windows en programmation 64 bits▲
Windows utilise souvent les structures pour envoyer et recevoir des informations lorsque l'on utilise des API. En 64 bits, ces structures sont susceptibles d'├¬tre consid├®rablement diff├®rentes de leurs homologues 32 bits en raison de l'├®largissement de nombreux types de donn├®es ├Ā 64 bits. Voir la section ┬½┬ĀModifications apport├®es aux types de donn├®es Windows┬Ā┬╗.
VII-D-1. Structure WNDCLASS▲
Prenons par exemple la structure WNDCLASS qui est utilis├®e lorsque vous souhaitez enregistrer une classe de fen├¬tre┬Ā:
WNDCLASS STRUCT
style DD 0 ; +0 style de classe de fenêtre
DD 0 ; +4 octets de comblement
lpfnWndProc DQ 0 ; +8 pointeur vers la proc├®dure de fen├¬tre
DD 0 ; +10 nb d'octets suppl├®mentaires ├Ā allouer apr├©s la structure
DD 0 ; +14 nb d'octets suppl├®mentaires ├Ā allouer apr├©s l'instance de fen├¬tre
hInstance DQ 0 ; +18 handle de l'instance contenant la proc├®dure de fen├¬tre
hIcon DQ 0 ; +20 handle de l'ic├┤ne de classe
hCursor DQ 0 ; +28 handle du curseur de classe
hbrBackground DQ 0 ; +30 identifie la brosse de l'arri├©re-plan de la classe
lpszMenuName DQ 0 ; +38 pointeur vers le nom de ressource pour le menu de classe
lpszClassName DQ 0 ; +40 pointeur vers la chaîne contenant le nom de la classe de fenêtre
ENDSUn certain nombre de membres sont maintenant des QWords, alors qu'auparavant il s'agissait de DWords comme vous pouvez le voir dans la version 32 bits ci-dessous. Le style de classe ├Ā l'offset +┬Ā0h demeure un DWord, mais dans la version 64 bits, un bourrage de quatre octets est n├®cessaire parce que le membre suivant est un QWord. Ceci est conforme ├Ā l'exigence selon laquelle les membres d'une structure doivent ├¬tre align├®s sur leur fronti├©re naturelle. Suivent, jusqu'├Ā la fin de la structure, une s├®rie de QWords incluant trois pointeurs. Le premier (en +8h) est utilis├® pour pointer la proc├®dure Window elle-m├¬me, le second, en + 38h pointe le nom de la ressource de la classe Menu et le troisi├©me, en +40h, pointe le nom de classe de fen├¬tre. Ceci en d├®pit du fait que les programmes 64 bits tels qu'impl├®ment├®s par Win64 pour le processeur AMD64 utilisent uniquement des pointeurs 32 bits o├╣ ces pointeurs donnent les adresses des donn├®es internes. On peut en attribuer la raison au fait que les structures utilis├®es ici sont les m├¬mes que celles qui sont mises en ┼ōuvre pour la famille de processeurs Intel IA-64 (lesquels emploient, pour leur part, des pointeurs 64 bits en direction des donn├®es internes). Enfin, les handles de la structure sont ├®galement ├®tendus ├Ā 64 bits.
WNDCLASS STRUCT
style DD 0 ; +0 style de la classe de fenêtre
lpfnWndProc DD 0 ; +4 pointeur vers la proc├®dure de fen├¬tre (callback)
DD 0 ; +8 nb d'octets suppl├®mentaires ├Ā allouer apr├©s la structure
DD 0 ; +C nb d'octets suppl├®mentaires ├Ā allouer apr├©s l'instance de fen├¬tre
hInstance DD 0 ; +10 handle de l'instance contenant la proc├®dure de fen├¬tre
hIcon DD 0 ; +14 handle de l'ic├┤ne de classe
hCursor DD 0 ; +18 handle du curseur de classe
hbrBackground DD 0 ; +1C identifie la brosse de l'arri├©re-plan de la classe
lpszMenuName DD 0 ; +20 pointeur vers le nom de la ressource pour le menu de classe
lpszClassName DD 0 ; +24 pointeur de la chaîne contenant le nom de classe de fenêtre
ENDSVoici un autre exemple, cette fois celui de la structure DRAWITEMSTRUCT sous ses formes 32 et 64 bits┬Ā:
typedef struct DRAWITEMSTRUCT {
UINT CtlType; // +0
UINT CtlID; // +4
UINT itemID; // +8
UINT itemAction; // +C
UINT itemState; // +10
HWND hwndItem; // +14
HDC hDC; // +18
RECT rcItem; // +1C
ULONG_PTR itemData; // +2C
// (la taille totale de la structure est de 30h octets)
} DRAWITEMSTRUCT;typedef struct DRAWITEMSTRUCT {
UINT CtlType; // +0
UINT CtlID; // +4
UINT itemID; // +8
UINT itemAction; // +C
UINT itemState; // +10
// Dwords de bourrage
HWND hwndItem; // +18
HDC hDC; // +20
RECT rcItem; // +28
ULONG_PTR itemData; // +38
// (la taille totale de la structure est de 40h octets)
} DRAWITEMSTRUCT;En 64 bits, on retrouve l'exigence selon laquelle la structure est agrandie de telle sorte qu'elle se termine sur la limite naturelle de son plus grand membre. Cette contrainte est satisfaite en ajoutant le bourrage n├®cessaire ├Ā l'extr├®mit├® de la structure.
Dans ces m├¬mes conditions, PAINTSTRUCT devient, en 64 bits┬Ā:
PAINTSTRUCT STRUCT
hDC DQ 0 ; +0
fErase DD 0 ; +8
left DD 0 ; +C ŌöÉ
top DD 0 ; +10 Ōöé RECT
right DD 0 ; +14 right Ōöé
bottom DD 0 ; +18 bottom Ōöś
fRestore DD 0 ; +1C
fIncUpdate DD 0 ; +20
rgbReserved DB 32 DUP 0 ;+24
DD 0 ; +44 octets de bourrage pour obtenir une taille totale de 72 octets
ENDSDans la pratique, il a bien ├®t├® constat├® que le syst├©me ├®crivait dans la zone de comblement ├Ā +┬Ā44h lors de l'utilisation de PAINTSTRUCT dans certaines circonstances. Cela prouve l'importance de se conformer ├Ā ces r├©gles (sinon vous pourriez ├¬tre confront├® ├Ā un ├®crasement inopin├® des donn├®es imm├®diatement apr├©s la structure).
Notez que le d├®but des structures doit ├®galement ├¬tre align├® sur la limite naturelle du plus grand membre. Toutes les r├©gles ci-dessus garantissent, par cons├®quent, que les QWords dans la structure sont toujours align├®s selon une modularit├® de quatre octets.
VII-D-2. Alignement et comblement automatiques des structures et de leurs membres▲
Comme nous l'avons vu, l'alignement correct des structures et de leurs membres est crucial pour le bon fonctionnement du code 64 bits. Malheureusement, les fichiers d'en-t├¬te de Windows contenant les d├®finitions de structure ne contiennent pas n├®cessairement les directives de comblement n├®cessaires pour atteindre un tel alignement.
C'est pourquoi, ├Ā partir de la version 0.56 (b├¬ta), GoAsm fait ce travail automatiquement pour vous en proc├®dant comme suit┬Ā:
- GoAsm aligne toujours la structure elle-m├¬me sur la modularit├® de donn├®es correcte.
- GoAsm effectue toujours un comblement, si n├®cessaire, pour garantir que les membres de la structure sont sur leur fronti├©re naturelle. Ainsi, dans l'exemple de structure MSG ci-dessous, le comblement ├Ā +┬Ā0Ch peut ├¬tre laiss├® de c├┤t├® car ins├®r├® automatiquement par GoAsm.
- GoAsm ajoute toujours des octets de comblement ├Ā l'extr├®mit├® d'une structure de telle sorte que celle-ci se termine sur une fronti├©re naturelle. Ainsi, dans l'exemple ci-dessous, le comblement ├Ā +┬Ā2Ch peut ├¬tre laiss├® de c├┤t├® car ins├®r├® automatiquement par GoAsm.
- Les symboles cr├®├®s lors de l'utilisation d'une structure sont automatiquement ajust├®s pour satisfaire l'alignement et le comblement qui sont appliqu├®s.
MSG STRUCT
hWnd DQ 0 ; +0h
message DD 0 ; +8h
DD 0 ; comblement pour garantir l'alignement de la suite
wParam DQ 0 ; +10h
lParam DQ 0 ; +18h
time DD 0 ; +20h
point DD 0 ; +24h position de la souris (X)
DD 0 ; +28h position de la souris (Y)
DD 0 ; +2Ch comblement pour porter la taille globale de la structure ├Ā 48 octets
ENDSVous pouvez constater par vous-m├¬me l'alignement et le comblement que GoAsm a ajout├®s ├Ā votre code source si vous sp├®cifiez /l dans la ligne de commande de GoAsm et que vous examinez le fichier listing r├®sultant. Vous pouvez ├®galement faire le m├¬me constat avec le d├®bogueur.
VII-D-3. Structures - Tableau d'ensemble▲
Si vous ├®crivez un code source destin├® aux versions 32 et 64 bits de votre programme, il sera beaucoup plus facile d'utiliser l'assemblage conditionnel pour produire les structures correctes au moment de l'assemblage. De m├¬me, au lieu de remplir les structures en utilisant des d├®calages, il est nettement pr├®f├®rable d'utiliser des noms de membres. En utilisant cette m├®thode, GoAsm calcule automatiquement le d├®calage appropri├®. Cette technique a ├®t├® utilis├®e dans le fichier de d├®monstration Hello64World 3.
Vous pouvez utiliser l'assemblage conditionnel pour changer de banque de structures en une seule fois. Celles-ci peuvent être contenues dans des fichiers d'inclusion comprenant respectivement des structures 64 bits et 32 bits.
Dans la mesure o├╣ GoAsm aligne et comble automatiquement les structures, vous pouvez utiliser les d├®finitions de structure 64 bits d├®j├Ā disponibles dans les fichiers d'inclusion, ou vous pouvez constituer les v├┤tres ├Ā partir des fichiers d'en-t├¬te Windows ├Ā l'aide de l'utilitaire xlatHinc de Wayne J. Radburn.
VII-E. Choix des registres▲
La chose principale ├Ā retenir est que tous les handles de Windows sont sur 64 bits de sorte que les API op├©reront leur retour dans RAX plut├┤t que dans EAX.
La m├¬me chose vaut pour les pointeurs de Windows. Par exemple, vous pouvez demander de la m├®moire ├Ā Windows. L'adresse de cette m├®moire sera retourn├®e alors dans RAX et non dans EAX.
Cela signifie donc que
ARG 4h, 3000h, EDX, 0
INVOKE VirtualAlloc ; r├®serve et engage EDX octets de m├®moire en lecture/├®criture
MOV [EAX], 66666666h ; ins├©re un nombre au d├®but de cette m├®moireest un mauvais codage 64 bits, alors que
ARG 4h, 3000h, EDX, 0
INVOKE VirtualAlloc ; r├®serve et engage EDX octets de m├®moire en lecture/├®criture
MOV [RAX], 66666666h ; ins├©re un nombre au d├®but de cette m├®moireest correct.
├ētant donn├® que tous les pointeurs vers des labels internes de donn├®e et de code sont sur 32 bits, il est possible, en th├®orie, d'utiliser les versions 32 bits des registres ├Ā usage g├®n├®ral (EAX ├Ā ESP) pour tous ces pointeurs de telle sorte que, par exemple, vous pourriez utiliser MOV [ESI],AL au lieu de MOV [RSI],AL.
Cependant, je d├®conseille cette pratique pour les cinq raisons suivantes┬Ā:
- Cela signifie que vous devez garder une trace de ceux des pointeurs qui sont internes et de ceux qui sont externes. Vous devez pr├®voir que les externes seront sur 64 bits.
- Vous pouvez avoir besoin de deux ensembles de proc├®dures qui sont souvent utilis├®s dans votre programme, l'un utilisant des pointeurs sous forme de registres 32 bits, l'autre utilisant des pointeurs sous forme de registres 64 bits.
- Les instructions de cha├«ne telles que LODSB, MOVSW, STOSD, CMPSQ et SCASB utilisent RSI et RDI dans un programme 64 bits en lieu et place de ESI et EDI. Et les pr├®fixes de r├®p├®tition REP, REPZ et REPNZ utilisent RCX au lieu de ECX.
- L'utilisation des versions 32 bits de ces instructions dans les codes de programme 64 bits produit un opcode plus grand que pour la version 64 bits. En effet, dans un programme 64 bits, MOV [RSI], AL est le codage par d├®faut et sa conversion en MOV [ESI], AL n├®cessite l'octet 67h d'override.
- Vous pouvez toujours utiliser le m├¬me code source pour produire un programme sur les plateformes 32 bits et 64 bits ├Ā condition que vous utilisiez uniquement les registres ├Ā usage g├®n├®ral, RAX ├Ā RSP. En effet, lorsque vous utilisez le commutateur /x86 avec GoAsm, ces registres sont automatiquement consid├®r├®s, en lieu et place, comme EAX ├Ā ESP.
Vous pouvez automatiser les modifications n├®cessaires au code 32 bits pour passer au 64 bits en utilisant AdaptAsm.
Si vous avez besoin d'utiliser les registres R8 ├Ā R15, rappelez-vous que R8 ├Ā R11 sont volatils, c'est-├Ā-dire qu'ils ne seront pas pr├®serv├®s par les API. Si vous utilisez les registres non volatils R12 ├Ā R15 ├Ā l'int├®rieur des proc├®dures de fen├¬tre et de proc├®dures callback vous devez vous assurer qu'ils sont restaur├®s apr├©s utilisation. Cela peut ├¬tre fait en utilisant PUSH au d├®but et POP ├Ā la fin de la proc├®dure qui les utilise, ou en utilisant l'instruction USES.
Lors du passage des param├©tres ├Ā une API par INVOKE, vous devez garder pr├®sent ├Ā l'esprit que, dans la convention d'appel FASTCALL, les param├©tres sont transmis ├Ā l'API successivement par les registres RCX, RDX, R8 et R9. Par cons├®quent, vous ne pouvez envisager de passer des param├©tres dans des registres qui seront ├®cras├®s par GoAsm (vous obtiendriez un message d'erreur si vous essayiez de le faire).
Par exemple, la formulation qui suit est erron├®e et affiche une erreur┬Ā:
INVOKE MessageBoxW, RDX, R8, R9, R10Elle est dans cette situation parce que, si elle ├®tait autoris├®e, elle se traduirait par┬Ā:
MOV R9, R10
MOV R8, R9
MOV RDX, R8
MOV RCX, RDXo├╣ l'on peut voir en effet que le contenu des registres est ├®cras├® avant d'├¬tre utilis├® pour ├®tablir les param├©tres.
Une meilleure formulation pourrait ├¬tre┬Ā:
INVOKE MessageBoxW, R10, R9, R8, RDXQui se traduirait par┬Ā:
MOV R9, RDX
MOV RDX, R9
MOV RCX, R10Notez que GoAsm n'empêche pas le codage de MOV R8, R8.
Pour terminer, voici une formulation plus probante qui ne n├®cessite pas de code suppl├®mentaire pour passer les param├©tres car ceux-ci sont d├®j├Ā dans les registres appropri├®s┬Ā:
INVOKE MessageBoxW, RCX, RDX, R8, R9Ce code se r├®v├©le donc tr├©s efficace.
Voir aussi quelques conseils pour r├®duire la taille de votre code, qui a des implications suppl├®mentaires dans votre choix des registres et aussi quelques pi├©ges ├Ā ├®viter lors de la conversion du code source existant.
VII-F. Extension ├Ā z├®ro des r├®sultats dans les registres 64 bits▲
Il convient d'├¬tre prudent lors de l'usage conjoint de registres 32 et 64 bits parce que le processeur peut modifier le contenu de la partie haute du registre 64 bits au terme d'une op├®ration bien que rien ne le laisse pr├®sager. En effet, lors de l'├®criture de r├®sultats dans un registre 32 bits, le processeur va ├®tendre le r├®sultat sur l'ensemble des 64 bits du registre, avec pour cons├®quence de mettre inopin├®ment ├Ā z├®ro les 32 bits de plus fort poids. Ainsi, ┬Ā:
MOV RAX, -1 ; charge RAX avec 0FFFFFFFF FFFFFFFFh
AND EAX, 0F0F0F0Fh ; (apparemment) agit seulement sur EAXle processeur ├®tend ├Ā z├®ro le r├®sultat dans RAX. En d'autres termes, le DWord de poids fort de RAX sera mis ├Ā z├®ro dans cette op├®ration alors que rien de tel n'a ├®t├® explicitement demand├®. D'o├╣ le r├®sultat inattendu┬Ā: RAX = 00000000 0F0F0F0Fh et non pas 0FFFFFFFF 0F0F0F0Fh comme on pouvait s'y attendre. Cela se produit ind├®pendamment de la valeur du bit 31 de RAX et se distingue, en cela, du m├®canisme d'extension de signe.
Un ph├®nom├©ne similaire se produit lors de l'utilisation d'autres instructions. En voici un exemple avec XOR┬Ā:
MOV RAX, -1 ; charge RAX avec 0FFFFFFFF FFFFFFFFh
XOR EAX, EAX ; (apparemment) met EAX ├Ā z├®roContre toute attente, le r├®sultat dans RAX est z├®ro.
Ce ph├®nom├©ne appara├«t de la m├¬me mani├©re avec l'instruction MOV┬Ā:
MOV RCX, 1111111111111111h
MOV ECX, 88888888hLe r├®sultat, dans ce cas, est RCX=88888888h.
Vous pouvez tirer avantage de l'extension ├Ā z├®ro de diverses mani├©res. Quelques exemples en sont donn├®s dans la section quelques conseils pour r├®duire la taille de votre code. Consid├®rez ├®galement l'exemple qui suit o├╣ la structure RECT (qui est de quatre DWords) contient des valeurs qui doivent ├¬tre transmises ├Ā l'API MoveWindow en tant que QWords┬Ā:
MOV RBX, ADDR RECT
MOV EAX, [EBX] ; r├®cup├©re x-pos
MOV ECX, [EBX+4] ; r├®cup├©re y-pos
MOV EDX, [EBX+8] ; r├®cup├©re right
SUB EDX, EAX ; r├®cup├©re width
MOV R8D, [EBX+0Ch] ; r├®cup├©re bottom
SUB R8D, ECX ; r├®cup├©re height
INVOKE MoveWindow, [hWnd], RAX, RCX, RDX, R8, 0Ici seuls des registres 32 bits sont utilis├®s pour extraire les informations de la structure RECT, mais nous savons que la partie haute des versions 64 bits de ces registres sera syst├®matiquement mise ├Ā z├®ro.
Il est possible qu'il y ait une perte de rendement en se fondant sur le m├®canisme d'extension ├Ā z├®ro. Une partie de la documentation sugg├©re en effet que le processeur doit effectuer une op├®ration suppl├®mentaire pour mettre ├Ā z├®ro les bits de poids fort du registre.
VII-G. Extension de signe des r├®sultats dans les QWords▲
Vous pouvez l├®gitimement vous interroger sur la diff├®rence qui pourrait exister entre les instructions suivantes┬Ā:
MOV D[THING], 12345678h
MOV Q[THING], 12345678hCes codes produisent, contre toute attente, des r├®sultats diff├®rents┬Ā! La version DWord, comme vous vous y attendez, place la valeur 12345678H dans le DWord du label THING. La version QWord fait la m├¬me chose, mais force ├®galement ├Ā z├®ro le DWord ├Ā THING+4. Techniquement, cette instruction pratique une extension de signe sur le r├®sultat dans le QWord situ├® au label THING. Selon le m├¬me principe, si le bit le plus ├®lev├® du DWord de plus faible poids avait ├®t├® ├Ā 1, la version QWord de l'instruction aurait rempli THING+4 avec 0FFFFFFFFh. En d'autres termes, les valeurs de 32 bits dans ces instructions sont consid├®r├®es comme des nombres sign├®s, et ├®crits en m├®moire en cons├®quence.
MOV D[THING], 12345678h ; THING prend la valeur 12345678h (comme DWord)
MOV Q[THING], 12345678h ; THING prend la valeur 12345678h (comme QWord)
MOV D[THING], 82345678h ; THING prend la valeur 82345678h ie. -7DCBA988h (comme DWord)
MOV Q[THING], 82345678h ; THING prend la valeur 0FFFFFFFF 82345678h
; c'est-├Ā-dire -7DCBA988h (comme QWord)La m├¬me chose se produit si vous utilisez un registre pour traiter la zone de donn├®es, par exemple┬Ā:
MOV RSI, ADDR THING
MOV D[RSI], 12345678h ; THING prend la valeur 12345678h (comme DWord)
MOV Q[RSI], 12345678h ; THING prend la valeur 12345678h (comme QWord)
MOV Q[RSI], 82345678h ; THING prend la valeur 0FFFFFFFF 82345678h
; c'est-├Ā-dire -7DCBA988h (comme QWord)Notez que vous ne pouvez pas mettre plus de quatre octets directement dans la m├®moire en utilisant l'instruction MOV, m├¬me si vous utilisez le code 64 bits. La repr├®sentation qui suit fait donc appara├«tre une erreur┬Ā:
MOV Q[THING], 123456789ABCDEFhAu lieu de cela, il convient de proc├®der comme suit pour atteindre ce r├®sultat┬Ā:
MOV RAX, 123456789ABCDEFh
MOV [THING], RAXVII-H. Alignement automatique de la pile▲
Le pointeur de pile (RSP) doit ├¬tre align├® sur une modularit├® de 16 octets lors d'un appel d'API. Avec certaines API cela n'a pas d'importance, mais avec d'autres, un mauvais alignement va provoquer une exception. Certaines vont g├®rer l'exception elles-m├¬mes et aligner la pile au besoin (au prix, cependant, d'une perte de performances). D'autres API (├®labor├®es au minimum au d├®but du x64) ne peuvent pas g├®rer l'exception et, ├Ā moins que vous n'ex├®cutiez l'application sous le contr├┤le du d├®bogueur, il en r├®sultera une sortie de programme.
En raison de cette exigence, la documentation Win64 indique que vous ne pouvez appeler une API qu'├Ā l'int├®rieur d'une trame de pile. En effet, il est suppos├® que c'est seulement ├Ā l'int├®rieur d'une trame de pile que l'on peut garantir qu'elle sera align├®e correctement. Un appel hors trame de pile aura pour effet de d├®saligner la pile de 8 octets.
Cette exigence est tr├©s restrictive pour les programmeurs en assembleur, et occasionne de fortes migraines aux compilateurs. GoAsm r├®sout ce probl├©me en proposant l'insertion d'un codage sp├®cial avant et apr├©s chaque appel d'API (lorsque INVOKE est utilis├®) pour veiller ├Ā ce que la pile soit toujours bien align├®e au moment de l'appel. Cela soulage le programmeur en assembleur et signifie que┬Ā:
- Les appels vers les API (en utilisant INVOKE) peuvent ├¬tre faits partout dans votre code. Ils peuvent ├¬tre construits ├Ā partir de proc├®dures appel├®es par d'autres proc├®dures sans se soucier du pointeur de pile.
- PUSH et POP peuvent ├¬tre utilis├®s de la mani├©re habituelle pour sauvegarder et restaurer les registres, les adresses de m├®moire et les contenus de m├®moire sans avoir ├Ā se soucier que cela mette ou non la pile hors alignement.
- Vous pouvez utiliser le m├¬me code source ├Ā la fois pour les versions 32 bits et 64 bits de votre application (il n'y a aucune exigence pour l'alignement de la pile en 32 bits).
L'en-t├¬te pour aligner la pile au moment de chaque appel d'API se traduit pas neuf octets suppl├®mentaires par API, ce qui semble un faible prix ├Ā payer au regard du b├®n├®fice escompt├®. A contrario, pour conserver une taille de code aussi r├®duite que possible, GoAsm exploite un certain nombre de possibilit├®s pour optimiser le code, en particulier lors de l'insertion des param├©tres. Voir la section optimisations effectu├®es par GoAsm pour plus de d├®tails. Voir aussi codage pour obtenir un alignement automatique de la pile.
VII-I. Utilisation du m├¬me code source en 32 et 64 bits▲
Le pr├®sent manuel d├®crit l'utilisation d'ARG et INVOKE dans la section traitant des appels des API Windows en 32 bits et 64 bits et l'utilisation de FRAME ŌĆ” ENDF dans la section traitant des trames de pile pour callback en 32 et 64 -bits. Les constructions ARG/INVOKE et FRAME ŌĆ” ENDF de GoAsm permettent de g├®rer efficacement les changements de convention d'appel induits par la programmation 64 bits.
Si l'on r├®unit toutes ces consid├®rations, ainsi que celles ├®nonc├®es ci-dessus, il est parfaitement possible d'utiliser le m├¬me code source pour cr├®er des ex├®cutables pour les deux plateformes 32 bits et 64 bits.
Pour m├®moire, voici les r├©gles qui doivent ├¬tre suivies pour ce faire.
- Lors des appels d'API utiliser INVOKE dans votre code au lieu de CALL.
- Pour passer les param├©tres aux API utiliser ARG dans votre code au lieu de PUSH ou alors, positionner les param├©tres ├Ā la fin du INVOKE (imm├®diatement apr├©s le nom d'API).
- Utilisez FRAMEŌĆ” ENDF dans votre code lors de l'utilisation de donn├®es locales (LOCAL) ou de la collecte de param├©tres envoy├®s ├Ā une proc├®dure de fen├¬tre (ou ├Ā toute autre proc├®dure callback similaire).
- Si vous souhaitez utiliser les nouveaux registres R8-R15, XMM8-XMM 15, ou les nouveaux registres adressables en 8, 16 ou 32 octets, assurez-vous qu'ils ne sont mentionn├®s que dans la portion du script source strictement r├®serv├®e au code 64 bits lorsque vous utilisez l'assemblage conditionnel.
- Utilisez de pr├®f├®rence la forme 64 bits des registres ├Ā usage g├®n├®ral (RAX, RBP, RBX, RCX, RDX, RDI, RSI et RER) pour les pointeurs. Lorsque GoAsm proc├©dera en effet ├Ā un assemblage en 32 bits, il r├®duira automatiquement ces registres ├Ā leur configuration 32 bits.
- Si vous avez utilis├® PUSHFD et POPFD pour sauvegarder et restaurer les flags, changer pour PUSHF et POPF ou PUSH FLAGS et POP FLAGS.
- Veiller ├Ā ce que les structures, les tailles de donn├®es et les indicateurs de type soient corrects pour un usage alternatif 32/64 bits, si n├®cessaire en recourant ├Ā l'assemblage conditionnel.
- Utiliser le commutateur /x64 dans la ligne de commande pour cr├®er un ex├®cutable 64 bits, et /x86 pour cr├®er un ex├®cutable 32 bits.
Les outils ┬½┬ĀGo┬Ā┬╗ vont faire le resteŌĆ”
Notez que le commutateur /x86 ne doit pas ├¬tre utilis├® dans la ligne de commande pour un code source Win32 (le r├®server uniquement ├Ā un code source 32/64 bits commutable).
Voir le fichier Hello64World3 comme exemple de code source qui peut afficher un ┬½┬ĀHello World┬Ā┬╗ soit en Win32, soit en Win64.
VII-J. Conversion d'un code 32 bits existant en code 64 bits▲
Compte tenu des consid├®rations qui pr├®c├©dent, voici ce que vous devez faire pour convertir un code source existant 32 bits en code source 64 bits┬Ā:
- Changez tous les CALLs ├Ā destination d'API en INVOKE. Ne pas changer les CALLs autres que pour des API.
- Si vous avez utilis├® PUSH pour envoyer des param├©tres ├Ā une API dans votre source 32 bits, changer pour ARG. En revanche, ne pas utiliser ARG en lieu et place des PUSH qui ne seraient pas d├®di├®s ├Ā cet usage.
- Changez tous les registres 32 bits ├Ā usage g├®n├®ral utilis├®s comme pointeurs (qui sont donc entre crochets) par leurs homologues 64 bits (RAX, RBP, RBX, RCX, RDX, RDI, RSI et RSP). Cela vous permettra de conserver un code plus court, et de garantir que les pointeurs vers des donn├®es externes fonctionnent correctement. Pensez aussi ├Ā utiliser uniquement RSI, RDI et RCX avec les instructions de cha├«ne et les pr├®fixes de r├®p├®tition utilisant un format inf├®rieur de ces registres. Voir, ├Ā ce sujet, le paragraphe choix des registres.
- Veillez ├Ā ce que les registres qui contiennent les handles du syst├©me et d'autres valeurs fournies par le syst├©me soient chang├®s par leurs homologues 64 bits (RAX, RBP, RBX, RCX, RDX, RDI, RSI et RER).
- Ajustez l'usage des autres registres aux besoins. En g├®n├®ral pour une autre utilisation, les registres existants fonctionneront parfaitement bien, mais ne m├®langez pas l'utilisation de registres 32 bits et 64 bits en raison du m├®canisme d'extension ├Ā z├®ro des r├®sultats. Il n'y a pas besoin de modifier les PUSH et POP de registres. Ces changements sont effectu├®s automatiquement par GoAsm parce que les opcodes sont les m├¬mes (par exemple PUSH EAX est consid├®r├® comme ├®tant le m├¬me que PUSH RAX et r├®ciproquement).
- Veillez ├Ā ce que les structures, la taille des donn├®es et les indicateurs de type soient corrects dans la perspective d'une utilisation 64 bits.
- V├®rifiez que vos instructions JECXZ sont modifi├®es en JRCXZ, le cas ├®ch├®ant.
- Dans la mesure o├╣ un code 64 bits a tendance ├Ā ├¬tre un peu plus grand que son homologue 32 bits, vous pourriez constater, lors du r├®assemblage de votre code en utilisant le commutateur /x64, que certains sauts courts doivent ├¬tre r├®organis├®s car devenus hors de port├®e.
Fort heureusement, le programme AdaptAsm permet de r├®aliser automatiquement une partie de ces travaux d'adaptation.
VII-K. Utilisation de AdaptAsm.exe pour la conversion 64 bits▲
AdaptAsm est compris dans le pack GoAsm. J'ai ├®crit cet utilitaire ├Ā l'origine pour aider ├Ā convertir ├Ā la syntaxe GoAsm le code source cr├®├® sur d'autres assembleurs. Aujourd'hui, il est capable, outre les fonctions pr├®cit├®es, de convertir du code source 32 bits en code source 64 bits. Cela fonctionne aussi bien sur les scripts GoAsm que sur ceux d'autres assembleurs.
Pour plus de d├®tails sur les autres fonctionnalit├®s de AdaptAsm voir le paragraphe V.Q.
AdaptAsm s'utilise ├Ā partir de la simple ligne de commande suivante┬Ā:
AdaptAsm [command line switches] inputfile[.ext]Si aucune extension du nom du fichier d'entr├®e n'est sp├®cifi├®e, l'extension .asm est pr├®sum├®e.
Si aucune extension du nom du fichier de sortie n'est sp├®cifi├®, l'extension .adt est pr├®sum├®e.
Les commutateurs de la ligne de commande de AdaptAsm.exe sont┬Ā:
|
affiche l'aide. |
|
adapte un fichier A386. |
|
adapte un fichier MASM. |
|
adapte un fichier NASM. |
|
sp├®cifie le chemin d'acc├©s du fichier de sortie. Ex┬Ā: AdaptAsm /fo GoAsm\adapted.asm. |
|
cr├®e un fichier de sortie avec l'extension .log. |
|
supprimer l'alerte pr├®c├®dant toute ├®criture sur le fichier d'entr├®e. |
|
adapte le fichier ├Ā la plateforme 64 bits. |
|
Ce que AdaptAsm fait lorsqu'il facilite l'adaptation d'un fichier en 64 bits en utilisant le commutateur /x64 |
|
Les CALLs en direction des API sont chang├®s en INVOKE (les CALLs qui ne sont pas des appels d'API ne sont pas affect├®s). AdaptAsm r├®alise cette conversion en consultant la liste des API dans les fichiers ┬½┬Ā.h.txt┬Ā┬╗ dans le m├¬me dossier que AdaptAsm.exe. Voir la section sur les fichiers ┬½┬Āh.txt┬Ā┬╗ pour plus d'informations. Cela fonctionne avec tous les types d'appels, m├¬me si la destination est entre crochets et m├¬me si elle d├®pend d'une d├®finition (equate) ou d'un interrupteur, par exemple┬Ā: CALL ExitProcess┬Ā: chang├® en INVOKE CALL [ExitProcess]┬Ā: chang├® en INVOKE CALL INTERNAL_PROC┬Ā: inchang├® CALL SendMessage┬Ā: chang├® en INVOKE CALL SendMessageA┬Ā: chang├® en INVOKE CALL SendMessageW┬Ā: chang├® en INVOKE CALL SendMessage##AW┬Ā: chang├® en INVOKE |
|
Change PUSH en ARG pour les param├©tres envoy├®s ├Ā l'API. AdaptAsm y proc├©de en comptant le nombre correct de param├©tres ├Ā rebours du CALL et en le comparant avec le nombre correct de param├©tres figurant dans la liste des API du fichier ┬½┬Āh.txt┬Ā┬╗ dans le m├¬me r├®pertoire que AdaptAsm.exe. Voir le paragraphe sur les fichiers ┬½┬Āh.txt┬Ā┬╗ pour plus d'informations. Voici quelques exemples simples┬Ā: PUSH EBX, 0, 1100h, [hMessTV]┬Ā: PUSH est chang├® en ARG (et EBX chang├® en RBX) CALL SendMessageA┬Ā: CALL est chang├® en INVOKE PUSH EBX, 0┬Ā: PUSH est chang├® en ARG (et EBX chang├® en RBX) PUSH 1100h┬Ā: PUSH est chang├® en ARG PUSH [hMessTV]┬Ā: PUSH est chang├® en ARG CALL SendMessageA┬Ā: CALL est chang├® en INVOKE Vous avez peut-├¬tre pr├®serv├® des registres au travers des appels d'API et ceux-ci ne sont pas affect├®s, par exemple┬Ā: PUSH EAX┬Ā: PUSH demeure inchang├® (mais EAX est chang├® en RAX) PUSH EBX, 0, 1100h, [hMessTV]┬Ā: PUSH est chang├® en ARG (et EBX est chang├® en RBX) CALL SendMessageA┬Ā: CALL est chang├® en INVOKE POP EAX┬Ā: POP demeure inchang├® (mais EAX est chang├® en RAX) Toutefois, si vous avez m├®lang├® ces deux utilisations de PUSH, AdaptAsm montrera une erreur en changeant le PUSH en ARG et en notifiant le probl├©me dans le fichier journal┬Ā: PUSH EAX, EBX, 0, 1100h, [hMessTV]┬Ā: PUSH est chang├® en ARG (trop de param├©tres) CALL SendMessageA┬Ā: CALL est chang├® en INVOKE POP EAX┬Ā: restaure le registre EAX Si AdaptAsm ne peut pas trouver tous les param├©tres attendus, il affiche une erreur en changeant le CALL en INVOKE et en notifiant le probl├©me dans le fichier journal. Par exemple┬Ā: CALL INTERNAL_PROC┬Ā: inchang├® PUSH 0, 1100h, [hMessTV]┬Ā: PUSH est chang├® en ARG CALL SendMessageA┬Ā: CALL est chang├® en INVOKE (trop peu de param├©tres) Cela signifie que ce genre de chose qui pourrait ├¬tre fait en 32 bits, sera affich├® comme une erreur par AdaptAsm (et ├Ā juste titre puisque, dans l'assembleur 64 bits, chaque CALL doit imm├®diatement succ├®der aux param├©tres)┬Ā: PUSH 0, EAX, 14Eh, [hComboSev]; 14Eh = CB_SETCURSEL PUSH 0, EAX, 151h, [hComboSev]; 151h = CB_SETITEMDATA CALL SendMessageA CALL SendMessageA |
|
Les registres ├Ā usage g├®n├®ral 32 bits entre crochets sont remplac├®s par leurs homologues 64 bits afin qu'ils puissent ├¬tre utilis├®s ├Ā la fois en assemblage 32 et 64 bits. Par exemple┬Ā: MOV EAX, [EAX+EBX]┬Ā: chang├® en MOV EAX, [RAX+RBX] MOV D[EBX*8+EBP], 8h┬Ā: chang├® en MOV D[RBX*8+RBP], 8h CALL [EBX]┬Ā: chang├® en CALL [RBX] INVOKE ExitProcess, [EBX]┬Ā: chang├® en INVOKE ExitProcess, [RBX] PUSH [EBX]┬Ā: chang├® en PUSH [RBX] ou ARG [RBX] POP [EBX]┬Ā: chang├® en POP [RBX] |
|
Lorsqu'un pointeur est utilis├® avec un registre ├Ā usage g├®n├®ral 32 bits, le registre est chang├® par son ├®quivalent 64 bits, par exemple┬Ā: MOV EAX, ADDR THING┬Ā: chang├® en MOV RAX, ADDR THING CMP ESI, ADDR THING┬Ā: chang├® en CMP RSI, ADDR THING MOV EBP, OFFSET THING┬Ā: chang├® en MOV RBP, OFFSET THING LEA EAX, THING┬Ā: chang├® en LEA RAX, THING |
|
Bien que pas strictement n├®cessaire mais pour faire bonne mesure, les registres 32 bits ├Ā usage g├®n├®ral apr├©s PUSH, POP et INVOKE sont chang├®s en leur ├®quivalent 64 bits, par exemple┬Ā: PUSH EAX, EBX┬Ā: chang├® en PUSH RAX, RBX POP EBX, EAX┬Ā: chang├® en POP RBX, RAX INVOKE ExitProcess, EBX┬Ā: chang├® en INVOKE ExitProcess, RBX |
| Ce que AdaptAsm ne fait pas (et que vous devez faire ├Ā la main) |
| AdaptAsm ne peut pas d├®cider ├Ā votre place quel registre ├Ā utiliser dans d'autres circonstances. Ce choix vous incombe au cas par cas en vous inspirant toutefois des r├©gles et usages recens├®s dans la section choix des registres qui fournit quelques indications ├Ā ce sujet. |
| AdaptAsm ne garantit pas que les tailles des structures et des donn├®es sont correctes pour une utilisation en 64 bits, ni que les pointeurs vers les structures et les cha├«nes sont correctement align├®s. |
VII-L. Les fichiers ┬½┬Āh.txt┬Ā┬╗ utilis├®s par AdaptAsm avec le commutateur /x64▲
Ces fichiers sont des fichiers texte contenant des listes d'API ainsi que le nombre de param├©tres requis par chacune d'entre elles. AdaptAsm regarde ├Ā l'int├®rieur de son propre r├®pertoire pour voir si des fichiers ┬½┬Āh.txt┬Ā┬╗ sont pr├®sents. Ces fichiers sont cr├®├®s ├Ā partir de fichiers d'en-t├¬te Microsoft en utilisant l'astucieux fichier JavaScript ApiParamCount.js, ├®crit par Leland M George de West Virginia, qui a bien voulu en autoriser l'usage dans le domaine public. Ce fichier js est livr├® avec AdaptAsm ainsi que quelques fichiers h.txt pr├¬ts ├Ā l'emploi contenant les API les plus couramment utilis├®es. Si votre programme utilise des API d├®clar├®es dans d'autres fichiers d'en-t├¬te, vous pouvez constituer vos propres ┬½┬Āh.txt┬Ā┬╗ de ces fichiers en utilisant le fichier js. Il y a deux fa├¦ons d'utiliser ce dernier┬Ā:
- soit glisser-d├®placer le fichier d'en-t├¬te sur le fichier js (un fichier h.txt sera constitu├® dans le m├¬me r├®pertoire)┬Ā;
- soit ├Ā partir de la ligne de commande en utilisant la commande suivante (par exemple)┬Ā:
cscript ApiParamCount.js WinNT.hou
wscript ApiParamCount.js WinNT.hqui commande le d├®marrage du Windows Scripting Host qui g├©re les handles des fichiers JavaScript en dehors de la page Web environnements.
Si vous devez t├®l├®charger le Windows Scripting Host vous pouvez l'obtenir ├Ā partir du site Microsoft.
Sinon, vous pouvez cr├®er votre propre fichier h.txt ou modifier ceux qui existent d├®j├Ā. Le format est le suivant┬Ā:
- le premier nom d'API doit commencer au d├®but du fichier et les suivants syst├®matiquement en d├®but de ligne┬Ā;
- de nouvelles lignes sont cr├®├®es ├Ā l'aide d'un retour chariot (code ASCII d├®cimal 13) suivi d'un saut de ligne (code ASCII d├®cimal 10)┬Ā;
- une virgule suit imm├®diatement le nom de l'API┬Ā;
- le nombre de param├©tres requis par l'API suit imm├®diatement la virgule et est exprim├® par un chiffre d├®cimal en format ASCII. Si l'API ne prend pas de param├©tres le nombre est ├®gal ├Ā z├®ro.
VII-M. Commutation utilisant x64 et x86 en assemblage conditionnel▲
En plus de pouvoir d├®clencher l'assemblage 64 ou 32 bits en sp├®cifiant respectivement /x64 ou /x86 dans la ligne de commande de GoAsm, cet assembleur permet m├¬me ├Ā ces directives d'├¬tre test├®es dans l'assemblage conditionnel. Ainsi, vous pouvez ├®crire une proc├®dure de fen├¬tre distincte pour chaque plateforme et d├®terminer leur activation au moyen du test suivant┬Ā:
WndProcTable:
#if X64
MOV EAX, ADDR MESSAGES ; met en EAX la liste des messages ├Ā traiter
CALL GENERAL_WNDPROC64 ; appel du gestionnaire de message g├®n├®rique (version 64 bits)
#else
MOV EDX, ADDR MESSAGES ; met en EDX la liste des messages ├Ā traiter
CALL GENERAL_WNDPROC ; appel du gestionnaire de message g├®n├®rique (version 32 bits)
#endif
RETNotez que les mots ┬½┬Āx64┬Ā┬╗ et ┬½┬Āx86┬Ā┬╗ ne sont pas sensibles ├Ā la casse.
Voici un autre exemple o├╣ l'on commute des fichiers d'inclusion porteurs de structures┬Ā:
#if X64
#include structures64.inc
#else
#include structures32.inc
#endifVII-N. Quelques pi├©ges ├Ā ├®viter lors de la conversion du code source existant▲
VII-N-1. Vous oubliez que les param├©tres d'API sont syst├®matiquement des QWords.▲
Votre code source existant 32 bits aura ├®t├® ├®crit selon l'hypoth├©se correcte que chaque param├©tre est un DWord. Par exemple┬Ā:
ARG 4000h, [SYSTEM_INFO+4h], [MEMORY_END]
INVOKE VirtualFree ; lib├©re une page de m├®moireEn 32 bits, ce codage est correct parce qu'il y a un DWord ├Ā [SYSTEM_INFO +4h] (le DWord contient ici la taille des pages m├®moire syst├©me (celle-ci supposant que la structure a ├®t├® remplie au moyen d'un appel ├Ā l'API GetSystemInfo).
En 64 bits, ce codage est mauvais parce que la valeur ├Ā +4h est toujours un DWord, mais vous envoyez maintenant un QWord ├Ā VirtualFree et pas seulement un DWord. Cela devrait donc ├¬tre cod├® comme suit en remplacement┬Ā:
XOR RAX, RAX ; RAX = 0
MOV EAX, [SYSTEM_INFO+4h] ; r├®cup. de la taille de page dans les 32 bits de poids faible de RAX
ARG 4000h, RAX, [MEMORY_END]
INVOKE VirtualFree ; lib├©re une page de m├®moireNotez que, dans la pratique, MOV EAX met ├Ā z├®ro la partie sup├®rieure de RAX de sorte que vous pouvez supprimer la premi├©re ligne de cet exemple┬Ā!
Un probl├©me similaire se pose lors de l'interrogation du syst├©me et de la r├®ception des informations dans les donn├®es. Votre code 32 bits existant peut bien ressembler ├Ā ceci┬Ā:
ARG 0, ADDR SIZEOF_WORKAREA, 0, 48 ; 48 = SPI_GETWORKAREA (excluding tray)
INVOKE SystemParametersInfoA ; r├®cup├©re la taille de la zone de travail dans SIZEOF_WORKAREAIci, l'appel place une valeur de 32 bits dans le dword SIZEOF_WORKAREA, ce qui est correct. Cependant l'assemblage puis l'ex├®cution du m├¬me code sur une plateforme 64 bits a pour effet d'├®craser le DWord suivant en m├®moire (un QWord est envoy├®, pas un DWord). D'o├╣ la n├®cessit├® d'├®tendre SIZEOF_WORKAREA au format QWord.
VII-N-2. Vous oubliez que tous les CALLs sont maintenant avec des valeurs 64 bits.▲
Cela peut arriver facilement lors de l'utilisation de tables permettant, par exemple, d'effectuer les CALLs en direction de labels de code d├╗ment r├®pertori├®s dans ces tables. Consid├®rons le cas d'un tableau simple de labels suivant┬Ā:
DATA
Table DD CODELABEL, 2h
CODE
CALL [Table]
; ou
DATA
Table DD CODELABEL, 2h
CODE
MOV RSI, ADDR Table
CALL [RSI]Ces CALLs attendent une adresse de 64 bits qui va ├¬tre constitu├®e, contre toute attente, de l'adresse du label CODELABEL dans le DWord de poids faible et de la valeur 2 dans le Dword de poids fort. D'o├╣ une erreur plus que probable au moment de l'ex├®cution. Cela provient ├®videmment de la table qui d├®clare des DWords au lieu de QWords. La solution pour les appels internes est donc de coder comme suit┬Ā:
DATA
Table DQ CODELABEL, 2h
CODE
CALL [Table]
; ou
DATA
Table DD CODELABEL, 2h
CODE
MOV RSI, ADDR Table
XOR RAX, RAX
MOV EAX, [RSI]
CALL RAXLe code qui pr├®c├©de garantit que le DWord de poids fort de l'adresse 64 bits est bien ├®gal ├Ā z├®ro. Cela fonctionne parce que tous les pointeurs vers des labels de donn├®e et de code interne sont ├Ā 32 bits.
VII-N-3. Vous oubliez que tous les handles de Windows sont maintenant des valeurs 64 bits.▲
Dans Win64, les handles de syst├©me sont ├®tendus ├Ā 64 bits de sorte qu'il est imprudent de supposer qu'ils pourraient toujours tenir dans 32 bits. Cela signifie donc que┬Ā:
ARG 32512 ; IDC_ARROW (curseur classique en forme de fl├©che)
INVOKE LoadCursorA, 0 ; r├®cup├©re dans EAX le handle de ce curseur
MOV [WNDCLASS+28h], EAX ; et le communique ├Ā WNDCLASSproc├©de d'un mauvais codage 64 bits, alors que┬Ā:
ARG 32512 ; IDC_ARROW (curseur classique en forme de fl├©che)
INVOKE LoadCursorA, 0 ; r├®cup├©re dans RAX le handle de ce curseur
MOV [WNDCLASS+28h], RAX ; et le communique ├Ā WNDCLASSest correct.
VII-N-4. Vous oubliez que tous les POPs sont maintenant des QWords.▲
Votre code source existant 32 bits peut effectuer des POP de DWord en m├®moire. Par exemple┬Ā:
DRAW_RECTANGLE:
PUSH [RECT], [RECT+4] ; sauvegarde de la largeur et de la longueur du rectangle
; code pour ajuster le rectangle
; puis le dessiner
POP [RECT+4], [RECT] ; restauration de la longueur et de la largeur
; du rectangle pour un usage ult├®rieur
RETEn 64 bits, une structure RECT est toujours de quatre DWords comme elle l'├®tait en 32 bits. Toutefois, le deuxi├©me POP dans le code ci-dessus effacera le deuxi├©me DWord dans la structure parce que le POP agit en fait sur 64 bits, et non pas 32 bits.
Il en r├®sulte que le codage correct pour 64 bits doit s'├®crire┬Ā:
DRAW_RECTANGLE:
PUSH [RECT], [RECT+4] ; sauvegarde de la largeur et de la longueur du rectangle
; code pour ajuster le rectangle puis le dessiner
POP RAX ; restauration de la longueur du rectangle pour un usage ult├®rieur
MOV [RECT+4], EAX ; insertion d'un dword seulement
POP RAX ; restauration de la largeur du rectangle pour un usage ult├®rieur
MOV [RECT], EAX ; insertion d'un dword seulement
RETVII-O. Assemblage et ├®dition de liens pour produire un ex├®cutable▲
Pour cr├®er un fichier d'objet 64 bits avec GoAsm, utiliser la ligne de commande┬Ā:
GoAsm /x64 filenameo├╣ filename est le nom de votre fichier asm ├®crit soit comme un fichier source 64 bits soit comme un fichier source commutable 32/64 bits. Utilisez /x86 au lieu de /x64 lorsque vous assemblez un fichier source commutable 32/64 pour en faire une version 32 bits.
Le fichier objet cr├®├® par GoAsm peut ├¬tre envoy├® ├Ā GoLink ou ├Ā un autre linker de la mani├©re habituelle.
GoLink d├®tecte automatiquement si le fichier objet est en 32 ou 64 bits et cr├®e, selon le cas, le type de fichier ex├®cutable appropri├®.
Vous ne pouvez pas m├®langer des fichiers objet 32 bits et 64 bits. GoLink affichera une erreur pour toute tentative faite en ce sens.
Vous ne devez pas n├®cessairement faire des ex├®cutables 64 bits sur une machine 64 bits. En effet, les noms de DLL donn├®s ├Ā GoLink disent simplement au linker que les DLL contiennent les API utilis├®es par l'application, lesquelles API tendent ├Ā ├¬tre identiques entre les deux plateformes. Si votre application appelle des API sp├®cifiques au syst├©me 64 bits cependant, cela ne fonctionne pas.
VII-P. Quelques optimisations et am├®liorations apport├®es par GoAsm▲
GoAsm vise toujours ├Ā produire, ├Ā partir de votre script source, le code le plus compact possible. Dans le cas du 64 bits, GoAsm n'a pas encore pris en consid├®ration toutes les possibilit├®s d'optimiser le code. En effet, il subsiste encore quelques inconnues, notamment les effets sur les performances du code optimis├® sur x64.
Les optimisations et am├®liorations effectu├®es automatiquement par GoAsm sont list├®es ici pour vous aider lorsque vous regarderez le code produit par GoAsm dans le d├®bogueur.
| Optimisations et am├®liorations apport├®es par GoAsm dans tout le code |
|
Aucune de celles-ci n'affecte les flags ou n'affecte n├®gativement les performances.
|
LEA R11, ADDR Non_Local_Label PUSH R11 Voir l'explication de cette m├®thode. Notez que cela aura ├®galement lieu avec INVOKE lors de la mise en pile des arguments avec ADDR , qui comprend ├®galement l'utilisation de pointeurs vers une cha├«ne ou une donn├®e brute (ex. 'Hello' ou <'H','i',0>). Ceci affecte les flags.
PUSHRBP ADDD[RSP], +/-Displacement |
| Optimisations et am├®liorations additionnelles uniquement avec INVOKE |
|
Celles-ci peuvent affecter les flags qui n'ont pas d'importance lors de l'appel d'API. Celles qui comptent sur l'extension ├Ā z├®ro peuvent n├®cessiter une autre op├®ration de la part du processeur, mais il est suppos├® que cela n'a pas d'importance lors de l'appel d'une API. Il est plus important de r├®duire la taille du code.
Sélectionnez ou Sélectionnez |
VII-Q. Quelques conseils pour r├®duire la taille de votre code▲
Notez qu'il est possible certaines de ces optimisations nuisent ├Ā la performance.
- L'utilisation de registres 64 bits (RAX ├Ā RSP) en tant que pointeurs vers la m├®moire (par exemple, l'instruction MOV [RSI], AL) permet de gagner un octet sur la longueur de l'opcode par rapport ├Ā la variante utilisant des registres 32 bits (par exemple MOV [ESI], AL). En effet, dans ces instructions, un octet d'override 67h est n├®cessaire pour la version 32 bits.
- Il en va diff├®remment lorsque vous assignez des valeurs imm├®diates (nombres) ├Ā des registres. Dans ce cas, l'utilisation de registres ├®largis (RAX ├Ā RSP), de registres ├®tendus (R8 ├Ā R15) ou de l'une des nouvelles m├®thodes adressage des registres, ajoutent au moins un octet ├Ā chaque instruction. Par exemple, MOV RAX, 23456h occupe deux octets de plus que MOV EAX, 23456h. Le contraste est encore plus saisissant en utilisant de grands nombres, et sup├®rieurs en tout ├®tat de cause ├Ā 7FFFFFFFh, parce ceux-ci doivent ├¬tre cod├®s comme des nombres 64 bits si vous utilisez un registre 64 bits. Ainsi, le codage de MOV RAX, 80234560h occupe cinq octets de plus que celui de MOV EAX, 80234560h. Si le nombre que vous souhaitez d├®placer tient dans un octet, de plus grandes ├®conomies peuvent ├¬tre r├®alis├®es. Par exemple, le codage de MOV AL, 88h n'occupe que deux octets, alors que celui de MOV RAX, 88h atteint 10 octets.
- DEC et INC (avec un registre) utilisent maintenant deux opcodes, alors que dans les processeurs 86, ces instructions se contentaient d'un seul. Cela ├®tant, Intel recommande aujourd'hui de leur pr├®f├®rer respectivement SUB registre, 1 et ADD registre, 1 afin d'uniformiser le traitement des flags.
En effet, les instructions INC et DEC ne modifient seulement qu'une partie des bits dans le registre des flags comparativement aux instructions ADD et SUB dont elles ne sont pourtant qu'un cas particulier. Selon Intel,(2) il peut m├¬me s'av├®rer particuli├©rement probl├®matique dans certains cas d'en poursuivre l'usage. - En programmation 64 bits, l'instruction LEA register, Label est de 5 opcodes plus courte que l'instruction MOV register, ADDR Label tout en atteignant le m├¬me r├®sultat. Dans un code source GoAsm, cependant, vous pouvez utiliser l'une ou l'autre de ces deux formes puisque GoAsm s├®lectionne automatiquement la plus courte.
- PUSH ADDR THING se code sur 9 octets, alors que si vous utilisez, en remplacement, LEA RAX, THING suivi de PUSH RAX, le codage global se r├®duit ├Ā 8 octets mais pr├®sente l'inconv├®nient de modifier le contenu du registre RAX.
- Mettre ├Ā z├®ro un registre en utilisant XOR. L'instruction XOR RAX, RAX occupe 3 octets, alors que l'instruction MOV RAX, 0 occupe 10 octets parce qu'elle met en ┼ōuvre une valeur imm├®diate de 64 bits (nombre). Notez cependant que XOR affecte les flags, ce qui n'est pas le cas de MOV.
- L'instruction XOR EAX, EAX est encore plus courte avec seulement deux octets et met ├Ā z├®ro l'ensemble du registre RAX en vertu du principe d'extension ├Ā z├®ro automatique des r├®sultats.
- Une bonne fa├¦on de porter la valeur -1 dans un registre, est d'utiliser l'instruction OR registre, -1 qui, dans le cas d'un registre 64 bits, occupe 4 octets, soit un gain de 6 octets par rapport ├Ā MOV registre ,-1. Cependant, contrairement ├Ā MOV, l'instruction OR affecte les flags.
- Une comparaison dans la plage -80h ├Ā +7Fh n'occupe que 4 octets (par exemple, CMP RDX, -80h ├Ā CMP RDX, 7Fh), mais en dehors de cette plage, le codage s'effectue sur 7 octets. Par exemple, CMP RDX, 80h se code sur 7 octets.
- Vous pouvez toujours utiliser LEA pour r├®aliser certaines op├®rations arithm├®tiques intraregistre, par exemple LEA RAX, [RAX+RAX*2] qui multiplie RAX par trois. Ce code n'occupe que 4 octets.
Voir ├®galement les quelques conseils et astuces de programmation prodigu├®s dans l'annexe K de ce document.
VII-R. R├®f├®rences et liens concernant la programmation 64 bits▲
- Information about the AMD64┬Ā;
- AMD information for developers┬Ā;
- Intel - Introduction to the x64 Assembly┬Ā;
- Intel - 64-bit programming.
Newsgroups et forums┬Ā:
VIII. Annexes▲
VIII-A. Exemples de programmes en assembleur GoAsm▲
VIII-A-1. Programme HelloWorld1.asm▲
Ce programme est dit ┬½┬Āde console┬Ā┬╗, c'est-├Ā-dire qu'il est pr├®vu pour fonctionner sous l'invite de commande MS-DOS. Son action se borne ├Ā afficher le message ┬½┬ĀHello World (from GoAsm)┬Ā┬╗ ainsi que le montre la copie d'├®cran ci-dessous (texte sur fond jaune et fl├©che rouge)┬Ā:
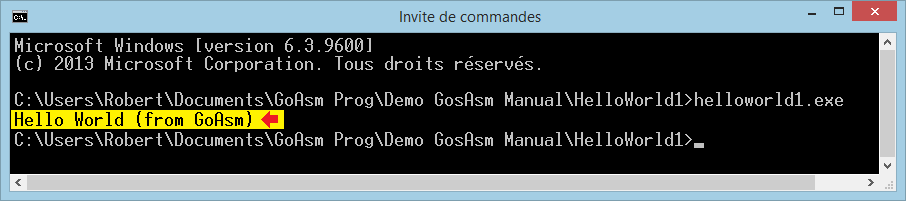
;------------------------------------------------------------------
; HelloWorld1 - copyright Jeremy Gordon 2002
; SIMPLE "HELLO WORLD" WINDOWS CONSOLE PROGRAM - for GoAsm
;
; Assemblage & ├ēdition de liens :
; GoAsm HelloWorld1 (produit un fichier PE COFF)
; GoLink /console [-debug coff] helloworld1.obj kernel32.dll
; -debug coff n'est utilis├® que s'il est souhaitable d'analyser le
; programme dans le d├®bogueur
;
; Notez que les API GetStdHandle et WriteFile rel├©vent de kernel32.dll
;------------------------------------------------------------------
;
DATA SECTION
;
RCKEEP DD 0 ; variable ├Ā usage g├®n├®ral
;
CODE SECTION
;
START:
PUSH -11D ; STD_OUTPUT_HANDLE
CALL GetStdHandle ; r├®cup├©re en EAX le handle du buffer d'├®cran actif
PUSH 0, ADDR RCKEEP ; RCKEEP va r├®cup├®rer la sortie d'API
PUSH 24D, 'Hello World (from GoAsm)' ; 24 = longueur de la chaîne
PUSH EAX ; handle du buffer d'├®cran actif
CALL WriteFile
XOR EAX, EAX ; retour de la valeur z├®ro
RETVIII-A-2. Programme HelloWorld2.asm▲
Le programme HelloWorld2.asm, ├®crit pour Windows 32 bits, permet de dessiner une ellipse dans un rectangle. La figure ci-dessous montre le r├®sultat obtenu sur l'├®cran┬Ā:
On trouvera, dans la m├¬me annexe, trois variantes de ce programme┬Ā:
- HelloWorld3.asm, toujours en 32 bits, qui est une version plus structur├®e du m├¬me programme faisant usage de structures formelles, de trames automatiques de pile FRAME ŌĆ” ENDF, de USEDATA et USES, INVOKE, de d├®finitions et de labels de nom r├®utilisables┬Ā;
- Hello64World2.asm qui est la version 64 bits de HelloWorld2.asm┬Ā;
- Hello64World3.asm qui est une version sp├®ciale destin├®e ├Ā ├¬tre compil├®e indiff├®remment pour les plateformes 32 et 64 bits.
;------------------------------------------------------------------
; HelloWorld2 - copyright Jeremy Gordon 2002
;
; SIMPLE "HELLO WORLD" WINDOWS GDI PROGRAM - for GoAsm
;
; Assemblage & ├ēdition de liens :
; GoAsm HelloWorld2 (produit un fichier PE COFF)
; GoLink [-debug coff] HelloWorld2.obj user32.dll kernel32.dll gdi32.dll
; -debug coff n'est utilis├® que s'il est souhaitable d'analyser le
; programme dans le d├®bogueur
;------------------------------------------------------------------
;
DATA SECTION
;
hInst DD 0 ; m├®morise le handle du process lui-m├¬me
hDC DD 0 ; m├®morise le handle du device context
PAINTSTRUCT DD 16 DUP 0 ; structure accueillant les infos de Windows sur WM_PAINT
MSG DD 7 DUP 0 ; structure pour accueillir les messages de Windows comme suit:
; hwnd, +4=message, +8=wParam, +C=lParam, +10h=time, +14h/18=pt
WNDCLASS DD 10D DUP 0 ; structure pour les donn├®es manipul├®es par RegisterClass:
; +0 style de classe de fenêtre (CS_)
; +4 pointeur vers la proc├®dure de fen├¬tre
; +8 nb d'octets suppl├®mentaires ├Ā allouer apr├©s la structure
; +C nb d'octets suppl├®mentaires ├Ā allouer apr├©s window instance
; +10 handle de l'instance de cette classe de fenêtre
; +14 handle de l'ic├┤ne de classe
; +18 handle du curseur de classe
; +1C identifie la brosse d'arri├©re-plan de la classe
; +20 pointeur vers le nom de ressource pour le menu de la classe
; +24 pointeur vers la chaîne correspondant au nom de la classe de fenêtre
;******************** Table de messages Windows
; (dans un programme plus ├®labor├®, il y aurait beaucoup plus de messages ├Ā traiter)
MESSAGES DD (ENDOF_MESSAGES-$-4)/8 ; = nombre de messages ├Ā traiter
DD 1h, CREATE, 2h, DESTROY, 0Fh, PAINT
ENDOF_MESSAGES: ; label utilis├® pour d├®terminer le nombre de messages
;******************************************
;
WINDOW_CLASSNAME DB 'WC', 0 ; cha├«ne destin├®e ├Ā contenir le nom de la classe de fen├¬tre
;
;------------------------------------------------------------------
CODE SECTION
;
INITIALISE_WNDCLASS: ; pr├®pare l'enregistrement de la classe de fen├¬tre
MOV EBX, ADDR WNDCLASS
MOV EAX, 9 ; compteur = 10 param├©tres ├Ā RAZ
L1:
MOV D[EBX+EAX*4], 0 ; RAZ de chaque param├©tre
DEC EAX
JNS L1
;***** additionner des infos ├Ā la classe de fen├¬tre pour toutes les fen├¬tres du programme ..
MOV EAX, [hInst] ; donner le handle au process
MOV [EBX+10h], EAX ; le constituer en tant que classe de fenêtre
PUSH 32512 ; curseur commun IDC_ARROW
PUSH 0
CALL LoadCursorA ; on r├®cup├©re dans EAX le handle de la fl├©che de curseur
MOV [EBX+18h], EAX ; et on le met dans WNDCLASS
MOV D[EBX+1Ch], 6D ; initialise la couleur de fond dans COLOR_WINDOW+1
RET
;
;*******************
CREATE: ; l'un des quelques messages trait├®s par ce prog
XOR EAX, EAX ; retourne z├®ro pour constituer la fen├¬tre
RET
;
DESTROY: ; l'un des quelques messages trait├®s par ce prog
PUSH 0
CALL PostQuitMessage ; sortie via la boucle de message
STC ; aller ├Ā DefWindowProc en plus
RET
;
; Le process qui suit dessine une ellipse dans le rectangle fourni par Windows
; sur le message WM_PAINT. Ce rectangle est la zone qui a besoin d'├¬tre mise ├Ā jour, par exemple
; au moment d'un redimensionnement ou si la fen├¬tre est d├®couverte par une autre.
;
PAINT:
MOV EBX, ADDR PAINTSTRUCT
PUSH EBX, [EBP+8h] ; EBP+8h=hwnd
CALL BeginPaint ; obtient le contexte de p├®riph├®rique ├Ā utiliser, initialise la peinture
MOV [hDC], EAX
PUSH [EBX+14h], [EBX+10h] ; extr├®mit├® basse, droite du rectangle
PUSH [EBX+0Ch], [EBX+8h] ; extr├®mit├® haute, gauche du rectangle
PUSH [hDC]
CALL Ellipse ; trace une ellipse dans le rectangle actualis├®
PUSH EBX, [EBP+8h] ; EBP+8h=hwnd
CALL EndPaint
XOR EAX, EAX
RET
;
;********** Ceci est une proc├®dure de fen├¬tre g├®n├®rale qui, dans un programme
;********** ordinaire, traite tous les messages envoy├®s ├Ā la fen├¬tre
GENERAL_WNDPROC: ; EAX peut ├¬tre utilis├® pour transmettre des informations au CALL
PUSH EBP ; utilise EBP pour ├®viter EAX, lequel peut contenir des informations
MOV EBP, [ESP+10h] ; uMsg
MOV ECX, [EDX] ; r├®cup├©re le nombre de messages ├Ā traiter
ADD EDX, 4 ; saute le dword contenant le nombre de messages
L2:
DEC ECX
JS >L3
CMP [EDX+ECX*8], EBP ; voir si c'est le message correct
JNZ L2 ; non
MOV EBP, ESP
PUSH ESP, EBX, EDI, ESI ; on sauvegarde les registres tel que requis par Windows
ADD EBP, 4 ; on saute le dword contenant le code du message
; d├©s lors : [EBP+8]=hwnd, [EBP+0Ch]=uMsg, [EBP+10h]=wParam, [EBP+14h]=lParam,
CALL [EDX+ECX*8+4] ; on appelle la proc├®dure correspondant au message
POP ESI, EDI, EBX, ESP
JNC >L4 ; nc=retourne la valeur en EAX - on n'appelle pas DefWindowProc
L3:
PUSH [ESP+18h], [ESP+18h], [ESP+18h], [ESP+18h] ; permet le changement de ESP
CALL DefWindowProcA
L4:
POP EBP
RET
;
;******************* Ceci est la proc├®dure de fen├¬tre courante
WndProcTable:
MOV EDX, ADDR MESSAGES ; EDX pointe la liste des messages ├Ā traiter
CALL GENERAL_WNDPROC ; appel du gestionnaire de message g├®n├®rique
RET 10h ; restauration de la pile comme requis par l'appelant
;
;*******************************************************************
START:
PUSH 0
CALL GetModuleHandleA ; r├®cup├®ration du handle du process
MOV [hInst], EAX ; enregistrement de ce handle au label de donn├®e hInst
CALL INITIALISE_WNDCLASS ; pr├®pare l'enregistrement de la classe de fen├¬tre
;********** ajoutons maintenant des param├©tres sp├®cifiques ├Ā la fen├¬tre ├Ā construire
MOV D[EBX], 1h+2h+40h ; CS_VREDRAW+CS_HREDRAW+CS_CLASSDC (style de classe de fenêtre)
MOV D[EBX+4], ADDR WndProcTable ; proc├®dure de fen├¬tre
MOV D[EBX+24h], ADDR WINDOW_CLASSNAME ; nom de la classe de fenêtre
PUSH EBX ; adresse structure avec donn├®es de classe de fen├¬tre
CALL RegisterClassA ; enregistre la classe de fenêtre (window class)
PUSH 0, [hInst], 0, 0 ; propri├®taire = bureau
PUSH 200D ; hauteur
PUSH 320D ; largeur
PUSH 50D, 50D ; position y, puis x
PUSH 90000000h+0C00000h+40000h+80000h+20000h+10000h ; style de fenêtre
;(POPUP+VISIBLE)+CAPTION+SIZEBOX+SYSMENU+MINIMIZEBOX+MAXIMIZEBOX
PUSH 'Hello World window made by GoAsm' ; titre de la fenêtre
PUSH ADDR WINDOW_CLASSNAME ; nom de la classe de fenêtre
PUSH 0 ; style de fen├¬tre ├®tendu
CALL CreateWindowExA ; construit la fenêtre, retourne le handle dans EAX
;************************ on entre maintenant dans la boucle de message principale
L1:
PUSH 0, 0, 0
PUSH ADDR MSG
CALL GetMessageA ; attente d'un message de Windows
OR EAX,EAX ; on regarde si c'est WM_QUIT
JZ >L2 ; oui, alors on va ├Ā L2
PUSH ADDR MSG
CALL TranslateMessage ; dans le cas contraire, conversion du message en caract├©res si n├®cessaire
PUSH ADDR MSG
CALL DispatchMessageA ; et envoi du message ├Ā la proc├®dure de fen├¬tre
JMP L1 ; apr├©s le message trait├®, boucle de retour pour un prochain
L2:
PUSH [hInst], ADDR WINDOW_CLASSNAME ; le message ├®tait WM_QUIT
CALL UnregisterClassA ; on fait en sorte que la classe soit supprim├®e
PUSH [MSG+8h] ; sortie du programme (on envoie le contenu de wParam)
CALL ExitProcess ; retour ├Ā Windows de la mani├©re appropri├®eVIII-A-3. Programme HelloWorld3.asm▲
Le programme HelloWorld3.asm, ├®crit pour Windows 32 bits, permet de dessiner une ellipse dans un rectangle. La figure ci-dessous montre le r├®sultat obtenu sur l'├®cran. HelloWorld3.asm est une version plus structur├®e de HelloWorld2.asm faisant usage de structures formelles, de trames automatiques de pile FRAME ŌĆ” ENDF, de USEDATA et USES, INVOKE, de d├®finitions et de labels de nom r├®utilisables.
On trouvera, dans la m├¬me annexe, trois variantes de ce programme┬Ā:
- HelloWorld2.asm, toujours en 32 bits, qui est une version moins structur├®e du m├¬me programme┬Ā;
- Hello64World2.asm qui est la version 64 bits de HelloWorld2.asm┬Ā;
- Hello64World3.asm qui est une version sp├®ciale destin├®e ├Ā ├¬tre compil├®e indiff├®remment pour les plateformes 32 et 64 bits.
;------------------------------------------------------------------
; HelloWorld3 - copyright Jeremy Gordon 2002
;
; "HELLO WORLD" WINDOWS GDI PROGRAM - programme de d├®monstration faisant
; usage de structures formelles, de trames automatiques de pile FRAME..ENDF,
; USEDATA et USES, INVOKE, de d├®finitions et labels de nom r├®utilisables
; dans la syntaxe GoAsm
; Assemblage & ├ēdition de liens :
; GoAsm HelloWorld3 (produisant un fichier PE COFF)
; GoLink [-debug coff] HelloWorld3.obj user32.dll kernel32.dll gdi32.dll
; -debug coff n'est utilis├® que s'il est souhaitable d'analyser le
; programme dans le d├®bogueur
;------------------------------------------------------------------
;
; La premi├©re permet de sp├®cifier un couple de structures formalis├®es
;
WNDCLASSEX STRUCT
cbSize DD 30h ; +0 taille de la structure (WNDCLASSEX seulement)
style DD ? ; +4 style de classe de fenêtre (CS_)
lpfnWndProc DD ? ; +8 pointeur de la proc├®dure de fen├¬tre
cbClsExtra DD ? ; +C nb d'octets suppl├®mentaires ├Ā allouer apr├©s la structure
cbWndExtra DD ? ; +10 nb d'octets suppl├®mentaires ├Ā allouer apr├©s l'instance de fen├¬tre
hInstance DD ? ; +14 handle de l'instance de cette classe de fenêtre
hIcon DD ? ; +18 handle de l'ic├┤ne de classe
hCursor DD ? ; +1C handle du curseur de classe
hbrBackground DD ? ; +20 identifie la brosse d'arri├©re-plan de la classe
lpszMenuName DD ? ; +24 pointeur du nom de ressource pour la classe de menu
lpszClassName DD ? ; +28 pointeur vers la chaîne du nom de classe de fenêtre
hIconSm DD ? ; +2C handle de la petite ic├┤ne
ENDS
;
RECT STRUCT
left DD ?
top DD ?
right DD ?
bottom DD ?
ENDS
;
PAINTSTRUCT STRUCT
hdc DD ?
fErase DD ?
rcPaint RECT
fRestore DD ?
fIncUpdate DD ?
rgbReserved DB 32 DUP ?
ENDS
;
; et maintenant quelques d├®finitions pour une utilisation ult├®rieure :
; *** d'abord quelques styles de classe de fenêtre
CS_VREDRAW = 1h
CS_HREDRAW = 2h
CS_CLASSDC = 40h
; *** et maintenant, certains styles de fenêtres
WS_POPUP = 80000000h
WS_VISIBLE = 10000000h
WS_CAPTION = 0C00000h
WS_SIZEBOX = 40000h
WS_SYSMENU = 80000h
WS_MINIMIZEBOX = 20000h
WS_MAXIMIZEBOX = 10000h
; *** enfin, les messages auxquels nous allons avoir affaire
WM_CREATE = 1h
WM_DESTROY = 2h
WM_PAINT = 0Fh
; *** et le reste...
COLOR_WINDOW = 5
;------------------------------------------------------------------
;
DATA SECTION
;
;------------------------------------------------------------------
wcex WNDCLASSEX ; ├®tablit la structure WNDCLASS dans DATA
hInst DD 0 ; handle du process lui-même
MSG DD 7 DUP 0 ; structure contenant des messages de Windows comme
; suit : hWnd, +4=message, +8=wParam, +C=lParam, +10h=time, +14h/18=pt
;------------------------------------------------------------------
;
CONST SECTION
;
;------------------------------------------------------------------
;
WINDOW_CLASSNAME DB 'WC', 0 ; cha├«ne destin├®e ├Ā contenir le nom
; de classe de fenêtre
;
;------------------------------------------------------------------
;
CODE SECTION
;
;------------------------------------------------------------------
INITIALISE_WNDCLASS: ; pr├®paration de WNDCLASS pour la fen├¬tre
MOV EBX, ADDR wcex
ADD EBX, 4 ; saut au-del├Ā du dword contenant la taille
MOV EAX, 10
L1:
MOV D[EBX+EAX*4], 0 ; comblement du reste de la structure avec des z├®ros
DEC EAX
JNS L1
; ***** ajout d'├®l├®ments ├Ā la classe de fen├¬tre pour toutes
; ***** les fenêtres dans le programme
MOV EAX, [hInst] ; EAX = handle du process
MOV [wcex.hInstance], EAX ; on le reporte dans la structure de classe de fenêtre
PUSH 32512 ; IDC_ARROW valeur le la fl├©che de curseur ordinaire
PUSH 0
CALL LoadCursorA ; on r├®cup├©re, dans EAX, le handle de la fl├©che de curseur
MOV [wcex.hCursor], EAX ; et on le r├®percute dans WNDCLASS
MOV D[wcex.hbrBackground], COLOR_WINDOW+1 ; on fixe la couleur de l'arri├©re-plan
RET
;
;*******************
CREATE: ; le seul message effectivement trait├® dans ce programme
XOR EAX, EAX ; retourne z├®ro pour faire la fen├¬tre
RET
;
DESTROY: ; l'un des rares messages trait├®s par ce prog
PUSH 0
CALL PostQuitMessage ; sortie via la boucle de message
STC ; aller ├Ā DefWindowProc
RET
;
;------------------------------------------------------------
;
CONST SECTION
;
;------------------------------------------------------------
; ******************** Table des messages de fenêtre
; (Dans un v├®ritable programme, cette table concernerait beaucoup plus de messages)
;
MESSAGES DD WM_CREATE, CREATE ; ├Ā chaque ligne,
DD WM_DESTROY, DESTROY ; le message puis l'adresse de code
DD WM_PAINT, PAINT
;------------------------------------------------------------
;
CODE SECTION
;
;------------------------------------------------------------
; ******************* Ceci est la proc├®dure de fen├¬tre courante
WndProc:
FRAME hwnd, uMsg, wParam, lParam ; ├®tablissement d'une trame de pile
; et obtention des param├©tres
MOV EAX, [uMsg] ; r├®cup├®ration en EAX du msg envoy├® par Windows
MOV ECX, SIZEOF MESSAGES/8 ; ECX, nb de messages de la table ├Ā tester
MOV EDX, ADDR MESSAGES ; EDX = adresse de la table
L2:
DEC ECX
JS >.notfound ; saut car message non trouv├®
CMP [EDX+ECX*8], EAX ; on regarde si c'est le bon msg dans la table
JNZ L2 ; non
CALL [EDX+ECX*8+4] ; appel de la proc├®dure correcte pour le msg
JNC >.exit
.notfound
INVOKE DefWindowProcA, [hwnd], [uMsg], [wParam], [lParam]
.exit
RET
ENDF ; fin de cette trame de pile
;
; *** et maintenant une proc├®dure, en dehors du FRAME, qui doit adresser
; *** les donn├®es locales stock├®es sur la pile dans le FRAME WndProc
; Cette proc├®dure trace une ellipse dans le rectangle fourni par Windows sur le
; message WM_PAINT. Ce rectangle est la zone qui a besoin d'├¬tre mise ├Ā jour, par
; exemple sur un redimensionnement ou si la fen├¬tre est d├®couverte par une autre.
; le trac├® est effectu├® en utilisant le contexte de p├®riph├®rique fourni par Windows.
;
PAINT:
USEDATA WndProc ; utilisation des param├©tres envoy├®s ├Ā WndProc
USES EBX, EDI, ESI ; sauvegarde des registres comme requis par Windows
LOCAL lpPaint:PAINTSTRUCT, hDC ; ├®tablit une zone de donn├®es locales
;
INVOKE BeginPaint, [hwnd], ADDR lpPaint ; met en EAX le DC (Device Context) ├Ā utiliser
MOV [hDC], EAX ; sauvegarde du DC dans les donn├®es locales
INVOKE Ellipse, [hDC], [lpPaint.rcPaint.left], \
[lpPaint.rcPaint.top] , \
[lpPaint.rcPaint.right], \
[lpPaint.rcPaint.bottom]
;
; d'autres proc├®dures de dessin pourraient ├¬tre ├®crites ici
;
INVOKE EndPaint, [hwnd], ADDR lpPaint ; retourne DC ├Ā Windows
XOR EAX, EAX ; retourne Cf=0 et EAX = 0
RET
ENDU ; fin utilisant les param├©tres envoy├®s ├Ā WndProc
;
;*******************************************************************
START:
;
INVOKE GetModuleHandleA, 0 ; r├®cup├®ration d'un handle pour le process
MOV [hInst], EAX ; on l'enregistre au label de donn├®e correspondant
CALL INITIALISE_WNDCLASS ; on initialise la structure WNDCLASS
;
; ********** on entre maintenant des param├©tres sp├®cifiques ├Ā la fen├¬tre ├Ā construire
;
MOV D[wcex.style], CS_VREDRAW+CS_HREDRAW+CS_CLASSDC
MOV [wcex.lpfnWndProc], ADDR WndProc ; proc├®dure de fen├¬tre
MOV [wcex.lpszClassName], ADDR WINDOW_CLASSNAME ; nom de classe de fenêtre
INVOKE RegisterClassExA, ADDR wcex ; m├®morisation de la classe de fen├¬tre
INVOKE CreateWindowExA, 0, ADDR WINDOW_CLASSNAME, \
'Hello World window made by GoAsm', \ ; chaîne correspondant au titre
WS_POPUP|WS_VISIBLE|WS_CAPTION|WS_SIZEBOX \ ; style de fenêtre
|WS_SYSMENU|WS_MINIMIZEBOX|WS_MAXIMIZEBOX, \
50, 50, \ ; position-x puis position-y
320, 200, \ ; largeur puis hauteur
0, 0, [hInst], 0
;
; ************************ on entre maintenant dans la boucle de message principale
;
.messloop
INVOKE GetMessageA, ADDR MSG, 0, 0, 0
OR EAX, EAX ; on regarde si c'est WM_QUIT (EAX = 0)
JZ >.quit ; oui
INVOKE TranslateMessage, ADDR MSG
INVOKE DispatchMessageA, ADDR MSG
JMP .messloop ; apr├©s le traitement du msg, boucle pour le suivant
.quit
INVOKE UnregisterClassA, ADDR WINDOW_CLASSNAME, [hInst]
INVOKE ExitProcess, [MSG+8h]VIII-A-4. Programme HelloDialog.asm▲
Ce programme affiche des messages dans une boîte de dialogue modale (cf. figure 1 ci-dessous), puis dans une MessageBox lors de la sortie (figure 2 ci-dessous).
La bo├«te de dialogue modale est faite en utilisant un mod├©le dans les donn├®es au lieu du fichier de ressources habituel.
Pour cette raison, il utilise l'API DialogBoxIndirectParamA au lieu de DialogBoxParam, cette derni├©re ├®tant d├®volue ├Ā la constitution d'une bo├«te de dialogue modale par le biais d'un fichier de ressources. Nous sommes par ailleurs dans le cas d'un mod├©le ├®tendu. L'en-t├¬te utilise le format DLGTEMPLATE et les d├®finitions de contr├┤le utilisent le format DLGITEMTEMPLATE.
fig. 1 - premi├©re fen├¬tre
fig.2 - fenêtre en sortie de programme
;------------------------------------------------------------------
; HelloDialog - copyright Jeremy Gordon 2004
;
; SIMPLE programme de Dialogue
;
; aucune inclusion de fichier n'est utilis├®e car toutes les constantes
; sont ins├®r├®es manuellement.
;
; Assemblage & ├ēdition de liens :
; GoAsm HelloDialog (produisant un fichier PE COFF)
; GoLink [-debug coff] HelloDialog.obj kernel32.dll user32.dll
; qui produit HelloDialog.exe
; -debug coff n'est utilis├® que s'il est souhaitable d'analyser le
; programme dans le d├®bogueur
;
;------------------------------------------------------------------
;
;*******************************************************************
;
DATA SECTION
;
ALIGN 4 ; juste pour souligner que ce qui suit doit ├¬tre align├® dword
; *********************** Voici le mod├©le pour le dialogue
; En-tête au format DLGTEMPLATE
DIALOG_TEMPLATE DD 10000000h|0C00000h|800h|40h| \
80h|80000h+20000h
; style WS_VISIBLE+WS_CAPTION+DS_CENTER+DS_SETFONT
; DS_MODALFRAME+WS_SYSMENU+WS_MINIMIZEBOX
DD 0 ; style ├®tendu
DW 5 ; nb d'items dans la boîte de dialogue
DW 0 ; position-x du coin sup├®rieur gauche
DW 0 ; position-y du coin sup├®rieur gauche
DW 160 ; largeur de la boîte
DW 104 ; hauteur de la boîte
DW 0 ; table de menu (pas de menu)
DW 0 ; zone de classe (valeur par d├®faut)
DUS 'HelloDialog demonstration', 0 ; titre (DUS impose ├Ā
; l'assembleur de convertir
; la chaîne en Unicode
; comme requis par Windows
DW 10 ; taille de la police de caract├©res en points
DUS 'Microsoft Sans Serif', 0 ; vous pouvez changer la police
; en d├®clarant, par exemple,
; 'Arial' ou 'Times New Roman'.
; *********************************** on constitue une boîte pour le groupe
; Contr├┤le au format DLGITEMTEMPLATE (y compris ceux qui suivent)
ALIGN 4 ; le d├®but doit ├¬tre align├® dword
DD 50000000h + 7h ; (WS_CHILD+WS_VISIBLE)+BS_GROUPBOX
DD 0 ; style ├®tendu
DW 6 ; position-x du coin sup├®rieur gauche du contr├┤le
DW 6 ; position-y du coin sup├®rieur gauche du contr├┤le
DW 148 ; largeur du contr├┤le
DW 90 ; hauteur du contr├┤le
DW 0 ; ID du contr├┤le
DW -1 ; examen du suivant pour la classe
DW 80h ; contr├┤le de type "bouton"
DUS 'Various strings drawn inside dialog', 0
DW 0 ; ├®l├®ments ├Ā envoyer ├Ā DlgProc (0 = aucun)
; *********************************** contr├┤le suivant
ALIGN 4 ; le d├®but doit ├¬tre align├® dword
DD 50000000h ; (WS_CHILD+WS_VISIBLE)
DD 0 ; style ├®tendu
DW 10 ; position-x du coin sup├®rieur gauche du contr├┤le
DW 23 ; position-y du coin sup├®rieur gauche du contr├┤le
DW 140 ; largeur du contr├┤le
DW 10 ; hauteur du contr├┤le
DW 1h ; ID du contr├┤le
DW -1 ; examen du suivant pour la classe
DW 82h ; contr├┤le statique
DUS 'String already in the dialog template', 0
DW 0 ; ├®l├®ments ├Ā envoyer ├Ā DlgProc (0 = aucun)
; *********************************** contr├┤le suivant
ALIGN 4 ; doit ├¬tre align├® dword
CONTROL_2: ; label permettant de modifier dynamiquement le contr├┤le
DD 50000000h ; +0 (WS_CHILD+WS_VISIBLE)
DD 0 ; +4 style ├®tendu
DW 10 ; +8 position-x du coin sup├®rieur gauche du contr├┤le
DW 43 ; +A position-y du coin sup├®rieur gauche du contr├┤le
DW 140 ; +C largeur du contr├┤le
DW 10 ; +E hauteur du contr├┤le
DW 2h ; +10 ID du contr├┤le
DW -1 ; +12 examen du suivant pour la classe
DW 82h ; +14 contr├┤le statique
DW 30 DUP 0 ; +16 espace pour la cha├«ne Unicode termin├®e par z├®ro ├Ā ajouter
DW 0 ; ├®l├®ments ├Ā envoyer ├Ā DlgProc (0 = aucun)
; *********************************** contr├┤le suivant
ALIGN 4 ; doit ├¬tre align├® dword
DD 50000000h ; (WS_CHILD+WS_VISIBLE)
DD 0 ; style ├®tendu
DW 10 ; position-x du coin sup├®rieur gauche du contr├┤le
DW 63 ; position-y du coin sup├®rieur gauche du contr├┤le
DW 140 ; largeur du contr├┤le
DW 10 ; hauteur du contr├┤le
DW 3h ; ID du contr├┤le
DW -1 ; examen du suivant pour la classe
DW 82h ; contr├┤le statique
DW 0 ; cette cha├«ne sera ajout├®e par INITIALISE_DIALOG
DW 0 ; ├®l├®ments ├Ā envoyer ├Ā DlgProc (0 = aucun)
; *********************************** contr├┤le suivant
ALIGN 4 ; doit ├¬tre align├® dword
DD 50000000h ; (WS_CHILD+WS_VISIBLE)
DD 0 ; style ├®tendu
DW 10D ; position-x du coin sup├®rieur gauche du contr├┤le
DW 83 ; position-y du coin sup├®rieur gauche du contr├┤le
DW 140 ; largeur du contr├┤le
DW 10 ; hauteur du contr├┤le
DW 4h ; ID du contr├┤le
DW -1 ; examen du suivant pour la classe
DW 82h ; contr├┤le statique
DW 0 ; cette cha├«ne sera ajout├®e par INITIALISE_DIALOG
DW 0 ; ├®l├®ments ├Ā envoyer ├Ā DlgProc (0 = aucun)
;
ALIGN 4
GOODBYE_MESSAGE DB "Goodbye from the HelloDialog program. We'll see you again.", 0
DYNO_STRING DB 'String inserted dynamically 1', 0 ; 30 caract├©res incluant le z├®ro
;
;*******************************************************************
;* CODE
;*******************************************************************
CODE SECTION
;
; ***************************************************** D├ēBUT DU PROGRAMME
START:
PUSH 0
CALL GetModuleHandleA ; r├®cup├®ration du handle de ce process en EAX
;
; ****************************** Cr├®ation de la bo├«te de dialogue et de ses contr├┤les
CALL INSERT_DYNAMICSTRING
PUSH 0 ; valeur d'initialisation (non utilis├®e)
PUSH ADDR DlgProc ; pointeur vers la proc├®dure de dialogue
PUSH 0 ; ce dialogue a le Bureau comme parent
PUSH ADDR DIALOG_TEMPLATE ; adresse du mod├©le d├®clar├® plus haut
PUSH EAX ; handle pour ce process en provenance de GetModuleHandleA
CALL DialogBoxIndirectParamA ; retour de cette API uniquement ├Ā la cl├┤ture du dialogue
PUSH 0 ; sortie avec le code z├®ro
CALL ExitProcess ; sortie d├®finitive
;
; ******************************************************* PROC├ēDURE DE DIALOGUE
; On utilise ici FRAME..ENDF pour ├®tablir une zone de donn├®es locales et
; de r├®cup├®ration de param├©tres.
;
DlgProc FRAME hDlg, uMsg, wParam, lParam
USES EBX, EDI, ESI ; sauvegarde EBX, EDI et ESI comme requis par Windows
; (par s├®curit├® seulement)
MOV EAX, [uMsg] ; r├®cup├®ration du message dans EAX
CMP EAX, 110h ; est-ce un message WM_INITDIALOG ?
JNZ > ; non, alors saut aux 2 points qui suivent
CALL INITIALISE_DIALOG
MOV EAX, 1
JMP >.return ; retourne EAX <> 0 comme requis par Windows
:
CMP EAX, 111h ; est-ce un message WM_COMMAND ?
JNZ >.false ; non
CMP W[wParam], 2h ; on regarde si sysmenu a ├®t├® cliqu├®
JNZ >.false ; non
; *********************** Oui, alors on dit"goodbye" avec une MessageBox
PUSH 40h ; mode ic├┤ne d'information et bouton Ok
PUSH 'GoodbyeDialog' ; titre
PUSH ADDR GOODBYE_MESSAGE ; texte du corps de la MsgBox
PUSH [hDlg] ; propri├®taire (ce dialogue)
CALL MessageBoxA
;******************************
PUSH 1, [hDlg]
CALL EndDialog ; fin du dialogue
.false
XOR EAX, EAX ; retourne z├®ro comme requis
.return
RET
ENDF
;
; Notez que ce qui suit doit ├¬tre ex├®cut├® avant que DialogBoxIndirectParam
; ne soit appel├®e. Il ne peut ├¬tre r├®alis├® sur le message WM_INITDIALOG
INSERT_DYNAMICSTRING:
; *************** ajout de la chaîne DYNO_STRING au 2e contrôle statique
MOV EDI, ADDR CONTROL_2 ; adresse du contr├┤le statique dans EDI
ADD EDI, 16h ; on fait pointer EDI sur l'adresse de la chaîne du contrôle
MOV ESI, ADDR DYNO_STRING ; on fait pointer ESI sur l'adresse de la chaîne source
XOR EAX, EAX ; EAX = 0
; *************** chargement de la chaîne en la convertissant en Unicode en même temps
; Notez qu'on lit des octets successifs que l'on copie sur des mots successifs
; entraînant de facto la conversion en Unicode puisque, dans tous les cas, AH = 0
L0:
LODSB ; charge AL avec [ESI] et incr├®mente ESI d'une unit├®
STOSW ; copie AX en [EDI] et incr├®mente EDI de 2 unit├®s
OR AL, AL ; on teste AL=0 marquant la fin de la cha├«ne ├Ā copier
JNZ L0 ; non, alors on continue la copie
RET
;
; Sur WM_INITDIALOG vous pouvez faire beaucoup de travail pour ajouter des choses
; ├Ā la bo├«te de dialogue. Par exemple :
INITIALISE_DIALOG:
USEDATA DlgProc ; utilisation des donn├®es locales de la trame DlgProc
PUSH 'String inserted dynamically 2'
PUSH 3h ; identifiant du contr├┤le = 3h
PUSH [hDlg] ; utilisation du handle du dialogue dans les donn├®es locales
CALL SetDlgItemTextA
; ************************** ├®tablissons maintenant le contr├┤le n┬░ 4 d'une mani├©re diff├®rente
PUSH 4h ; identifiant du contr├┤le = 4h
PUSH [hDlg] ; utilisation du handle du dialogue dans les donn├®es locales
CALL GetDlgItem ; r├®cup├®ration du handle du contr├┤le dans EAX
PUSH 'String inserted dynamically 3'
PUSH 0 ; wParam n'est pas utilis├®
PUSH 0Ch ; valeur constante pour le message WM_SETTEXT
PUSH EAX ; handle du contr├┤le issu du GetDlgItem qui pr├®c├©de
CALL SendMessageA ; envoi du message WM_SETTEXT avec la chaîne
RETVIII-A-5. Programme Hello64World1.asm▲
Ce programme est ├®crit en 64 bits pour fonctionner en mode console. Ce mode est d├®clench├® (voir plus loin) au niveau de l'├®dition de liens par l'utilisation du commutateur /console. La seule action de ce programme est d'afficher le message ┬½┬ĀHello 64 World (from GoAsm)┬Ā┬╗ (sur fond jaune dans la figure ci-dessous)┬Ā:
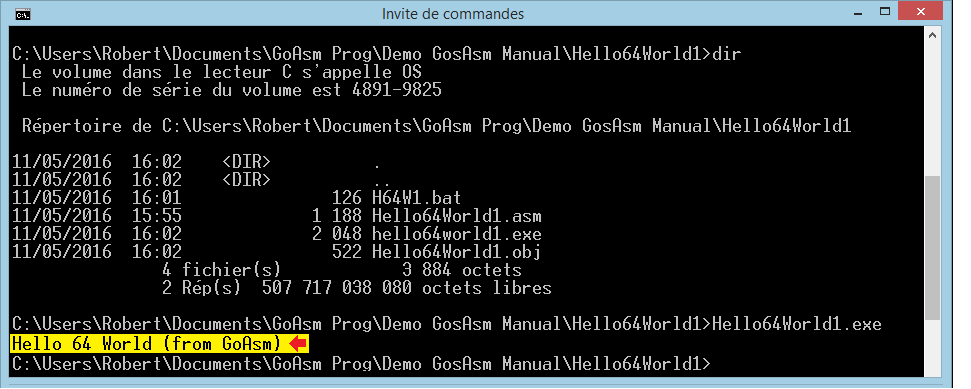
;------------------------------------------------------------------
; Hello64World1 - copyright Jeremy Gordon 2005-6
;
; SIMPLE "HELLO WORLD" WINDOWS CONSOLE PROGRAM - for GoAsm 64-bits
;
; Assemblage & ├ēdition de liens :
; GoAsm /x64 Hello64World1 (produisant un fichier PE COFF)
; GoLink /console [-debug coff] hello64world1.obj kernel32.dll
; qui produit HelloDialog.exe
; -debug coff n'est utilis├® que s'il est souhaitable d'analyser le
; programme dans le d├®bogueur
; Notez que les API GetStdHandle et WriteFile sont fournies par kernel32.dll
;------------------------------------------------------------------
;
DATA SECTION
;
ALIGN 8 ; alignement qword pour les donn├®es qui suivent
RCKEEP DQ 0 ; variable qword ├Ā usage g├®n├®ral
Message DB 'Hello 64 World (from GoAsm)'
;
CODE SECTION
;
START:
ARG -11 ; STD_OUTPUT_HANDLE
INVOKE GetStdHandle ; r├®cup├®ration, dans RAX, du handle du buffer d'├®cran actif
;********************
ARG 0, ADDR RCKEEP ; la variable RCKEEP re├¦oit la sortie de l'API
ARG 27 ; longueur de la chaîne
ARG ADDR Message, RAX ; RAX = handle du buffer d'├®cran actif
INVOKE WriteFile
XOR RAX, RAX ; retour de z├®ro indiquant une ex├®cution normale
RETVIII-A-6. Programme Hello64World2.asm▲
Le programme Hello64World2.asm est la version 64 bits de HelloWorld2 d├®crit plus avant. Il consiste ├Ā dessiner une ellipse dans un rectangle. La figure ci-dessous montre le r├®sultat obtenu sur l'├®cran.
;------------------------------------------------------------------
;
; Hello64World2 - copyright Jeremy Gordon 2005-6
;
; "HELLO WORLD" WINDOWS GDI PROGRAM - for 64 bits
;
; Assemblage & ├ēdition de liens :
; GoAsm /x64 Hello64World2 (produisant un fichier PE COFF)
; GoLink [-debug coff] Hello64World2.obj user32.dll kernel32.dll gdi32.dll
; qui produit HelloDialog.exe
; Notez que GoLink d├®tecte automatiquement le fait qu'il s'agisse d'un fichier
; ├Ā ├®diter en 64 bits
; -debug coff n'est utilis├® que s'il est souhaitable d'analyser le
; programme dans le d├®bogueur
;
;------------------------------------------------------------------
;
; ***************** Structure accueillant les infos de Windows sur WM_PAINT (version 64 bits)
; ***************** pour l'API BeginPaint
PAINTSTRUCT STRUCT
DQ 0 ; +0 hDC
DD 0 ; +8 fErase
left DD 0 ; +C gauche ŌöÉ
top DD 0 ; +10 haut Ōöé RECT (coin sup├®rieur gauche,
right DD 0 ; +14 droite Ōöé puis coin inf├®rieur droit)
bottom DD 0 ; +18 bas Ōöś
DD 0 ; +1C fRestore ŌöÉ
DD 0 ; +20 fIncUpdate Ōöé utilis├®s en interne par le syst├©me
DB 32 DUP 0 ; +24 rgbReserved Ōöś
DD 0 ; bourrage permettant de porter la taille totale
; de la structure ├Ā 72 octets
ENDS
;
DATA SECTION
;
ALIGN 8 ; garantit que tous les ├®l├®ments de donn├®es qui
; suivent sont align├®s sur un pas de 8 octets
hDC DQ 0 ; pour m├®moriser le handle du device context
PS PAINTSTRUCT
; ***************** Structure accueillant les messages pour les API
; ***************** GetMessageA, TranslateMessage et DispatchMessageA
MSG DQ 0 ; +0 hWnd
DD 0 ; +8 message
DD 0 ; bourrage pour retomber sur un pas de 8 octets
wParam DQ 0 ; +10 wParam
DQ 0 ; +18 lParam
DD 0 ; +20 heure ├Ā laquelle le message a ├®t├® post├®
DD 0 ; +24 position du curseur en coordonn├®es d'├®cran (1re partie)
DD 0 ; +28 position du curseur en coordonn├®es d'├®cran (2e partie)
DD 0 ; bourrage permettant de porter la taille totale
; de la structure ├Ā 48 octets
;
; ***************** Structure pour envoyer ├Ā RegisterClass les donn├®es m├®moris├®es
;
WNDCLASS DD 1h+2h+40h ; +0 style de classe de fenêtre (CS_VREDRAW+CS_HREDRAW+CS_CLASSDC)
DD 0 ; +4 octets de comblement
DQ WndProcTable ; +8 pointeur vers la proc├®dure de fen├¬tre
DD 0 ; +10 nb d'octets suppl├®mentaires ├Ā allouer apr├©s la structure
DD 0 ; +14 nb d'octets suppl├®mentaires ├Ā allouer apr├©s l'instance de fen├¬tre
hInst DQ 0 ; +18 handle de l'instance contenant la proc├®dure de fen├¬tre
DQ 0 ; +20 handle de l'ic├┤ne de classe
hCursor DQ 0 ; +28 handle du curseur de classe
DQ 6 ; +30 identifie la brosse de l'arri├©re-plan de la classe (6=COLOR_WINDOW+1)
DQ 0 ; +38 pointeur vers le nom de ressource pour le menu de classe
DQ WINDOW_CLASSNAME ; +40 pointeur vers chaîne contenant le nom de la classe de fenêtre
;
; ******************** Table des messages de fenêtre
; (Dans un v├®ritable programme, cette table concernerait beaucoup plus de messages)
MESSAGES DD (ENDOF_MESSAGES-$-4)/8 ; = nombre de messages ├Ā examiner
DD 1h, CREATE, 2h, DESTROY, 0Fh, PAINT
ENDOF_MESSAGES: ; label utilis├® pour calculer le nombre de messages
;******************************************
;
WINDOW_CLASSNAME DB 'WC', 0 ; chaîne contenant le nom de la classe de fenêtre
;
;------------------------------------------------------------------
;
CODE SECTION
;
;*******************
CREATE: ; l'un des quelques messages trait├®s par ce programme
XOR RAX, RAX ; retourne z├®ro pour fabriquer la fen├¬tre
RET
;
DESTROY: ; l'un des quelques messages trait├®s par ce programme
INVOKE PostQuitMessage, 0 ; sortie via la boucle de message
STC ; aller ├Ā DefWindowProc en plus
RET
;
; Le process qui suit permet de tracer une ellipse dans le rectangle fourni par
; Windows sur le message WM_PAINT. Ce rectangle est la zone qui a besoin d'être
; mise ├Ā jour, par exemple lors d'un redimensionnement ou si la fen├¬tre est
; d├®couverte par une autre.
PAINT:
PUSH RDI, RBX ; sauvegarde des registres non volatils utilis├®s
MOV RDI, RCX ; sauvegarde hWnd pour un usage ult├®rieur
LEA RBX, PS ; r├®cup├®ration de paintstruct dans rbx
ARG RBX ; l'envoyer en tant que param├©tre d'API
ARG RDI ; hWnd
INVOKE BeginPaint ; r├®cup├®ration du device context ├Ā utiliser, initialisation du dessin
MOV [hDC], RAX
; ***************** Utilisation du rectangle envoy├® par le syst├©me dans
; ***************** la structure de PAINTSTRUCT (PS) ..
XOR RAX, RAX
MOV EAX, [PS.bottom]
ARG RAX
MOV EAX, [PS.right]
ARG RAX
MOV EAX, [PS.top]
ARG RAX
MOV EAX, [PS.left]
ARG RAX
ARG [hDC]
INVOKE Ellipse ; dessine l'ellipse dans le rectangle mis ├Ā jour
;*****************
INVOKE EndPaint, RDI, RBX ; RDI = hWnd, RBX = paintstruct
POP RBX, RDI ; restauration des registres non volatils utilis├®s
XOR RAX, RAX ; retourne RAX = 0 et nc (ne pas appeler DefWindowProc)
RET
;
;***************************************************************************
; L'appel au label de code trouv├® dans la table n'est pas destin├® ├Ā CALL [EAX+R10D*8+4] puisque
; tous les calls ├Ā des adresses d├®tenues dans des zones de m├®moire point├®es par des registres
; ou ├Ā des adresses d├®tenues dans des registres eux-m├¬mes sont des appels ├Ā des adresses 64 bits
; en assemblage 64 bits.
; Mais la table ne contient que des adresses 32 bits. Ainsi, nous extrayons plut├┤t l'adresse
; de 32 bits dans la table ├Ā destination de R10D puis nous faisons un Call R10 sachant que
; le dword de poids fort de ce registre est nul.
GENERAL_WNDPROC64: ; uMsg est dans RDX (actuellement EDX)
MOV R10D, [EAX] ; on r├®cup├©re le nombre de messages ├Ā traiter
ADD EAX, 4 ; on saute par-dessus le dword contenant la taille
L2:
DEC R10D
JS >L3 ; message non trouv├® dans la table
CMP [EAX+R10D*8], EDX ; regardons si c'est le message correct
JNZ L2 ; non
; RCX=hwnd, RDX=uMsg, R8=wParam, R9=lParam
PUSH R9, R8, RDX, RCX ; sauvegarde des param├©tres pour DefWindowProcA
MOV R10D, [EAX+R10D*8+4] ; r├®cup├®ration de l'adresse de proc├®dure correspondant au message
CALL R10D
POP RCX, RDX, R8, R9 ; restauration des param├©tres pour DefWindowProcA
JNC >L4 ; nc = valeur de retour dans EAX - pas d'appel de DefWindowProc
L3:
SUB RSP, 20h ; on r├®serve de l'espace sur la pile pour les param├©tres en registres
; comme requis
CALL DefWindowProcA
ADD RSP, 20h ; lib├®ration de cet espace initialement r├®serv├® sur la pile
L4:
RET
;
;***************************************************************************
;
; ******************* Voici la proc├®dure de fen├¬tre courante
WndProcTable:
MOV EAX, ADDR MESSAGES ; EAX pointe la liste des messages ├Ā traiter
CALL GENERAL_WNDPROC64 ; appel du gestionnaire de message g├®n├®rique (version 64 bits)
RET
;
;*******************************************************************
START:
INVOKE GetModuleHandleA, 0 ; r├®cup├®ration du handle du process
MOV [hInst], RAX ; m├®morisation de ce handle dans hInst
INVOKE LoadCursorA, 0, 32512 ; chargement dans EAX, handle de IDC_ARROW (fl├©che de curseur classique)
MOV [hCursor], RAX ; m├®morisation de ce handle dans hCursor (dans WNDCLASS)
; ********** on enregistre maintenant la window class
INVOKE RegisterClassA, ADDR WNDCLASS ; m├®morisation de la window class
; ********** cr├®ation de la fen├¬tre
ARG 0, [hInst], 0, 0 ; propri├®taire = le bureau
ARG 200D ; hauteur
ARG 320D ; largeur
ARG 50D, 50D ; position y puis x
ARG 90000000h+0C00000h+40000h+80000h+20000h+10000h ; (POPUP+VISIBLE)+CAPTION+SIZEBOX+SYSMENU+MINIMIZEBOX+MAXIMIZEBOX
ARG 'Hello 64 World window made by GoAsm' ; titre de la fenêtre
ARG ADDR WINDOW_CLASSNAME ; nom de window class
ARG 0 ; style ├®tendu
INVOKE CreateWindowExA ; fabrication de la fenêtre
; ************************ on entre maintenant la boucle de message principale
L1:
INVOKE GetMessageA, ADDR MSG, 0, 0, 0
OR RAX, RAX ; on regarde si c'est WM_QUIT
JZ >L2 ; oui
INVOKE TranslateMessage, ADDR MSG
INVOKE DispatchMessageA, ADDR MSG
JMP L1 ; apr├©s le msg trait├®, boucle de retour pour un prochain msg
L2: ; cas o├╣ le message ├®tait WM_QUIT
ARG [hInst], ADDR WINDOW_CLASSNAME
INVOKE UnregisterClassA ; on s'assure que la classe est supprim├®e
INVOKE ExitProcess, [wParam] ; wParam= code de sortieVIII-A-7. Programme Hello64World3.asm▲
Le programme Hello64World3.asm a ├®galement la m├¬me fonction que HelloWorld2, HelloWorld3 et Hello64World.asm en ce sens qu'il se borne ├Ā tracer une ellipse dans un rectangle.
Toutefois, le code source est ├®crit de telle sorte qu'il puisse servir indiff├®remment sur les plateformes 32 et 64 bits selon l'utilisation du commutateur /x86 ou /x64 sur la ligne de commande de GoAsm. On sait que l'├®diteur de lien n'a besoin, quant ├Ā lui, d'aucune commande sp├®cifique pour ce faire.
;------------------------------------------------------------------
;
; Hello64World3 - copyright Jeremy Gordon 2005-6
;
; PROGRAM WINDOWS GDI "HELLO WORLD" COMMUTABLE Win32/64
;
; Assemblage :
; GoAsm /x64 Hello64World3 pour un exe 64 bits
; GoAsm /x86 Hello64World3 pour un exe 32 bits
; ├ēdition de liens :
; GoLink [-debug coff] Hello64World3.obj user32.dll kernel32.dll gdi32.dll
; qui produit Hello64World3.exe
; Notez que GoLink d├®tecte automatiquement le fait qu'il s'agit d'un fichier
; ├Ā ├®diter en 32 ou 64 bits
; -debug coff n'est utilis├® que s'il est souhaitable d'analyser le
; programme dans le d├®bogueur
;------------------------------------------------------------------
;
; L'utilisation du commutateur x86 a pour effet que :
; "x86" est un mot d├®fini et identifiable en utilisant #if
; Tous les registres ├®tendus sont remplac├®s par leur homologue 32 bits
; Par exemple,
; RBX devient EBX
; ARG RAX se traduit par PUSH EAX
; ARG ADDR WNDCLASS se traduit par PUSH ADDR WNDCLASS
; ARG 800h se traduit par PUSH 800h
; ARG [hInst] se traduit par PUSH [hInst]
; ARG 'String' ou ARG ADDR 'String' se traduit par PUSH 'String' (push de l'adresse de la chaîne)
; INVOKE fonctionne en STDCALL
; ARG doit être suivi par un INVOKE avant le CALL ou le RET suivants
; FRAME...ENDF fonctionne en Win32
;
; L'utilisation du commutateur x64 a pour effet que :
; "x64" est un mot d├®fini et identifiable en utilisant #if
; ARG RAX (selon sa position) se traduit par MOV RCX ou RDX ou R8 ou R9,RAX ou PUSH RAX
; ARG ADDR WNDCLASS (selon sa position) devient LEA RCX,WNDCLASS
; ou LEA RDX ou R8 ou R9 ou PUSH ADDR WNDCLASS
; ARG 800h se traduit par un MOV RCX ou RDX ou R8 ou R9,800h ou PUSH 800h
; ARG [hInst] se traduit par un MOV RCX ou RDX ou R8 ou R9,[hInst] ou PUSH [hInst]
; ARG 'String' ou ARG ADDR 'String' se traduit par un MOV RCX ou RDX ou R8 ou R9,ADDR 'String'
; PUSH 'String' (met l'adresse de la chaîne dans le registre ou sur la pile)
; INVOKE fonctionne en FASTCALL, offrant un espace r├®serv├® sur la pile pour les registres
; contenant des param├©tres au moyen de SUB RSP,20h avant le CALL et ADD RSP,20h apr├©s.
; il corrige ├®galement la pile pour permettre les param├©tres introduits par PUSH
; il permet ├®galement aux param├©tres de suivre les fonctions appel├®es comme en "C"
; ARG doit être suivi par un INVOKE avant le CALL ou le RET suivants
; FRAME...ENDF fonctionne en Win64
;
;------------------------------------------------------------------
;
RECT STRUCT
left DD ?
top DD ?
right DD ?
bottom DD ?
ENDS
;
; ***************** Structure d├®tenant les infos de Windows sur WM_PAINT (deux versions diff├®rentes)
;
#if x64
PAINTSTRUCT STRUCT ; ===== plateforme 64 bits
hdc DQ ?
fErase DD ?
rcPaint RECT
fRestore DD ?
fIncUpdate DD ?
rgbReserved DB 32 DUP ?
DD 0 ; bourrage pour atteindre une taille totale de 72 octets
ENDS
#else
PAINTSTRUCT STRUCT ; ===== plateforme 32 bits
hdc DD ?
fErase DD ?
rcPaint RECT
fRestore DD ?
fIncUpdate DD ?
rgbReserved DB 32 DUP ?
ENDS
#endif
;
DATA SECTION
;
; ***************** Structure h├®bergeant le message
#if x64 ; ===== cas du 64 bits
ALIGN 8 ; impose un alignement sur un multiple de 8 octets pour la structure
MSG DQ 0 ; +0 hWnd
DD 0 ; +8 message
DD 0 ; bourrage pour pr├®server l'alignement qword pour la suite
wParam DQ 0 ; +10 wParam
DQ 0 ; +18 lParam
DD 0 ; +20 time
DD 0 ; +24 position de la souris (X)
DD 0 ; +28 position de la souris (Y)
DD 0 ; bourrage pour donner ├Ā la structure une taille de 48 octets
#else ; ===== cas du 32 bits
MSG DD 0 ; +0 hWnd
DD 0 ; +4 message
wParam DD 0 ; +8 wParam
DD 0 ; +C lParam
DD 0 ; +10 time
DD 0 ; +14 position de la souris (X)
DD 0 ; +18 position de la souris (Y)
#endif
;
; ***************** Structure ├Ā envoyer ├Ā RegisterClass qui d├®tient les donn├®es
#if x64 ; ===== cas du 64 bits
ALIGN 8 ; impose un alignement sur un multiple de 8 octets pour la structure
WNDCLASS DD 1h+2h+40h ; +0 style de classe de fenêtre (CS_VREDRAW+CS_HREDRAW+CS_CLASSDC)
DD 0 ; bourrage pour retomber sur un alignement qword
DQ WndProc ; +8 pointeur vers la proc├®dure de fen├¬tre
DD 0 ; +10 nb d'octets suppl├®mentaires ├Ā allouer apr├©s la structure
DD 0 ; +14 nb d'octets suppl├®mentaires ├Ā allouer apr├©s window instance
hInst DQ 0 ; +18 handle de l'instance contenant la proc├®dure de fen├¬tre
DQ 0 ; +20 handle de l'ic├┤ne de classe
hCursor DQ 0 ; +28 handle du curseur de classe
DQ 6 ; +30 identifie la brosse d'arri├©re-plan de la classe (6=COLOR_WINDOW+1)
DQ 0 ; +38 pointeur vers nom de ressource pour le menu de classe
DQ WINDOW_CLASSNAME ; +40 pointeur vers la chaîne du nom de classe de fenêtre
#else ; ===== cas du 32 bits
WNDCLASS DD 1h+2h+40h ; +0 style de classe de fenêtre (CS_VREDRAW+CS_HREDRAW+CS_CLASSDC)
DD WndProc ; +4 pointeur vers la proc├®dure de fen├¬tre
DD 0 ; +8 nb d'octets suppl├®mentaires ├Ā allouer apr├©s la structure
DD 0 ; +C nb d'octets suppl├®mentaires ├Ā allouer apr├©s l'instance de fen├¬tre
hInst DD 0 ; +10 handle de l'instance de cette classe de fenêtre
DD 0 ; +14 handle de l'ic├┤ne de classe
hCursor DD 0 ; +18 handle du curseur de classe
DD 6 ; +1C identifie la brosse d'arri├©re-plan de la classe (6=COLOR_WINDOW+1)
DD 0 ; +20 pointeur vers nom de ressource pour le menu de classe
DD WINDOW_CLASSNAME ; +24 pointeur vers la chaîne du nom de classe de fenêtre
#endif
; +++
; ******************** Table des messages Windows
; Cette table permet d'identifier un message (en fait, une valeur binaire sur un dword) et de
; fournir le pointeur appropri├® vers la routine associ├®e. Dans un programme plus ├®labor├®, il y
; aurait beaucoup plus de messages ├Ā traiter que les 3 qui sont propos├®s.
ALIGN 8 ; garantit un alignement sur un multiple de 8 octets pour les call
; (essentiel en 64-bits!)
MESSAGES DD 1h, CREATE ; valeur du message, puis adresse de code 32 bits du label
DD 2h, DESTROY
DD 0Fh, PAINT
;
; ******************************************
;
ALIGN 8 ; garantit un alignement sur un multiple de 8 octets de la chaîne
; (essentiel en 64 bits !!)
WINDOW_CLASSNAME DB 'WC', 0 ; chaîne contenant le nom de classe de fenêtre
;
; ------------------------------------------------------------------
;
CODE SECTION
;
; *******************
CREATE: ; l'un des quelques messages trait├®s par ce programme
XOR RAX, RAX ; retourne z├®ro pour autoriser la construction de la fen├¬tre
RET
;
DESTROY: ; l'un des quelques messages trait├®s par ce programme
INVOKE PostQuitMessage, 0 ; sortie via la boucle de message
STC ; va ├Ā DefWindowProc ├®galement
RET
;
; ======================================= WINDOW PROC ============================================
; **** Ceci est la proc├®dure de fen├¬tre r├®elle qui fonctionne ├Ā la fois pour l'assemblage 32 bits
; et 64 bits. L'appel du label de code trouv├® dans le tableau ne se fait pas par CALL [EDX+ECX*8+4]
; puisque tous les CALLs ├Ā des adresses d├®tenues dans des zones m├®moire point├®es par des registres
; ou ├Ā des adresses d├®tenues dans les registres eux-m├¬mes sont des CALLs ├Ā des adresses 64 bits
; dans l'assembleur 64 bits.
; Mais le tableau ne contient que des adresses 32 bits. Aussi, nous extrayons l'adresse de 32 bits
; du tableau pour la placer en ECX puis nous appelons RCX sachant que le dword de poids fort de
; RCX est nul.
;
WndProc:
FRAME hwnd, uMsg, wParam, lParam ; ├®tablit la trame de pile et obtient les param├©tres
;
MOV EAX, [uMsg] ; met en EAX le message envoy├® par Windows
MOV ECX, SIZEOF MESSAGES/8 ; r├®cup├©re le nombre de messages ├Ā examiner
MOV EDX, ADDR MESSAGES
L2:
DEC ECX
JS >.notfound
CMP [EDX+ECX*8], EAX ; on regarde si c'est le message correct
JNZ L2 ; non
MOV ECX, [EDX+ECX*8+4]
CALL RCX
JNC >.exit
.notfound
INVOKE DefWindowProcA, [hwnd], [uMsg], [wParam] ,[lParam]
.exit
RET
ENDF ; fin de la trame de pile
;
; **** Et maintenant une proc├®dure, en dehors du FRAME, qui doit adresser les param├©tres
; **** stock├®s sur la pile dans le FRAME WndProc
; Elle dessine une ellipse dans le rectangle fourni par Windows sur le message WM_PAINT. Ce
; rectangle est la zone qui a besoin d'├¬tre mise ├Ā jour, par exemple sur le redimensionnement
; ou si la fen├¬tre est d├®couverte par une autre. Le dessin est fait en utilisant le contexte de
; p├®riph├®rique fourni par Windows.
; Nous mettons en place des donn├®es LOCAL ici, sp├®cifiques aux messages Windows
;
PAINT:
USEDATA WndProc ; utilise les param├©tres envoy├®s ├Ā WndProc
USES RBX, RDI, RSI ; sauvegarde les registres tel que requis par Windows
; (pas vraiment n├®cessaire ici)
LOCAL lpPaint:PAINTSTRUCT, hDC ; ├®tablit des donn├®es locales
;
INVOKE BeginPaint, [hwnd], ADDR lpPaint ; r├®cup├©re en EAX/RAX le DC ├Ā utiliser
MOV [hDC], RAX ; on le sauvegarde dans les donn├®es locales
INVOKE Ellipse, [hDC], [lpPaint.rcPaint.left], \
[lpPaint.rcPaint.top] , \
[lpPaint.rcPaint.right], \
[lpPaint.rcPaint.bottom]
;
; d'autres proc├®dures de dessin peuvent ├®ventuellement ├¬tre ├®crites ici
;
INVOKE EndPaint, [hwnd], ADDR lpPaint ; retour du DC ├Ā Windows
XOR RAX, RAX ; retour d'un Carry nul et de RAX = 0
RET
ENDU ; fin de l'utilisation des param├©tres envoy├®s ├Ā WndProc
;
; *******************************************************************
START:
INVOKE GetModuleHandleA, 0 ; r├®cup├®ration du handle du process
MOV [hInst], RAX ; m├®morisation de ce handle dans le label de donn├®e hInst
INVOKE LoadCursorA, 0, 32512 ; r├®cup├®ration en EAX du handle deIDC_ARROW (curseur commun de fl├©che)
MOV [hCursor], RAX ; enregistrement de ce handle au label de donn├®e hCursor (dans WNDCLASS)
;
; ********** enregistrons maintenant la classe de fenêtre
INVOKE RegisterClassA, ADDR WNDCLASS ; enregistrement de la classe de fenêtre
;
; ********** Cr├®ons maintenant la fen├¬tre
ARG 0
ARG [hInst]
ARG 0
ARG 0 ; propri├®taire=desktop
ARG 200D ; hauteur
ARG 320D ; largeur
ARG 50D ; position y
ARG 50D ; position x
ARG 90000000h+0C00000h+40000h+80000h+20000h+10000h ; (POPUP+VISIBLE)+CAPTION+SIZEBOX+SYSMENU+MINIMIZEBOX+MAXIMIZEBOX
ARG 'Hello 64 World window made by GoAsm' ; titre de la fenêtre
ARG ADDR WINDOW_CLASSNAME ; nom de la classe de fenêtre
ARG 0 ; style ├®tendu
INVOKE CreateWindowExA ; construction de la fenêtre
; ******************** Entrons maintenant dans la boucle de message principale
L1:
INVOKE GetMessageA, ADDR MSG, 0, 0, 0
OR RAX, RAX ; on regarde si c'est WM_QUIT
JZ >L2 ; oui
INVOKE TranslateMessage, ADDR MSG
INVOKE DispatchMessageA, ADDR MSG
JMP L1 ; apr├©s un traitement de message, boucle de retour pour un autre message
L2: ; cas o├╣ le message ├®tait WM_QUIT
ARG [hInst]
ARG ADDR WINDOW_CLASSNAME
INVOKE UnregisterClassA ; garantit que la classe est d├®senregistr├®e
INVOKE ExitProcess, [wParam] ; wParam = code de sortieVIII-B. ├ēcriture d'un programme Windows ├®l├®mentaire▲
Avez-vous d├®j├Ā ├®t├® frustr├® par une application qui ne fait pas exactement ce que vous voulez┬Ā? Eh bien, je me propose de vous montrer comment ├®crire vos propres applications et vous affranchir de ces inconv├®nients. C'est gratuit, enrichissant et, qui plus est, amusant┬Ā!
Cela ne peut ├¬tre un cours intensif en ├®criture de programme, et je vais devoir passer beaucoup de choses sous silence. Je vais supposer que vous en savez tr├©s peu sur la programmation informatique et commencer donc par les bases. ├Ć la fin de ce chapitre, vous saurez comment produire votre propre programme ┬½┬ĀBonjour tout le monde┬Ā┬╗. Il vous appartiendra, d├©s lors, de d├®cider si vous voulez aller plus loin dans ce monde fascinant. Dans l'affirmative, vous pourrez lire les autres articles de ce document et faire de m├¬me sur d'autres sites.
Commen├¦ons par le commencement. Un programme contient des instructions ├Ā destination du processeur de l'ordinateur. Celles-ci forment le code du programme. Le processeur ex├®cute les instructions de code une par une, ce qui est la raison pour laquelle le programme est qualifi├® d'ex├®cutable. Lors du chargement du programme, Windows communique au processeur l'adresse de d├®part dans le code c'est-├Ā-dire l'endroit o├╣ l'ex├®cution doit commencer. ├Ć partir de l├Ā, il appartient au programme de porter l'ex├®cution ├Ā l'endroit appropri├® de son code. Je reviendrai sur ce point important plus tard.
De quoi est constitu├® le code┬Ā? Il s'agit d'une s├®rie d'octets caract├®risant les instructions ├Ā ex├®cuter. Chaque instruction met en ┼ōuvre un ou plusieurs octets, chaque combinaison d'entre eux traduisant le plus souvent la tr├©s grande vari├®t├® de modes d'adressage possibles. Lorsque le processeur a identifi├® une instruction, il l'ex├®cute puis examine les octets suivants et ainsi de suite. Mais ce mode s├®quentiel est assez souvent remis en question par des sauts (JMP ou Jcc) ou des appels de sous-programme (CALL). Dans ce cas, le compteur d'instructions est incr├®ment├® (ou d├®cr├®ment├®, selon le cas) d'un nombre d'octets correspondant ├Ā la valeur du saut quitte ├Ā revenir ├Ā une position quitt├®e pr├®c├®demment par un retour (RET).
Eh bien, que font les instructions┬Ā? Entre autres activit├®s, elles d├®placent des nombres ou des caract├©res de registre ├Ā registre, entre registre et espace m├®moire ou entre deux espaces m├®moire. Elles r├®alisent ├®galement des op├®rations arithm├®tiques et logiques entre ces diff├®rentes entit├®s. Parmi ces registres, sept sont d├®volus ├Ā un usage g├®n├®ral et contiennent, chacun, 32 bits de donn├®es. Ce format est nomm├® DWord (litt├®ralement┬Ā: double mot). Chaque bit est activ├® ou d├®sactiv├® (un ou z├®ro, ┬½┬Āmis┬Ā┬╗ ou ┬½┬Ā├Ā z├®ro┬Ā┬╗) ├Ā un moment donn├®. C'est un nombre binaire. En 32 bits, si tous les bits sont activ├®s (tous ├Ā 1), le nombre en d├®cimal est 4┬Ā294┬Ā967┬Ā295 (232-1). Mais les nombres ne sont qu'un des aspects de ces repr├®sentations binaires puisque chaque octet peut ├®galement repr├®senter un caract├©re selon la codification ASCII bien connue.
Apr├©s le code, on trouve g├®n├®ralement la section de donn├®es qui se caract├®rise, comme le code, par une s├®rie d'octets mais avec une finalit├® radicalement diff├®rente. Elle contient des valeurs num├®riques et des messages utilis├®s par la section de code d├®crite pr├®c├®demment. Assez souvent, elle recueille le r├®sultat d'op├®rations effectu├®es par les instructions.
Apr├©s les donn├®es, se situe une assez grande zone libre appel├®e le ┬½┬Ātas┬Ā┬╗ (heap en anglais) qui accueille ├Ā la fois les buffers et les diff├®rentes tables initi├®es par Windows pour le fonctionnement interne du programme.
On trouve enfin une zone de m├®moire un peu particuli├©re qui s'appelle la pile. Ce dispositif re├¦oit toutes les donn├®es transitoires ainsi que les variables locales. Bien qu'incluse dans la m├®moire vive g├®n├®rale de l'ordinateur (RAM), elle se distingue par un mode de gestion in├®dit. Le stockage et le d├®stockage de l'information y est r├®alis├® respectivement par une instruction PUSH (mise en pile) et une instruction POP (retrait de la pile). Ces deux instructions n'ont pas de dispositif d'adressage explicite et fonctionnent par analogie ├Ā une pile d'assiettes, chacune d'entre elles ├®tant repr├®sent├®e par un DWord. Vous mettez une assiette sur la pile (PUSH) et vous la retirez le moment venu (POP). ├ēl├®mentaire. Mais, si l'assiette qui vous est ch├©re est en-dessous d'une autre, il vous faut retirer cette derni├©re avant de pouvoir la retrouver. Cela diff├©re sensiblement d'un stockage dans la section de donn├®es ├Ā une adresse fixe. Cons├®quence imm├®diate de ce mode de fonctionnement┬Ā: ├Ā mesure que l'on charge la pile de donn├®es par des PUSH successifs, l'adresse est d├®cr├®ment├®e. Elle est incr├®ment├®e, en revanche, chaque fois que l'on retire un ├®l├®ment de la pile. Il r├®sulte de cette structure un peu particuli├©re que le sommet de la pile repr├®sente l'adresse extr├¬me la plus haute de votre programme.
La pile est r├®serv├®e par le syst├©me au moment du chargement du programme.
Dans le contexte de Windows l'une des choses les plus importantes que les instructions de code r├®alisent est d'appeler une fonction de fen├¬tre, c'est-├Ā-dire de d├®tourner l'ex├®cution vers cette fonction. Les fonctions Windows sont appel├®es API (litt├®ralement Application Programmer's Interface ou Interface de Programmeur d'Applications). La plupart des autres instructions de code sont utilis├®es pour pr├®parer ces appels et en traiter le r├®sultat.
Ce sont ces appels aux API qui procureront ├Ā vos programmes des fonctionnalit├®s extraordinaires. La possibilit├® d'appeler Windows de cette fa├¦on vous ouvre l'acc├©s ├Ā une vaste gamme de processus qui comprendra l'interaction avec l'utilisateur, l'affichage d'├®cran appropri├®, l'impression, le traitement de fichiers, etc. Toutes ces actions sont effectivement conduites par Windows ├Ā la demande du programme.
VIII-B-1. Le processus de construction▲
Bien, mais comment ├®laborer un ex├®cutable┬Ā? Vous avez besoin pour cela d'outils de d├®veloppement qui sont tous disponibles en t├®l├®chargement ├Ā partir de mon site web. Ce sont des logiciels enti├©rement gratuits et sans date d'expiration. En voici un bref aper├¦u.
- GoAsm - l'assembleur. Ce programme prend en charge votre script source et le convertit en un fichier objet. Vous ├®crivez votre script source sous forme de texte avec votre ├®diteur de texte favori, par exemple le Bloc-Notes Windows (Notepad) ou Wordpad, en vous assurant qu'il enregistre le fichier sans caract├©res de contr├┤le dans le texte. Traditionnellement, l'extension de ce fichier est ┬½┬Ā.asm┬Ā┬╗. Le script source contient les lignes de code incluant les instructions de code et de donn├®es constituant votre programme. Le fichier objet est un fichier sous forme cod├®e qui peut ├¬tre lu par l'├®diteur de liens (ou linker) et qui est utilis├® pour fournir l'ex├®cutable final.
- GoRC - le compilateur de ressources. Ce programme prend en charge - s'il existe - votre script de ressources et le convertit en un fichier res. Le script de ressources est un autre fichier de texte brut, mais qui contient des instructions pour ├®tablir les contr├┤les de Windows pour nos programmes - menus, bo├«tes de dialogue, ic├┤nes, bitmaps et tables de cha├«nes. Traditionnellement, ce fichier re├¦oit l'extension rc. Il est sous forme cod├®e et trait├® comme tel par l'├®diteur de liens.
- GoLink - l'├®diteur de liens. Ce programme prend en charge un ou plusieurs fichiers objet et, s'il y a lieu, un fichier de ressources (res) dans le but de cr├®er l'ex├®cutable final.
- GoBug - le d├®bogueur. Avec cet outil, vous pouvez observer votre programme en train d'ex├®cuter les instructions une par une et voir comment chaque instruction affecte les registres et zones de m├®moire.
Pour r├®sumer, le processus de construction peut ├¬tre repr├®sent├® graphiquement comme suit┬Ā:
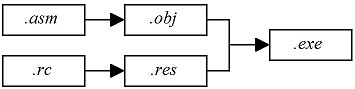
VIII-B-2. Cr├®ation d'un programme Windows ┬½┬Ādo-nothing┬Ā┬╗▲
Nous allons maintenant ├®crire un programme qui se charge, s'ex├®cute et se termineŌĆ” sans rien faire. L'objectif recherch├® ici est de d├®tailler le processus de construction.
| Action | Explication |
| Cr├®ez un nouveau r├®pertoire dans votre lecteur C: appel├® ┬½┬Āprog┬Ā┬╗. | Cela vous aide ├Ā organiser votre travail. Vous pouvez ainsi mettre tout votre travail et les outils de programmation dans ce r├®pertoire ou dans des sous-r├®pertoires cr├®├®s ├Ā cet effet si vous pr├®f├®rez. |
| Copiez GoAsm, GoRC, GoLink et GoBug dans ce r├®pertoire. | |
|
Ensuite, en utilisant votre ├®diteur de texte, cr├®ez un nouveau fichier et saisissez ces lignes┬Ā: CODE SECTION START: RET Enregistrez le fichier ainsi constitu├® dans le r├®pertoire ┬½┬Āprog┬Ā┬╗ et nommez-le ┬½┬ĀNothing.asm┬Ā┬╗. |
Voici l'int├®gralit├® du programme ┬½┬Ādo-nothing┬Ā┬╗. La ligne CODE SECTION indique ├Ā l'assembleur que les lignes qui suivent ne contiennent que des instructions de code ├Ā d├®faut de rencontrer toute autre d├®claration de section. START: est un label de code. Il notifie ├Ā l'├®diteur de liens que c'est ├Ā cet endroit que l'ex├®cution du programme doit commencer. RET est un mn├®monique (instruction processeur exprim├®e en mots explicites) qui signifie au processeur qu'il doit revenir au code appelant qui, dans ce cas, est Windows lui-m├¬me. |
|
Maintenant, en utilisant toujours votre ├®diteur de texte, cr├®ez un nouveau fichier et tapez ces lignes┬Ā: GoAsm Nothing GoLink Nothing.obj /console Pause Enregistrez ce fichier dans le dossier ┬½┬Āprog┬Ā┬╗ en l'appelant ┬½┬Āgonothing.bat┬Ā┬╗. |
Vous cr├®ez un fichier batch qui consiste en un petit fichier tr├©s utile s'ex├®cutant ligne par ligne ├Ā partir de la fen├¬tre MS-DOS (invite de commande). La premi├©re ligne ex├®cute l'assembleur GoAsm, en lui fournissant le fichier Nothing.asm (ici, l'extension asm n'est pas mentionn├®e car consid├®r├®e comme implicite). Cela cr├®e le fichier Nothing.obj qui est ensuite soumis ├Ā GoLink, pour cr├®er le fichier ex├®cutable Nothing.exe. Avec le commutateur /console sur sa ligne de commande, GoLink est par ailleurs invit├® ├Ā cr├®er un programme de console, ce nom indiquant qu'il ne fait pas usage de l'interface utilisateur graphique Windows dans le sens o├╣ il n'utilise pas de fen├¬tres. Enfin, la derni├©re ligne Pause permet de suspendre l'ex├®cution du fichier batch le temps, pour l'utilisateur, de d├®couvrir le compte-rendu d'ex├®cution des lignes qui pr├®c├©dent sur l'├®cran. |
| Allez dans le menu ┬½┬ĀD├®marrer┬Ā┬╗, ┬½┬ĀProgrammes┬Ā┬╗, puis cliquez sur ┬½┬ĀMS-DOS┬Ā┬╗ (noter que la position de cette commande peut diff├®rer selon les ordinateurs, par exemple, dans XP, on trouve ┬½┬ĀD├®marrer┬Ā┬╗, ┬½┬ĀTous les programmes┬Ā┬╗, ┬½┬ĀAccessoires┬Ā┬╗, ┬½┬ĀInvite de commande┬Ā┬╗). Maintenant, vous devriez voir ce que l'on appelle le ┬½┬ĀC:\>┬Ā┬╗ d'invite dans la fen├¬tre MS-DOS (invite de commande). Tapez ┬½┬Ācd prog┬Ā┬╗ puis Entr├®e. | Si vous n'├¬tes pas habitu├® aux commandes DOS, ces man┼ōuvres resteront un myst├©re pour vous. Mais disons ici, pour simplifier, que vous changez le r├®pertoire en cours dans la fen├¬tre MS-DOS (invite de commande) en ┬½┬Āc:\prog┬Ā┬╗, qui est le r├®pertoire dans lequel votre travail de programmation r├®side. |
| Tapez ┬½┬Āgonothing┬Ā┬╗ puis Entr├®e. |
Ici, vous ex├®cutez le fichier batch gonothing.bat. Il l'ex├®cutera ligne par ligne et vous pourrez voir ce qui se passe dans la fen├¬tre MS-DOS (invite de commande). Vous verrez les fichiers Nothing.obj et Nothing.exe successivement cr├®├®s par GoAsm puis GoLink. Si vous pr├®f├®rez, vous pouvez obtenir le m├¬me r├®sultat en double-cliquant tout simplement sur le fichier batch dans l'Explorateur Windows. |
| Finalement, tapez ┬½┬ĀNothing┬Ā┬╗ puis Entr├®e. | Pour terminer, vous ex├®cutez le fichier ex├®cutable Nothing.exe que vous venez de cr├®er pr├®c├®demment. Constatez, en tout cas, qu'il ne fait r├®ellementŌĆ” rien. L'invite DOS va simplement se d├®placer d'une ligne vers le bas. Mais Windows a ├®t├® tr├©s heureux avec ce programme - f├®licitations, vous venez de faire votre premier programme Windows┬Ā! |
VIII-B-3. Cr├®ation d'un programme de console ┬½┬ĀHello World┬Ā┬╗▲
Nous allons ├®crire un programme qui se charge ├Ā partir du prompt MS-DOS (commande) et affiche ┬½┬ĀHello World┬Ā┬╗ ├Ā l'├®cran. Il s'agit d'une version identique mais notablement plus comment├®e de HelloWorld1.asm d├®crit en annexe A. Son but essentiel est de d├®crire l'appel d'une API Windows. Ce type de programme est appel├® programme de console, car il ne produit pas de fen├¬tre, et par cons├®quent ne fait aucun usage de l'interface utilisateur graphique (connue sous le nom ┬½┬ĀGUI┬Ā┬╗).
Le processus est le m├¬me que pr├®c├®demment sauf que, cette fois, vous allez nommer le script source HelloWorld.asm, et le fichier batch, GoHello1.bat. N'oubliez pas de changer les instructions ├Ā destination de l'assembleur et de l'├®diteur de liens dans le fichier batch de sorte qu'ils traitent les bons fichiers.
| Action | Explication |
|
Cr├®ez un nouveau fichier et tapez ces lignes┬Ā: DATA SECTION RCKEEP DD 0 |
La ligne DATA SECTION indique ├Ā l'assembleur que les instructions qui suivent sont des d├®clarations de donn├®es. RCKEEP est un label de donn├®e, autrement dit un nom indiquant un emplacement particulier dans les donn├®es. DD cr├®e un DWord (quatre octets) dans les donn├®es (litt├®ralement ┬½┬ĀD├®clare-DWord┬Ā┬╗). 0 initialise le DWord ├Ā la valeur z├®ro, dans ce cas. |
|
Ajoutons maintenant ces quatre lignes┬Ā: CODE SECTION START: PUSH -11 CALL GetStdHandle |
CODE SECTION indique ├Ā l'assembleur que les lignes qui suivent sont des instructions de code. PUSH met une valeur sur la pile. Celle-ci, dans notre cas, est -11 (exprim├®e en valeur d├®cimale sign├®e). Cette instruction est le seul param├©tre ├Ā pousser en pile dans le cadre de l'appel de l'API GetStdHandle. Cette valeur est donn├®e par Microsoft et correspond ├Ā l'activation du buffer d'├®cran de la console active. Cette console est l'interface avec l'utilisateur, qui dans ce cas sera la fen├¬tre MS-DOS (├®galement connue sous le nom d'┬½┬Āinvite de commande┬Ā┬╗). Le CALL transf├©re le param├©tre ├Ā une proc├®dure, dans ce cas ├Ā l'API Windows GetStdHandle. Cette API re├¦oit ce param├©tre et renvoie, en retour, un handle dans le registre EAX qui permettra d'├®crire dans la fen├¬tre via une autre API. |
|
Maintenant, ces quatre autres lignes┬Ā: PUSH 0, ADDR RCKEEP PUSH 24D, 'Hello World (from GoAsm)' PUSH EAX CALL WriteFile |
Ici, nous poussons en pile les cinq param├©tres n├®cessaires ├Ā l'appel de l'API Windows WriteFile avant d'appeler cette derni├©re. WriteFile ├®crit dans le handle qui lui est pass├® dans le dernier param├©tre (toujours d├®tenu par le registre EAX). Concr├©tement, elle ├®crit la cha├«ne qui est de 24 caract├©res. Nous donnons ├®galement l'adresse de RCKEEP qui est le DWord de donn├®es d├®clar├® plus t├┤t. Ceci est n├®cessaire car la fonction WriteFile r├®percutera dans ce dword le nombre de caract├©res qu'elle a effectivement ├®crits. |
|
Et enfin, ces deux lignes en guise de conclusion┬Ā: MOV EAX,0 RET |
Ici, nous passons la valeur 0 dans le registre EAX pour notifier une fin de programme r├®ussie et utilisons ensuite RET pour retourner au syst├©me (fermeture du programme). |
|
Maintenant, vous pouvez assembler ce fichier et en proc├®der ├Ā l'├®dition des liens, en utilisant les m├¬mes techniques que pr├®c├®demment, mais avec un l├®ger changement. Votre fichier batch s'├®crira d├®sormais┬Ā: GoAsm HelloWorld1 GoLink HelloWorld1.obj /console kernel32.dll Ici, au-del├Ā des diff├®rents noms de fichiers dont la pr├®sence va de soi, vous avez inclus ┬½┬Ākernel32.dll┬Ā┬╗ dans la ligne de commande de GoLink. Cet insert commande ├Ā GoLink d'explorer le fichier syst├©me de Windows kernel32.dll lors de la l'├®dition de liens du fichier pour toutes les ┬½┬Āinconnues┬Ā┬╗, et notamment, les API Windows GetStdHandle et WriteFile qui sont indispensables ├Ā l'ex├®cution du programme. Enfin, l'ex├®cution de ce dernier se traduira par l'affichage de la cha├«ne ┬½┬ĀHello World┬Ā┬╗ en regard de l'invite de commande de la fen├¬tre MS-DOS. |
|
Vous savez maintenant comment cr├®er un programme simple en utilisant l'assembleur et le syst├©me d'exploitation Windows.
Je vous sugg├©re de lire ├®galement avec attention la plupart des annexes qui suivent et notamment┬Ā:
- Annexe C - Pour les d├®butantsŌĆ” en programmation
- Annexe D - Repr├®sentations binaires
- Annexe E - Pour les d├®butantsŌĆ” en langage assembleur
- Annexe F - Flags, sauts conditionnels, CMOVcc et SETcc
- Annexe G - Pour les d├®butantsŌĆ” en Windows
- Annexe H - Pour les d├®butantsŌĆ” en d├®bogage symbolique
- Annexe I - ComprendreŌĆ” la pile (prioritairement la partie n┬░ 1)
- Annexe J - ComprendreŌĆ” la m├®morisation invers├®e
Je vous recommande enfin de porter une attention particuli├©re aux scripts sources comment├®s de la s├®rie Hello World de l'annexe A. Ensuite, vous pouvez passer aux sujets relevant du niveau interm├®diaire et vous confronter ├Ā l'ensemble du pr├®sent manuel.
VIII-C. Pour les d├®butantsŌĆ” en programmation▲
L'une des choses les plus obscures au commun des mortels est d'appr├®hender l'├®criture et la cr├®ation d'un programme que l'ordinateur soit en mesure d'ex├®cuter. Dans l'annexe ├®criture d'un programme Windows ├®l├®mentaire qui pr├®c├©de, nous avons lev├® une partie du myst├©re ├Ā ce sujet et vu notamment ├Ā quel point cet objectif ├®tait relativement simple ├Ā tenir, en particulier avec les outils de d├®veloppement de l'assembleur. Mais ce n'├®tait qu'un aper├¦u. Nous allons nous attacher, maintenant, ├Ā d├®crire le processus de construction des programmes et ├Ā examiner les fichiers impliqu├®s de mani├©re plus d├®taill├®e.
VIII-C-1. Construction d'un programme▲
Le process de programmation Windows utilisant l'assembleur SANS ressources est┬Ā:
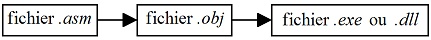
Le process de programmation Windows utilisant l'assembleur AVEC ressources est┬Ā:

Les ressources sont archiv├®es et trait├®es s├®par├®ment dans le but d'accro├«tre la facilit├® de programmation, et d├®tiennent principalement le contenu des menus et des dialogues, mais aussi des composants tels que des bitmaps, des curseurs et des ic├┤nes. Normalement, un programme de console ne contient pas de ressources car il ne fait aucune utilisation des capacit├®s graphiques de Windows. En revanche, un programme qui recourt ├Ā l'interface graphique Windows GUI (┬½┬ĀGraphics User Interface┬Ā┬╗) utilisera assez souvent les ressources bien que cela ne soit absolument pas n├®cessaire.
VIII-C-1-a. Le fichier .asm▲
Le fichier ASM est un fichier que vous cr├®ez et ├®ditez en utilisant un ├®diteur de texte ordinaire, comme Paws que vous pouvez t├®l├®charger ├Ā partir de mon site web, www.GoDevTool.com, ou de programmes comme Notepad (Bloc-notes) ou Wordpad qui sont livr├®s avec Windows. Si vous utilisez ces deux derniers, vous devez vous assurer que vous enregistrez le fichier dans un format qui n'ajoute pas de caract├©res de contr├┤le ou de formatage autres que l'habituelle fin de ligne (retour chariot et saut de ligne). Ceci, parce GoAsm ne s'int├®resse qu'au texte brut. Vous pouvez vous pr├®munir contre ces caract├©res non d├®sir├®s en sauvegardant le fichier comme document ┬½┬Ātexte┬Ā┬╗. Si vous n'adjoignez pas une extension au nom de fichier (l'extension d├®signe les caract├©res apr├©s le point), alors l'├®diteur peut lui attribuer automatiquement une extension ┬½┬Ā.txt┬Ā┬╗. Cependant, rien ne vous emp├¬che de la changer en renommant le fichier (vous pouvez ex├®cuter cette op├®ration sur l'Explorateur Windows en pratiquant un clic droit sur le nom et en s├®lectionnant la fonction ┬½┬ĀRenommer┬Ā┬╗).
Il se peut que vous ne puissiez visualiser l'extension du fichier sur votre ordinateur. Il s'agit, en ce cas, d'une question de param├®trage de l'Explorateur Windows. Pour ce faire, s├®lectionnez l'├®l├®ment de menu ┬½┬ĀAffichage┬Ā┬╗, ┬½┬ĀOptions┬Ā┬╗, ┬½┬ĀModifiez les options des dossiers et de recherche┬Ā┬╗ puis sur l'onglet ┬½┬ĀAffichage┬Ā┬╗ et, enfin, veillez ├Ā ce que la case ┬½┬ĀMasquer les extensions des fichiers dont le type est connu┬Ā┬╗ soit d├®coch├®e. La proc├®dure peut diff├®rer l├®g├©rement selon la version de Windows.
Il est de tradition chez les programmeurs d'attribuer ├Ā leurs scripts source une extension qui corresponde au langage dans lequel il est ├®crit. Par exemple, vous pourriez avoir un fichier assembleur appel├® ┬½┬Āmyprog.asm┬Ā┬╗. De la m├¬me mani├©re, vous trouverez g├®n├®ralement le code source ├®crit en langage ┬½┬ĀC┬Ā┬╗ avec l'extension ┬½┬Ā.c┬Ā┬╗ ou ┬½┬Ā.cpp┬Ā┬╗ (pour ┬½┬ĀC ++┬Ā┬╗), ┬½┬Ā.pas┬Ā┬╗ pour Pascal et ainsi de suite. Cependant, ces extensions sont totalement neutres d'un point de vue strictement informatique. GoAsm accepte ainsi les fichiers de toute extension de m├¬me que les fichiers qui en sont d├®pourvus.
Le fichier .asm contient vos instructions pour le processeur en mots et nombres. Celles-ci sont converties en code ex├®cutable successivement par l'assembleur puis par l'├®diteur de liens. C'est ce code qui sera reconnu et ex├®cut├® par le processeur. On dit donc que le fichier .asm contient votre ┬½┬Ācode source┬Ā┬╗ ou votre ┬½┬Āscript┬Ā┬╗.
Lorsque votre programme est pr├¬t, vous passez le fichier .asm ├Ā l'Assembleur qui est un programme qui convertit les fichiers .asm en fichiers.obj. Vous pouvez utiliser, par exemple, mon assembleur GoAsm.
VIII-C-1-b. Le fichier .obj▲
C'est le fichier constitu├® par l'assembleur ├Ā partir d'un fichier .asm. L'assembleur prend les instructions dans le fichier .asm qui sont dans les mots et les nombres et les convertit dans le format d'objet COFF qui est le format attendu par l'├®diteur de liens. L'assembleur concat├©ne toutes vos instructions de code et de donn├®es dans le script source et les organise en sections de code et de donn├®es dans le fichier .obj. La section de code contient les instructions r├®elles de processeurs (┬½┬Āopcodes┬Ā┬╗) que le processeur ex├®cute lorsque le programme est lanc├®. La section data contient des informations qui seront conserv├®es en m├®moire pendant que le programme est ex├®cut├®.
Vous ne pouvez pas r├®ellement ex├®cuter un fichier .obj en tant que programme car il n'est pas dans le format final de programme attendu par Windows (le format PE). Pour y parvenir, vous devez soumettre le fichier .obj ├Ā l'├®diteur de liens (ou linker) d├©s lors que vous ├¬tes pr├¬t ├Ā finaliser votre programme. Parfois, le fichier .obj est qualifi├® de fichier ┬½┬Ābinaire┬Ā┬╗ ou ┬½┬Ābin┬Ā┬╗ dans un souci de simplification. En effet, le fichier peut bien ├¬tre consid├®r├® comme ne contenant maintenant que des chiffres. Mais si vous regardez ├Ā l'int├®rieur d'un fichier .obj vous y verrez toujours les cha├«nes de caract├©res qui ├®taient dans votre script source.
VIII-C-1-c. Le fichier .rc▲
Il s'agit ici d'un autre type fichier texte que vous constituez en utilisant un ├®diteur de texte. Ce fichier rassemble des instructions d'un format sp├®cifique sous forme de mots et de chiffres que Windows utilise pour constituer les ressources de votre programme lorsqu'il est ex├®cut├®. Entrent notamment dans cette cat├®gorie la plupart des menus, bo├«tes de dialogue et tables de cha├«nes. Vous pouvez ├®galement utiliser le fichier .rc pour nommer les fichiers qui doivent ├¬tre charg├®s dans le fichier .res lorsque le compilateur de ressources est ex├®cut├® (par exemple, des ic├┤nes et des curseurs bitmaps). Par cons├®quent, le fichier .rc peut correctement ├¬tre d├®crit comme contenant de la mati├©re source. Vous pouvez trouver plus d'informations sur les ressources dans le chapitre consacr├® ├Ā mon compilateur de ressources GoRC dans le volume 2.
VIII-C-1-d. Le fichier .res▲
Ce fichier est produit par le compilateur de ressources GoRC ├Ā partir d'un fichier .rc. Le compilateur de ressources formate les instructions dans le fichier .rc qui sont sous forme de mots et de nombres et les convertit en une forme pr├¬te pour l'insertion dans la section de ressources dans le fichier .exe final. Vous passez le fichier .res dans l'├®diteur de liens lorsque vous ├¬tes pr├¬t ├Ā finaliser votre programme.
VIII-C-1-e. Le fichier .exe▲
C'est le fichier ex├®cutable final qui peut ├¬tre ex├®cut├® en tant que programme par Windows. Il est dans le format Portable Executable (PE). Il est constitu├® par l'├®diteur de liens qui traite un ou plusieurs fichiers .obj et, ├®ventuellement, un fichier .res et les combine dans le fichier .exe final. Le format PE exige ├®galement que le fichier .exe ait un en-t├¬te avec des informations sur le fichier .exe. L'├®diteur de liens fournit cette information. Pour ├®laborer les programmes Windows, vous aurez besoin d'utiliser d'un ├®diteur de liens capable de faire des fichiers PE par exemple GoLink d├®crit dans le volume 2.
VIII-C-1-f. Le fichier .dll▲
Il contient d'autres fonctions et donn├®es que votre fichier .exe peut utiliser quand il est en cours d'ex├®cution. La plupart du temps vous n'aurez absolument pas besoin d'utiliser un fichier .dll. Toutefois, un tel fichier peut se r├®v├®ler utile s'il contient des fonctions qui doivent ├¬tre appel├®es par plus d'un fichier .exe. Au lieu de dupliquer le m├¬me code dans deux fichiers .exe, vous pouvez ne l'avoir qu'une seule fois dans un fichier .dll. Windows utilise les fichiers .dll ├Ā grande ├®chelle pour fournir aux applications Windows un acc├©s aux API. Prenez le temps de consulter le r├®pertoire Windows\system dans votre ordinateur - c'est l├Ā que les DLL de Windows sont normalement entrepos├®es.
├Ć noter enfin que le volume 2 propose un chapitre d├®taill├® sur le sujet.
VIII-C-2. Organisation de votre travail de programmation▲
Voici quelques suggestions concernant l'organisation de votre travail de programmation. Il existe d'autres moyens, y compris l'utilisation d'un IDE (Integrated Development Environment) pour ex├®cuter les diff├®rents outils au mieux de vos int├®r├¬ts. Mais si vous d├®butez, vous trouverez probablement plus facile de vous rallier, dans un premier temps, aux suggestions qui vont suivre, quitte ├Ā en changer au fur et ├Ā mesure de l'├®volution de vos besoins et de vos id├®es.
Cela n├®cessite un effort de mise en place, mais une fois ce dernier accompli vous aurez en main une formule souple qui pourra ├¬tre utilis├®e ├Ā maintes reprises et facilement modifi├®e selon les besoins.
Tout d'abord, il convient d'entreposer tous les travaux de programmation et les fichiers correspondants sur le disque dur dans un dossier sp├®cifique qui pourrait se nommer PROG. Bref, d'un nom, qui permette de le s├®parer des autres travaux sur votre ordinateur.
Ensuite, concernant le d├®marrage d'un nouveau projet, je vous sugg├©re de cr├®er un nouveau sous-dossier de ce projet dans l'explorateur Windows. Conservez-y les fichiers source du projet ainsi que tous les fichiers cr├®├®s ├Ā partir de ces fichiers source dans le sous-dossier. Donc tous les fichiers.asm, .rc, .obj, .res et .exe relatifs au projet devront y prendre place.
Entreposez l'assembleur, le compilateur de ressources et l'├®diteur de liens dans un autre sous-dossier dans le dossier PROG.
Ainsi, si votre projet est appel├® ┬½┬ĀMyprog┬Ā┬╗, vos fichiers seront organis├®s comme suit┬Ā:
- dans le r├®pertoire c:\prog\myprog - Myprog.asm, Myprog.rc, Myprog.obj, Myprog.res et Myprog.exe┬Ā;
- dans le r├®pertoire c:\prog\utils - GoAsm.exe (l'assembleur), GoRC.exe (le compilateur de ressources) et GoLink.exe (l'├®diteur de liens).
Ensuite, vous devez concevoir deux fichiers batch qui automatisent l'assemblage, la compilation et le processus d'├®dition de liens. Un fichier batch est un fichier texte ordinaire avec l'extension ┬½┬Ā.bat┬Ā┬╗. Quand un tel fichier est ex├®cut├® ├Ā partir d'une ligne de commande MS-DOS (┬½┬Āinvite de commande┬Ā┬╗), il ex├®cute chaque ligne l'une apr├©s l'autre, comme si chacune avait ├®t├® tap├®e s├®par├®ment sur la ligne de commande. Les fichiers batch doivent ├¬tre ├®crits en utilisant l'├®diteur de texte et ├¬tre entrepos├®s dans le r├®pertoire c:\prog\myprog. Outre les d├®tails mentionn├®s ci-apr├©s, on trouvera en annexe M un aper├¦u aussi complet que possible de ces fichiers.
Si vous mettez en ┼ōuvre des ressources, le premier fichier batch pourra ├¬tre appel├® ┬½┬ĀGorc.bat┬Ā┬╗ et aura la t├óche de lancer le compilateur de ressources afin que le fichier Myprog.rc soit converti en Myprog.res. Dans ce cas, il y aura une seule ligne dans le fichier de commandes libell├®e comme suit┬Ā:
c:\prog\utils\GoRC /r Myprog.rcSi vous utilisez ce fichier et tapez ┬½┬ĀGorc┬Ā┬╗ puis Entr├®e ├Ā partir de la ligne de commande, ce sera comme si la ligne de commande compl├©te avait ├®t├® saisie manuellement.
Le fichier batch principal peut ├¬tre appel├® ┬½┬ĀGo.bat┬Ā┬╗. Il d├®clenche l'assemblage de Myprog.asm puis confie le fichier .obj r├®sultant et le fichier .res ├Ā l'├®diteur de liens qui convertit le tout en un fichier .exe. Dans ce cas, le fichier batch comportera deux lignes┬Ā:
c:\prog\utils\GoAsm Myprog.asm
c:\prog\utils\GoLink @command.filLa premi├©re ligne initie l'assemblage qui se traduit par la cr├®ation du fichier Myprog.obj.
La deuxi├©me ligne active l'├®diteur de liens. Vous pouvez voir que nous utilisons ici un fichier nomm├® ┬½┬Ācommand.fil┬Ā┬╗. Un tel fichier contient des instructions ├Ā destination de l'├®diteur de liens. L'utilisation d'un fichier de commandes facilite le changement ├®ventuel des param├©tres pass├®s ├Ā l'├®diteur de liens. Vous constituez ce fichier en utilisant l'├®diteur de texte. Encore une fois, il devra ├¬tre dans le r├®pertoire ┬½┬Āc:\prog\myprog┬Ā┬╗.
Le fichier de commandes peut contenir, par exemple, les lignes suivantes┬Ā:
/debug coff
Myprog.obj
Myprog.res
Kernel32.dllLa premi├©re ligne est le commutateur /debug coff qui demande ├Ā l'├®diteur de liens d'inclure les symboles dans l'ex├®cutable final. Cela vous permettra notamment d'utiliser ult├®rieurement le d├®bogueur symbolique GoBug. Les deux lignes suivantes nomment les fichiers d'entr├®e, dans ce cas, le fichier objet puis le fichier .res contenant les ressources (omettre la ligne .res si vous n'utilisez aucune ressource). La derni├©re ligne invite l'├®diteur de liens ├Ā explorer le fichier syst├©me Kernel32.dll pour y identifier les appels d'API effectu├®s dans le programme. Il se pourrait que votre programme effectue des appels en direction d'API localis├®es dans d'autres DLL syst├©me. Si tel est le cas, il est imp├®ratif que les DLL concern├®es soient nomm├®es. Vous pouvez identifier celles-ci dans l'information sur Windows contenue dans le Software Development Kit, ou dans les fichiers d'en-t├¬te de Windows. Habituellement, la plupart des appels d'API dont vous aurez besoin sont contenus dans une ou plusieurs des DLL suivantes (en plus de Kernel32.dll), qui devront, dans ce cas, ├¬tre mentionn├®es dans le fichier de commandes┬Ā:
user32.dll
gdi32.dll
COMCTL32.dll
COMDLG32.dll
OLEAUT32.dll
Winspool.drv
Hhctrl.ocxL'├®diteur de liens peut fonctionner plus rapidement si vous pouvez r├®duire la liste des DLL.
Note┬Ā: les travaux ci-dessus concernent exclusivement GoLink. Avec d'autres ├®diteurs de liens, vous serez contraints d'utiliser des fichiers ┬½┬Ālib┬Ā┬╗ pour identifier la DLL pertinente. Si les fichiers lib ne sont pas disponibles, vous devez les constituer ├Ā partir de la DLL au moyen d'un outil sp├®cial.
VIII-C-3. Lancement de l'Assembleur, du Compilateur de Ressources et de l'├ēditeur de liens▲
Il existe deux fa├¦ons d'ex├®cuter les fichiers batch que vous avez cr├®├®s┬Ā:
1. La premi├©re est de double-cliquer sur l'ic├┤ne de fichier appropri├®e dans l'Explorateur Windows (qui ouvre automatiquement une fen├¬tre de console pour donner les r├®sultats)┬Ā;
2. La seconde est d'ouvrir vous-m├¬me une fen├¬tre MS-DOS (invite de commande) et d'ex├®cuter les fichiers ├Ā partir de l├Ā. Pour ce faire, cliquez sur D├®marrer, Programmes, invite MS-DOS. Dans XP c'est ┬½┬ĀD├®marrer┬Ā┬╗, ┬½┬ĀTous les programmes┬Ā┬╗, ┬½┬ĀAccessoires┬Ā┬╗, ┬½┬ĀInvite de commande┬Ā┬╗. Vous verrez alors probablement l'invite ┬½┬ĀC:\WINDOWS>┬Ā┬╗. Cela signifie que le r├®pertoire actif est le dossier ┬½┬ĀWindows┬Ā┬╗ dans le lecteur C:. Modifiez ce r├®pertoire en tapant ┬½┬Ācd c:\prog\myprog┬Ā┬╗ puis en validant avec la touche Entr├®e. L'invite doit maintenant afficher ┬½┬ĀC:\prog\myprog>┬Ā┬╗. Pour la suite, on suppose que vos fichiers source sont en ordre que vous ├¬tes maintenant pr├¬t ├Ā ex├®cuter les fichiers batch. ┬½┬ĀGorc┬Ā┬╗ lancera le compilateur de ressources (si vous l'utilisez), ┬½┬ĀGo┬Ā┬╗ assemblera et proc├©dera ├Ā l'├®dition de liens du programme. Enfin ┬½┬ĀMyprog┬Ā┬╗ va ex├®cuter le fichier EXE.
- Voir le chapitre consacr├® au compilateur de ressources GoRC dans le volume 2 pour voir comment faire un fichier RC.
- Voir, dans le pr├®sent volume 1, comment ├®laborer un fichier de travail .asm.
- Voir le chapitre consacr├® ├Ā l'├®diteur de liens GoLink dans le volume 2 pour plus de pr├®cisions sur son utilisation.
- Enfin, il existe plusieurs exemples de fichiers sur mon site que vous pouvez consulter et utiliser, en particulier les fichiers HelloWorld (├®galement en Annexe A de ce document) et les fichiers d'aide de Testbug.
VIII-D. Repr├®sentations binaires▲
VIII-D-1. Syst├©mes de num├®ration▲
Un syst├©me de num├®ration est un ensemble de symboles permettant de repr├®senter des nombres. Le syst├©me d├®cimal que nous connaissons bien utilise 10 symboles (ou chiffres)┬Ā: 0, 1, 2, 3, 4, 5, 6, 7, 8 et 9. Mais il est possible d'en imaginer d'autres tels que, par exemple, le binaire, l'octal, l'hexad├®cimal, etc.
Pour cela, chaque syst├©me de num├®ration poss├©de une base b ├Ā partir de laquelle il est possible d'├®crire tous les nombres sous la forme suivante┬Ā:
Valeur d├®cimale = a n ├Ś bn + an-1 ├Ś bn-1 + ┬Ę┬Ę┬Ę + a1 ├Ś b1 + a0 ├Ś b0
Dans laquelle b = base (10 pour d├®cimal, 2 pour binaire, 8 pour octal, 16 pour hexad├®cimal)
0 Ōēż an < b
Partant de l├Ā┬Ā:
- le nombre d├®cimal 193 s'├®crit┬Ā: (1 ├Ś 102) + (9 ├Ś 101) + (3 ├Ś 100) = 193┬Ā;
- le nombre binaire 1101 s'├®crit┬Ā: (1 ├Ś 23) + (1 ├Ś 22) + (0 ├Ś 21) + (1 ├Ś 20) = 13┬Ā;
- le nombre hexad├®cimal A57C s'├®crit┬Ā: (10 ├Ś 163) + (5 ├Ś 162) + (7 ├Ś 161) + (12 ├Ś 160) = 42┬Ā364.
VIII-D-2. Bits et repr├®sentation binaire▲
Un bit est un ├®l├®ment ├®lectrique d'une puce ├®lectronique de l'ordinateur qui peut ├¬tre soit ┬½┬Āon┬Ā┬╗ ou ┬½┬Āoff┬Ā┬╗. En termes de physique, nous avons affaire ├Ā une jonction de semi-conducteurs qui est en mesure soit de produire une tension ├®lectrique quand elle est ┬½┬Āon┬Ā┬╗, soit de ne pas en produire du tout lorsqu'elle est ┬½┬Āoff┬Ā┬╗. ├Ć l'├®tat ┬½┬Āon┬Ā┬╗, elle est consid├®r├®e comme ayant la valeur 1. En langage informatique, on dit alors que le bit est ┬½┬Āmis┬Ā┬╗ (traduction de ┬½┬Āset┬Ā┬╗). Quand elle est ┬½┬Āoff┬Ā┬╗, elle est consid├®r├®e comme ayant la valeur z├®ro. En langage informatique le bit est donc mis ├Ā z├®ro (┬½┬Ācleared┬Ā┬╗). Les bits peuvent ├¬tre mis (├Ā 1) ou ├Ā z├®ro (0) mais ne peuvent avoir d'autre ├®tat. La pr├®sence de deux ├®tats sugg├©re, bien ├®videmment, une repr├®sentation limit├®e ├Ā deux symboles (0 et 1), d'o├╣ le recours naturel ├Ā la repr├®sentation binaire.
Deux ou plusieurs bits peuvent ├¬tre associ├®s pour repr├®senter un nombre plus ├®lev├®. Lorsque des bits sont ainsi combin├®s, le bit sur la droite est le moins significatif et, s'il est ┬½┬Āmis┬Ā┬╗, il repr├®sente la valeur 1. Le bit imm├®diatement ├Ā gauche du pr├®c├®dent est plus significatif ├Ā un facteur 2 pr├©s. Lorsque ce bit est ┬½┬Āmis┬Ā┬╗, il repr├®sente la valeur 2. Voyons tout de suite un exemple┬Ā: supposons que vous ayez un nombre form├® de deux bits. Dans ce cas, il peut s'exprimer en binaire par 00, 01, 10 ou 11, correspondant en d├®cimal respectivement ├Ā 0, 1, 2 ou 3.
VIII-D-3. Octets, mots, double-mots, quadruple-mots et autresŌĆ”▲
Les octets (Bytes), mots (Words), doubles-mots (DWords) et quadruples-mots (QWords) sont des structures de donn├®e standard - au sens large du terme - utilis├®es en programmation. Le processeur fonctionnera avec la taille de donn├®e appropri├®e selon l'instruction en cours d'ex├®cution.
VIII-D-3-a. Repr├®sentation des nombres entiers▲
Si n est le nombre de bits d'une donn├®e, le nombre maximum repr├®sentable correspond ├Ā 2n-1 en base d├®cimale. Il s'agit, en l'occurrence, de nombres entiers en arithm├®tique non sign├®e.
Parmi les diff├®rents formats les plus usuels, un octet contient 8 bits, un mot en contient 16 (2 octets), un DWord, 32 bits (4 octets) et un QWord, 64 bits (8 octets). Le TWord de 80 bits (10 octets) existe ├®galement mais au niveau de l'unit├® arithm├®tique du processeur. Il est qualifi├® de ┬½┬Āformat en double-pr├®cision ├®tendu┬Ā┬╗. Enfin, les processeurs actuels poss├©dent quelques registres 128 bits (16 octets) et certaines instructions sont ├Ā m├¬me de manipuler directement des donn├®es de 128 bits.
Les formats les plus courants affichent les caract├®ristiques suivantes┬Ā:
| Format | Nb de bits | Nb d'octets | Valeur enti├©re max (non sign├®e) |
| Octet (Byte) | 8 | 1 | 28-1 = 256 |
| Mot (Word) | 16 | 2 | 216-1 = 65┬Ā535 |
| Double-mot (DWord) | 32 | 4 | 232-1 = 4┬Ā294┬Ā967┬Ā295 |
| Quadruple-mot (QWord) | 64 | 8 | 264-1 = 18┬Ā446┬Ā744┬Ā073┬Ā709┬Ā551┬Ā615 |
On notera qu'il est courant de parler, pour simplifier le propos, de 64 kilo-octets (64 Ko) de capacit├® pour un mot et de 4 Gigaoctets (4┬ĀGo) pour un double-mot bien que les valeurs exactes affichent une diff├®rence sensible.
Tous les formats que nous venons de voir sont employ├®s aussi en arithm├®tique sign├®e. Le principe est simple┬Ā: le bit de plus fort poids est d├®di├® au signe (1 = n├®gatif, 0 = positif). Corr├®lativement, la gamme de valeurs absolues quantifiables se voit divis├®e par 2.
VIII-D-3-b. Repr├®sentation des nombres en virgule flottante▲
Le processeur ne peut se cantonner ├Ā ne g├®rer que des nombres entiers et doit assez souvent recourir aux formats en virgule flottante. Ici, nous entrons dans un autre monde o├╣ les m├¬mes formats utilis├®s pr├®c├®demment emploient d├®sormais la structure arithm├®tique classique de la forme┬Ā:
Nb = mantisse ├Ś 2exposant
Cette repr├®sentation est r├®gie par la norme IEEE 754 relative aux nombres en virgule flottante. Ses principes de base peuvent ├¬tre r├®sum├®s dans le tableau suivant(3)┬Ā:
| Type de donn├®e |
Longueur (bits) |
Pr├®cision (bits) |
Champ de d├®finition approximatif des nombres | |
| Binaire | D├®cimal | |||
| Demi-Pr├®cision | 16 | 11 | 2-14 ├Ā 215 | 3,1 ├Ś 10-5 ├Ā 6,50 ├Ś 104 |
| Simple-Pr├®cision | 32 | 24 | 2-126 ├Ā 2127 | 1,18 ├Ś 10-38 ├Ā 3,40 ├Ś 1038 |
| Double-Pr├®cision | 64 | 53 | 2-1022 ├Ā 21023 | 2,23 ├Ś 10-308 ├Ā 1,79 ├Ś 10308 |
| Double-Pr├®cision ├ētendue | 80 | 64 | 2-16382 ├Ā 216383 | 3,37 ├Ś 10-4932 ├Ā 1,18 ├Ś 104932 |
VIII-D-4. Nombres hexad├®cimaux▲
Avant d'aller plus avant dans la repr├®sentation num├®rique hexad├®cimale, attardons-nous un instant sur une subdivision importante de l'octet┬Ā: le quartet qui est en fait un demi-octet. Ce quartet contient quatre bits de donn├®es. Il se pr├¬te particuli├©rement bien, on le voit, ├Ā la num├®ration hexad├®cimale puisqu'il peut repr├®senter l'ensemble des nombres allant de 0 ├Ā 15. Dans ce cas, il est d'ailleurs d'usage de repr├®senter les nombres 10 ├Ā 15 repectivement par les lettres A ├Ā F. Consid├®rons par exemple le nombre hexad├®cimal 148C qui occupe deux octets. Le premier octet contient la valeur de 14h et le second 8Ch. Les 4 quartets contiennent respectivement les valeurs 1, 4, 8 et 0Ch.
Les programmeurs utilisent la repr├®sentation hexad├®cimale pour de multiples raisons. C'est un moyen pratique de repr├®senter un nombre de mani├©re plus compacte mais n├®anmoins compr├®hensible. La modularit├® par quartet permet de visualiser, du premier coup d'┼ōil, le format d'un nombre en tant qu'octet, Word, DWord ou QWord. Elle permet ├®galement au programmeur de scruter certains bits et d'├®valuer imm├®diatement leur ├®tat, ce que n'autorise pas une repr├®sentation d├®cimale. Enfin, leur usage facilite la compr├®hension et la mise en ┼ōuvre d'instructions logiques telles que OR, AND, XOR, TEST ou BT, par exemple.
Les nombres hexad├®cimaux (ou Hex en abr├®viation) sont ainsi nomm├®s parce qu'ils sont en base 16. Chaque symbole hexad├®cimal utilise les chiffres 0 ├Ā 9 ou les lettres A, B, C, D, E ou F, ces derni├©res caract├®risant respectivement les valeurs 10, 11, 12, 13, 14 ou 15. Chaque symbole hexad├®cimal occupe quatre bits de donn├®es binaires.
Voici les valeurs qui peuvent ├¬tre cr├®├®es ├Ā partir de quatre bits et, pour chacune, leur ├®quivalent en hexad├®cimal et en d├®cimal┬Ā:
| binaire 0000 0001 0010 0011 0100 0101 0110 0111 1000 1001 1010 1011 1100 1101 1110 1111 |
hex 0 1 2 3 4 5 6 7 8 9 A B C D E F |
d├®cimal 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
Un octet peut ├¬tre repr├®sent├® par la juxtaposition de deux chiffres hexad├®cimaux, un mot par quatre chiffres hexad├®cimaux et un DWord par huit chiffres hexad├®cimaux. Le tableau qui suit vous permet de mesurer le r├®el atout de la notation hexad├®cimale lorsque l'on repr├®sente de grands nombres qui deviennent d├©s lors difficiles ├Ā manier sous leur format d├®cimal┬Ā:
| binaire 10000000 1000000000000001 1111111111111111 10000000000000000000000000000001 11111111111111111111111111111111 |
hexa 80 8001 FFFF 80000001 FFFFFFFF |
d├®cimal 128 32┬Ā769 65┬Ā535 2┬Ā147┬Ā483┬Ā649 4┬Ā294┬Ā967┬Ā295 |
(Byte) (Word) (Word) (DWord) (DWord) |
VIII-D-5. Nombres finis, n├®gatifs, sign├®s et en compl├®ment ├Ā 2▲
Dans le monde des math├®matiques, les nombres sont cens├®s pouvoir prendre des valeurs infiniment grandes.
Dans le cas de l'informatique, les nombres g├®r├®s par les ordinateurs sont n├®cessairement limit├®s parce que la taille du bloc de donn├®es mis ├Ā disposition du stockage et du calcul est finie. Par exemple, un octet ne peut contenir un nombre sup├®rieur ├Ā 255. Si, lors d'une op├®ration sur un octet, vous ajoutez 1 ├Ā 255, le r├®sultat devient nul. Dans ce cas particulier, fort heureusement, l'instruction positionne le flag de retenue ├Ā 1 indiquant de la sorte que le nombre r├®sultant ├®tait trop grand pour le format de donn├®e utilis├®. Vous pouvez savoir ainsi que le r├®sultat n'├®tait pas nul, mais ├®gal en fait ├Ā 256.
├ētant donn├® que la taille des donn├®es est finie, il est possible de consid├®rer les donn├®es comme ayant deux valeurs ├Ā un moment donn├®, une valeur positive et une valeur n├®gative.
Voici o├╣ je veux en venir┬Ā: supposons que vous ayez un octet dont tous les bits sont ├Ā 1. Vous pouvez logiquement penser qu'il contient le nombre 0FFh (ou 255 en d├®cimal). Mais vous pourriez ├®galement consid├®rer qu'il s'agit du nombre -1, dont on peut dire qu'il correspond ├Ā la soustraction 256-1. Vous pouvez d'ailleurs prouver qu'il est correct d'assimiler ce nombre ├Ā 1 parce que si vous lui ajoutez 1, le r├®sultat est nul, ce qui est correct au regard de la taille des donn├®es concern├®es (bien qu'il y ait une retenue).
En jargon de programmeur, le seul fait de consid├®rer que le bloc de donn├®es puisse contenir un nombre n├®gatif signifie que le nombre appartient de facto ├Ā la cat├®gorie des ┬½┬Ānombres sign├®s┬Ā┬╗. On parle aussi d'arithm├®tique sign├®e dans ce cas. Que le nombre soit n├®gatif ou non d├®pend alors de l'├®tat du bit de plus fort poids (le plus ├Ā gauche) dans le bloc de donn├®e, qui est appel├® le ┬½┬Ābit de signe┬Ā┬╗. Si ce bit est ├Ā 1, nous sommes en pr├®sence d'un nombre sign├® n├®gatif. Par exemple, supposons qu'un octet contienne la valeur 82h. Si nous sommes cens├®s ├®voluer en arithm├®tique sign├®e, le bit de signe est ├Ā 1 de sorte que le nombre est en r├®alit├® -7Eh (ou -126 d├®cimal) car r├®sultant de la soustraction 100h-82h. De m├¬me, une valeur de 81h dans le m├¬me contexte correspond ├Ā -7Fh (ou -127 en d├®cimal). Ou encore, une valeur de 80h correspond ├Ā -80h (ou -128 en d├®cimal). En revanche, une valeur de 7Fh caract├®rise avec certitude le nombre positif +7Fh puisque le bit de signe est pr├®sentement nul et ceci, que nous soyons en arithm├®tique sign├®e ou non.
Le bit de signe est toujours celui qui se situe le plus ├Ā gauche. C'est donc le bit 7 dans un octet, le bit 15 dans un mot, le bit 31 dans un DWord et le bit 63 dans un QWord. Cette num├®rotation suppose que le bit le plus ├Ā droite soit le bit 0 dans tous les cas, ce qui correspond du reste ├Ā un usage largement r├®pandu.
Au terme de l'ex├®cution de la plupart des instructions arithm├®tiques, le flag de signe est positionn├® ├Ā 1 si le bit de signe est lui-m├¬me ├Ā 1. ├ēvidemment, ce flag peut ├¬tre test├® pour voir si le r├®sultat est n├®gatif apr├©s que l'instruction a ├®t├® ex├®cut├®e.
Remarquons que, dans un octet en arithm├®tique sign├®e, le nombre 0FFh correspond ├Ā -1h, 0FEh correspond ├Ā -2h, 0FDh correspond ├Ā -3h et ainsi de suite. On voit donc que cette s├®quence, bien que d├®croissante en apparence, est en r├®alit├® une progression si l'on consid├©re la valeur absolue des nombres n├®gatifs ├®quivalents. Seule l'exp├®rience en mati├©re de manipulation de nombres hexad├®cimaux permet de saisir cette dualit├® au premier coup d'┼ōil.
Une fa├¦on simple de calculer la valeur absolue d'un nombre n├®gatif (affichant donc un bit de signe ├Ā 1) est d'effectuer son compl├®ment en inversant tous ses bits, puis d'ajouter 1 au r├®sultat obtenu. Voici une illustration de ce calcul┬Ā:
0F0h en binaire est 11110000
son compl├®ment est 00001111 ŌåÆ compl├®ment ├Ā 1
qui est 0Fh
on ajoute 1, soit 10h ŌåÆ compl├®ment ├Ā 2
ce qui correspond ├Ā 16 en d├®cimalLa premi├©re ├®tape consistant ├Ā inverser les bits est nomm├®e ┬½┬Ācompl├®ment ├Ā 1┬Ā┬╗. L'ajout d'une unit├® ├Ā ce r├®sultat permet d'obtenir ce que l'on appelle le ┬½┬Ācompl├®ment ├Ā 2┬Ā┬╗. C'est la raison pour laquelle les nombres sign├®s sont parfois dits en ┬½┬Ācompl├®ment ├Ā 2┬Ā┬╗.
L'avantage d├®cisif de ce syst├©me de num├®ration est que beaucoup d'instructions processeur peuvent ├¬tre utilis├®es ├Ā la fois pour les nombres sign├®s et non sign├®s. Il appartient de ce fait au programmeur, et ├Ā lui seul, de d├®finir le statut des nombres utilis├®s. Il y a quelques instructions, cependant, pour lesquelles cette polyvalence n'existe pas et, notamment les instructions de multiplication, de division et de d├®calage de bits ├Ā droite. Pour les deux premiers cas, le processeur propose des instructions de multiplication - IMUL - et de division - IDIV - sp├®cialement d├®di├®es ├Ā l'arithm├®tique sign├®e ├Ā utiliser en lieu et place de MUL et DIV qui sont les versions non sign├®es. Il y a trois raisons pour lesquelles cette distinction est n├®cessaire┬Ā:
- En premier lieu, lors de la manipulation de nombres sign├®s, le signe du r├®sultat d├®pend de celui des op├®randes. On conna├«t la r├©gle, applicable ├Ā la fois ├Ā la multiplication et ├Ā la division┬Ā: lorsque les deux membres de l'op├®ration sont de m├¬me signe, le r├®sultat est positif┬Ā; lorsqu'ils sont de signe contraire, le r├®sultat est n├®gatif. Les instructions IMUL et IDIV reportent le bon signe sur le r├®sultat alors que MUL et DIV sont incapables de le faire et ne peuvent op├®rer que sur des nombres positifs.
- En second lieu, le format des op├®randes d'instructions de multiplication et division ainsi que celui du r├®sultat de ces m├¬mes op├®rations ont, par nature, un gabarit diff├®rent. Par exemple, le r├®sultat de la multiplication de deux op├®randes de 32 bits est restitu├® par la paire de registres EDX:EAX qui forme un ensemble de 64 bits. Si la multiplication met en ┼ōuvre des op├®randes sign├®s, il est n├®cessaire que le signe du r├®sultat soit positionn├® sur son bit 63 (ou le bit 31 du registre EDX dans ce cas particulier). Dans le cas de la division 32 bits, le dividende est pr├®sum├® ├Ā 64 bits et h├®berg├® par la paire de registres EDX:EAX si le diviseur est un registre ou un espace m├®moire de format 32 bits. Le quotient est recueilli par le registre EAX et le reste, dans le registre EDX. Le signe du dividende sera sur le bit 31 de EDX┬Ā; celui du diviseur sera sur le bit 31 du registre ou emplacement m├®moire qui l'h├®berge. Enfin, celui du quotient et du reste sera respectivement sur le bit 31 des registres EAX et EDX. On voit ainsi que les instructions sign├®es veillent ├Ā ce que le bit de signe soit ├Ā la bonne place. On parle, dans ce cas, d'┬½┬Āextension de signe┬Ā┬╗ d'un nombre.
- Enfin, comme nous allons le voir, les instructions sign├®es garantissent que les flags de carry (retenue) et d'overflow (d├®passement) sont correctement positionn├®s selon le signe du r├®sultat.
Dans le cas de l'instruction d├®calage ├Ā droite SHR, il existe une variante sp├®ciale (SAR) qui ne modifie pas le bit de plus fort poids de l'op├®rande tout en maintenant le bon signe dans le r├®sultat. Une telle pr├®caution n'est pas n├®cessaire pour les instructions de d├®calage ├Ā gauche puisque le signe s'autocorrige. Pour autant, il existe une instruction SAL pendante de SHL mais qui a, en r├®alit├® le m├¬me code processeur.
Cet exemple montre ce qu'il advient concr├©tement┬Ā:
MOV AL, 0FEh ; met -2 dans AL
SAR AL, 1 ; divise AL par 2 - le r├®sultat dans AL est maintenant 0FFh, soit -1
MOV AL, 0FEh ; met -2 dans AL
SAL AL, 1 ; multiplie par 2 - le r├®sultat dans AL est maintenant 0FCh, soit -4Les nombres sign├®s ont aussi leur propre jeu d'instructions de saut conditionnel sign├®.
VIII-E. Pour les d├®butantsŌĆ” en langage assembleur▲
VIII-E-1. Qu'est-ce que le langage assembleur┬Ā?▲
Le langage assembleur est un langage de programmation. Les programmes y sont ├®crits sous forme litt├®rale ├Ā l'aide d'un simple ├®diteur de texte en vue de constituer le ┬½┬Ācode source┬Ā┬╗ ├®galement nomm├® ┬½┬Āscript┬Ā┬╗. Ce code source est lu puis traduit par un ┬½┬Āassembleur┬Ā┬╗ en fichier objet┬Ā; ce dernier est ├Ā son tour trait├® par un ┬½┬Ālinker┬Ā┬╗ - ou ├®diteur de liens - pour constituer le programme ex├®cutable final.
Une des caract├®ristiques du langage assembleur est que chaque ligne du code source ne contient habituellement qu'une seule instruction ├Ā destination du processeur. Par exemple MOV EAX, EDX copiera le contenu du registre EDX dans le registre EAX. Nous d├®couvrons ici l'instruction MOV qui est appel├®e ┬½┬Āmn├®monique┬Ā┬╗, contraction de ┬½┬Āmn├®motechnique┬Ā┬╗. Concr├©tement, cette instruction d├®place (MOV(e) en anglais) le contenu d'un registre ou d'un emplacement m├®moire vers un autre registre ou emplacement m├®moire. Quoi que l'on puisse penser de cette symbolique minimaliste, on conviendra ais├®ment qu'elle est plus expressive qu'une succession de deux ou trois octets binaires impossibles ├Ā m├®moriser par un cerveau normalement constitu├®. L'instruction, telle que nous venons de la d├®couvrir, peut sembler assez basique si vous ├¬tes habitu├® ├Ā un langage de haut niveau. Toutefois, lorsque vous commencerez ├Ā utiliser des API Windows dans vos programmes, vous c├┤toierez, sans vous en rendre vraiment compte, un langage de haut niveau (Windows lui-m├¬me). Ainsi, l'utilisation conjointe de Windows et de l'assembleur vous permettra-t-elle de manier un langage de haut niveau tout en conservant le contr├┤le total du processeur, autant dire LA combinaison parfaite┬Ā!
VIII-E-2. Pourquoi un code de si bas niveau┬Ā?▲
Il y a plusieurs raisons pour lesquelles il peut ├¬tre int├®ressant de recourir ├Ā un langage de si bas niveau.
- Taille┬Ā: en codant ├Ā ce faible niveau, vous pouvez r├®duire le code ├Ā un strict minimum inatteignable m├¬me par les compilateurs les plus performants.
- Vitesse┬Ā: une taille de code r├®duite au strict n├®cessaire signifie que vos programmes se chargent et s'ex├®cutent plus rapidement.
- Contr├┤le┬Ā: vous contr├┤lez totalement le code, ├Ā la diff├®rence d'un compilateur. Cela signifie que vous savez exactement ce que le processeur est en train de faire lorsqu'il ├®volue ├Ā travers votre code. Cela permet d'obtenir un r├®sultat probant et de rep├®rer les erreurs plus facilement.
- Satisfaction┬Ā: vous ├®crivez vous-m├¬me le programme. Il n'y a aucune intervention de quelque compilateur que ce soit.
VIII-E-3. Les instructions ├Ā votre disposition▲
Vous aurez besoin d'├®tudier les instructions qui constituent le c┼ōur de votre assembleur et d'en assimiler parfaitement les tenants et les aboutissants. Cependant, si l'on s'attache aux plus essentielles dans le cadre d'une approche initiatique, on aboutit ├Ā la liste qui suit.
- Instructions de registre. Elles consistent ├Ā commander au processeur de d├®placer des donn├®es ou effectuer des calculs en utilisant ses propres registres 32 bits. Il y a six registres ├Ā usage g├®n├®ral appel├®s EAX, EBX, ECX, EDX, ESI et EDI. Des exemples de telles instructions sont┬Ā:
MOV ESI, EBX ; d├®place le contenu du registre EBX dans le registre ESI
ADD EAX, EDI ; additionne le contenu du registre EDI ├Ā celui du registre EAX
BT ECX, 0 ; teste le bit 0 du registre ECX
CMP EDX, 450 ; compare le contenu du registre EDX ├Ā la valeur 450
DIV ECX ; divise EDX:EAX (entier long) par ECX
MUL ECX ; multiplie EAX par ECX et place le r├®sultat en EDX:EAX (entier long)
SHL EDX, 4 ; d├®cale les bits de EDX de 4 bits vers la gauche (multiplication par 16)
TEST EAX, 8 ; teste le bit 3 du registre EAX (├®quivaut ├Ā un AND)- Instructions de pile. La pile est une zone de m├®moire fournie par Windows pour chaque programme en cours d'ex├®cution destin├®e ├Ā ├¬tre utilis├®e comme une zone de stockage temporaire. Des exemples de telles instructions sont┬Ā:
PUSH EAX ; pousse le contenu du registre EAX sur la pile
POP EDX ; r├®cup├©re de la pile dans EDX le dernier ├®l├®ment pouss├® sur la pile
PUSH 1000h ; pousse la valeur hexad├®cimale 1000 sur la pile
MOV EBP, ESP ; r├®cup├©re la valeur courante du pointeur de pile dans le registre EBP
SUB ESP, 30h ; d├®place le pointeur de pile pour r├®server une zone de donn├®es locales
MOV D[EBP-20h], 500h ; ins├©re la valeur hexad├®cimale 500 dans la zone de donn├®es locales- Instructions d'ex├®cution. Elles commandent au processeur d'interrompre l'ex├®cution normale du flot d'instructions cons├®cutives et de la poursuivre en un autre point du code. Les exemples d'instructions r├®pondant ├Ā cette d├®finition sont┬Ā:
CALL MAKEWINDOW ; ex├®cute la proc├®dure situ├®e au label MAKEWINDOW et revient ensuite
CALL EAX ; ex├®cute la proc├®dure situ├®e au label dont l'adresse est contenue
; dans le registre EAX et revient ensuite
RET ; ach├©ve une proc├®dure et provoque un retour ├Ā l'appelant
JZ 4 ; d├®place l'ex├®cution au label 4: si le r├®sultat est nul
JC >.fin ; d├®place l'ex├®cution au label .fin si le flag de Carry est ├Ā 1
JMP MAKEWINDOW ; poursuit l'ex├®cution au label MAKEWINDOW
LOOP 2 ; d├®cr├®mente ECX puis effectue un saut au label 2: si ECXŌēĀ0- Instructions de m├®moire. Ces instructions, selon le cas, lisent une zone m├®moire autre que la pile ou ├®crivent dessus. Typiquement, cette m├®moire peut ├¬tre dans la section de donn├®es (data section) propre de l'ex├®cutable ou dans de la m├®moire ├®ventuellement allou├®e par Windows lors de l'ex├®cution. En voici quelques exemples┬Ā:
ADD EAX, [ESI] ; additionne au contenu de EAX le contenu de la m├®moire point├®e par ESI
MOV EAX, [MYDATA] ; copie dans EAX le contenu de la m├®moire au label MYDATA
SUB D[MYDATA+64], 10h ; soustrait la valeur 10h au dword ├Ā l'adresse MYDATA plus 64 octets
CMP B[MYDATA+EDX*4], 2 ; compare ├Ā 2 un octet situ├® dans le tableau MYDATA ├Ā l'offset EDX
LODSB ; copie dans AL l'octet de m├®moire point├® par le registre ESI
STOSD ; copie le contenu de EAX dans le dword de m├®moire point├® par EDI- Instructions de flags. Les principaux indicateurs (ou flags) que vous allez utiliser sont Z (flag de z├®ro), C (flag de carry ou de retenue), S (flag de signe) et D (flag de direction). Ils sont d├®positaires, en temps r├®el et automatiquement, du r├®sultat de la plupart des op├®rations ou tests effectu├®s par les instructions. ├Ć cela s'ajoutent certaines instructions sp├®cifiques que vous pouvez utiliser pour modifier manuellement les flags du processeur┬Ā:
STC ; met ├Ā 1 le flag de carry (retenue)
CLC ; met ├Ā 0 le flag de carry (retenue)
STD ; met ├Ā 1 le flag de direction pour LODS, STOS, CMPS, SCAS et MOVS
CLD ; met ├Ā 0 le flag de direction- D├®clarations de m├®moire. Windows r├®serve de la m├®moire ├Ā l'ex├®cutable lors du d├®marrage de ce dernier. Les d├®clarations sont faites pour r├®server de la m├®moire dans la section de donn├®es ou la section constante si les donn├®es doivent ├¬tre initialis├®es, c'est-├Ā-dire qu'une valeur leur est assign├®e. Si les donn├®es ne sont pas destin├®es ├Ā ├¬tre initialis├®es, la zone de donn├®es peut ├¬tre r├®serv├®e alors dans la section de donn├®es non initialis├®es. Dans ce cas, elle ne prend pas de place dans le fichier Exe. Au lieu cela, un espace dans la m├®moire lui est allou├® au moment du d├®marrage de l'ex├®cutable.
Quelques exemples de la fa├¦on dont la m├®moire est d├®clar├®e (qui peut diff├®rer selon les assembleurs)┬Ā:
DB 4 ; d├®clare un octet et porte sa valeur initiale ├Ā 4
MYDATA DB 4 ; octet de valeur initiale 4 avec le label de donn├®e MYDATA
MYSTRUCT DD 16 DUP 0 ; 16 dwords tous mis ├Ā 0 et appel├®s MYSTRUCT
BUFFER DB 1024 DUP ? ; 1024 octets nomm├®s BUFFER en tant que donn├®es non initialis├®es- D├®clarations de sections. Instructions qui pr├®cisent ├Ā l'assembleur dans quelle section mettre le code source qui suit. L'assembleur consid├©re la section de code en lecture seule et comme ├®tant la seule ex├®cutable. L'assembleur d├®finit ├®galement des sections de donn├®es d├®finies et non d├®finies en lecture/├®criture. Voici quelques exemples (des diff├®rences existent entre les diff├®rents assembleurs existants)┬Ā:
CODE SECTION ; tout ce qui suit cette d├®claration est ├Ā marquer en
; lecture seule et ex├®cutable (code)
DATA SECTION ; tout ce qui suit cette d├®claration est avec des attributs
; de lecture/├®criture distincts des attributs de code
CONST SECTION ; tout ce qui suit cette d├®claration est dans une section
; avec des attributs en lecture seule- Commentaires. Tout ce qui suit un point-virgule sera ignor├® jusqu'├Ā la fin de la ligne courante, vous permettant ainsi de d├®crire exactement, sous forme de commentaires, ce que votre code source est en train de faire et dans quel but.
- Fonctions Windows. Elles permettent au programmeur assembleur d'acc├®der ├Ā une vaste gamme d'API Windows (Applications Programming Interface). Il s'agit de code localis├® dans le syst├©me d'exploitation Windows. En voici quelques exemples┬Ā:
PUSH 12h ; pousse en pile le code de la touche Alt sur le clavier
CALL GetKeyState ; demande ├Ā Windows de mettre l'├®tat de la touche Alt dans EAX
TEST EAX, 80000000h ; teste si la touche Alt est press├®e (bit 31=1 ?)
JZ >L22 ; non, alors on va au label L22
;.............
PUSH 24h ; valeur hexa 24 = point d'interrogation + Boutons Oui et Non
PUSH ESI, EDI ; adresse du titre, adresse du message
PUSH [hWnd] ; handle de la fenêtre
CALL MessageBoxA ; affiche la Message Box Windows avec la demande Oui/Non
CMP AL, 7 ; On regarde si c'est le bouton Non qui a ├®t├® cliqu├® par l'utilisateur
JNZ >L40 ; non, alors on va au label L40
;.............
PUSH 0
PUSH ADDR FILE_DONE ; on donne l'adresse de FILE_DONE pour y recevoir le r├®sultat
PUSH ECX, EDX ; ECX = nb d'octets ├Ā ├®crire, EDX= source de donn├®es,
PUSH ESI ; ESI = handle du fichier
CALL WriteFile ; ├®crit ECX octets de EDX vers ESI
;.............
PUSH 808h, 5h ; 808 = bas et milieu rempli, 5 = ├®lev├®
PUSH EBX, EDX ; EBX = RECT, EDX = contexte de p├®riph├®rique
CALL DrawEdge ; dessine un rectangle bord├® sp├®cial ├Ā l'├®cran
;.............
PUSH 4h, 3000h, ESI, 0 ; 4h = m├®moire en lecture/├®criture, 3000h = r├®servation
CALL VirtualAlloc ; r├®serve et engage ESI octets de m├®moire en lecture/├®criture
;.............
PUSH 0, [hInst], 0, 0 ; param, handle du module, menu, personnel
PUSH 208, 130, 30, 300 ; hauteur, largeur, y, x
PUSH 80C80000h ; style (POPUP+CAPTION+SYSMENU)
PUSH EAX ; EAX = adresse de la chaîne AsciiZ avec titre
PUSH 'LISTBOX' ; mise en pile du pointeur de 'LISTBOX'
PUSH 0 ; style ├®tendu (aucun)
CALL CreateWindowExA ; cr├®ation d'une fen├¬tre listbox
;...... ou, si vous pr├®f├®rez, vous pouvez utiliser INVOKE ..
INVOKE CreateWindowExA, 0, 'LISTBOX', EAX, 80C80000h, 300, 30, 130, 208, 0, 0, [hInst], 0
;.............
INVOKE ShowWindow, [hWnd], 1VIII-F. Flags, sauts conditionnels, CMOVcc et SETcc▲
VIII-F-1. Les Flags▲
Les flags sont constitu├®s, chacun, d'un seul bit du registre 32 bits EFLAGS du processeur (RFLAGS en 64 bits). Il y a six flags d'├®tat utilis├®s pour indiquer le r├®sultat de certaines instructions et un flag de direction permettant de fixer le sens d'incr├®mentation automatique des adresses sur certaines instructions telles que MOVS, CMPS, SCAS, LODS et STOS. Certaines instructions comme CMP, TEST et BT se bornent ├Ā modifier certains de ces flags et ne font rien d'autre. D'autres instructions effectuent des op├®rations tout en modifiant tout ou partie de ces flags tandis que certaines n'ont aucune action sur eux. L'impact de chaque instruction sur les flags est parfaitement document├® par les fondeurs de processeur.
Les flags sont fr├®quemment utilis├®s pour changer le cours d'ex├®cution d'une partie du code par le biais d'instructions de saut conditionnel. Ces instructions ont la particularit├® d'effectuer ou non un branchement vers une autre portion de code selon l'├®tat d'un ou plusieurs flags. Seulement cinq parmi ces flags peuvent ├¬tre utilis├®s de cette mani├©re┬Ā: z├®ro, signe, retenue et parit├®. Les sixi├©me (retenue auxiliaire) et septi├©me (direction) flags sont lus par d'autres instructions.
Voici plus d'informations sur les cinq flags qui peuvent ├¬tre utilis├®s par les instructions de saut conditionnel┬Ā:
VIII-F-1-a. Zf - flag de z├®ro▲
Prend la valeur 1 chaque fois que le r├®sultat d'une op├®ration prescrite par une instruction est nul dans le registre ou l'emplacement m├®moire destination. Certaines instructions telles que CMP (comparaison) et TEST (test) permettent de positionner ce flag sans effectuer la moindre op├®ration. Par exemple, CMP r├®alise une soustraction de l'op├®rande source et de l'op├®rande destination sans en donner le r├®sultat et ├Ā seule fin d'activer certains indicateurs dont le flag de z├®ro. En ce sens, elle s'apparente ├Ā l'instruction SUB qui op├©re de la m├¬me mani├©re mais fournit explicitement le r├®sultat de la soustraction dans l'op├®rande destination. Par exemple┬Ā:
CMP EAX, 33h ; met ├Ā 1 le flag de z├®ro si EAX=33h, mais ne modifie pas EAX
SUB EAX, 33h ; met ├Ā 1 le flag de z├®ro si EAX=33h, mais soustrait 33h ├Ā EAX
CMP EAX, EDX ; met ├Ā 1 le flag de z├®ro si EAX=EDX
CMP EAX, [VALUE] ; met ├Ā 1 le flag de z├®ro si EAX=le nb point├® par VALUELe flag de z├®ro peut ├®galement ├¬tre utilis├® pour d├®tecter l'atteinte d'une borne sup├®rieure ou inf├®rieure par un compteur. Par exemple┬Ā:
DEC EAX ; met ├Ā 1 le flag de z├®ro si EAX est nul apr├©s l'instruction
; et le met ├Ā z├®ro dans le cas contraire
INC EAX ; met ├Ā 1 le flag de z├®ro si EAX est nul apr├©s l'instruction
; et le met ├Ā z├®ro dans le cas contraireLe flag de z├®ro peut ├®galement servir ├Ā contr├┤ler la r├®p├®tition d'instructions de cha├«ne telles que LODS, STOS, MOVS, SCAS, CMPS, INS et OUTS.
- Le pr├®fixe REP appliqu├® aux instructions LODS, STOS, MOVS, INS et OUTS r├®p├©te ces instructions autant de fois que sp├®cifi├® par le contenu du registre (E)CX/RCX. Concr├©tement, au terme de chaque ex├®cution de l'instruction, l'adresse contenue dans chaque registre d'index(4) est incr├®ment├®e (ou d├®cr├®ment├®e(5)), la r├®p├®tition s'interromp lorsque (E)CX/RCX=0, situation marqu├®e par le flag Zf.
- Les pr├®fixes REPE/REPZ/REPNE/REPNZ appliqu├®s ├Ā l'instruction SCAS permettent de comparer le contenu de (E)AX/RAX ├Ā l'adresse de m├®moire point├®e par (E)DI/RDI. SCAS est r├®p├®t├®e tant que (E)AX/RAX=[(E)DI/RDI] avec REPE/REPZ ou tant que (E)AX/RAXŌēĀ[(E)DI/RDI] avec REPNE/REPNZ. Au terme de chaque ex├®cution de l'instruction, l'adresse contenue dans (E)DI/RDI est incr├®ment├®e (ou d├®cr├®ment├®e) selon le positionnement du flag de direction.
- Les pr├®fixes REPE/REPZ/REPNE/REPNZ appliqu├®s ├Ā l'instruction CMPS permettent de comparer le contenu de l'emplacement m├®moire point├® par (E)SI/RSI ├Ā celui point├® par (E)DI/RDI. CMPS est r├®p├®t├®e tant que [(E)SI/RSI] = [(E)DI/RDI] avec REPE/REPZ ou tant que [(E)SI/RSI] ŌēĀ [(E)DI/RDI] avec REPNE/REPNZ. Au terme de chaque ex├®cution de l'instruction, les adresses contenues dans (E)SI/RSI et (E)DI/RDI sont incr├®ment├®es (ou d├®cr├®ment├®es) selon le positionnement du flag de direction.
Il n'est pas rare qu'un retour d'API Windows (le plus souvent dans EAX) se solde par un ├®chec d'ex├®cution. Donc, vous aurez souvent besoin de tester cette ├®ventualit├®. Lors du test de EAX, vous pouvez utiliser ces alternatives┬Ā:
CMP EAX, 0 ; voir si EAX = 0 (flag de z├®ro ├Ā 1 dans ce cas)
OR EAX, EAX ; fait la même chose mais utilise 2 opcodes au lieu de 3
TEST EAX, EAX ; fait ├®galement la m├¬me chose et utilise seulement 2 opcodesLes versions 16 bits et 8 bits des instructions testent seulement les 16 ou 8 premiers bits de la zone de registre ou de la m├®moire, respectivement, par exemple┬Ā:
CMP W[DAVID], 0 ; voir si les 16 premiers bits de m├®moire point├®s
; par DAVID sont nuls
CMP B[SUE], 0 ; voir si les 8 premiers bits de m├®moire point├®s
; par SUE sont nuls
OR DX, DX ; voir si le registre DX est ├Ā z├®ro (registre 16 bits)
TEST DH, DH ; voir si le registre DH est ├Ā z├®ro (registre 8 bits)
SUB B[VALUE], 2 ; soustrait 2 ├Ā la valeur 8 bits point├®e par VALUE (flag de
; z├®ro ├Ā 1 si le r├®sultat de l'op├®ration est nul)
DEC SI ; flag de z├®ro ├Ā 1 si SI est nul (registre 16 bits)
INC B[COUNT] ; flag de z├®ro ├Ā 1 si l'octet point├® par COUNT est nulDans la mesure o├╣ les flags sont tr├©s utiles lors du retour d'une routine pour identifier un ├®ventuel ├®chec d'ex├®cution, vous devrez parfois en fixer pr├®alablement le contenu. Il n'existe pas d'instruction d├®di├®e ├Ā l'initialisation du flag de z├®ro. Vous pouvez cependant y parvenir simplement de la mani├©re suivante┬Ā:
CMP EAX, EAX ; met ├Ā 1 le flag de z├®ro (EAX demeure inchang├®)
SUB EAX, EAX ; met ├Ā 0 le flag de z├®ro (provoque de surcro├«t : EAX = 0)
CMP EAX, EDX ; met ├Ā 0 le flag de z├®ro lorsque EAXŌēĀEDX
OR EAX, EAX ; met ├Ā 0 le flag de z├®ro tant que EAXŌēĀ0
TEST EAX, EAX ; m├¬me effet que OR EAX,EAXApr├©s ex├®cution de l'instruction TEST, le flag de z├®ro est mis ├Ā 1 si le bit test├® est nul. Notez, dans ce cas, que l'op├®rande de l'instruction permet de d├®finir le (ou les) bit(s) test├®(s). Par exemple┬Ā: 1 = bit #0, 2 = bit #1, 4 = bit #2, 3 = bits #0 et #1. Retenir que, selon un principe analogue ├Ā CMP, TEST effectue un AND entre les op├®randes source et destination, positionne le flag de z├®ro en cons├®quence mais ne fournit pas le r├®sultat de l'op├®ration.
Les exemples qui suivent illustrent le m├®canisme de r├®flexion ├Ā associer aux instructions TEST et CMP pour bien en comprendre le fonctionnement┬Ā:
MOV ECX, 1 ; donne la valeur 1 au registre ECX
TEST ECX, 1 ; AND ECX, 1 est ├®gal ├Ā 1 => le flag de z├®ro est nul
CMP ECX, 1 ; SUB ECX, 1 est ├®gal ├Ā 0 => le flag de z├®ro est ├Ā 1MOV EDX, 0 ; EDX = 0
TEST EDX, 1 ; AND EDX, 1 est ├®gal ├Ā 0 => le flag de z├®ro est ├Ā 1
CMP EDX, 1 ; SUB EDX, 1 est ├®gal ├Ā -1 => le flag de z├®ro est nulMOV EBX, -1 ; EBX = -1 (0FFFFh en pratique => tous les bits ├Ā 1)
TEST EBX, -1 ; AND EBX, -1 est ├®gal ├Ā 1 (TEST sur les 32 bits) => le flag
; de z├®ro est nul
CMP EBX, -1 ; SUB EBX, -1 est ├®gal ├Ā 0 => le flag de z├®ro est ├Ā 1Le flag de z├®ro est le seul utilis├® avec les instructions de saut conditionnel JZ et JNZ (├®quivalant rigoureusement ├Ā JE et JNE). Par exemple┬Ā:
JZ >L10 ; saut vers l'avant en L10 si le flag de z├®ro est ├®gal ├Ā 1
JNZ L1 ; saut vers l'arri├©re en L1 si le flag de z├®ro est nulLe flag de z├®ro est ├®galement utilis├® dans le JA (sauter si sup├®rieur ├Ā(6)), JB (saut si inf├®rieur ├Ā) et les instructions ├®quivalentes de saut conditionnel (JA = JNBE et JB = JNAE).
Il peut ├®galement ├¬tre utilis├® dans des boucles en utilisant des instructions sp├®cifiques ou non. Voici quelques exemples assez classiques┬Ā:
L1:
; autre code ici
CMP EDX, EAX
LOOPZ L1 ; d├®cr├®mente ECX, poursuit la boucle jusqu'├Ā ce que ECX = 0
; ou jusqu'├Ā ce que EDX = EAX (lorsque le flag de z├®ro sera ├Ā 1)
;*******
L1:
; autre code ici
CMP EDX, EAX
LOOPNZ L1 ; d├®cr├®mente ECX, poursuit la boucle jusqu'├Ā ce que ECX = 0
; ou jusqu'├Ā ce que EDX ŌēĀ EAX (lorsque le flag de z├®ro sera nul)
;*******
L1:
; autre code ici
CMP EDX, EAX
JZ >L10 ; saut hors de la boucle si EDX=EAX (flag de z├®ro flag ├Ā 1)
LOOP L1 ; d├®cr├®mente ECX, poursuit la boucle jusqu'├Ā ce que ECX = 0
L10:
;*******
L1:
; autre code ici
CMP EDX, EAX
JNZ L1 ; poursuit la boucle jusqu'├Ā ce que EDX = EAX (flag de z├®ro ├Ā 1)On notera ici qu'il n'a pas ├®t├® question ici des instructions de saut conditionnel JCXZ, JECXZ et JRCXZ fr├®quemment utilis├®es dans les boucles mais dont la particularit├® est de n'agir que sur le constat que le contenu des registres CX, ECX, RCX (selon le cas) est nul.
VIII-F-1-b. Sf - flag de signe▲
Prend la valeur 1 chaque fois que le bit le plus significatif (le plus ├Ā gauche) du r├®sultat est ├®gal ├Ā 1. La position de ce bit d├®pend de la taille des donn├®es. Dans un octet, le bit le plus significatif est le bit 7 (8 bits des bits 0 ├Ā 7)┬Ā; dans un mot, c'est le bit 15 (16 bits des bits 0 ├Ā 15)┬Ā; dans un DWord, c'est le bit 31 (32e bit des bits 0 ├Ā 31) et dans un QWword, c'est le bit 63 (64e bit des bits 0 ├Ā 63). Donc, ce bit sera ├Ā 1 si le r├®sultat de l'instruction est Ōēź 80h pour un octet, Ōēź 8000h pour un mot ou Ōēź 80000000h pour un DWord. Notez que dans les nombres sign├®s le bit le plus significatif indique que le nombre est n├®gatif (1) ou non (0).
Le flag de signe est modifi├® par INC et DEC alors que le flag de retenue ne l'est pas, donc le test de l'indicateur de signe est souvent utile dans les boucles. Par exemple┬Ā:
L0:
;
DEC ECX ; d├®cr├®mente ECX d'une unit├®
JNS L0 ; boucle arri├©re vers L0 si ECX n'est pas encore ├Ā -1Le flag de signe peut ├®galement ├¬tre commod├®ment utilis├® dans des fonctions ├Ā multiples-actions, par exemple┬Ā:
MULTI_ACTION: ; ├Ā l'entr├®e, le registre AL contient l'action ├Ā accomplir
DEC AL ; voir si AL = 0
JS >L0 ; oui
DEC AL ; voir si AL = 1
JS >L1 ; oui
DEC AL ; voir si AL = 2
JS >L2 ; oui
DEC AL ; voir si AL = 3
JS >L3 ; oui
DEC AL ; voir si AL = 4
JS >L4 ; ouiL'utilisation de l'indicateur de signe est un moyen pratique de voir si le bit de plus fort poids d'un registre est ├Ā 1 ou ├Ā 0. Un certain nombre d'instructions mettent ce flag ├Ā 1 sans modifier aucun registre, par exemple┬Ā:
OR EDX, EDX ; met le flag de signe ├Ā 1 si le plus haut bit de EDX est ├Ā 1
CMP EDX, EDX ; - idem -
TEST EDX, EDX ; - idem -OR CL, CL ; met le flag de signe ├Ā 1 si le plus haut bit de CL est ├Ā 1
CMP CL, CL ; - idem -
TEST CL, CL ; - idem -Lors de la v├®rification du contenu de zones de m├®moire cependant, vous ne pouvez adresser la m├®moire qu'une fois par instruction de sorte que vous devez utiliser CMP. Par exemple┬Ā:
CMP B[DATA44], 0 ; met ├Ā 1 le flag de signe si le 8┬░ bit de DATA44 est ├Ā 1
CMP W[DATA44], 0 ; met ├Ā 1 le flag de signe si le 16┬░ bit de DATA44 est ├Ā 1
CMP D[DATA44], 0 ; met ├Ā 1 le flag de signe si le 32┬░ bit de DATA44 est ├Ā 1
CMP B[DATA44+7], 0 ; met ├Ā 1 le flag de signe si le 64┬░ bit de DATA44 est ├Ā 1
CMP B[DATA44+9], 0 ; met ├Ā 1 le flag de signe si le 80┬░ bit de DATA44 est ├Ā 1Noter que la position du bit de poids fort dans la zone de m├®moire point├®e par DATA44 d├®pend de la taille de donn├®es trait├®e par l'instruction au moyen de l'indicateur de type (B, W ou D pr├®sentement). En effet, les octets des donn├®es dans les zones de m├®moire sont stock├®s dans l'ordre inverse, l'octet le moins significatif ├®tant positionn├® en premier alors que l'octet le plus significatif figure en dernier ├Ā une adresse plus haute. On lira avec int├®r├¬t sur ce sujet l'annexe traitant la question de la m├®morisation invers├®e. L'instruction CMP B[DATA44+7], 0 teste le 8e octet qui contient le 64e bit. Il s'agit bien du signe, mais pour une taille de donn├®es de 64 bits.
Le flag de signe est principalement utilis├® par les instructions de saut conditionnel JS et JNS, par exemple┬Ā:
JS >L10 ; saut avant vers L10 si le flag de signe est ├Ā 1
JNS L1 ; saut arri├©re vers L1 si le flag de signe est ├Ā 0Le flag de signe est ├®galement utilis├® par JG (saut si plus grand que), JNG (saut si non plus grand que) et les instructions ├®quivalentes de saut conditionnel (JG = JNLE et JNG = JLE).
VIII-F-1-c. Cf - flag de retenue ou flag de carry▲
Prend la valeur 1 chaque fois que le r├®sultat de l'instruction est all├® au-del├Ā de la limite de la taille des donn├®es (c'est-├Ā-dire qu'une ┬½┬Āretenue┬Ā┬╗ - ┬½┬Ācarry┬Ā┬╗ en anglais - a ├®t├® faite). Supposons par exemple que, dans une instruction de 8 bits, la valeur de 1 soit ajout├®e ├Ā 255. Cela ne peut pas faire 256 puisque 255 est la limite structurelle de la donn├®e pour un octet. Donc, le r├®sultat sera 0, mais le flag de retenue sera activ├® en prenant la valeur 1. Imaginons maintenant la situation o├╣ l'on soustrairait 4 ├Ā 2. L├Ā encore, on constaterait l'activation du flag de retenue parce que le r├®sultat passe en dessous de z├®ro, qui est la limite inf├®rieure de taille des donn├®es.
Le flag de retenue indique donc qu'un d├®bordement est survenu lors de l'utilisation des nombres non sign├®s. Voir la section concernant le flag d'overflow s'agissant des d├®bordements lorsque des nombres sign├®s sont utilis├®s.
Contrairement ├Ā d'autres flags d'├®tat, il existe des instructions sp├®cifiquement con├¦ues pour positionner le flag de retenue directement┬Ā:
STC ; met ├Ā 1 le flag de retenue
CLC ; met ├Ā 0 le flag de retenue
CMC ; compl├®mente le flag de retenue (inverse son ├®tat)Par ailleurs, les instructions de manipulation de bits BT, BTS, BTR et BTC permettent de copier un bit sp├®cifi├® dans le flag de retenue.
Compte tenu de la simplicit├® de mise en ┼ōuvre des instructions STC, CLC et CMC, le flag de retenue est tr├©s utilis├® pour signaler le r├®sultat d'une fonction au processus appelant, par exemple┬Ā:
CALCULATE2:
;
CMP EBX, ESI
JZ >.fail ; saut au label .fail si EBX = ESI
CMP EAX, ESI
JZ >.success ; saut au label .success si EAX = ESI
.fail
STC ; met le flag de retenue ├Ā 1 pour faire appara├«tre un ├®chec
RET
.success
CLC ; met le flag de retenue ├Ā 0 pour faire appara├«tre un succ├©s
RET
;
CALCULATE1:
CALL CALCULATE2
JC >L40 ; saut avant vers L40 s'il y a eu ├®chec dans CALCULATE2Notez que INC et DEC ne modifient pas le flag de retenue. Il en va de m├¬me pour les instructions de boucle. Ceci est utile si vous avez une boucle qui doit rendre compte de son r├®sultat en utilisant le flag de retenue, par exemple┬Ā:
.loop
;
CMP ESI, EDI ; est-ce que ESI < EDI ? (flag de retenue ├Ā 1 si oui)
DEC ECX ; voir s'il y a plus de boucles ├Ā ex├®cuter
JNZ .loop ; oui
RET ; retour avec le r├®sultat de CMP ESI,EDI dans le flag de retenueQuelques instructions mettent toujours ├Ā z├®ro le flag de retenue. Il est utile de le savoir pour ├®viter le codage d'un CLC surabondant si vous souhaitez effacer le flag de retenue au terme de ces instructions. Il s'agit de AND, OR et TEST.
Certaines instructions ont une action d├®termin├®e partiellement ou en totalit├® par le flag de retenue┬Ā:
- ADC (addition avec retenue)┬Ā;
- SBB (soustraction avec retenue)┬Ā;
- les sauts conditionnels JC, JNC, JA, JNA, JAE, JNAE, JB, JBE, JNBE, JNB┬Ā;
- les instructions de copie de donn├®e conditionnelle CMOVC, CMOVNC, CMOVA, CMOVNA, CMOVAE, CMOVNAE, CMOVB, CMOVBE, CMOVNBE, CMOVNB.
Le flag de retenue est principalement utilis├® avec les instructions de saut conditionnel JC et JNC en plus de celles mentionn├®es pr├®c├®demment. Par exemple┬Ā:
JC >L10 ; saut avant vers L10 si le flag de retenue est ├Ā 1
JNC L1 ; saut arri├©re vers L1 si le flag de retenue est ├Ā 0VIII-F-1-d. Of - flag de d├®bordement ou flag d'overflow▲
Pour appr├®hender le fonctionnement du flag de d├®bordement (overflow), il est n├®cessaire de bien comprendre la structure des nombres sign├®s. Le flag de d├®bordement est utilis├® pour identifier un ├®ventuel d├®bordement au terme d'une op├®ration effectu├®e sur des nombres sign├®s. Le flag de retenue ne peut pas ├¬tre utilis├® dans ce but ainsi que le montre l'exemple simple ci-dessous┬Ā:
MOV AL, 0FEh ; charge AL avec 254 d├®cimal (non sign├®) ou -2 (sign├®)
ADD AL, 4h ; additionne 4 => AL contient maintenant 2hIci, on constate que le flag de retenue (carry) est mis ├Ā 1 parce que le r├®sultat de 258, interpr├®t├® au sens de l'arithm├®tique non sign├®e, est trop grand au regard de la limite de taille fatidique de 255. Mais, si l'on se place du point de vue de l'arithm├®tique sign├®e, il n'y a pas d├®bordement. La valeur de 2 prise par AL est le r├®sultat de l'addition -2+4. Le flag de d├®bordement est donc ├Ā 0, en toute logique, puisqu'il se d├®termine dans un contexte d'arithm├®tique sign├®e.
Voici un autre exemple o├╣ il y a d├®bordement dans un calcul sign├®┬Ā:
MOV AL, 7Fh ; charge AL avec 127 d├®cimal
ADD AL, 4h ; additionne 4 => AL contient maintenant 83hIci, le flag de retenue est nul parce que le r├®sultat non sign├® 131 (83h) en AL est en de├¦├Ā de la limite de taille de donn├®e de 255. Mais, analys├® dans un contexte d'arithm├®tique sign├®e, il provoque un d├®bordement parce que le r├®sultat se situe au-del├Ā des limites assign├®es de -127 ├Ā +128.
Donc, dans ce type d'op├®ration arithm├®tique le processeur met ├Ā 1 le flag de d├®bordement si le bit de signe change alors qu'il n'y a pas de retenue. Ceci est ind├®pendant du flag de retenue comme on peut le voir dans l'exemple qui suit┬Ā:
MOV AL, 7Fh ; charge AL avec 127 d├®cimal
INC AL ; provoque un d├®passement (retenue non affect├®e par INC)
;
MOV AL, 80h ; charge AL avec -128 decimal
DEC AL ; provoque un d├®passement (retenue non affect├®e par DEC)Dans les instructions de d├®calage binaires et uniquement pour les op├®rations de d├®calage d'un seul bit, le flag de d├®bordement ne donne une indication valide que si le r├®sultat sign├® est trop grand pour la taille des donn├®es. Par exemple┬Ā:
MOV AL, 80h ; AL = -128
SHL AL, 1 ; la multiplication par 2 cause un d├®bordement
MOV AL, 0FEh ; AL = -2
SHL AL, 1 ; la multiplication par 2 (-4) ne cause pas de d├®bordement
MOV AL, 80h ; AL = -128
SHL AL, 2 ; la multiplication par 4 ne signale pas de d├®bordement
MOV AL, 0FEh ; AL = -2
SAR AL, 1 ; la division par 2 (-1) ne provoque pas de d├®bordementSAR est une instruction sp├®ciale de d├®calage binaire ├Ā droite qui a pour effet de maintenir le bon signe dans le r├®sultat. Elle le fait en d├®pla├¦ant ├Ā droite tous les bits sauf celui de plus fort poids qui d├®tient le signe. L'emplacement ainsi lib├®r├® imm├®diatement ├Ā droite du bit de signe est combl├® par une copie de ce m├¬me bit. Dans la mesure o├╣ l'instruction SAR revient ├Ā une division par deux, elle ne peut jamais d├®border.
Fonctionnement de l'instruction SAR (7)
En revanche, SHL est sujette ├Ā cet inconv├®nient et, dans les op├®rations de d├®calage binaire d'un bit, le flag de d├®bordement est positionn├® de mani├©re appropri├®e selon le r├®sultat. Pour y parvenir, le processeur scrute une ├®ventuelle ├®galit├® entre le bit de signe et le flag de retenue et met ├Ā z├®ro le flag de d├®bordement si tel est le cas.
Gr├óce ├Ā ce test, il est possible d'envisager une autre utilisation pour le flag de d├®bordement (notez que ces tests affectent le contenu du registre) ainsi que le montre l'exemple qui suit┬Ā:
SHL AL, 1
JNO >L1 ; saut si les 2 bits de plus fort poids de AL sont les mêmes
SHL AL, 1
JO >L1 ; saut si les 2 bits de plus fort poids de AL sont diff├®rents
SHL EAX, 1
JNO >L1 ; saut si les 2 bits de plus fort poids de EAX sont les mêmes
SHL EAX, 1
JO >L1 ; saut si les 2 bits de plus fort poids de EAX sont diff├®rentsLes instructions de rotation de bits fonctionnent de la m├¬me mani├©re. ├ētant donn├® que l'instruction ROR d├®cale tous les bits vers la droite en rempla├¦ant le bit le plus ├®lev├® par le plus bas, ceci fournit un moyen de comparer le bit de plus fort poids et celui de plus faible poids d'une donn├®e. En voici une illustration (notez que ces tests changent le contenu du registre)┬Ā:
ROR AL, 1
JNO >L1 ; saut si le bit le plus bas et le plus haut de AL sont ├®gaux
ROR AL, 1
JO >L1 ; saut si le bit le plus bas et le plus haut de AL diff├©rent
ROR EAX, 1
JNO >L1 ; saut si le bit le plus bas et le plus haut de EAX sont ├®gaux
ROR EAX, 1
JO >L1 ; saut si le bit le plus bas et le plus haut de EAX diff├©rentL'instruction sp├®ciale IMUL de multiplication sign├®e met ├Ā 1 le flag de d├®bordement si le r├®sultat sign├® est trop grand pour la taille des donn├®es.
Le flag de d├®bordement est principalement utilis├® avec les instructions de saut conditionnel JO et JNO, par exemple┬Ā:
JO >L10 ; saut avant vers L10 si le flag de d├®bordement est ├Ā 1
JNO L1 ; saut arri├©re vers L1 si le flag de d├®bordement est ├Ā 0Les flags JG, JGE, JL, JLE, JNG, JNGE, JNL, JNLE sont ├®galement conditionn├®s par Of mais ce dernier est analys├® conjointement avec Sf. Par exemple┬Ā:
- JNGE (saut court si non plus grand que ou ├®gal) n'est actif que si les flags Of et Sf affichent un ├®tat diff├®rent┬Ā;
- JGE (saut court si plus grand que ou ├®gal) n'est actif que si les flags Of et Sf ont le m├¬me ├®tat.
VIII-F-1-e. Pf - flag de parit├® ou Parity flag▲
Le flag de parit├® indique si la donn├®e trait├®e affiche un nombre de bits ├Ā 1 pair ou impair. Cet indicateur est ├Ā 1 si le nombre de bits ├Ā 1 est pair est ├Ā 0 si ce nombre est impair. Dans les communications s├®rie, le bit de parit├® est utilis├® comme contr├┤le d'erreur ├®l├®mentaire. Parall├©lement ├Ā chaque octet envoy├®, l'├®metteur envoie un bit de parit├® qui indique au r├®cepteur si l'octet qu'il vient d'envoyer est pair ou impair. Le proc├®d├® est trop sommaire pour identifier avec certitude un octet corrompu mais se r├®v├©le n├®anmoins int├®ressant d├©s lors qu'appara├«t une s├®rie d'octets corrompus. Lorsque le contr├┤le de parit├® est utilis├® de cette mani├©re en transmissions s├®rie, il est d'usage, pour chaque octet, d'affecter un bit au contr├┤le de parit├® et les sept autres ├Ā la transmission effective de la donn├®e.
Le flag de parit├® est principalement utilis├® avec les instructions de saut conditionnel JP et JNP, par exemple┬Ā:
JP >L10 ; saut avant vers L10 si le flag de parit├® est ├Ā 1
JNP L1 ; saut arri├©re vers L1 si le flag de parit├® est ├Ā 0VIII-F-1-f. Af - flag auxiliaire ou Auxiliary flag▲
Le flag de retenue auxiliaire est utilis├® en arithm├®tique BCD (Binaire Cod├® D├®cimal). Contrairement aux autres flags, celui-ci n'a strictement aucun effet sur les instructions de saut conditionnel. Au contraire, il ne peut ├¬tre activ├® que par une instruction de calcul BCD, puis lu par l'instruction BCD suivante. L'arithm├®tique BCD est d├®crite dans le volume 2.
VIII-F-1-g. Df - flag de direction ou Direction flag▲
Le flag de direction est tr├©s important car il d├®termine le mode de fonctionnement des instructions de cha├«ne LODS, STOS, MOVS, SCAS, CMPS, INS et OUTS. Ces instructions utilisent en effet, s├®par├®ment ou conjointement, le registre d'index (E)SI/RSI(8) pour pointer la donn├®e source (SI = Source Index) et son homologue (E)DI/RDI pour pointer la donn├®e destination (DI = Destination Index).
Or ces registres d'index sont incr├®ment├®s ou d├®cr├®ment├®s automatiquement au terme de l'ex├®cution des instructions pr├®cit├®es de mani├©re ├Ā ├¬tre pr├¬ts ├Ā traiter la donn├®e suivante. C'est ici qu'intervient le flag de direction Df┬Ā:
- Df = 1, les registres d'index sont d├®cr├®ment├®s┬Ā;
- Df = 0, les registres d'index sont incr├®ment├®s.
Deux instructions permettent de positionner ce flag┬Ā:
- CLD (CLear Direction)ŌåÆ Df = 0 ŌåÆ le(s) registre(s) d'index sont incr├®ment├®s┬Ā;
- STD (SeT Direction)ŌåÆ Df = 0 ŌåÆ le(s) registre(s) d'index sont incr├®ment├®s.
Deux exemples mettant en ┼ōuvre REP MOVSB permettront de mieux comprendre ce m├®canisme┬Ā:
DATA SECTION
msg1 DB 'on incr├®mente !'
msg2 DB 'on d├®cr├®mente !'
msg1b DB 15 dup 0
msg2b DB 15 dup 0
CODE SECTION
START:
CLD ; incr├®mentation automatique des adresses
MOV ESI, ADDR msg1 ; ESI pointe msg1
MOV EDI, ADDR msg1b ; EDI pointe msg1b
MOV ECX, 15 ; nombre de caract├©res ├Ā copier
REP MOVSB ; apr├©s cette op├®ration :
; msg1b = 'on incr├®mente !'
; ECX = 0, ESI = ADDR msg1+15, ESI = ADDR msg1b+15
STD ; d├®cr├®mentation automatique des adresses
MOV ESI, ADDR msg2+14 ; ESI pointe le dernier caract├©re de msg2
MOV EDI, ADDR msg2b ; EDI pointe le dernier caract├©re de msg2b
MOV ECX, 15 ; nombre de caract├©res ├Ā copier
REP MOVSB ; apr├©s cette op├®ration :
; msg1b = 'on incr├®mente !'
; ECX = 0, ESI = ADDR msg2-1, ESI = ADDR msg2b-1
XOR EAX, EAX
RETVIII-F-2. Les sauts conditionnels ▲
En raison de la cohabitation de l'arithm├®tique sign├®e et non sign├®e, la qualification de la comparaison de deux grandeurs peut poser quelques probl├©mes si elle n'est pas encadr├®e par un vocabulaire pr├®cis. Nous utiliserons donc, dans ce manuel, la convention de traduction suivante┬Ā:
| Arithm├®tique NON sign├®e | Arithm├®tique sign├®e | |||
| Symbole | < | > | < | > |
| En fran├¦ais | Inf├®rieur ├Ā | Sup├®rieur ├Ā | Plus petit que | Plus grand que |
| En anglais | Below than | Above than | Less then | Greater than |
On rappelle ici la signification de la repr├®sentation abr├®g├®e des flags┬Ā:
|
|
VIII-F-2-a. Les instructions de saut conditionnel NON sign├®es▲
| Instruction | Alternative | Action |
| JZ | JE | Saut si Zf = 1 (saut si ├®gal) |
| JNZ | JNE | Saut si Zf = 0 (saut si non ├®gal) |
| JC | JB ou JNAE | Saut si Cf = 1 (saut si ┬½┬Āinf├®rieur ├Ā┬Ā┬╗ ou ┬½┬Ānon sup├®rieur ├Ā┬Ā┬╗ ou ┬½┬Ā├®gal┬Ā┬╗) |
| JNC | JNB ou JAE | Saut si Cf = 0 (saut si ┬½┬Ānon inf├®rieur ├Ā┬Ā┬╗ ou ┬½┬Āsup├®rieur ├Ā┬Ā┬╗ ou ┬½┬Ā├®gal┬Ā┬╗) |
| JA | JNBE | Saut si ni Cf, ni Zf ne sont ├Ā 1 (i.e. saut si ┬½┬Āsup├®rieur ├Ā┬Ā┬╗ ou si ┬½┬Ānon inf├®reur ├Ā┬Ā┬╗ ou ┬½┬Ā├®gal┬Ā┬╗). Voir la note concernant JNA ci-dessous. |
| JNA | JBE |
Saut si soit Cf, soit Zf = 1 (c'est-├Ā-dire si saut ┬½┬Ānon sup├®rieur ├Ā┬Ā┬╗ ou si ┬½┬Āinf├®rieur ├Ā┬Ā┬╗ ou ┬½┬Ā├®gal┬Ā┬╗). Ceci est utile pour v├®rifier apr├©s une soustraction qu'un registre reste sup├®rieur ├Ā 1. Par exemple, vous pourriez utiliser ceci dans le codage de protection qui suit dans lequel il est suppos├® que EDI pointe la fin d'une cha├«ne dans BUFFER┬Ā: MOV EDX, BUFFER SUB EDI, EDX ┬Ā; r├®cup├©re la longueur de cha├«ne dans EDI JNA >.error ┬Ā; la longueur est trouv├®e n├®gative ou nulle |
| JP | ┬Ā | Saut si Pf = 1 |
| JNP | ┬Ā | Saut si Pf = 0 |
| JECXZ | ┬Ā | Saut si ECX = 0 |
| JCXZ | ┬Ā | Saut si CX = 0 |
VIII-F-2-b. Les instructions de saut conditionnel sign├®es▲
| Instruction | Alternative | Action |
| JS | ┬Ā | Saut si Sf = 1 (saut si le signe du nombre est n├®gatif) |
| JNS | ┬Ā | Saut si Sf = 0 (saut si si le signe du nombre est positif) |
| JO | ┬Ā | Saut si Of = 1 (d├®passement ├Ā l'issue d'une op├®ration) |
| JNO | ┬Ā | Saut si Of = 0 (pas de d├®passement ├Ā l'issue d'une op├®ration) |
| JL | JNGE | Saut si Sf et Of sont diff├®rents (saut si ┬½┬Āplus petit que┬Ā┬╗ ou ┬½┬Ānon plus grand que┬Ā┬╗ ou ┬½┬Ā├®gal┬Ā┬╗). Ce test sp├®cial est n├®cessaire pour les nombres consid├®r├®s comme sign├®s parce que JA (saut si ┬½┬Āsup├®rieur ├Ā┬Ā┬╗) et JB (saut si ┬½┬Āinf├®rieur ├Ā┬Ā┬╗) ne travaillent pas avec ces nombres. Par exemple, si AL est ├Ā 1, alors une instruction JB plac├®e imm├®diatement apr├©s CMP AL, -1 n'effectuera pas de saut puisque Cf = 0. En revanche, JL effectuera ce saut parce que, justement, Cf = 0 et qu'il agit en arithm├®tique sign├®e, consid├®rant que -1 est plus petit que 1. |
| JNL | JGE | Saut si Sf et Of sont ├®gaux (saut si ┬½┬Ānon plus petit que┬Ā┬╗ ou ┬½┬Āplus grand que ou ├®gal┬Ā┬╗). Voir la note ci-dessus concernant JL. |
| JLE | JNG | Saut si Sf et Of sont diff├®rents et que ZF = 1 (saut si ┬½┬Āplus petit que ou ├®gal┬Ā┬╗ ou ┬½┬Ānon plus grand que┬Ā┬╗) |
| JLNE | JG | Saut si Sf et Of sont ├®gaux et que Zf = 0 (saut si ┬½┬Ānon plus petit que ou ├®gal┬Ā┬╗ ou ┬½┬Āplus grand que┬Ā┬╗) |
VIII-F-3. Instructions CMOVcc et SET cc▲
Pass├®es les am├®liorations classiques telles que l'augmentation de la vitesse d'horloge et du parall├®lisme des op├®rations, les fondeurs de processeurs ont introduit des am├®liorations beaucoup plus subtiles o├╣ la vitesse d'ex├®cution est subordonn├®e ├Ā un ensemble de petites actions de nature parfois assez complexes, le tout assorti de m├®moires-cache, de multithreading et autres concepts tout aussi ├®tranges. Bref, il existe d├®sormais, pour chaque famille de processeurs, de v├®ritables ┬½┬Āpav├®s┬Ā┬╗ souvent plut├┤t bien faits, si l'on se limite ├Ā Intel et AMD, qui d├®taillent les multiples ┬½┬Ārecettes┬Ā┬╗ que se doit de conna├«tre d├®sormais tout programmeur soucieux de produire des applications hautement optimis├®es.
Un focus particuler est fait notamment dans ces ouvrages sur les branchements. D'une mani├©re g├®n├®rale, il est recommand├® d'en faire aussi peu usage que possible et, en tout ├®tat de cause, de les limiter ├Ā trois - voire moins - par fen├¬tre de code de 16 octets cons├®cutifs. Fort heureusement, deux instructions ont ├®t├® introduites dans ce but et nous verrons qu'elles permettent de supprimer de nombreux sauts jug├®s incontournables jusqu'ici.
VIII-F-4. Les instructions CMOVcc▲
Plut├┤t que de r├®aliser un MOV dans le cadre d'un branchement conditionnel, une nouvelle instruction baptis├®e CMOV pour la circonstance - Conditionnal MOVe -, propose un MOV dont l'ex├®cution est subordonn├®e ├Ā l'├®tat des flags selon l'exacte grille de lecture qu'en font les sauts conditionnels.
On trouve de la sorte┬Ā: CMOVA, CMOVAE, CMOVNA, CMOVNAE, CMOVB, CMOVBE, CMOVNB, CMOVNBE, CMOVC, CMOVNC, CMOVE, CMOVNE, CMOVG, CMOVGE, CMOVNG, CMOVNGE, CMOVL, CMOVLE, CMOVNL, CMOVNLE, CMOVO, CMOVNO, CMOVP, CMOVPE, CMOVNP, CMOVS, CMOVNS, CMOVZ, CMOVNZ, CMOVPO.
Sur le plan s├®mantique, le mn├®monique r├®sulte de la contraction de MOV et Jcc, le J ├®tant ├®limin├®. Il est de la forme┬Ā: CMOVcc dest, srce.
Par exemple┬Ā: CMOVA EAX, EBX signifie que le contenu du registre EBX est copi├® dans EAX si, et seulement si, les flags ont un ├®tat tel qu'un branchement conditionnel JA pourrait ├¬tre activ├® dans cette situation.
Voici maintenant deux exemples qui montrent comment supprimer un saut conditionnel avec un MOV┬Ā:
| 1┬░ exemple | 2┬░ exemple |
|
Avant optimisation TEST ECX, ECX┬Ā; on teste ECX = 0 JNZ Suite ┬Ā; saut vers Suite si ECX ŌēĀ 0 MOV EAX, EBX ┬Ā; EAX = EBX si ECX = 0 ; Ōü× Suite: |
Avant optimisation CMP ECX, 5┬Ā; on teste ECX > 5 JB Suite ┬Ā; saut vers Suite si ECX < 5 MOV ECX, 5┬Ā; ECX est limit├® ├Ā 5 ; Ōü× Suite: |
|
Apr├©s optimisation TEST ECX, ECX ┬Ā; on teste ECX = 0 CMOVZ EAX, EBX┬Ā; r├®alise le MOV si le flag ; Zf est ├®gal ├Ā 1. Le label ; Suite peut ├¬tre supprim├®. |
Apr├©s optimisation CMP ECX, 5 ┬Ā; on teste ECX > 5 CMOVA ECX, 5┬Ā; ECX est plafonn├® ├Ā 5 |
VIII-F-5. Les instructions SETcc▲
Elles sont de la forme SETcc dest et ont pour particularit├® de mettre l'op├®rande destination ├Ā 0 ou 1 selon le positionnement des flags d'├®tat. Cet op├®rande est constitu├® d'un octet qui peut ├¬tre un registre ou une adresse m├®moire. Le positionnement op├®r├® par cette instruction est strictement de m├¬me nature que le mode de branchement effectu├® par les sauts conditionnels dont il emprunte la forme.
D'un point de vue s├®mantique, le mn├®monique r├®sulte de la contraction de SET et Jcc, le J ├®tant ├®limin├®.
De m├¬me que pour CMOVcc, on trouve┬Ā: SETA, SETAE, SETNA, SETNAE, SETB, SETBE, SETNB, SETNBE, SETC, SETNC, SETE, SETNE, SETG, SETGE, SETNG, SETNGE, SETL, SETLE, SETNL, SETNLE, SETO, SETNO, SETP, SETPE, SETNP, SETS, SETNS, SETZ, SETNZ, SETPO.
Par exemple, dans┬Ā:
CMP EAX ,12
SETE DL ; implique DL = 1 si EAX = 12 (sinon DL = 0)
SETAE DL ; implique DL = 0 si EAX = 10 (sinon DL = 1)Par rapport ├Ā CMOVcc, on peut remarquer que l'instruction SETcc a la particularit├® de f├®d├®rer sur un seul bit - celui de plus faible poids de la destination - tout r├®sultat de comparaison.
Voici un exemple de suppression de saut r├®alis├®e avec SETcc┬Ā:
├ēcriture traditionnelle avec des sauts conditionnels┬Ā:
XOR EBX, EBX ; EBX = 0
CMP EAX, 10 ; est-ce que EAX > 10 ?
JBE InfEgal ; saut ├Ā InfEgal si EAX Ōēż 10
MOV EBX, 115 ; EBX = 115 si EAX > 10
JMP Superieur ; vers fin du calcul
InfEgal:
MOV EBX, 110 ; EBX = 110 si EAX Ōēż 10
Superieur: ; EBX = 115 si EAX > 10Suppression du saut par introduction de SETcc ┬Ā:
XOR EBX, EBX ; EBX = 0
CMP EAX, 10 ; est-ce que EAX > 10 ?
SETBE BL ; BL = 1 si EAX Ōēż 10
; BL = 0 si EAX > 10
SUB EBX, 1 ; EBX = 11...11 ou 00...00 selon le contenu de BL
AND EBX, 5 ; 115-110
ADD EBX, 110 ; EBX = 110 ou 115On voit ici que tous les sauts ont ├®t├® supprim├®s.
VIII-G. Pour les d├®butantsŌĆ” en Windows▲
Cet article est destin├® ├Ā ceux qui d├®butent en programmation sous Windows.
Il d├®crit les ├®l├®ments du syst├©me d'exploitation Windows qu'il est essentiel de conna├«tre avant de pouvoir ├®crire un programme significatif. Bien s├╗r, Windows est bien plus volumineux que ce qui est d├®crit ici, et vous aurez besoin de beaucoup plus d'informations avant de pouvoir ├®crire des programmes.
VIII-G-1. Windows - La mise sous contr├┤leŌĆ”▲
Windows prend le contr├┤le de l'ordinateur presque totalement d├©s le moment o├╣ l'on met en route ce dernier et ce, jusqu'├Ā ce qu'on l'├®teigne. Une application ne peut donc s'ex├®cuter qu'avec l'autorisation et l'aide de Windows et sous son contr├┤le. D├©s lors, Windows peut assister l'utilisateur avec l'ergonomie et les performances attrayantes qu'on lui conna├«t┬Ā: pr├®visibilit├® et coh├®rence de l'interface utilisateur, aptitude (en apparence tout au moins) ├Ā ex├®cuter plusieurs programmes ├Ā la fois (multit├óches) et robustesse du syst├©me en cas d'├®chec d'une application.
VIII-G-1-a. ŌĆ” du mat├®riel▲
La plupart des micropuces qui fonctionnent avec l'unit├® centrale de traitement sont programmables. Par exemple, la carte d'affichage a besoin de conna├«tre les bonnes vitesse de balayage, r├®solution et couleurs. Les circuits d'entr├®e/sortie de l'imprimante doivent conna├«tre le port imprimante ├Ā utiliser et la vitesse ├Ā laquelle les donn├®es doivent ├¬tre transf├®r├®es. Les puces int├®gr├®es au clavier doivent conna├«tre le taux de r├®p├®tition ├Ā utiliser. La communication r├®elle avec ces p├®riph├®riques doit ├¬tre contr├┤l├®e - chacun aura sa propre zone de m├®moire ├Ā utiliser et devra savoir ├Ā quoi s'attendre et quand. Windows ex├®cute toutes les t├óches de base que vous attendez normalement d'un syst├©me d'exploitation. Vous, le programmeur d'application, pouvez alors vous concentrer sur le travail r├®ellement cr├®atif.
Mais Windows prend ├®galement le contr├┤le total de la lecture/├®criture avec tous les composants externes. Ceci pr├®sente des avantages importants pour le programmeur de l'application.
Par exemple, pour imprimer un document, l'application peut se borner ├Ā indiquer ├Ā Windows l'endroit o├╣ le document r├®side en m├®moire ainsi que sa taille. Windows prendra les dispositions pour qu'il soit imprim├®, en utilisant le pilote d'imprimante appropri├® pour l'imprimante en cours d'utilisation, et en le mettant dans la bonne position dans la file d'attente d'imprimante, laquelle pourrait ├®galement contenir d'autres travaux d'impression provenant d'autres applications. Le travail d'impression est toujours effectu├® en mode graphique. Windows indique ├Ā l'imprimante l'emplacement exact o├╣ chaque point constituant l'image finale imprim├®e doit aller sur le papier. Les avantages pour le programmeur d'applications sont tr├©s importants. Il est lib├®r├® de la t├óche fastidieuse de fournir des pilotes d'imprimante ├Ā son application et d'├®crire des algorithmes graphiques. Il peut ┬½┬Āpenser graphique┬Ā┬╗ d├©s le d├®part sans avoir ├Ā se soucier des complications qui en d├®coulent.
Windows r├®alise un travail encore plus sophistiqu├® avec l'affichage ├Ā l'├®cran, qui est ├®galement en mode graphique. Ici, Windows doit souvent faire face ├Ā plusieurs applications essayant d'afficher simultan├®ment leur sortie sur l'├®cran. Il peut y avoir plusieurs fen├¬tres ├Ā tout moment, et pour l'utilisateur, certaines d'entre elles semblent se chevaucher de sorte que certaines informations sont invisibles. Windows a la lourde responsabilit├® de la construction de l'image finale de l'├®cran en arbitrant entre ces diff├®rentes sorties d'application qui revendiquent, ├Ā juste titre, le droit d'appara├«tre sur l'├®cran. Il le fait ├Ā partir de l'enregistrement actualis├® de chaque fen├¬tre et de sa connaissance de la priorit├®, de l'ordre de l'├®cran, du type et du style de chaque fen├¬tre. Une grande partie de votre travail de programmation impliquera de d├®finir correctement ces facteurs dans votre propre programme pour garantir que Windows produise la sortie d'├®cran correcte.
Le corollaire au contr├┤le que Windows exerce sur le mat├®riel p├®riph├®rique est qu'une application ne peut pas (ou du moins ne devrait pas) acc├®der directement aux p├®riph├®riques. Mais cela ne pr├®sente g├®n├®ralement aucun inconv├®nient puisque d'une part, Windows se caract├®rise par une grande polyvalence, d'autre part les ordinateurs modernes accomplissent la plupart des t├óches ├Ā une vitesse satisfaisante.
VIII-G-1-b. ŌĆ” de toutes les applications▲
Que se passe-t-il lorsque l'utilisateur clique sur l'ic├┤ne repr├®sentant votre programme avec la souris┬Ā? Tout d'abord, Windows sait exactement o├╣ la souris a ├®t├® cliqu├®e et quelle ic├┤ne ├®tait dans le champ du pointeur de la souris (curseur) ├Ā ce moment. Il sait aussi, d'apr├©s ses listes de ┬½┬Āraccourcis┬Ā┬╗ et de ┬½┬Āpropri├®t├®s┬Ā┬╗, quel programme d├®marrer si cette ic├┤ne particuli├©re est cliqu├®e.
Comment le programme est-il lanc├® ├Ā partir de cette action┬Ā? Windows commence par charger le programme en lisant le fichier correspondant puis l'installe en m├®moire vive. Enfin, Windows appelle tout simplement le programme. Autrement dit, le processeur est invit├® ├Ā poursuivre l'ex├®cution ├Ā partir de l'adresse du point d'entr├®e du programme. En cons├®quence, la fa├¦on la plus simple pour le programme de s'achever consiste ├Ā retourner au syst├©me avec une banale instruction RET.
VIII-G-1-c. ŌĆ” du microprocesseur▲
Comme nous l'avons vu pr├®c├®demment, pour d├®marrer le programme, le registre EIP du processeur re├¦oit l'adresse du point d'entr├®e par Windows. Windows a ├®galement un contr├┤le sur la valeur de tous les autres registres du processeur. Windows conserve ceux-ci en m├®moire dans une zone de m├®moire appel├®e contexte de registre (register context). Windows peut (et ne se g├¬ne pas pour y recourir souvent), arr├¬ter le processeur, m├®moriser la valeur courante des registres, et enfin charger le processeur avec d'autres donn├®es pour ex├®cuter un autre programme ├Ā la place pendant un certain temps. Si bien que cet autre programme se voit affecter une tranche de temps par Windows. Une fois termin├®e, Windows peut alors restaurer les registres dans votre programme qui reprend alors l'ex├®cution ├Ā partir de l├Ā o├╣ elle avait ├®t├® interrompue, car il y avait alors une tranche de temps.
Nous venons de toucher du doigt la mani├©re dont fonctionne le multit├óche sous Windows. Chaque programme en cours d'ex├®cution dans le syst├©me se voit affecter une part de temps processeur. L'utilisateur peut avoir ainsi l'impression que plusieurs programmes s'ex├®cutent simultan├®ment alors que ce n'est que du temps partag├® s├®quentiel, s'agissant d'ordinateurs ├Ā processeur unique. Windows d├®termine la longueur de la tranche de temps en fonction de diff├®rentes priorit├®s. Par exemple, une op├®ration de lecture/├®criture de disque se verra normalement attribuer une priorit├® tr├©s ├®lev├®e et pourra m├¬me emp├¬cher d'autres programmes de s'ex├®cuter jusqu'├Ā ce que l'op├®ration soit termin├®e.
Un programme peut demander ├Ā Windows de d├®marrer un autre thread. Windows va alors attribuer ├Ā ce thread ses propres tranches de temps ainsi que ses propres valeurs de registres et de pile. Le nouveau thread donnera l'impression de s'ex├®cuter en m├¬me temps que le thread principal du programme. Ceci est utile si un programme doit se poursuivre avec une seule activit├® (par exemple un long calcul) tout en continuant ├Ā dialoguer avec l'utilisateur. Le programme peut donc appara├«tre ├Ā l'utilisateur comme ex├®cutant deux ou plusieurs choses ├Ā la fois.
C'est ce qu'on appelle le multithreading.
VIII-G-1-d. ŌĆ” de la m├®moire et des donn├®es▲
Votre programme peut faire beaucoup plus que simplement manipuler des donn├®es dans les registres du processeur. ├Ć tout moment, votre programme aura ses propres donn├®es en m├®moire. Celles-ci seront soit dans la m├®moire ├®tablie pour l'adressage direct, soit sur la pile. Alors, comment Windows pr├®serve-t-il ces donn├®es lors de la commutation de tranche de temps entre les programmes┬Ā?
La r├®ponse est que Windows conserve une carte m├®moire de toutes les donn├®es du programme. Cela veut dire qu'il sait exactement o├╣, dans la m├®moire physique de l'ordinateur, les donn├®es du programme sont maintenues ├Ā tout moment. Windows conserve cette carte de m├®moire dans une zone appel├®e m├®moire de contexte. Si la m├®moire physique est ├®puis├®e, Windows va utiliser le disque dur pour conserver, si n├®cessaire, les donn├®es du programme. C'est la raison pour laquelle, dans les syst├©mes disposant de faibles ressources en m├®moire, il y a beaucoup plus d'activit├® du disque que dans les syst├©mes mieux pourvus en m├®moire.
Lorsque le programme a besoin d'acc├®der ├Ā ses donn├®es, il doit le faire en utilisant une adresse virtuelle. Cela signifie que l'adresse de la zone m├®moire ne correspond pas, en fait, ├Ā l'adresse r├®elle des donn├®es dans la m├®moire physique. Windows informe le processeur du lieu dans lequel se situent les zones de m├®moire n├®cessaires. Il le fait en donnant au processeur, dans le registre CR3, l'adresse de sa table de r├®partition des pages correspondant au programme.
VIII-G-1-e. ŌĆ” de l'interface utilisateur▲
La principale raison pour laquelle Windows a ├®t├® d├®velopp├® ├®tait, en premier lieu, de fournir une interface coh├®rente et compr├®hensible ├Ā l'utilisateur. L'id├®e ├®tait que ce dernier puisse se d├®placer sans difficult├® d'un ordinateur ├Ā un autre, une fois familiaris├® avec le syst├©me d'exploitation Windows. Plus important pour le programmeur Windows, chaque application interagirait avec l'utilisateur de mani├©re similaire et selon une disposition famili├©re. Par cons├®quent, les utilisateurs auraient un bon point de d├®part pour d├®velopper un nouveau programme, ce qui r├®duirait la formation et le temps d'apprentissage de fa├¦on spectaculaire. Ces objectifs ont ├®t├® atteints avec un grand succ├©s, et il y a maintenant des millions d'utilisateurs d'ordinateurs dans le monde entier utilisant des applications Windows qui tra├«naient initialement une r├®putation d'┬½┬Āanalphab├©te informatique┬Ā┬╗.
Windows a atteint cette uniformit├® en proposant des applications avec des composants standard ├Ā inclure dans leurs programmes. Les exemples les plus ├®vidents sont les menus qui apparaissent juste sous la barre de titre d'une application, les bo├«tes de dialogue o├╣ l'utilisateur peut faire des choix, les boutons avec texte que l'utilisateur peut cliquer, les barres de d├®filement pour d├®placer le contenu d'une fen├¬tre vers le haut ou vers le bas, les boutons de la barre d'outils contenant de petites images et les fichiers d'aide standardis├®s.
Ces composants standard sont collectivement regroup├®s sous l'appellation ┬½┬ĀGraphical User Interface┬Ā┬╗ (interface graphique) ou, plus simplement, GUI.
Comment une application les utilise-t-elle┬Ā? Par appel d'une ┬½┬ĀApplication Programming Interface┬Ā┬╗ ou API. Il s'agit de proc├®dures propos├®es par Windows qui peuvent ├¬tre appel├®es par votre programme au moyen d'un nom sp├®cifique. Toutes les API sont contenues dans des fichiers nomm├®s Dynamic Link Libraries ou DLL. Ces derni├©res sont des fichiers ex├®cutables pourvus de l'extension Dll. Vous en verrez beaucoup dans le r├®pertoire Windows\System sur votre ordinateur. Elles contiennent du code pour l'export, c'est-├Ā-dire que ce code est disponible pour ├¬tre import├® dans votre programme lorsque vous souhaitez utiliser l'interface graphique Windows.
VIII-G-1-f. ŌĆ” et des fichiers▲
Les DLL sont constamment r├®vis├®es par les d├®veloppeurs de Windows qui ajoutent de nouvelles API ou modifient les existantes. Elles sont distribu├®es ├Ā l'utilisateur de diverses mani├©res, parfois dans un service pack Windows, ou lorsque vous chargez la nouvelle version d'un programme Microsoft (la m├®thode pr├®f├®r├®e a ├®t├® d'inclure de nouvelles versions des DLL via Internet Explorer). L'utilisateur peut ne pas r├®aliser ce qui se passe, et pour vous, en tant que programmeur, cela ne fait aucune diff├®rence. Votre programme continuera toujours ├Ā appeler la m├¬me API pour faire la m├¬me chose, mais il pourrait ├®ventuellement le faire de mani├©re l├®g├©rement diff├®rente.
Windows conserve trace de la localisation de tous les fichiers qui sont importants pour son propre fonctionnement ou pour le pilotage des p├®riph├®riques. Lorsque votre programme est install├®, Windows impose que cette action produise un enregistrement appropri├® dans la base de registre, qui est une base de donn├®es maintenue par Windows sur la configuration du syst├©me et des applications qui se d├®roulent sous son contr├┤le. Windows n├®cessite ├®galement qu'une application au comportement irr├®prochable place les fichiers supportant une nouvelle application dans des r├®pertoires correctement nomm├®s de sorte qu'ils soient plus rapides et plus faciles ├Ā trouver. Ce travail est d├®volu ├Ā un programme d'installation, qui est g├®n├®ralement livr├® avec le programme et intitul├® Setup.exe.
VIII-G-2. Syst├©me - communication de l'application▲
Comme nous l'avons vu plus haut, le syst├©me Windows contr├┤le tous les aspects importants de l'ordinateur ainsi que les applications en cours d'ex├®cution ├Ā un moment donn├®. Pour atteindre ce niveau de contr├┤le, un syst├©me de communication entre le syst├©me et l'application est indispensable.
Une application voudra communiquer avec le syst├©me quand elle aura besoin de savoir quelque chose ├Ā propos de l'interface graphique, par exemple la taille d'une fen├¬tre particuli├©re ou celle d'une cha├«ne de texte particuli├©re dans une police sp├®cifique. Aussi, quand une application souhaite utiliser les fonctionnalit├®s d'une API, doit-elle ├¬tre en mesure de dire tr├©s pr├®cis├®ment ├Ā l'API comment fonctionner.
Les m├®thodes habituelles de notification de l'application au syst├©me sont les suivantes.
- Donn├®es sur la pile. Avant de faire un appel d'API, vous poussez les donn├®es n├®cessaires sur la pile (PUSH) ├Ā destination de l'API pour son usage. Les donn├®es sont toujours des valeurs num├®riques au format DWord, mais peuvent souvent ├¬tre des pointeurs vers des structures contenant plus de donn├®es, ou des cha├«nes de texte.
- Messages. Vous envoyez un message au syst├©me en appelant l'API SendMessage. Le message lui-m├¬me se r├®duit en fait ├Ā une valeur num├®rique au format DWord pouss├®e sur la pile, mais vous pouvez ├®galement envoyer jusqu'├Ā trois DWords de donn├®es avec le message.
Le syst├©me va vouloir communiquer avec l'application pour lui donner les r├®sultats d'un appel d'API, ou pour l'informer que quelque chose se passe dans l'interface graphique (GUI) ou que quelque chose d'important se passe dans le syst├©me lui-m├¬me.
Les m├®thodes habituelles de communication ├Ā partir du syst├©me vers l'application sont les suivantes.
- Au retour d'une API, le syst├©me d├®pose habituellement une valeur dans le registre EAX donnant le r├®sultat de l'appel d'API.
- Parfois, au retour d'une API, le syst├©me laisse des donn├®es dans la m├®moire ├Ā un emplacement sp├®cifi├® par le programme lors de l'appel de cette API. Cet emplacement peut, par exemple, avoir ├®t├® sp├®cifi├® par l'application au moyen d'un PUSH de pointeur sur la pile avant l'appel de l'API.
- Messages ├Ā l'application┬Ā: ils sont ├®mis par le syst├©me lorsqu'il appelle l'application. Lorsque cela se produit, le syst├©me envoie ├®galement des donn├®es sur la pile. L'application aura pr├®alablement inform├® le syst├©me de l'adresse, dans son code, d'une proc├®dure o├╣ ces appels peuvent ├¬tre faits en pr├®vison d'un traitement. Cette proc├®dure, tr├©s importante est nomm├®e le plus souvent callback, proc├®dure de fen├¬tre ou, plus simplement, WndProc.
VIII-G-3. Handles et contextes de p├®riph├®riques▲
Tous les ┬½┬Āobjets┬Ā┬╗ avec lesquels Windows travaille ont des handles. Ces objets peuvent ├¬tre des fen├¬tres, des contr├┤les, des menus, des dialogues, des processus, des threads, des zones m├®moire, des ├®crans, des imprimantes, des fichiers, des disques durs, et m├¬me des polices, des pinceaux et crayons utilis├®s pour le dessin et l'├®criture. Un handle est une valeur DWord que l'application demande ├Ā Windows. L'application utilisera le handle lorsqu'elle voudra communiquer avec Windows pour utiliser ou modifier l'objet concern├®.
Tous les appareils qui affichent ou, plus g├®n├®ralement, produisent une sortie ont des contextes de p├®riph├®riques. Le contexte de p├®riph├®rique est une zone de m├®moire entretenue par Windows qui contient des informations sur la fa├¦on dont l'appareil doit afficher sa sortie. Ainsi, une fen├¬tre particuli├©re aura-t-elle un contexte de p├®riph├®rique qui contient des informations sur la police qui doit ├¬tre utilis├®e dans la fen├¬tre et la couleur dans laquelle tout dessin ou ├®criture devront appara├«tre dans ladite fen├¬tre. Pour sa part, une imprimante aura un contexte de p├®riph├®rique contenant des informations sur les capacit├®s de l'imprimante, la taille du papier, les couleurs disponibles et ainsi de suite.
VIII-G-4. Les types d'ex├®cutables▲
Un ┬½┬Āex├®cutable┬Ā┬╗ est un fichier qui contient un code qui peut ├¬tre ex├®cut├® par le processeur. Int├®ressons-nous, dans l'imm├®diat, ├Ā deux d'entre eux┬Ā; ceux qui ont l'extension de fichier exe (une application) et ceux avec l'extension dll (biblioth├©que de liens dynamiques).
Pour pouvoir ├¬tre qualifi├® d'ex├®cutable Windows, le fichier doit ├¬tre en format PE (Portable Executable). Comme son nom l'indique, ce type de fichier est destin├® ├Ā ├¬tre portable entre diff├®rentes plateformes, de sorte qu'il puisse fonctionner sur un ordinateur ├®quip├® indiff├®remment avec un processeur Intel, AMD, MIPS, Alpha, Powerpc, ou RISC, par exemple, et ├Ā condition bien s├╗r que le syst├©me d'exploitation Windows soit charg├® et que le fichier PE soit dans sa version correcte pour ces processeurs.
Windows sait que l'ex├®cutable est un fichier PE parce que la signature ┬½┬ĀPE┬Ā┬╗ appara├«t d├©s le d├®but du fichier. Un fichier non PE, par exemple un ex├®cutable DOS, n'a pas cette signature et Windows peut alors prendre toutes dispositions appropri├®es pour son ex├®cution.
Une DLL est utilis├®e si son code ou ses donn├®es doivent ├¬tre partag├®s par plusieurs applications. Windows utilise les DLL pour stocker le code de ses API. La DLL est alors r├®put├®e avoir des exports. Cela r├®duit consid├®rablement la taille de l'Exe individuel, car on sait d├©s lors que le code sera disponible dans une DLL et utilisable en tant que tel par l'Exe. L'un des champs importants du fichier PE est pr├®cis├®ment la liste des imports. Il s'agit d'une liste de fonctions sur lesquelles l'Exe repose et qu'il peut avoir besoin d'appeler pendant son fonctionnement. Cette liste d├®tient ├®galement le nom de la DLL contenant la fonction. Lors du chargement du Exe, Windows v├®rifie que toutes les fonctions et DLL sont disponibles. Sinon, il ne lance pas le programme. Vous pouvez tester vous-m├¬me cette situation en essayant de lancer un programme destin├® uniquement ├Ā Windows NT sur Windows 98. Il y a des chances pour que quelques-unes des fonctions ou DLL soient absentes. Cela peut ├®galement se produire si votre application appelle une API qui est disponible uniquement dans des versions ult├®rieures de Windows.
Vous pouvez ├®viter ce genre de probl├©me, soit en fournissant diff├®rentes versions de votre programme ex├®cutable sp├®cialis├®es selon les versions de Windows potentiellement en possession des utilisateurs, soit en programmant de telle sorte que l'API appropri├®e soit appel├®e lors de l'ex├®cution en fonction de la version Windows install├®e. L'identification de la version du Windows r├®sident peut ├¬tre obtenue au moyen de l'API GetVersionEx. Fort de cette information, vous pouvez alors appeler l'API qui convient ├Ā cette version du syst├©me d'exploitation. Vous devez veiller ├Ā ne pas appeler l'API de la mani├©re habituelle, sinon elle appara├«t dans la liste des imports, ce qui pourrait arr├¬ter votre programme en cours d'ex├®cution d├©s le d├®but. Au lieu de cela, r├®alisez cet appel en utilisant les API LoadLibrary (qui charge la DLL concern├®e si ce n'est pas d├®j├Ā le cas) et GetProcAddress (qui trouve l'adresse de l'API concern├®e dans la DLL).
Tout comme Windows utilise des DLL, vous pouvez ├®galement ├®crire de tels modules, g├®n├®ralement pour les exp├®dier avec le programme que vous avez d├®cid├® de diffuser. Vous pouvez proc├®der ainsi si vous exp├®diez plus d'un programme et que la DLL d├®tient du code ou des donn├®es partag├®s. Vous pourriez ├®galement recourir ├Ā une DLL ├Ā seule fin de r├®duire la taille des in├®vitables mises ├Ā jour. Dans ce cas, au lieu de mettre ├Ā jour l'ensemble du fichier Exe, vous n'auriez affaire qu'aux ├®l├®ments susceptibles d'├¬tre mis ├Ā jour r├®guli├©rement dans une DLL.
VIII-H. Pour les d├®butantsŌĆ” en d├®bogage symbolique▲
Je ne saurais trop vous recommander d'apprendre ├Ā utiliser un d├®bogueur. Si vos programmes franchissent victorieusement l'├®tape de l'assemblage et de l'├®dition de liens, mais refusent pour autant de fonctionner, vous resterez dans un brouillard opaque quant ├Ā la raison de cette situation jusqu'├Ā ce que vous vous d├®cidiez ├Ā placer vos programmes d├®faillants sous le contr├┤le du d├®bogueur. Souvent, une session de d├®bogage affichera l'erreur instantan├®ment et pourra vous ├®pargner un temps fastidieux pass├® ├Ā essayer diff├®rentes choses et ├Ā tenter parfois des man┼ōuvres aussi hasardeuses que risqu├®es. Lors de la programmation pour Windows, vous avez besoin d'un bon d├®bogueur Windows con├¦u pour ce travail.
Voici les diff├®rents points trait├®s dans cette annexe┬Ā:
- Qu'est-ce qu'un d├®bogueur┬Ā?
- ├Ć quoi servent les symboles┬Ā?
- Qu'est-ce qu'un d├®bogueur symbolique┬Ā?
- D├®bogage en Win32 - Besoins sp├®ciaux
- Techniques sp├®ciales lors du d├®bogage dans Win32
- Autres techniques ├Ā mettre en ┼ōuvre (en substitution du d├®bogage)
VIII-H-1. Qu'est-ce qu'un d├®bogueur┬Ā?▲
Un d├®bogueur est un logiciel qui permet d'ex├®cuter un autre programme (le ┬½┬Ādebuggee┬Ā┬╗) dans des conditions particuli├©res et ├®troitement contr├┤l├®es. Il vous permet de progresser pas ├Ā pas dans le code du programme. Le processeur ex├®cute une seule instruction ├Ā la fois, et vous pouvez visualiser imm├®diatement son effet sur les registres et flags, la pile et les zones m├®moire du programme examin├®. Habituellement, un d├®bogueur vous permet de choisir de tracer ├Ā l'int├®rieur des CALL ou de les ex├®cuter sans en analyser le contenu. Un d├®bogueur vous permet ├®galement de d├®finir des points d'arr├¬t o├╣ vous pouvez arr├¬ter l'ex├®cution et proc├®der ├Ā l'analyse ├Ā partir de l├Ā, ou d'ex├®cuter le programme suspect jusqu'├Ā ce que quelque chose aille mal.
VIII-H-2. ├Ć quoi servent les symboles┬Ā?▲
Les symboles sont les labels de donn├®e et de code de votre script source. Un label de donn├®e se rapporte ├Ā une adresse dans la section de donn├®es et existe lorsque la donn├®e est d├®clar├®e. Par exemple,
SmallBuffer DD 20h DUP 0cr├®e un tampon de 32 dwords initialis├®s ├Ā z├®ro, avec le label ┬½┬ĀSmallBuffer┬Ā┬╗. Ce tampon peut alors ├¬tre invoqu├® sous ce nom tout au long de votre code source. Un label de code se rapporte ├Ā une adresse dans la section de code et peut ├¬tre libell├® comme suit┬Ā:
Procedure66:Ceci permettra d'├®tablir le label ┬½┬ĀProcedure66┬Ā┬╗ dans la section de code. La proc├®dure peut alors ├¬tre appel├®e en utilisant la forme de code
CALL Procedure66Un label de donn├®e ou de code ne doit pas ├¬tre au d├®but de la zone de donn├®es ou de code. Vous pouvez diviser les zones de donn├®es de telle sorte que le label ne porte que sur une partie de celui-ci, et un label de code peut ├¬tre sur une ligne dans la section de code.
VIII-H-3. Qu'est-ce qu'un d├®bogueur symbolique┬Ā?▲
Un d├®bogueur symbolique conna├«t l'adresse des symboles et est capable de les afficher dans le d├®sassemblage.
Ici, par exemple, le d├®bogueur visualise, dans le d├®sassemblage, le label de code du d├®but de la proc├®dure et un second label quelques lignes plus loin. Les r├®f├®rences de donn├®es dans le d├®sassemblage sont montr├®es par label de donn├®e. Un d├®bogueur symbolique peut ├®galement utiliser les labels de code pour permettre ├Ā l'utilisateur d'├®tablir des points d'arr├¬t, et peut afficher le contenu de la m├®moire par r├®f├®rence ├Ā des labels de donn├®e. Les symboles sont connus par le d├®bogueur soit parce que les informations de symbole sont int├®gr├®es dans l'ex├®cutable, soit par ce qu'elles sont conserv├®es dans un fichier s├®par├®. Cela se fait au moment de l'├®dition de liens et est r├®alis├® par le linker lequel, si on le lui demande, va trier les labels dans les fichiers objet et les mettre dans le fichier ex├®cutable (ou dans un fichier s├®par├®) pour pouvoir ├¬tre lus par le d├®bogueur en tant que symboles.
VIII-H-4. D├®bogage en Win32 - Besoins sp├®ciaux▲
Un d├®bogueur Win32 doit ├¬tre sp├®cialement con├¦u pour surveiller et traiter les ├®v├®nements du syst├©me, les messages et les actions. En particulier, il doit ├¬tre en mesure d'observer et de rendre compte des messages ├®chang├®s entre le programme ├Ā d├®boguer et le syst├©me d'exploitation, puisque c'est le principal moyen d'interaction entre les deux. Les messages peuvent ├¬tre envoy├®s par le syst├©me, soit directement au programme, soit par le biais de la file de messages (pr├®lev├®e dans la boucle de messages). Lors de l'attente d'un retour de GetMessage dans la boucle de message, le d├®bogueur doit ├¬tre capable de capter et de surveiller une ex├®cution ailleurs dans le programme induite par les messages envoy├®s ├Ā des proc├®dures de fen├¬tre. Le d├®bogueur doit ├®galement ├¬tre en mesure de d├®boguer des applications multithreads, de surveiller l'activit├® de chaque thread et de montrer l'interaction entre les threads. Il doit pouvoir afficher des zones de m├®moire et de pile virtuelles et des valeurs de registres et identifier les zones de m├®moire uniques pour le syst├©me d'exploitation. Il doit ├¬tre capable de retracer l'ex├®cution ├Ā l'int├®rieur des DLL. Il doit ├¬tre en mesure de traiter les exceptions ├Ā analyser caus├®es par le programme et permettant ├Ā ce dernier de poursuivre son ex├®cution sans crash. Il doit pouvoir signaler les erreurs indiqu├®es par les API. Enfin, le d├®bogueur doit ├¬tre capable de fermer le programme ├Ā analyser de mani├©re ┬½┬Āpropre┬Ā┬╗.
VIII-H-5. Techniques sp├®ciales lors du d├®bogage dans Win32▲
Voici quelques-unes des actions que vous devez pouvoir conduire avec un d├®bogueur Win32 bien con├¦u.
- Mise en place d'un point d'arr├¬t pour ex├®cuter le programme jusqu'├Ā un message quelconque ou jusqu'├Ā un message particulier, l'un et l'autre dans le cadre d'une proc├®dure de fen├¬tre particuli├©re.
- Visualiser la s├®quence et le d├®tail des messages.
- ├ētude de l'ex├®cution de nouveaux threads et examen de la mani├©re dont Windows partage le temps processeur entre eux.
- Affichage du contenu de la pile en d├®tail.
- Supervision des erreurs d'API.
- Changement de la valeur des registres (ordinaires, ├Ā virgule flottante ou MMX) ou des flags ├Ā l'ex├®cution pour corriger d'├®ventuelles erreurs ou v├®rifier votre code.
- Possibilit├® de suspendre l'ex├®cution des boucles continues.
- Visualiser et v├®rifier les opcodes produits par votre assembleur ou compilateur, et faire de m├¬me avec tout code ex├®cutable sous forme de mn├®moniques assembleur.
- Visualisation en tant que code ou de donn├®e des zones m├®moire et de m├®moire repr├®sent├®es par les symboles qui sont charg├®s.
- Visualisation du contexte m├®moire du programme test├® ainsi que ses DLL (les images ex├®cutables) tels que charg├®s en m├®moire.
- Recherche du contexte m├®moire du programme et la m├®moire partag├®e pour les cha├«nes ou valeurs sp├®cifiques et affichage des r├®sultats.
- Visualisation des ressources du programme et de ses DLL telles que charg├®es en m├®moire et (sous r├®serve du respect du copyright), extraction des ressources utiles ├Ā partir de fichiers ex├®cutables.
VIII-H-6. Autres techniques utilisables (en substitution au d├®bogage)▲
VIII-H-6-a. Examen de votre code▲
Souvent, il n'y a pas d'autre solution que de scruter attentivement votre code source pour y identifier l'endroit o├╣ l'erreur est survenue. Il vous sera beaucoup plus facile de progresser dans le d├®veloppement et le test de votre code source si vous proc├®dez de mani├©re incr├®mentale. En d'autres termes, ajoutez de petits morceaux de code, puis astreignez-vous ├Ā les tester imm├®diatement plut├┤t que proc├®der par grandes sections, qui peuvent contenir plus d'une d├®faillance et m├¬me interagir.
VIII-H-6-b. Retracer les ├®tapes avant le bogue▲
Essayez de rep├®rer la s├®quence d'├®v├®nements qui a pr├®c├®d├® le bogue chaque fois que le d├®faut se produit. Puis reprenez cette s├®quence de nouveau pour v├®rifier que le d├®faut se produit bien ├Ā cet endroit. Essayez d'isoler le d├®faut en supprimant certaines des ├®tapes ou en prenant d'autres mesures. Obtenez, de la sorte, une s├®quence aussi courte que possible. Ce processus vous aidera ├Ā identifier le coupable le plus probable tout en r├®duisant le nombre de proc├®dures que vous devez v├®rifier.
VIII-H-6-c. Ralentissez le syst├©me au moment de l'ex├®cution pour les probl├©mes de dessin▲
Si vous avez un probl├©me de dessin Windows dans lequel vous soup├¦onnez que Windows dessine quelque chose ├Ā l'├®cran puis le masque aussit├┤t en dessinant quelque chose d'autre par-dessus, essayez de ralentir le programme en ins├®rant le processus suivant ├Ā un endroit appropri├®┬Ā:
PUSH 1000
CALL SleepCette courte s├®quence appelle l'API Sleep (veille) et introduit une temporisation de 1000 millisecondes. L'API va agir uniquement sur le thread qui l'appelle, de sorte que, si vous soup├¦onnez qu'un autre thread est en train d'├®craser le mat├®riau du premier thread, cette technique le mettra en ├®vidence.
Notez qu'il n'est pas recommand├®, dans une application Windows, d'avoir plus d'un thread responsable du dessin ├Ā l'├®cran ou de la gestion des fen├¬tres car cela est susceptible d'induire le syst├©me en erreur.
Si l'├®crasement appara├«t au sein de votre propre code en r├®ponse au message WM_PAINT, ins├®rez alors l'appel ├Ā l'API Sleep ├Ā des endroits appropri├®s dans votre processus de dessin pour d├®couvrir exactement o├╣ l'├®crasement se produit.
Windows va parfois dessiner par-dessus ce que vous avez essay├® de dessiner ├Ā l'├®cran. Cela peut se produire, par exemple, si le syst├©me est persuad├® qu'une autre fen├¬tre devrait appara├«tre au sommet du dessin (c'est-├Ā-dire une autre fen├¬tre qui est plus ├®lev├®e dans la hi├®rarchie-Z) ou si le syst├©me estime que la zone que vous avez dessin├®e est ┬½┬Āinvalide┬Ā┬╗ (n├®cessite d'├¬tre peinte parce qu'elle s'est d├®plac├®e ou a ├®t├® d├®couverte). Gardez pr├®sent ├Ā l'esprit que le syst├©me ne fera pas de dessin plus loin dans une fen├¬tre jusqu'├Ā ce que le thread qui a cr├®├® cette fen├¬tre ne soit revenu de son WndProc ou jusqu'├Ā ce que DefWndProc soit appel├®. Ainsi, vous pouvez ins├®rer l'API Sleep avant de faire cela.
VIII-H-6-d. Masquer des parties de votre code▲
Voici une autre technique utile pour identifier des probl├©mes d'├®crasement par ├®criture, que ce soit ├Ā l'├®cran ou dans la m├®moire. Elle consiste ├Ā ├®liminer provisoirement un code suspect en pla├¦ant tout simplement un point-virgule au d├®but de la ligne de code concern├®e, de sorte que l'assembleur en ignore le contenu, assimil├® d├©s lors ├Ā un commentaire. Il suffit de voir alors si ce retrait corrige le probl├©me. Bien s├╗r, vous devez ├¬tre prudent et veiller notamment ├Ā ce que toutes les valeurs de registre et de m├®moire n├®cessaires soient fournies aux lignes de code en aval, et que l'├®quilibre de la pile soit maintenu.
L'avantage de cette technique tient au fait qu'elle est facile ├Ā mettre en ┼ōuvre tout comme l'est le r├®tablissement ├Ā la situation ant├®rieure.
VIII-H-6-e. Ajouter un testeur visible ├Ā votre code au moment de l'erreur▲
La m├®thode consiste ├Ā afficher ├Ā l'├®cran une fen├¬tre de test lorsqu'une partie particuli├©re du code est atteinte. Pour ce faire, on ajoute au programme en cours de d├®veloppement le code et les donn├®es ci-dessous qui d├®finissent le testeur dont il est question. La fen├¬tre de ce module affiche en hexad├®cimal la valeur du registre EAX. Le testeur enregistre tous les registres et flags ce qui le rend donc totalement transparent vis-├Ā-vis du programme qu'il scrute. Si le testeur est appel├® ├Ā nouveau, il ajoute une autre ligne ├Ā la fen├¬tre du testeur avec la valeur de EAX ├Ā ce moment. Chaque ligne est num├®rot├®e et peut ├¬tre consult├®e par simple d├®filement. Il convient toutefois d'├¬tre prudent sur deux points. En premier lieu, si vous rencontrez des probl├©mes de peinture et de dessin, il se peut que le testeur aggrave la situation dans la mesure o├╣ il agit lui-m├¬me sur l'affichage selon des modalit├®s identiques. En second lieu, lors de l'insertion du testeur dans un thread secondaire, il ne faut surtout pas l'appeler directement ├Ā partir de ce thread. Au lieu de cela, envoyez un message ├Ā la fen├¬tre principale et appelez le testeur ├Ā partir de l├Ā comme indiqu├® plus loin apr├©s le listing du testeur.
; ******* LISTING DU TESTEUR *******
DATA SECTION
;
TESTER_MSG DD 7 DUP 0
; hWnd, +4=message, +8=wParam, +C=lParam, +10h=time, +14h/18h=pt
hTester DD 0
TesterThreadId DD 0
TEST_COUNTER DD 0
sHEXb DB '0123456789ABCDEF'
TEST_MESS DB 18D DUP 0
;
CODE SECTION
;
TESTER: ; le programme en cours de test appelle ce label, EAX contenant
; la valeur ├Ā afficher en hexa et en d├®cimal
PUSHFD ; sauvegarde des flags pour les restaurer ult├®rieurement
PUSH EAX, EBX, ECX, EDX, EDI, ESI ; sauvegarde des registres qui vont ├¬tre utilis├®s
MOV ESI, EAX ; sauvegarde du nombre ├Ā ├®crire dans ESI
CMP D[hTester], 0 ; voir si le testeur de fen├¬tre existe d├®j├Ā
JNZ >L200 ; oui
MOV D[TEST_COUNTER], 0 ; on force le compteur ├Ā d├®marrer ├Ā partir de z├®ro
CALL GetDesktopWindow ; pr├®paration pour que parent = bureau (v├®rifie que les
; messages parents ne sont pas envoy├®s ├Ā l'application
; et que la fen├¬tre est correctement dessin├®e)
PUSH 0, 0, 0, EAX
PUSH 208D, 130D, 30D, 30D ; hauteur, largeur et position de la fenêtre
PUSH 4C80000h+200000h+10000h+20000h+40000h ; WS_CHILD+CAPTION+SYSMENU+WS_VSCROLL
; +WS_HSCROLL+WS_MINIMIZEBOX+SIZEBOX
PUSH 'Tester window' ; titre charg├® avec l'extension PUSH (voir manuel GoAsm)
PUSH 'LISTBOX' ; classe
PUSH 1h+8h ; WS_EX_DLGMODALFRAME + WS_EX_TOPMOST
CALL CreateWindowExA ; constitution fenêtre avec retour du handle dans EAX
OR EAX, EAX ; une erreur s'est-elle produite ?
JZ >L202 ; oui
MOV [hTester], EAX ; m├®morisation du handle
PUSH 8h, EAX ; pr├¬t ├Ā afficher mais non activ├®
CALL ShowWindow
PUSH 12D
CALL GetStockObject ; r├®cup├®ration du handle de ANSI_VAR_FONT d├®tenu par Windows
PUSH 0, EAX, 30h, [hTester] ; 30h=WM_SETFONT
CALL SendMessageA ; d├®finition de la police de caract├©res pour la listbox
MOV EAX, ESI ; r├®cup├®ration du nombre ├Ā ├®crire
L200:
CALL WRITE_NUMBER
L202:
POP ESI, EDI, EDX, ECX, EBX, EAX ; restauration de tous les registres affect├®s
POPFD ; restauration des flags
RET
;
WRITE_TESTCOUNTER: ; ├®criture nombre d├®cimal en EAX dans [EDI]
MOV EDI, ADDR TEST_MESS ; cette fonction est appel├®e par WRITE_NUMBER
XOR EDX, EDX
XOR ECX, ECX ; ECX est utilis├® comme un compteur
MOV EBX, 10D ; EBX = 10 (d├®cimal)
L100:
DIV EBX ; division EDX:EAX par 10 avec quotient dans EAX, reste en EDX
PUSH EDX ; m├®morisation du reste en pile
INC ECX ; on incr├®mente le compteur de ceux qui sont en pile
XOR EDX, EDX
CMP EAX,EDX ; on regarde s'il y a quelque chose de plus ├Ā faire
JNZ L100 ; oui
L101:
POP EAX ; inversion de l'ordre des chiffres utilisant la pile
ADD AL, 48D ; conversion en ascii
STOSB ; ├®criture du chiffre dans le buffer
LOOP L101
MOV EAX, ' .'
STOSD ; ├®criture nombre hexa en EAX dans [EDI]
RET
;
TEST_HEXWRITE: ; ├®crit en hexa le contenu de EAX dans [EDI]
PUSH ECX
MOV EBX, ADDR sHEXb
MOV ECX,8 ; 8 caract├©res ├Ā afficher
L130:
ROL EAX, 4 ; AL = quartet sup├®rieur de EAX obtenu par permutation
MOV DL, AL
AND EDX, 0Fh ; on ne conserve que le quartet le moins significatif
MOV DL, [EBX+EDX] ; DL = caract├©re correct extrait de la table
MOV [EDI], DL ; on ├®crit le caract├©re
INC EDI ; on pointe l'emplacement du caract├©re suivant
LOOP L130 ; boucle jusqu'├Ā ce que ECX = 0
POP ECX
RET
;
WRITE_NUMBER: ; affichage ├Ā l'├®cran du nombre contenu dans EAX
INC D[TEST_COUNTER] ; incr├®mentation du compteur
CMP D[TEST_COUNTER], 1000D ; on regarde si le compteur d├®passe maintenant 1000
JNA >L112 ; non
MOV D[TEST_COUNTER], 1 ; on d├®passe 1000, alors on r├®initialise le compteur
L112:
MOV EDI, ADDR TEST_MESS
MOV EAX, [TEST_COUNTER]
CALL WRITE_TESTCOUNTER ; ├®criture du nombre en EAX en [edi] sous format d├®cimal
MOV EAX, ESI ; restauration du nombre du programme sous test
CALL TEST_HEXWRITE ; ├®criture du nombre en EAX en [edi] sous format hexa
MOV B[EDI], 'h' ; caract├©re 'h' de fin marquant que la valeur est hexa
MOV B[EDI+1], 0 ; caract├©re NULL ├Ā la fin
PUSH ADDR TEST_MESS
PUSH 0, 180h, [hTester] ; 180h = LB_ADDSTRING
CALL SendMessageA
MOV EDI, EAX ; m├®morisation de l'index en EDI
CMP EDI, 999D ; voir si l'index d├®passe 999 (index├® ├Ā z├®ro)
JNA >L118 ; non
PUSH 0, 0, 182h, [hTester] ; 182h = LB_DELETESTRING
CALL SendMessageA ; suppression de la toute premi├©re entr├®e (on s'assure
; qu'il n'y a pas surcharge)
L118: ; d├®file maintenant pour garantir que le dernier mis est visible
DEC EDI ; d├®cr├®mentation de l'index
PUSH 0, EDI ; EDI pointe la cha├«ne permettant de garantir la visibilit├®
PUSH 197h, [hTester] ; 197h = LB_SETTOPINDEX
CALL SendMessageA ; scroll de la listbox maintenant
L123:
PUSH [hTester]
CALL UpdateWindow ; garantit que Windows affiche des changements
RET ; d├©s qu'il est pr├¬tVIII-H-6-e-1. Pr├®cautions particuli├©res si vous appelez le testeur ├Ā partir d'un thread secondaire▲
Si vous appelez le testeur directement ├Ā partir d'un thread secondaire (c'est-├Ā-dire d'un thread autre que celui qui a construit la fen├¬tre principale de votre application), le syst├©me va ├¬tre d├®sorient├® et vous rencontrerez des probl├©mes. Au lieu de cela, envoyez un message d├®fini par l'utilisateur ├Ā la fen├¬tre principale de votre application et appelez le testeur ├Ā partir de la proc├®dure de fen├¬tre principale. Utilisez le code suivant pour envoyer un message d├®fini par l'utilisateur ├Ā la fen├¬tre principale de votre application┬Ā:
THREAD_TESTER:
PUSH EAX, ECX, EDX
PUSH 6, EAX, 411h, hWnd
CALL SendMessageA
POP EDX, ECX, EAX
RETCe code envoie le message 411h ├Ā la proc├®dure de la fen├¬tre principale (dont le handle est m├®moris├® dans hWnd). Notez que les messages d'utilisation d├®finis doivent ├¬tre de valeur 400h ou plus. Le nombre (en EAX) ├Ā ├®crire dans la fen├¬tre du testeur est envoy├® ├Ā la proc├®dure de fen├¬tre sur la pile comme wParam. Ici aussi, la valeur de lParam est fix├®e ├Ā 6 pour une identification plus pouss├®e. Ce code est appropri├® dans la mesure o├╣ il n'est pas important que le thread secondaire doive attendre l'apparition de la fen├¬tre du testeur (SendMessage ne retourne pas jusqu'au retour effectif de la proc├®dure de la fen├¬tre). Si cela constitue un probl├©me, utilisez PostMessage ├Ā la place.
VIII-H-6-f. Affectation d'une touche du clavier pour visualiser la fen├¬tre du testeur au cours du d├®veloppement de votre application▲
On peut enfin faire en sorte qu'une touche sp├®cifique du clavier, identifi├®e comme telle par WM_KEYDOWN, provoque l'appel du testeur. Vous pouvez charger dans EAX n'importe quelle valeur de la m├®moire que vous voulez ├®tudier. Lorsque votre programme est termin├® et pr├¬t ├Ā ├¬tre publi├®, assurez-vous que ce code est supprim├®. En tout cas, il constitue un moyen rapide pour afficher les valeurs de m├®moire sans avoir ├Ā d├®marrer le d├®bogueur. Encore une fois, vous pouvez appeler le testeur autant de fois que vous le souhaitez, les r├®sultats d├®filant tout simplement, en ce cas, dans la fen├¬tre. Cette technique peut ├®galement ├¬tre utilis├®e pour v├®rifier les r├®sultats de votre codage plus en d├®tail. Par exemple, arrangez-vous pour appeler la fonction en cours de test lorsque la touche est press├®e, en lui passant diff├®rentes valeurs. Lire le r├®sultat pour v├®rifier qu'elle fonctionne bien.
VIII-I. ComprendreŌĆ” la pile▲
Tous les programmes font un usage intensif de la pile au moment de l'ex├®cution. Si vous programmez dans un langage de haut niveau, vous ne pouvez absolument pas avoir conscience que le compilateur en fait usage. Mais en tant que programmeur assembleur vous ne pouvez vous en abstraire dans la mesure o├╣ la pile est l'un des principaux outils ├Ā votre disposition. En l'utilisant directement, vous pouvez r├®aliser son potentiel ├®lev├® dans vos programmes. Bien que vous puissiez programmer en assembleur sans savoir quoi que ce soit ├Ā propos de la pile, il est utile (et m├¬me recommand├®) d'en appr├®hender le fonctionnement.
- Dans la partie 1, vous trouverez des informations qui vous seront indispensables si vous envisagez de vous lancer s├®rieusement dans la programmation en assembleur.
- La partie 2, d'un abord plus complexe, n'est pas indispensable mais elle propose une excursion en profondeur de ce dispositif.
VIII-I-1. Partie 1▲
VIII-I-1-a. Caract├®ristiques et avantages de la pile▲
Fondamentalement, la pile est une zone de dword (zones de donn├®es 32 bits) en m├®moire que votre application peut utiliser pour stocker temporairement les donn├®es lors de son ex├®cution. Elle a certaines caract├®ristiques et des avantages r├®els par rapport aux autres types de stockage de m├®moire (sections de donn├®es et zones de m├®moire lors de l'ex├®cution)┬Ā:
- le processeur ├®crit et lit sur la pile tr├©s rapidement, car il est optimis├® pour cet usage┬Ā;
- les instructions ├®l├®mentaires PUSH et POP peuvent ├¬tre utilis├®es pour ├®crire et lire sur la pile. Elles sont tr├©s compactes┬Ā: un seul octet pour la manipulation de registres, cinq octets lors de l'utilisation de labels de m├®moire ou de pointeurs vers des adresses de m├®moire┬Ā;
- sous Windows, la pile est agrandie dynamiquement lors de l'ex├®cution par blocs de 4K. Ceci permet d'├®viter le gaspillage de m├®moire.
VIII-I-1-b. Usages courants de la pile▲
La pile peut ├¬tre utilis├®e pour┬Ā:
- Pr├®server la valeur de registres dans des fonctions┬Ā:
Exemple┬Ā:
PUSH EDI ; sauvegarde en pile du handle du fichier
CALL CALCULATE ; r├®alisation de calculs (utilise EDI)
POP EDI ; restaure le handle du fichier
CALL CLOSE_FILEHANDLE ; fermeture du handle du fichier contenu dans EDI- Pr├®server des donn├®es en m├®moire┬Ā:
Exemple┬Ā: supposons que vous ayez soigneusement calcul├® le nombre de widgets et que vous vouliez ├®crire des d├®tails sur ceux-ci ├Ā la fois sur l'├®cran et dans un fichier. Vous pouvez utiliser le code suivant┬Ā:
PUSH [NOOF_WIDGETS] ; m├®morisation en pile du nombre de widgets
L2:
CALL REPORT_WIDGET ; ├®crit les d├®tails du widget sur l'├®cran
DEC D[NOOF_WIDGETS] ; d├®cr├®mente le nombre de widgets
JNZ L2 ; continue avec le suivant tant qu'il n'est pas nul
POP [NOOF_WIDGETS] ; restaure le nombre de widgets
CALL WRITETO_FILE ; et effectue un report similaire sur le fichier- D├®placer des donn├®es dans la m├®moire sans utiliser de registres┬Ā:
Exemple┬Ā: supposons que vous vouliez d├®placer le nombre de widgets de l'exemple pr├®c├®dent ├Ā un autre label de m├®moire. Vous pouvez utiliser┬Ā:
MOV EAX, [NOOF_WIDGETS]
MOV [COPYOF_NOOF_WIDGETS], EAXMais vous pouvez tout aussi efficacement utiliser le code suivant qui ├®vite toute utilisation de registre┬Ā:
PUSH [NOOF_WIDGETS]
POP [COPYOF_NOOF_WIDGETS]Dans la mesure o├╣ le registre EAX n'est plus mis ├Ā contribution, il ne perd donc pas sa valeur et peut donc ├¬tre affect├® ├Ā un autre usage.
- Renverser l'ordre de donn├®es┬Ā:
Exemple┬Ā: vous pouvez mettre ├Ā profit le m├®canisme ┬½┬ĀLast In, First Out┬Ā┬╗ ├Ā la base du fonctionnement de la pile pour inverser l'ordre de donn├®es. On en trouve une utilisation pratique d├©s lors que l'on se propose d'afficher ├Ā l'├®cran une valeur en format d├®cimal. Voir l'exemple du I1.8 plus loin.
VIII-I-1-c. Le Pointeur de Pile┬Ā: registre ESP▲
Le registre ESP (litt├®ralement ┬½┬ĀExtended Stack Pointer┬Ā┬╗) pointe l'emplacement m├®moire correspondant au sommet de la pile. C'est le point o├╣ les instructions qui utilisent la pile (PUSH, POP, CALL et RET) effectuent leurs op├®rations avec la m├®moire. ├Ć quelques exceptions pr├©s (r├®servation d'une zone de m├®moire sur la pile, par exemple), ESP n'est g├®r├® que par les instructions PUSH, POP, CALL et RET et le programmeur intervient fort peu sur ce registre. Il en sera question un peu plus loin.
Le registre EBP (litt├®ralement ┬½┬ĀExtended Base Pointer┬Ā┬╗) est traditionnellement positionn├® par le programmeur ├Ā un endroit et ├Ā un moment particuliers sur la pile, de sorte que les donn├®es puissent y ├¬tre lues et ├®crites au moyen de l'adressage de base d'index (base index addressing). Par exemple, dans l'instruction MOV EAX, [EBP+8h], le registre EBP est utilis├® comme un index pointant une zone de la pile et cette instruction copie un mot situ├® 8 octets plus bas dans la pile dans le registre EAX. L'utilisation traditionnelle de EBP ├Ā cet effet est l'h├®ritage direct de la programmation 16 bits. Dans ce mode, utilisant la technique de m├®moire segment├®e, on trouvait un registre BP d'une taille de 16 bits qui, comme tous les registres d'index, ├®tait attach├® ├Ā un registre de segment ├®galement de 16 bits. Par d├®faut, BP ├®tait attach├® au registre de segment SS (Stack Segment), ce dernier pouvant ├¬tre modifi├® par override. Aujourd'hui, sous 32 bits, les segments ne sont plus exploit├®s et chaque programme fonctionne dans ses propres 4┬ĀGo d'espace d'adressage. EBP peut donc pointer l'ensemble de cet espace et ne se limite plus ├Ā traiter la pile. Il peut donc maintenant ├¬tre utilis├® comme un registre ├Ā usage g├®n├®ral bien que le poids de son pass├® le cantonne au traitement de zones particuli├©res de la pile principalement pour acc├®der aux param├©tres transmis aux fonctions et routines callback et pour traiter les donn├®es locales.
VIII-I-1-d. PUSH et POP de donn├®es sur la pile▲
 La pile peut ├¬tre assimil├®e ├Ā la desserte de plateau-repas d'un traiteur. Cet ustensile fonctionne selon le principe ┬½┬Ādernier entr├®, premier sorti┬Ā┬╗. Le dernier plateau pouss├® sur la desserte en utilisant l'instruction PUSH sera le premier retir├® en utilisant l'instruction POP. Le pointeur de la pile dans ESP pointe toujours sur cette plaque sup├®rieure.
La pile peut ├¬tre assimil├®e ├Ā la desserte de plateau-repas d'un traiteur. Cet ustensile fonctionne selon le principe ┬½┬Ādernier entr├®, premier sorti┬Ā┬╗. Le dernier plateau pouss├® sur la desserte en utilisant l'instruction PUSH sera le premier retir├® en utilisant l'instruction POP. Le pointeur de la pile dans ESP pointe toujours sur cette plaque sup├®rieure.
Regardons cela sous une forme plus traditionnelle. Supposons que la valeur de ESP soit 64FE3Ch et vous ayez les instructions suivantes dans votre code source┬Ā:
PUSH 2
PUSH [hWnd]
PUSH ADDR STRING├Ć l'issue de ces trois instructions, ESP serait 64FE30h (soit 12 octets ou 3 DWords de moins) et la pile affiche alors l'activit├® suivante┬Ā:
| ESP est ici ŌåÆ | 64FE30h | Adresse de STRING |
| 64FE34h | Valeur contenue par hWnd | |
| 64FE38h | Le nombre 2 | |
| 64FE3Ch |
Notez que chaque instruction PUSH commence par r├®duire la valeur de ESP de 4 octets puis m├®morise la donn├®e sp├®cifi├®e en tant qu'op├®rande au nouvel endroit point├® par ESP.
Voyons maintenant ce qu'il en est avec les instructions POP. Avec les m├¬mes valeurs sur la pile, utilisons les instructions suivantes┬Ā:
POP EAX
POP EBX
POP ECXL'instruction POP r├®alise l'inverse de PUSH┬Ā: le contenu de l'adresse point├®e par ESP est copi├® dans l'op├®rande puis ESP se voit incr├®ment├® de 4 octets.
Examinons l'├®volution du comportement de la pile┬Ā:
| 64FE30h | Adresse de STRING | |
| 64FE34h | Valeur contenue par hWnd | |
| 64FE38h | Le nombre 2 | |
| ESP est ici ŌåÆ | 64FE3Ch |
La premi├©re chose ├Ā noter ici est que, apr├©s ces trois instructions, ESP revient ├Ā 64FE3Ch, soit la valeur initiale de l'exemple pr├®c├®dent. Cela signifie que ESP a ├®t├® r├®tabli ├Ā l'├®quilibre. Il s'agit ici d'un concept important car la stabilit├® du programme en d├®pend.
Le registre EAX contient maintenant l'adresse de STRING, EBX re├¦oit la valeur d├®tenue par hWnd et ECX re├¦oit le nombre 2. Donc, les donn├®es stock├®es sur la pile en ont ├®t├® extraites dans l'ordre inverse de celui dans lequel elles y avaient ├®t├® pouss├®es.
Notez ├®galement que les donn├®es sur la pile demeurent toujours pr├®sentes bien qu'ayant ├®t├® extraites. Cette situation r├®sulte du fait que l'instruction POP n'├®crit pas sur la pile et se contente d'en lire simplement la donn├®e dans la deuxi├©me partie de l'instruction (appel├®e ┬½┬Āop├®rande┬Ā┬╗).
VIII-I-1-e. Pr├®servation de la valeur des registres dans les fonctions▲
Les programmes ├®crits en assembleur sont rapides car ils utilisent des registres autant que possible. Cela signifie souvent cependant que le contenu des registres ├Ā un moment donn├® doit ├¬tre conserv├® en pr├®vision d'une utilisation ult├®rieure. Ainsi, supposons un handle de fichier en EDI, et qu'apr├©s avoir effectu├® quelques calculs utilisant ├®galement EDI vous auriez ├®ventuellement besoin de fermer ledit handle du fichier d├®tenu initialement par EDI. Voici comment op├®rer les sauvegardes n├®cessaires┬Ā:
PUSH EDI ; sauvegarde du handle du fichier
CALL CALCULATE ; calculs utilisant EDI
POP EDI ; restauration du handle du fichier
CALL CLOSE_FILEHANDLE ; fermeture du handle du fichier contenu en EDIComme alternative, vous pourriez ├®galement envisager de pr├®server EDI au sein de la proc├®dure de calcul elle-m├¬me, par exemple┬Ā:
CALL CALCULATE ; calculs utilisant EDI mais sauvegardant sa valeur initiale
CALL CLOSE_FILEHANDLE ; fermeture du handle du fichier contenu en EDIo├╣ la fonction CALCULATE pr├®senterait l'allure suivante┬Ā:
CALCULATE:
PUSH EDI ; sauvegarde du handle du fichier
; .
; . ; code utilisant EDI et modifiant donc sa valeur
; .
POP EDI ; restauration du handle du fichier
RETUne autre raison pour laquelle un registre peut devoir ├¬tre pr├®serv├® doit ├¬tre envisag├®e dans le contexte o├╣ une fonction particuli├©re est appel├®e de l'ext├®rieur (par une autre fonction dans le m├¬me programme, d'un autre programme ou par le syst├©me). Dans la plupart des cas, assurez-vous que EBP, EBX, EDI et ESI sont pr├®serv├®s. C'est assur├®ment l'exigence d'un programme C dans le cas o├╣ il appelle une routine ├®crite en assembleur┬Ā; c'est ├®galement l'exigence de proc├®dures callback appel├®es par Windows. Un exemple d'une telle proc├®dure callback est la classique proc├®dure de fen├¬tre qui est utilis├®e par le syst├©me pour transmettre des messages ├Ā une fen├¬tre dans l'application. Dans de telles circonstances, vous devez vous assurer que ces registres sont pr├®serv├®s en utilisant, par exemple┬Ā:
PUSH EBP, EBX, EDI, ESI
;.
;. ; votre code s'├®crit ici
;.
POP ESI, EDI, EBX, EBPBien s├╗r, si votre code ne change pas ces registres, rien de vous emp├¬che d'omettre les PUSH et POP concern├®s, mais il peut ├¬tre consid├®r├® de bonne pratique que de les maintenir en l'├®tat dans l'├®ventualit├® o├╣ vous augmenteriez ult├®rieurement votre code et oublieriez de veiller ├Ā ce que ces registres soient pr├®serv├®s. Notez comment les POP sont tous dans l'ordre inverse des PUSH┬Ā: cela est d├╗ au principe ┬½┬Ādernier entr├®, premier sorti┬Ā┬╗ qui est la nature m├¬me de la pile. ├Ć noter ├®galement dans le code ci-dessus que les registres sont positionn├®s dans l'ordre alphab├®tique. Cela n'est qu'un moyen mn├®motechnique destin├® ├Ā faciliter le contr├┤le de coh├®rence des PUSH et POP.
Notez que GoAsm met ├Ā votre disposition l'instruction USES qui pr├®serve et restaure automatiquement les registres selon une ├®criture simplifi├®e.
VIII-I-1-f. Pr├®servation des donn├®es en m├®moire▲
Tout comme vous pouvez conserver la valeur d'un registre ├Ā l'aide de la pile, vous pouvez utiliser cette derni├©re pour conserver les donn├®es en m├®moire. Supposons par exemple que vous ayez soigneusement calcul├® le nombre de widgets et que vous vouliez ├®crire des d├®tails sur les widgets ├Ā la fois ├Ā l'├®cran et dans un fichier, vous pouvez utiliser le code suivant┬Ā:
PUSH [NOOF_WIDGETS] ; m├®morisation en pile du nombre de widgets
L2:
CALL REPORT_WIDGET ; ├®criture des d├®tails du widget ├Ā l'├®cran
DEC D[NOOF_WIDGETS] ; d├®cr├®mentation du nombre de widgets
JNZ L2 ; on continue avec le suivant tant que le nombre de widgets n'est pas nul
POP [NOOF_WIDGETS] ; on restaure le nombre de widgets de d├®part
CALL WRITETO_FILE ; et on fait un report similaire en direction du fichierVIII-I-1-g. D├®placement de donn├®es en m├®moire sans utiliser de registres▲
Supposons que vous vouliez d├®placer le nombre de widgets de l'exemple pr├®c├®dent ├Ā un autre label de m├®moire. Vous pouvez utiliser┬Ā:
MOV EAX, [NOOF_WIDGETS]
MOV [COPYOF_NOOF_WIDGETS], EAXMais vous pouvez tout aussi efficacement utiliser le code suivant qui ├®vite toute utilisation de registre┬Ā:
PUSH [NOOF_WIDGETS]
POP [COPYOF_NOOF_WIDGETS]Dans la mesure o├╣ le registre EAX n'est plus mis ├Ā contribution, il ne perd donc pas sa valeur et peut donc ├¬tre affect├® ├Ā un autre usage.
Notez ├®galement que l'on peut d├®placer facilement des donn├®es en m├®moire avec l'instruction CMPS.
VIII-I-1-h. Renversement de l'ordre des donn├®es▲
Vous pouvez mettre ├Ā profit le m├®canisme ┬½┬ĀLast In, First Out┬Ā┬╗ (dernier entr├®, premier sorti) ├Ā la base du fonctionnement de la pile pour inverser l'ordre de donn├®es. On en trouve une utilisation concr├©te d├©s lors que l'on se propose d'afficher ├Ā l'├®cran une valeur en format d├®cimal. Voici un exemple (o├╣ EAX d├®tient la valeur binaire ├Ā afficher en d├®cimal et EDI, la position dans la m├®moire du tampon qui contiendra la cha├«ne ├Ā afficher)┬Ā:
XOR EDX, EDX ; met EDX ├Ā z├®ro
XOR ECX, ECX ; met ECX ├Ā z├®ro (utilis├® comme compteur)
MOV EBX, 10 ; EBX contient toujours la valeur 10
CLD ; incr├®mentation automatique de EDI avec STOSB
L2:
DIV EBX ; Div EDX:EAX par 10 = quotient en EAX, reste en EDX
PUSH EDX ; on place le reste sur la pile
INC ECX ; compte le nombre d'empilages r├®alis├®s
XOR EDX, EDX ; mets EDX ├Ā z├®ro
CMP EAX, EDX ; il y a-t-il quelque chose d'autre ├Ā faire ?
JNZ L2 ; oui
L3: ; inverse maintenant l'ordre des chiffres ├Ā afficher
POP EAX ; retire de la pile l'enregistrement le plus r├®cent
ADD AL, 48 ; conversion de ce chiffre en nombre ASCII
STOSB ; m├®morisation du chiffre ASCII dans le buffer
LOOP L3 ; continue tant que ecx ne vaut pas z├®roAttardons-nous un instant sur ce code. Supposons que la valeur initiale de EAX ├Ā traiter soit le nombre d├®cimal 123. La premi├©re division par 10 met 12 dans EAX (quotient) et 3 dans EDX (reste). La valeur 3 est pouss├®e en pile par PUSH EDX. La seconde division de 12 par 10 met 1 en EAX et 2 dans EDX. La valeur 2 est pouss├®e en pile de la m├¬me mani├©re. La troisi├©me division de 1 par 10 met z├®ro dans EAX et 1 dans EDX. Le reste 1 est pouss├® en pile ├Ā son tour. L'instruction CMP EAX, EDX(9) constate alors que le quotient est nul (EAX = 0), marquant ainsi la fin des divisions successives et le code est projet├® au label L3. Le registre ECX affiche la valeur 3. Il a compt├® le nombre de divisions et, corr├®lativement, le nombre de chiffres du nombre trait├®. Chacun de ces trois chiffres est maintenant extrait de la pile ├Ā son tour. S'agissant de valeurs binaires, on y ajoute la valeur 48, les transformant de la sorte, en caract├©res ASCII qui sont stock├®s dans la m├®moire tampon et pr├¬ts ├Ā ├¬tre affich├®s ├Ā l'├®cran ult├®rieurement.
VIII-I-1-i. Comment CALL et RET utilisent la pile▲
L'instruction CALL est beaucoup utilis├®e en programmation. Elle a pour fonction de d├®tourner l'ex├®cution des instructions vers une proc├®dure particuli├©re (ou ┬½┬Āfonction┬Ā┬╗) situ├®e en un autre point du programme. Lorsque cette proc├®dure est termin├®e, une instruction particuli├©re (RET) renvoie l'ex├®cution juste apr├©s le CALL ├Ā l'origine de ce d├®tournement. L'appel de proc├®dures contribue ├Ā pr├®server la clart├® de votre code source en limitant notamment la r├®p├®tition de blocs de code identiques. En voici un exemple┬Ā:
MOV EAX, EDX
CALL CALCULATE_ASSETS
MOV [ASSETS], EAX ; sauvegarde en m├®moire le r├®sultat de la proc├®dure appel├®e par CALLOn devine ais├®ment qu'un travail important est effectu├® par la proc├®dure CALCULATE_ASSETS, mais il n'est pas n├®cessaire de se soucier de la fa├¦on dont elle fonctionne lorsqu'on regarde cet extrait du script source.
L'utilisation des CALLs contribue ├®galement ├Ā rendre votre code modulaire. La proc├®dure ci-dessus peut ├®galement ├¬tre utilis├®e par d'autres programmes. Si vous le voulez, vous pouvez la consid├®rer comme un ┬½┬Āobjet┬Ā┬╗. Fondamentalement, elle est bien un objet de programmation orient├®e objet.
Alors, comment le processeur sait-il o├╣ poursuivre le traitement en retour de l'appel┬Ā? Eh bien, c'est tr├©s simple┬Ā: il ins├©re l'adresse de retour sur la pile┬Ā!
Observons la pile lorsque cela se produit. Supposons que la valeur du registre ESP soit ├Ā nouveau 64FE3Ch et que vous ayez les instructions suivantes dans votre code source┬Ā:
401020: MOV EAX, EDX
401022: CALL CALCULATE_ASSETS
401027: MOV [ASSETS], EAX ; sauvegarde en m├®moire le r├®sultat de la proc├®dure
; appel├®e par CALLNous avons ajout├® ici l'adresse du pointeur d'instructions (EIP) ├Ā gauche du code pour mieux illustrer ce qui se passe. Apr├©s la premi├©re instruction, ESP est ├®videmment encore ├Ā 64FE3Ch, la pile n'ayant pas chang├® car une instruction MOV ne la modifie pas de quelque fa├¦on que ce soit. Mais quand l'instruction suivante CALL CALCULATE_ASSETS est ex├®cut├®e, le processeur commence par pousser sur la pile l'adresse de retour 401027h, puis d├®tourne l'ex├®cution du programme au label CALCULATE_ASSETS. Le code de la proc├®dure s'ex├®cute alors jusqu'├Ā rencontrer une instruction RET (retour ├Ā l'appelant) qui retire de la pile la valeur stock├®e pr├®c├®demment et la place dans le pointeur d'instructions, permettant au programme de reprendre son cours initial. Voici la forme que prend la proc├®dure ainsi d├®crite┬Ā:
CALCULATE_ASSETS:
; code vari├® ici
RET ; retour ├Ā l'appelantL'instruction RET provoque en effet un POP en EIP, autrement dit ce qui est ├Ā [ESP] est charg├® dans EIP (le pointeur d'instruction) et ESP est augment├® de 4 octets.
Consid├®rons donc la pile avant, pendant et apr├©s les instructions qui pr├®c├©dent┬Ā:
| Avant le Call | Pendant le Call | Apr├©s le Call | ||||||
| 64FE30h | 64FE30h | 64FE30h | ||||||
| 64FE34h | 64FE34h | 64FE34h | ||||||
| 64FE38h | ESP ŌåÆ | 64FE38h | 401027h | 64FE38h | 401027h | |||
| ESP ŌåÆ | 64FE3Ch | 64FE3Ch | ESP ŌåÆ | 64FE3Ch | ||||
Remarquez comment, apr├©s le CALL, ESP est r├®tabli ├Ā l'├®quilibre.
VIII-I-1-j. Importance de l'├®quilibre de la pile▲
Nous avons vu comment une proc├®dure peut ├¬tre appel├®e et comment l'adresse de retour d'ex├®cution est stock├®e sur la pile. Cela dit, il faut consid├®rer que les proc├®dures elles-m├¬mes font souvent appel ├Ā d'autres proc├®dures, qui en appellent ├®galement d'autres et ainsi de suite. Vous pourriez avoir, par exemple┬Ā:
CALCULATE_ASSETS:
CALL CALCULATE_FIXEDASSETS
RET ; retour ├Ā l'appelantet
CALCULATE_FIXEDASSETS:
; ┬Ę
; ┬Ę ; code vari├® ici
; ┬Ę
CALL GET_COSTVALUES
CALL ADJUSTFOR_DEPRECIATION
ADD ESP, 4 ; place ESP en d├®s├®quilibre
RETIci, chaque partie de la t├óche est divis├®e en diff├®rents composants. Maintenant, supposons que la proc├®dure CALCULATE_FIXEDASSETS ajoute 4 ├Ā ESP par erreur. Si cela se produit, lorsque l'instruction RET sera ex├®cut├®e, le pointeur d'instruction EIP se verra charg├® avec une valeur erron├®e et le programme partira dans une direction impr├®visible avant de se bloquer.
Pendant qu'une proc├®dure s'ex├®cute, il est courant que ESP soit modifi├® (par exemple lors de la r├®servation d'un espace de donn├®es sur la pile), mais il est n├®anmoins essentiel de veiller ├Ā ce que l'├®quilibre de la pile soit r├®tabli lorsqu'une proc├®dure est sur le point de se terminer. Lorsque des param├©tres lui ont ├®t├® envoy├®s via la pile, l'├®quilibre peut ├¬tre r├®tabli avec l'instruction RET xx ou en r├®ajustant ESP en fonction du nombre de ces param├©tres.
L'├®quilibre de la pile est ├®galement important pour le retour ├Ā Windows au terme d'une application, m├¬me la plus minimaliste. Dans le genre, l'application qui suit est assez remarquable┬Ā:
START:
RETO├╣ START est le point d'entr├®e de l'application. En fait, normalement, Windows appelle votre application ├Ā partir de Kernel32.dll, et donc un simple RET termine le programme de la mani├©re la plus heureuse qui soit.
VIII-I-1-k. Utilisation de la pile pour passer des param├©tres▲
Structurellement, les API Windows s'attendent ├Ā recevoir leurs param├©tres sur la pile. Lorsque vous appelez une API vous devez donc pousser les param├©tres sur la pile (instructions PUSH) de telle sorte qu'ils puissent ├¬tre r├®cup├®r├®s par elle. Il en va ainsi dans le code qui suit┬Ā:
PUSH 1, [hButton]
CALL EnableWindow ; autorise le boutonDans cet exemple, vous poussez sur la pile la valeur 1 en premier (flag ENABLE), suivi par le handle de la fen├¬tre que vous souhaitez activer. Windows utilise la convention d'appel STDCALL du C pour ses API, ce qui fait qu'au retour de l'API la pile sera ramen├®e ├Ā l'├®quilibre. Cette convention implique ├®galement que EBP, EBX, ESI et EDI soient toujours restaur├®s ├Ā leur valeur pr├®c├®dente par l'API.
Un autre aspect de la convention STDCALL est que les param├©tres sont toujours pouss├®s de droite ├Ā gauche. Les sp├®cifications pour l'API EnableWindow donn├®es dans le Software Development Kit (SDK) de Windows apparaissent en effet comme suit┬Ā:
BOOL WINAPI EnableWindow(
_In_ HWND hWnd,
_In_ BOOL bEnable
);Si l'on traduit cela en assembleur, vous avez besoin de lire les param├©tres de droite ├Ā gauche pour construire correctement l'empilage des param├©tres. Cela peut ├¬tre un peu plus facile si vous utilisez l'instruction INVOKE au lieu du CALL, puisqu'il vous suffit alors de placer les param├©tres dans l'ordre dans lequel ils apparaissent dans le SDK┬Ā:
; Avec CALL
PUSH 1
PUSH [hButton]
Call EnableWindow
; Avec INVOKE
INVOKE EnableWindow, [hButton], 1Voil├Ā tout ce que vous devez savoir sur la passation de param├©tres sur la pile pour le moment, mais la compr├®hension de la pile est abord├®e de fa├¦on plus d├®taill├®e dans la partie 2 qui suit.
VIII-I-2. Partie 2▲
Dans la pr├®sente partie 2, vous trouverez des informations qui ne sont pas une lecture essentielle pour les programmeurs en assembleur, mais peuvent se r├®v├®ler indispensables ├Ā un certain niveau de ma├«trise du langage.
VIII-I-2-a. La pile et la notion d'espace d'adressage virtuel▲
La valeur dans ESP est une adresse virtuelle. Si elle est, par exemple, d'une valeur de 64FE3Ch au d├®marrage, nous ne parlons pas ici d'une adresse dans la m├®moire physique r├®elle. Pour obtenir l'adresse dans la m├®moire physique r├®elle, le syst├©me a besoin de convertir (ou ┬½┬Ācartographier┬Ā┬╗) le 64FE3Ch selon ses propres enregistrements internes. Par exemple, cette adresse pourrait ├¬tre en r├®alit├® 2FE3Ch dans la m├®moire physique r├®elle. Une adresse virtuelle est donc juste une repr├®sentation pratique d'une position en m├®moire. On dit souvent que chaque application fonctionne dans son propre espace d'adressage virtuel. En th├®orie, toute la gamme d'adresses 32 bits (z├®ro ├Ā 4┬ĀGo) est disponible pour chaque application. Dans la pratique, ce n'est pas le cas, mais il est vrai que chaque application en cours d'ex├®cution sur le syst├©me peut utiliser la m├¬me plage d'adresses virtuelles. Il n'y a pas de conflit entre elles parce que le syst├©me sait quelle application adresse la m├®moire ├Ā tout moment et peut donc pointer l'application ├Ā la bonne place dans la m├®moire physique. Donc, ├Ā un moment donn├®, il est probable qu'il existe plusieurs applications avec la m├¬me valeur de ESP. Mais, en r├®alit├®, cette valeur pointera effectivement vers des parties diff├®rentes de la m├®moire physique.
VIII-I-2-b. La pile au d├®marrage┬Ā: contenu▲
Dans Windows, le thread principal se voit allouer sa propre zone de pile par le syst├©me lors de son chargement. Le syst├©me lui-m├¬me utilise ce thread et la zone de pile pour ses propres besoins avant d'appeler l'adresse du point d'entr├®e du programme. Vous pouvez le voir dans le d├®bogueur. D├®marrez votre programme jusqu'├Ā l'adresse de d├®part et scrutez la valeur de ESP. Maintenant, ouvrez une fen├¬tre d'inspection de la valeur de ce registre. Vous pourriez vous attendre ├Ā ce que cette valeur se situe en bas de la zone de m├®moire, mais tel n'est pas le cas. Si vous faites d├®filer l'inspecteur au fond de la zone de m├®moire (faites-le d├®filer jusqu'├Ā l'adresse la plus ├®lev├®e), vous voyez qu'il y a d├®j├Ā eu beaucoup d'activit├® dans la pile o├╣ le syst├©me s'est pr├®par├® pour son appel de l'adresse du point d'entr├®e du programme. Il est int├®ressant de constater (dans Windows 98 en tout cas) que la derni├©re valeur sur la pile avant que l'application ait ├®t├® appel├®e est une adresse de retour dans Kernel32.dll. Ceci indique qu'une fonction dans Kernel32.dll a appel├® l'application. En raison de cette adresse de retour, il est possible d'utiliser un simple RET pour mettre fin ├Ā un processus, plut├┤t que d'appeler l'API ExitProcess. Bien s├╗r, cela ne fonctionne que si la pile est en ├®quilibre de telle sorte que l'ex├®cution du code se poursuive dans la fonction de l'appelant dans Kernel32.dll.
Un peu plus loin en bas de la pile, nous pouvons voir le nom du fichier de l'application, et beaucoup plus bas, que l'adresse du propre gestionnaire d'exception du syst├©me pour le thread principal de l'application a ├®t├® mise sur la pile. Toutes ces choses montrent que la propre zone pile de l'application (et le propre thread) est utilis├®e par le syst├©me pour pr├®parer l'appel de l'application.
VIII-I-2-c. La pile au d├®marrage┬Ā: dimension▲
Dans Windows, lorsque de la m├®moire est r├®serv├®e pour les besoins d'une application, une plage d'adresses virtuelles est allou├®e par le syst├©me. Cette allocation r├®serve ces adresses ├Ā l'usage exclusif de l'application. Si cette derni├©re requiert plus de m├®moire, les m├¬mes adresses ne peuvent pas ├¬tre r├®utilis├®es. Aucune m├®moire physique n'est effectivement utilis├®e jusqu'├Ā ce que la m├®moire soit r├®serv├®e. Ce n'est qu'├Ā ce stade que les adresses virtuelles qui ont ├®t├® allou├®es sont mapp├®es sur la ou les zones de m├®moire physique dont le syst├©me dispose.
Il est ├®vident que pour que cet arrangement fonctionne, le syst├©me a besoin de conna├«tre la taille maximale de m├®moire contigu├½ qui peut ├¬tre engag├®e. Celle-ci constitue alors la plage d'adresses allou├®e.
Lors de la r├®servation de m├®moire pour la pile, la m├¬me d├®marche est mise en ┼ōuvre. Au moment du d├®marrage d'une application, le syst├©me a besoin de conna├«tre la quantit├® de m├®moire ├Ā allouer ├Ā la pile, et l'ampleur de la r├®servation en premi├©re instance. Ces deux param├©tres sont contenus dans l'ex├®cutable ├Ā + 48h et + 4Ch respectivement dans l'en-t├¬te optionnel (pour comprendre exactement o├╣ cela se trouve dans le fichier ex├®cutable, vous devez conna├«tre le format de fichier PE). Comme on le voit ci-dessous, ces param├©tres s'appliquent non seulement au thread principal de l'application, mais ├®galement ├Ā de nouveaux threads g├®n├®r├®s par l'application.
La plupart des ├®diteurs de liens utilisent respectivement 1MB et 4K par d├®faut (la taille normale de page) pour ces valeurs. Avec GoLink, vous pouvez modifier les valeurs par d├®faut en utilisant respectivement les commutateurs /stacksize et /stackinit (voir le manuel de GoLink pour conna├«tre leur utilisation).
VIII-I-2-d. Agrandissement de la pile au moment du lancement▲
Le syst├©me d├®tecte si une application tente de lire ou d'├®crire en dehors de la zone de pile r├®serv├®e en ayant recours ├Ā la gestion d'exceptions. Si la tentative se situe dans la zone de pile autoris├®e, la nouvelle m├®moire sera engag├®e selon les besoins (en W9x). M├¬me si une tentative est faite pour agrandir la pile au-del├Ā de la zone allou├®e, sous NT (mais pas W9x) le syst├©me va essayer d'allouer plus de m├®moire, mais ce ne sera pas possible si les adresses virtuelles alors n├®cessaires ont ├®t├® allou├®es ├Ā d'autres des zones de m├®moire.
VIII-I-2-e. Zone de pile autoris├®e utilisable▲
La pile n'est pas consid├®r├®e comme appropri├®e ├Ā la m├®morisation de grandes quantit├®s de donn├®es et cette limitation est confort├®e par Windows au travers de son m├®canisme d'exception. Dans W9x la zone de pile utilisable autoris├®e est entre la valeur de ESP courante et la fronti├©re de page qui suit, plus la taille de la page. Par exemple, si ESP est 64FE3Ch, que la limite de page suivante est 64F000h et qu'une page suppl├®mentaire (qui est g├®n├®ralement fix├® ├Ā 4K par le syst├©me) s'impose, cela vous emm├©ne ├Ā 64E000h┬Ā:
| 64D000h | ||
| Page 4K indisponible |
64E000h | |
| Page 4K disponible |
64F000h | |
| ESP (64FE3Ch) est ici ŌåÆ | Page 4K disponible |
650000h |
Donc, si ESP est ├Ā 64FE3Ch, vous constaterez que l'instruction
MOV D[ESP-1E40h], 0provoque une exception, parce que l'adresse r├®sultante point├®e sur la pile correspond ├Ā 64DFFCh et que cette valeur se situe dans une r├®gion indisponible car non r├®serv├®e par le syst├©me.
Et vous ne pouvez pas non plus contourner cela en d├®pla├¦ant ESP. Dans W9x le syst├©me vous permet de d├®placer ESP seulement jusqu'├Ā la limite de page suivante + la taille d'une page moins quatre octets. Par exemple, si ESP est 64FE3C une simple instruction sera autoris├®e ├Ā d├®placer ESP de 1E38h (soit 7836 octets en d├®cimal). Cela signifie que l'instruction
SUB ESP, 1E38hram├©ne ESP ├Ā 64E004h et qu'elle est autoris├®e. En revanche, l'instruction
SUB ESP, 1E3Chva provoquer une exception. La diff├®rence de quatre octets dans la position qui d├®clenche l'exception sugg├©re qu'il existe deux m├®canismes de protection diff├®rents au travail ici.
De ce qui pr├®c├©de, il pourrait sembler que la taille des donn├®es ├Ā mettre sur la pile est limit├®e ├Ā 4K, mais cela est faux. Il existe deux fa├¦ons d'├®viter que ces exceptions ne se produisent et de permettre ainsi d'utiliser la pile pour des zones de donn├®es plus importantes.
La premi├©re fa├¦on consiste ├Ā d├®placer ESP selon un processus incr├®mental. Cela permet de garantir que le syst├©me engage la m├®moire progressivement comme pr├®vu. Le code suivant cr├®e en toute s├®curit├® une zone de 40K octets sur la pile┬Ā:
MOV ECX, 10
L0:
SUB ESP, 1000h
MOV D[ESP], 0
LOOP L0Ici, le syst├©me est invit├® ├Ā r├®server dix blocs 4K de m├®moire de pile. Au terme de cette op├®ration, ESP pointe ensuite le sommet de cette zone de pile. Ce processus n'est pas particuli├©rement rapide puisque le syst├©me doit r├®server de la m├®moire dix fois de suite. Une m├®thode plus rapide consiste ├Ā charger le syst├©me de r├®server une zone d'embl├®e plus grande que la zone de m├®moire habituelle pour la pile lorsque l'application est charg├®e. Avec GoLink vous pouvez le faire en utilisant le commutateur /stackinit.
Par exemple┬Ā:
/stackinit 0A000veillera ├Ā ce que 40K de m├®moire soient r├®serv├®s sur la pile au d├®marrage. Vous pourrez alors d├®placer ESP en toute s├®curit├® en utilisant l'instruction┬Ā:
SUB ESP, 0A000hqui vous octroie 40K de m├®moire sur la pile enti├©rement ├Ā votre disposition.
VIII-I-2-f. Utilisation de la pile pour m├®moriser des flux de donn├®es▲
Lorsque des pr├®cautions sont prises, la pile peut ├¬tre utilis├®e pour m├®moriser des flux de donn├®es assez volumineux. Les principes ├Ā retenir sont les suivants.
- Toujours restaurer ESP ├Ā l'├®quilibre lorsque vous en avez termin├® avec la pile.
- Ne jamais ├®crire sur l'adresse [ESP], sauf si vous avez soustrait au moins 4 octets de la valeur originale de ce registre qui, rappelons-le, d├®tient l'adresse de retour de la proc├®dure. Ne jamais ├®crire sur l'adresse [ESP+n], sauf si un nombre suffisant d'octets a ├®t├® soustrait de ESP pour ├®viter d'├®craser d'autres donn├®es importantes.
- Si vous ne d├®placez pas ESP vers le haut de la zone de donn├®es, alors vous devez ├®crire les donn├®es dans l'ordre inverse, c'est-├Ā-dire selon des adresses cons├®cutivement d├®croissantes. Cela peut se faire de diverses mani├©res, la plus classique consistant sans doute ├Ā mettre ├Ā 1 le flag de direction par le biais de l'instruction STD, puis ├Ā utiliser l'instruction MOVS, par exemple┬Ā:
MOV ECX, 8000
MOV EDI, ESP
SUB EDI, 4
STD ; met ├Ā 1 le flag de direction (d├®cr├®mentation auto de ESI et EDI)
REP MOVSD ; copie ECX dwords de [ESI] ├Ā [EDI]
CLD ; RAZ flag de directionCette portion de code copie 8000 DWords dans la pile. Notez que SUB EDI, 4 ├®vite l'├®criture sur [ESP] qui d├®tient l'adresse de retour de la proc├®dure. Il n'y a pas de probl├©me d'agrandissement de la m├®moire dans la mesure o├╣ l'├®criture est d├®cr├®mentale, de sorte que le syst├©me cr├®e correctement de nouvelles zones de m├®moire 4K lorsqu'il en a besoin.
- Si vous ne positionnez pas ESP au sommet de la zone de donn├®es, vous devez prendre les pr├®cautions vis├®es dans le paragraphe pr├®c├®dent. Apr├©s avoir fait cela, vous pouvez ├®crire dans la pile en direction de l'avant.
VIII-I-2-g. La pile dans les applications multithreads▲
Chaque thread de votre application a ses propres registres et sa propre pile. Autrement dit, lorsque le syst├©me donne du temps processeur ├Ā un thread, il bascule sur le contexte de registre (register context) qui lui est sp├®cifique. Celui-ci contient toutes les valeurs de registres correspondant ├Ā l'ach├©vement du dernier temps-processeur ex├®cut├® sur le thread. ├ētant donn├® que les registres comprennent ESP, la valeur de ce dernier sera ├®galement correctement commut├®e de telle sorte que la zone appropri├®e de m├®moire physique sera utilis├®e par le thread comme sa pile. Il en r├®sulte qu'un thread peut compter sur le fait qu'il peut utiliser sa pile comme une zone discr├©te de la m├®moire qui ne sera pas perturb├®e par d'autres threads. Vous pouvez le constater dans le d├®bogueur. Vous pouvez ├®galement observer que ESP change toujours consid├®rablement lors de l'ex├®cution des changements d'un thread ├Ā l'autre.
Quand un thread d├®marre, une zone de pile lui est allou├®e. ├Ć titre d'exemple, il a ├®t├® trouv├® sous W98 que la pile du thread principal d'une application se situait ├Ā 64FE3Ch et que, lorsqu'un nouveau thread a ├®t├® lanc├®, sa pile se situait ├Ā 75FF9Ch. Dans un autre test, ├Ā l'occasion de la cr├®ation de six nouveaux threads, il a pu ├¬tre constat├® que leurs piles ont commenc├® respectivement ├Ā 19DEF9Ch, 1AFFF9Ch, 1C1FF9Ch, 1D3FF9Ch, 1E5FF9Ch et 1F7FF9Ch. Vous pouvez donc en d├®duire que le syst├©me s├®pare l'adresse virtuelle de chaque zone de pile par 128KB plus de la zone de 1Mo par d├®faut. Ceci est probablement un am├®nagement pour laisser de la place ├Ā l'usage propre du syst├©me de la pile et aussi une certaine marge de man┼ōuvre suppl├®mentaire. La modification d'allocation de la taille de la pile ├Ā 200000h (2MB) en utilisant le commutateur /stacksize puis la cr├®ation de six nouveaux threads se sont traduits par des zones de pile s├®par├®es par 128KB en plus des 2Mo.
VIII-I-2-h. La trame de pile et les donn├®es locales▲
Une trame de pile est une zone sp├®cifique de la pile qui h├®berge l'adresse de retour d'une fonction ainsi que les donn├®es utilis├®es par cette fonction sans risque d'├®crasement parce que le contenu du registre ESP a ├®t├® d├®cr├®ment├®e d'une valeur correspondant justement ├Ā la taille de ces donn├®es. Ces derni├©res sont conserv├®es dans une trame de pile et sont appel├®es ┬½┬Ādonn├®es locales┬Ā┬╗. Elles sont pr├®vues uniquement pour une utilisation dans la trame de pile concern├®e et n'ont pas vocation ├Ā ├¬tre trait├®es par le programme en g├®n├®ral. Consid├®rons cet exemple simple┬Ā:
PROCEDURE1:
SUB ESP, 20h ; constitution d'un espace sur la pile pour les donn├®es locales
; utilisation de la zone de donn├®es locales
CALL PROCEDURE2
; retour de la PROCEDURE2
; on continue ├Ā utiliser la zone de donn├®es locales
ADD ESP, 20h ; r├®tablissement de ESP ├Ā l'├®quilibre
RETet
PROCEDURE2:
PUSH EAX, EBX, ECX
; r├®alisation de divers calculs
POP ECX, EBX, EAX
RETIci, la trame de pile est cr├®├®e par l'instruction SUB ESP, 20h qui a pour effet de r├®duire la valeur de ESP de 32 octets cr├®ant ainsi un espace pour 8 DWords sur la pile. Maintenant, du fait que ESP a ├®t├® d├®plac├®, tout ce qui arrive dans PROCEDURE2 ne peut remplacer ces 8 DWords. V├®rifions ce point visuellement en formant l'hypoth├©se que ESP prend la valeur 64FE38h au d├®but de PROCEDURE1┬Ā:
| 64FE08h | Contient la valeur en ECX ins├®r├®e par PROCEDURE2 | |
| 64FE0Ch | Contient la valeur en EBX ins├®r├®e par PROCEDURE2 | |
| 64FE10h | Contient la valeur en EAX ins├®r├®e par PROCEDURE2 | |
| ESP pointe le d├®but de PROCEDURE2ŌåÆ | 64FE14h | Contient l'adresse de retour de PROCEDURE2 |
| Trame de pile de PROCEDURE1 | 64FE18h ├Ā 64FE34h |
8 DWords pour les donn├®es locales |
| 64FE38h | Contient l'adresse de retour de PROCEDURE1 |
VIII-I-2-i. Adressage des donn├®es locales▲
Note┬Ā: l'adressage des donn├®es locales est automatis├® en utilisant les directives FRAME .. END avec GoAsm et PROC .. ENDP avec MASM.
Puisque ESP pointe vers le haut de la zone de donn├®es locale, vous pouvez traiter les donn├®es en utilisant ESP. Ainsi, dans l'exemple ci-dessus le premier dword des donn├®es locales serait disponible ├Ā [ESP] imm├®diatement apr├©s le SUB ESP, 20h. Mais l'utilisation de ESP pour pointer les donn├®es locales sur la pile peut se r├®v├®ler p├®rilleuse parce ESP se d├®placera ├Ā chaque CALL, PUSH ou POP au sein de la proc├®dure. Pour cette raison, il est de pratique courante que l'on y substitue le registre EBP qui est exempt de tout d├®sagr├®ment de ce type. La valeur initiale de EBP est habituellement fix├®e au d├®but de la trame de la pile vers le bas des donn├®es locales et ne sera pas modifi├®e avant que l'ex├®cution ne quitte la trame de pile. De cette fa├¦on, vous pouvez ├¬tre certain que les donn├®es locales peuvent toujours ├¬tre trait├®es en utilisant un d├®calage par rapport ├Ā EBP.
De cette mani├©re, le code pour une trame de pile classique ressemble ├Ā ceci┬Ā:
TypicalStackFrame:
PUSH EBP ; sauvegarde la valeur de EBP qui va ├¬tre alt├®r├®e ŌöÉ
MOV EBP, ESP ; EBP = valeur courante du pointeur de pile Ōöé "prologue"
SUB ESP, 0Ch ; cr├®ation d'un espace pour les donn├®es locales Ōöś
; POINT "X"
;
; code de la proc├®dure (ne modifie jamais EBP)
;
MOV ESP, EBP ; restaure le pointeur de pile ├Ā sa valeur d'origine ŌöÉ
POP EBP ; restaure la valeur de EBP Ōöé "├®pilogue"
RET ; retourne ├Ā l'appelant en ajustant le pointeur de pile ŌöśDans cet exemple, nous avons d├®plac├® le pointeur de pile de 12 octets. Au point ┬½┬ĀX┬Ā┬╗ la pile par r├®f├®rence ├Ā EBP ressemble ├Ā ceci┬Ā:
| EBP-10h | Le prochain PUSH ira ici | |
| ESP ici au point ┬½┬ĀX┬Ā┬╗ŌåÆ | EBP-0Ch | Espace pour les donn├®es locales |
| EBP-8h | Espace pour les donn├®es locales | |
| EBP-4h | Espace pour les donn├®es locales | |
| EBP | Sauvegarde de EBP | |
| EBP+4h | Adresse de retour de TypicalStackFrame |
Maintenant, au travers de la trame de pile, quoi qu'il puisse arriver ├Ā ESP, les donn├®es locales seront toujours accessibles ├Ā [EBP-4h], [EBP-8h] et [EBP-0Ch].
Notez comment ESP est r├®tabli ├Ā l'├®quilibre automatiquement par l'utilisation de MOV ESP, EBP juste avant le retour au programme appelant.
En r├®alit├®, cette fonction d├®volue ├Ā EBP peut surprendre car n'importe quel registre peut en faire autant. Mais EBP est traditionnellement utilis├® ├Ā cet effet et votre code n'en sera que plus compr├®hensible vis-├Ā-vis des autres si telle est votre pr├®occupation.
VIII-I-2-j. Acc├©s aux param├©tres ├Ā partir de la pile▲
Nous avons vu d├®j├Ā comment passer des param├©tres sur la pile ├Ā d'autres proc├®dures. Maintenant, nous allons voir comment utiliser les param├©tres pass├®s aux proc├®dures de l'int├®rieur desdites proc├®dures. Fondamentalement, ces param├©tres sont plus bas dans la pile de sorte qu'ils ne risquent pas d'├¬tre ├®cras├®s dans des circonstances de fonctionnement normales. Pour cette raison, il n'est absolument pas n├®cessaire de les r├®cup├®rer ni de les sauvegarder. Lors de l'entr├®e dans une proc├®dure, ESP pointe l'adresse de retour de la proc├®dure (ins├®r├®e par CALL). Les param├©tres seront donc successivement ├Ā [ESP + 4h], [ESP + 8h], [ESP + 0Ch] et ainsi de suite, selon leur nombre. Mais il peut ├¬tre difficile de rep├®rer les param├©tres avec ESP de mani├©re fiable car ce registre ne va pas arr├¬ter de changer au gr├® des PUSH, POP ou CALL qui peuvent ├¬tre rencontr├®s dans le code de la proc├®dure. C'est l├Ā que s'impose l'utilisation de EBP pour pointer les param├©tres ind├®pendamment des al├®as du code.
Si vous avez le code de prologue┬Ā:
PUSH EBP ; sauvegarde la valeur de EBP qui va ├¬tre alt├®r├®e ŌöÉ
MOV EBP, ESP ; EBP = valeur courante du pointeur de pile Ōöé "prologue"
SUB ESP, 0Ch ; cr├®ation d'un espace pour les donn├®es locales ŌöśLorsque ESP est copi├® dans EBP, il est de 4 octets inf├®rieur en valeur par rapport au d├®but de l'appel (cela est d├╗ au premier PUSH EBP). Par cons├®quent, les param├©tres peuvent maintenant ├¬tre consult├®s aux adresses [EBP+8h], [EBP+0Ch], [EBP+10h] et ainsi de suite, selon le nombre de param├©tres.
VIII-I-2-k. Utilisation de la pile dans les proc├®dures callback de Windows▲
Les deux techniques qui viennent d'├¬tre expos├®es (constitution d'un espace pour les donn├®es locales et param├©tres d'adressage) sont n├®cessaires dans les proc├®dures callback de Windows. La proc├®dure callback la plus souvent rencontr├®e dans les programmes Windows est la proc├®dure de fen├¬tre. C'est dans son cadre que Windows envoie des ┬½┬Āmessages┬Ā┬╗ et qu'il en attend la r├®ponse correcte. Windows appelle la proc├®dure de fen├¬tre ├Ā l'aide du propre thread du programme. Cela se produit g├®n├®ralement lorsque le programme se trouve dans la boucle de message, soit en attente d'un retour de l'API GetMessage, soit pendant l'ex├®cution de l'API DispatchMessage.
Heureusement, dans GoAsm, vous pouvez utiliser FRAME ŌĆ” ENDF pour r├®cup├®rer les param├©tres envoy├®s par Windows et les adresser selon leur nom. FRAME ŌĆ” ENDF vous permet tout aussi facilement de constituer des zones de donn├®es locales adressables nominativement. Et vous pouvez ├®galement pr├®server les registres ainsi que restaurer la pile ├Ā l'├®quilibre automatiquement. Le pr├®sent manuel vous renseignera compl├©tement sur ces diff├®rentes fonctionnalit├®s ou vous pouvez ├®galement vous reporter utilement ├Ā la partie n┬░ 1 de cette annexe.
VIII-J. ComprendreŌĆ” la m├®morisation invers├®e▲
Cette question rev├¬t une certaine importance si vous projetez d'examiner des donn├®es, de la m├®moire ou, plus g├®n├®ralement, votre ordinateur ├Ā l'aide d'un d├®bogueur.
Fondamentalement, les processeurs Intel ne conservent pas les donn├®es en m├®moire dans l'ordre auquel vous vous attendez. Au lieu de cela, les donn├®es sont stock├®es en inverse sur la base d'un octet pour un octet.
Voyons cela plus en d├®tail┬Ā: un seul octet est stock├® ├®videmment en m├®moire ├Ā l'adresse attendue. On s'en serait dout├®ŌĆ” Mais un mot (deux octets) sera stock├® en m├®moire avec l'octet le moins significatif ├Ā l'adresse du mot en m├®moire et l'octet le plus significatif ├Ā l'adresse imm├®diatement sup├®rieure.
Pour une s├®quence d'octets, on parle parfois de format ┬½┬Ālittle-endian┬Ā┬╗ parce que l'octet le moins significatif est en premier et le plus significatif en second. L'inverse est appel├® ┬½┬Ābig-endian┬Ā┬╗ et est utilis├® par d'autres processeurs.
VIII-J-1. Exemple du mot (Word)▲
Supposons donc que vous ayez un mot de valeur 248Ch qui doit ├¬tre stock├® ├Ā 400000h. Il sera stock├® de la fa├¦on suivante┬Ā:
- 8Ch ├Ā l'adresse 400000h┬Ā;
- 24h ├Ā l'adresse 400001h.
Lorsque la m├®moire ├Ā 400000h est lue dans un registre 16 bits (soit un mot) par une instruction de type Word, les octets seront lus dans le sens inverse afin que la valeur 248Ch soit charg├®e dans le registre.
VIII-J-2. Exemple du double-mot (DWord)▲
Un DWord (quatre octets) sera stock├® dans la m├®moire avec l'octet le moins significatif ├Ā l'adresse du dword en m├®moire, puis les deux prochains octets et enfin avec l'octet le plus significatif ├Ā la quatri├©me adresse vers le haut.
Par exemple, supposons que vous ayez un dword de valeur 12345678h devant ├¬tre stock├® ├Ā l'adresse 400000h. Il sera stock├® de la fa├¦on suivante┬Ā:
- 78h ├Ā l'adresse 400000h┬Ā;
- 56h ├Ā l'adresse 400001h┬Ā;
- 34h ├Ā l'adresse 400002h┬Ā;
- 12h ├Ā l'adresse 400003h.
Lorsque la m├®moire ├Ā 400000h est lue dans un registre 32 bits par une instruction DWord, les octets sont lus dans le sens inverse afin que la valeur 12345678H soit charg├®e dans le registre.
On notera que les quartets de l'octet ne sont invers├®s ├Ā aucun moment.
├Ć pr├®sent, vous vous interrogez peut-├¬tre sur les raisons de cette pratique pour le moins exotique. Ne serait-il pas beaucoup plus facile de stocker des donn├®es dans le m├¬me ordre que nous les visualisons┬Ā? Eh bien, ce serait bien pour nous, mais pas pour l'ordinateur. Et ce n'est pas quelque chose que vous pouvez reprocher au langage assembleur. Toutes les donn├®es quelle que soit la langue utilis├®e sont stock├®es de cette mani├©re sur les processeurs Intel. Normalement, c'est transparent pour le programmeur et vous ne devez pas vous inqui├®ter ├Ā ce sujet.
VIII-K. Quelques conseils et astuces de programmation▲
VIII-K-1. Quelques conseils de programmation▲
VIII-K-1-a. Usage traditionnel des registres▲
Certaines instructions utilisent des registres particuliers pour effectuer certaines t├óches┬Ā; d'autres s'av├©rent plus rapides si certains registres sont utilis├®s┬Ā; dans les premiers processeurs, enfin, seuls certains registres ├®taient multiusages. Ces trois constats auxquels il convient d'associer l'utilisation traditionnelle des registres ├®tablie par les programmeurs en assembleur au fil des ans, ont ├®tabli une sorte de corpus de r├©gles informel sur la fa├¦on dont les registres doivent ├¬tre utilis├®s. Si vous vous conformez ├Ā ces quelques r├©gles, la lisibilit├® et la portabilit├® de votre code s'en ressentiront sensiblement.
- Utilisez EAX pour transmettre des donn├®es ├Ā une proc├®dure et pour retourner des donn├®es ├Ā l'issue d'une proc├®dure ├Ā destination du code appelant. Les API Windows elles-m├¬mes utilisent EAX pour retourner une valeur ├Ā l'appelant. Les formats AL, AX et EAX peuvent ├®galement ├¬tre privil├®gi├®s dans la mesure du possible pour recevoir des donn├®es de la m├®moire et en envoyer, car ils travaillent un peu plus rapidement que d'autres registres. Par exemple utiliser MOV AL, [ESI] de pr├®f├®rence ├Ā MOV DL, [ESI]. De m├¬me, si vous avez besoin d'utiliser ADD, AND, ADC, CMP, MOV, OR, SUB, TEST, XCHG, avec une valeur imm├®diate (c'est-├Ā-dire un nombre comme dans MOV AL, 23h) utiliser AL, AX ou EAX si vous pouvez car l'instruction utilise moins d'opcodes que si vous utilisiez un autre registre.
- Utilisez le registre EDX comme sauvegarde de EAX si ce dernier est d├®j├Ā en cours d'utilisation.
- Utilisez ECX comme compteur. Ce registre est en effet utilis├® directement en tant que tel par certaines instructions. Par exemple, JECXZ est une instruction sp├®ciale qui effectue un saut si ECX est nul. De m├¬me, les instructions LOOP, SCAS et MOVS utilisent toutes ECX comme compteur.
- Utilisez EBX pour h├®berger des donn├®es g├®n├®rales ou pour adresser la m├®moire comme, par exemple MOV EAX, [EBX] ou MOV [EBX], EDX.
- Utilisez ESI d├©s lors que vous devez lire de la m├®moire. Par exemple┬Ā: MOV EAX, [ESI] et EDI si vous devez ├®crire dans la m├®moire. Par exemple, MOV [EDI], EAX. Ceci est coh├®rent avec les pratiques d'adressage des instructions LODSD, STOSD et MOVSD mais ne constitue en aucun cas une obligation de codage.
- Utilisez l'un des registres de base ou d'index dans les instructions utilisant un adressage complexe de la m├®moire par exemple MOV EAX, [memptr+ESI*4+ECX].
- N'utilisez jamais ESP autrement qu'en tant que pointeur de pile, sauf si vous avez une routine qui n'a pas du tout d'activit├® de pile. Dans ce cas, vous pouvez sauvegarder la valeur de ESP en m├®moire et la restaurer avant de retourner ├Ā l'appelant de la routine.
- Traditionnellement, EBP est utilis├® pour adresser les donn├®es locales sur la pile dans les routines callback. EBP et sa composante BP en 16 bits peuvent ├¬tre utilis├®s en tant que registres g├®n├®raux en programmation Windows, mais vous devez ├¬tre tr├©s prudent si vous utilisez des trames de pile (FRAME dans GoAsm) ou des donn├®es locales (LOCAL dans GoAsm). En effet, les param├©tres de trame de pile et les donn├®es locales sont adress├®s ├Ā l'aide de EBP associ├® ├Ā un offset positif ou n├®gatif. Si EBP est modifi├®, les param├©tres et donn├®es locales ne pourront plus ├¬tre adress├®s de mani├©re simple tant qu'il n'aura pas ├®t├® r├®tabli ├Ā sa valeur pr├®c├®dente. Notez qu'en code 16 bits, BP ├®tait con├¦u pour agir en relation avec le segment de la pile, sauf s'il ├®tait utilis├® avec un remplacement de segment (override). Mais en Windows 32 bits, EBP peut ├¬tre utilis├® pour traiter une partie de la zone de m├®moire ┬½┬Āflat┬Ā┬╗ de 4┬ĀGB.
- Les registres de segment CS, DS et SS sont encore utilis├®s par Windows, m├¬me dans sa version 32 bits, de sorte que vous devez imp├®rativement ├®viter de les utiliser. De m├¬me, vous ne pouvez pas utiliser ES, FS ou GS non plus. En Windows 98 et ses versions ult├®rieures, toute tentative contrevenant ├Ā ces exigences provoque une exception.
- Si vous avez besoin d'utiliser des registres ordinaires pour h├®berger une information 64 bits, utilisez le couple de registres EDX:EAX dans lequel EDX d├®tient les bits les plus significatifs. Cela concorde avec les instructions de d├®calage 64 bits SHLD et SHRD, avec CDQ, MUL/IMUL et DIV/IDIV.
VIII-K-1-b. Utilisation de Windows┬Ā: registres et pile▲
Vous pouvez compter sur le fait que toutes les API Windows sauvegardent et restaurent les registres EBP, EBX, EDI et ESI. Par cons├®quent utilisez ces registres pour h├®berger les handles et pointeurs qui doivent ├¬tre utilis├®s plus d'une fois ├Ā travers des s├®quences d'appels d'API.
Tout comme Windows pr├®serve la valeur de ces registres dans les API, vous devez ├®galement veiller ├Ā ce qu'ils soient maintenus dans vos proc├®dures callback. Je recommande que, dans chacune de vos proc├®dures callback et de fen├¬tre, vous enregistriez ces registres au d├®but de la proc├®dure et que vous les restauriez ├Ā la fin.
Vous pouvez ├®galement compter sur les API Windows pour la restauration de la pile sous r├®serve d'avoir fourni en entr├®e le nombre exact de param├©tres requis. Cependant, je suis tomb├® sur une exception ├Ā cette r├©gle (wsprintf). Mais, ceci est document├® dans le SDK Windows.
VIII-K-1-c. Mise en pile des registres par ordre alphab├®tique▲
Si vous avez besoin de pr├®server une s├®rie de registres dans une proc├®dure particuli├©re, il est conseill├® de les pousser en pile (PUSH) dans l'ordre alphab├®tique. De cette fa├¦on, vous pouvez facilement v├®rifier que les POP sont dans l'ordre alphab├®tique inverse, pr├®servant ainsi la restauration des registres avec leur valeur d'origine. Par exemple┬Ā:
PUSH EBP, EBX, EDI, ESI
;.
;. ; votre code vient ici
;.
POP ESI, EDI, EBX, EBPSi vous pr├®f├®rez, vous pouvez utiliser en GoAsm l'instruction USES qui pr├®servera et restaurera automatiquement les registres pour vous.
VIII-K-1-d. Protection du code▲
Il est important de concevoir des programmes aussi robustes que possible en r├®duisant au minimum le risque d'un accident de programme ou d'une boucle infinie. Voici quelques fa├¦ons d'agir en ce sens.
- Avant d'utiliser les pr├®fixes de r├®p├®tition REP, REPZ ou REPZ qui utilisent ECX comme registre de compte ├Ā rebours, et avant l'utilisation de LOOP, LOOPZ ou LOOPZ, toujours s'assurer que ECX n'est pas ├Ā z├®ro. Si l'instruction est effectu├®e avec ECX = 0, elle fera en effet 4294967296 op├®rations┬Ā! Si vous voulez ├¬tre doublement prudent, vous pouvez ├®galement tester le bit de plus fort poids de ECX et vous assurer qu'il n'est pas ├Ā 1, moyen simple de pr├®venir une valeur anormalement ├®lev├®e. On y parvient simplement au moyen de l'instruction OR ECX, ECX suivie de JS> L2.
- ├ēvitez une division par z├®ro en vous assurant pr├®alablement que le diviseur n'est pas nul (registre ECX dans DIV ECX par exemple) ├Ā d├®faut de quoi une exception est g├®n├®r├®e avec tous les troubles qui peuvent s'ensuivre pour votre programme.
- Chaque fois que vous pratiquez une division avec un diviseur 32 bits (DIV ECX par exemple) et que vous n'utilisez que EAX pour le dividende, forcez EDX ├Ā z├®ro. Dans le cas d'une division avec un diviseur 16 bits (DIV CX par exemple) et que vous n'utilisez que AX pour le dividende, forcez DX ├Ā z├®ro.
- MUL peut provoquer une exception de d├®bordement si les valeurs qui lui sont donn├®es sont trop ├®lev├®es. Si ces valeurs sont dans les registres, v├®rifier qu'elles ne sont pas trop ├®lev├®es avant d'appeler l'instruction MUL.
- Avant d'essayer de lire ou ├®crire dans un emplacement m├®moire adress├® par registre, v├®rifiez que le contenu de ce dernier n'est pas nul. Comme pr├®caution suppl├®mentaire, vous pouvez vous aider de l'API Windows IsBadReadPtr pour r├®aliser ce diagnostic.
- Enfin, prot├®gez-vous du code en utilisant la gestion des exceptions. Voir mon article tr├©s d├®taill├® sur ce sujet disponible ├Ā partir de mon site.
VIII-K-1-e. D├®veloppement incr├®mental du code▲
Lors de l'├®criture d'un nouveau code et d├©s que vous avez termin├® une partie restreinte de celui-ci, le tester en temps r├®el dans toutes les conditions possibles et aussi, si n├®cessaire, ex├®cutez-le en pas-├Ā-pas au travers du d├®bogueur. De cette fa├¦on, si votre programme fait quelque chose d'inattendu vous pouvez ├¬tre raisonnablement certain que la faute en est imputable au code que vous venez d'├®crire. Si vous abandonnez le test jusqu'├Ā ce que vous ayez ├®crit un autre code, la faute sera plus difficile ├Ā trouver.
VIII-K-1-f. Fonctions r├®utilisables▲
Prenez en compte le fait que certaines fonctions que vous ├®crivez pour votre programme peuvent ├¬tre utiles dans d'autres parties dudit programme ou dans les futurs programmes que vous ├®crirez. Vous allez alors vous retrouver avec un certain nombre de modules r├®utilisables qui assurent des t├óches sp├®cifiques, par exemple le chargement d'une cha├«ne ├Ā destination de la m├®moire, l'├®criture en m├®moire d'une valeur d├®cimale, la division par dix, le chargement d'une police de dialogue, ou le chargement d'un nouveau titre de fen├¬tre. Donnez aux fonctions des noms expressifs tels que LOAD_STRINGEDI ou DECIMAL_WRITE ou DIVIDE_BY_TEN et ainsi de suite. Vous pouvez ├®galement faire en sorte que ces modules d├®clarent eux-m├¬mes les donn├®es qu'ils utilisent pour les rendre encore plus ind├®pendants de leurs appelants. En programmation orient├®e objet on qualifierait ces modules d'┬½┬Āobjets┬Ā┬╗. Donc, vous ├¬tes maintenant dans la POO┬Ā! Pour faciliter cette approche modulaire, contentez-vous dans la mesure du possible d'une l'utilisation traditionnelle des registres, et veillez ├Ā sauvegarder et restaurer tous les registres utilis├®s par le module.
VIII-K-1-g. Divisez vos fonctions si elles sont trop volumineuses▲
L'approche modulaire de la programmation consiste ├®galement ├Ā faciliter la lisibilit├® de votre code en faisant notamment en sorte que le nom des petites fonctions appel├®es soit suffisamment explicite et vous aide ├Ā comprendre ce que font les grandes sections de code. Si vos fonctions deviennent trop grandes pour ├¬tre facilement compr├®hensibles, divisez-les en plus petites fonctions ├Ā appeler en donnant ├Ā chaque fonction un nom d├®crivant ce qu'elle fait. Je recommanderais de faire de m├¬me si la fonction n'est appel├®e qu'une seule fois. En tout ├®tat de cause, on retiendra qu'un appel ├Ā fonction ne g├®n├©re qu'une perte de vitesse insignifiante. En r├©gle g├®n├®rale, si l'un de vos sauts au sein d'une fonction (autre que les sauts pour quitter la fonction) ne peut pas ├¬tre cod├® en utilisant la forme courte (hors de la plage +127 / -128 octets), c'est un signe que votre fonction gagnerait ├Ā ├¬tre divis├®e en plus petites sections.
VIII-K-1-h. Valeurs et flags en retour de fonctions▲
Traditionnellement, EAX est utilis├® pour restituer une valeur en retour de l'ex├®cution d'une fonction, ce que font notamment les API Windows. En assembleur il est ├®galement habituel, si le travail d'une fonction est de trouver une adresse m├®moire, que celle-ci soit retourn├®e dans ESI, EDI ou EBX.
Il arrive aussi que les fonctions aient besoin de positionner un flag particulier lors de leur retour pour indiquer un r├®sultat de traitement. Les usages en la mati├©re sont les suivants┬Ā:
- retour Cf = 1 (Carry) pour montrer qu'une erreur est survenue┬Ā;
- retour Cf = 0 (not Carry) pour qualifier un succ├©s┬Ā;
- retour Zf = 0 ou 1 (Z├®ro ou non-Z├®ro) pour afficher le r├®sultat d'une action.
Les flags peuvent ├®galement ├¬tre utilis├®s pour inviter l'appelant ├Ā ne pas prendre d'autres mesures. Voici un exemple de la fonction GENERAL WNDPROC dans le programme de d├®mo HelloWorld2┬Ā:
CALL [EDX+ECX*8+4] ; appel de la proc├®dure appropri├®e pour le message
JNC >L4 ; Cf = 0 = ne pas appeler DefWindowProc
PUSH [ESP+18h], [ESP+18h], [ESP+18h], [ESP+18h]
CALL DefWindowProcA
L4:VIII-K-1-i. Qualit├® des descriptions et commentaires▲
Rappelez-vous qu'il peut vous arriver de vous r├®f├®rer ├Ā un code des ann├®es apr├©s que vous l'ayez ├®crit. C'est pourquoi, au tout d├®but du script source, il vous est recommand├® de d├®crire les fonctionnalit├®s du programme, d'expliquer comment il fonctionne, comment il doit ├¬tre assembl├® et soumis ├Ā l'├®diteur de liens. D├®crivez ├®galement chaque fonction ainsi que son fonctionnement, si ce n'est pas ├®vident. Ajoutez des commentaires ├Ā une ligne dans le script source s'il appara├«t que son action ne va pas de soi. Ajoutez des commentaires et des descriptions aux d├®clarations de donn├®es et aux mod├©les de structure.
VIII-K-1-j. Ordre des d├®clarations dans le script source▲
Bien que GoAsm soit un assembleur ├Ā une seule passe, il n'impose pas que les d├®clarations de donn├®es soient dans un endroit particulier du script source, bien qu'il soit habituel de d├®clarer des donn├®es avant le code qui en fait usage. En fait, GoAsm n'impose cette pr├®c├®dence qu'aux d├®finitions et mod├©les de structure qui doivent donc ├¬tre d├®clar├®s avant toute utilisation ├Ā d├®faut de quoi GoAsm ignorera tout de leur qualit├®.
Les donn├®es sont id├®alement align├®es sur une modularit├® correspondant ├Ā la taille des donn├®es. Ceci peut ├¬tre r├®alis├® au moyen de la directive ALIGN. Cependant, en cas de donn├®es de tailles diverses, un bon alignement sera obtenu automatiquement si l'ordre suivant est respect├® dans les d├®clarations de donn├®es, ├Ā partir de l'ouverture de la section de donn├®es┬Ā: QWords, DWords, mots, octets, cha├«nes. Les TWords sont mieux align├®s sur une modularit├® de 8 octets, mais un nombre impair de TWords d├®clar├®s au d├®but de la section de donn├®es bouleverse l'alignement du reste des donn├®es, car ils sont de 10 octets chacun.
Une d├®claration de donn├®es non initialis├®es n'affectera l'alignement en aucune mani├©re puisqu'il ne s'agit que d'une r├®servation d'espace et qu'elle ne concerne que la section .bss.
VIII-K-1-k. Meilleure direction des sauts conditionnels▲
Sur le Pentium III et versions ult├®rieures, le processeur d├®cide de mettre en cache la destination d'un saut conditionnel dans votre code en fonction de sa direction. La r├©gle utilis├®e par le processeur est que les destinations de sauts vers l'avant ne sont pas mises en cache, tandis que les destinations de sauts arri├©re le sont. Il en r├®sulte que votre code sera plus rapide si vous observez les r├©gles suivantes┬Ā:
- lors de la v├®rification des erreurs, par exemple dans le cas du test de la valeur dans EAX apr├©s un appel d'API, toujours sauter vers l'avant pour sortir en cas de d├®faillance┬Ā;
- dans les boucles, la boucle doit toujours faire un saut arri├©re vers le d├®but de la boucle┬Ā;
- dans les boucles, lors du test permettant de mettre fin ├Ā la boucle, toujours sauter vers l'avant pour sortir de la boucle.
VIII-K-1-l. Minuscules ou majuscules┬Ā?▲
Cette question rel├©ve, en grande partie, de choix personnels. Cependant, ma propre exp├®rience en mati├©re de programmation Windows m'a conduit ├Ā adopter ce qui suit pour rendre le script source aussi lisible que possible.
- Les mn├®moniques et noms de registres sont toujours soit en majuscules, soit en minuscules, mais ce choix doit demeurer coh├®rent tout au long du fichier.
- Les labels de code sont toujours en majuscules seulement. Cela distingue ces labels lorsqu'ils sont appel├®s ├Ā partir d'une API Windows qui combinera majuscules et minuscules. Par exemple, si vous observez cette r├©gle, vous saurez que CALL COMPARESTRING est un appel ├Ā l'une de vos propres proc├®dures et que CALL CompareStringA est un appel d'API Windows.
- Les labels de donn├®e et les noms de pointeur d├®crits dans le SDK Windows doivent ├¬tre utilis├®s en respectant la casse sp├®cifi├®e, tandis que les autres labels doivent ├¬tre en majuscules seulement. Encore une fois cela accro├«t la lisibilit├® du script source parce que les labels de donn├®e de Windows et les noms de pointeur sont bien connus de tous les programmeurs Windows. Vous savez par exemple que hwnd, hAccel ou szWindowName ont une signification particuli├©re pour Windows et sont d├®crits dans le SDK, alors que MBTITLE et MBMESSAGE sont sp├®cifiques ├Ā votre programme.
VIII-K-1-m. Sauvegardez votre travail r├®guli├©rement▲
Ceci est prudent non seulement en cas de d├®faillance du disque, mais il y a aussi une autre raison. En programmation, vous devez parfois prendre la d├®cision de changer radicalement la fa├¦on dont tout ou partie de votre programme fonctionne. Vous apportez, de ce fait, des modifications majeures ├Ā votre code. Cependant, ├Ā la fin de cette d├®marche, vous pourriez d├®cider de revenir au codage d'origine. Alors conservez une copie de toutes les versions du script jusqu'├Ā ce que vous soyez certain d'├¬tre satisfait de votre changement radical┬Ā!
VIII-K-2. Quelques tours de main▲
VIII-K-2-a. Positionnement des flags▲
L'├®tat des flags refl├©te normalement le r├®sultat de l'ex├®cution d'une instruction particuli├©re, mais il est souvent n├®cessaire de les pr├®positionner manuellement afin de rendre ce r├®sultat pertinent. En dehors de CLC, CMC et STC permettant de forcer le flag de Carry ├Ā 0 ou ├Ā 1 et de CLD et STD permettant de faire de m├¬me avec le flag de direction, vous pouvez utiliser les instructions suivantes qui ne changent pas les registres concern├®s et qui tiennent en deux opcodes chacune┬Ā:
CMP EAX, EAX ; met ├Ā 1 le flag de z├®ro (EAX est inchang├®)
CMP EAX, EDX ; met ├Ā 0 le flag de z├®ro si EAX et EDX ont un contenu diff├®rent
OR EAX, EAX ; met ├Ā 0 le flag de z├®ro si EAX est diff├®rent de z├®ro
TEST EAX, EAX ; m├¬me effet que OR EAX, EAXVIII-K-2-b. Test de z├®ro▲
Voici diff├®rentes mani├©res de tester une valeur nulle┬Ā:
JECXZ >L1 ; 2 opcodes
OR ECX, ECX ; 2 opcodes
JZ >L1 ; et 2 opcodes de plus
;
TEST ECX, ECX ; 2 opcodes
CMP ECX, 0 ; 3 opcodesVIII-K-2-c. Initier une valeur dans un registre ou en m├®moire▲
Voici diff├®rentes mani├©res de mettre un registre ├Ā une valeur donn├®e┬Ā:
XOR EAX, EAX ; r├®alise EAX = 0 avec 2 opcodes
SUB EAX, EAX ; r├®alise EAX = 0 avec 2 opcodes
AND EAX, 0 ; r├®alise EAX = 0 avec 3 opcodes
MOV EAX, 0 ; r├®alise EAX = 0 avec 5 opcodes
;
XOR EAX, EAX
INC EAX ; r├®alise EAX = 1 avec un total de 3 opcodes
MOV EAX, 1 ; r├®alise EAX = 1 avec 5 opcodes
;
OR EAX, -1 ; r├®alise EAX = -1 avec 3 opcodes
XOR EAX, EAX
DEC EAX ; r├®alise EAX = -1 avec un total de 3 opcodes
MOV EAX, -1 ; r├®alise EAX = -1 avec 5 opcodes
;
XOR EAX, EAX
MOV AL, 66h ; r├®alise EAX = 66h avec 4 opcodes
MOV EAX, 66h ; r├®alise EAX = 66h avec 5 opcodesEt lorsqu'on utilise de la m├®moire┬Ā:
XOR EAX, EAX ; EAX = 0 avec 2 opcodes
MOV [ESI], EAX ; met ├Ā 0 la m├®moire situ├®e ├Ā ESI avec 4 opcodes
MOV D[ESI], 0 ; met directement ├Ā 0 la m├®moire situ├®e ├Ā ESI avec 6 opcodes
;
XOR EAX, EAX ; EAX = 0 avec 2 opcodes
MOV [HELLO], EAX ; met HELLO ├Ā z├®ro en utilisant 7 opcodes
MOV D[HELLO], 0 ; met HELLO ├Ā z├®ro en utilisant 10 opcodesVIII-K-2-d. Utilisation de INC et DEC en lieu et place de ADD et SUB▲
INC ESI, ESI ; incr├®mente ESI deux fois avec 2 opcodes
ADD ESI, 2 ; incremente ESI deux fois avec 3 opcodes
;
DEC ESI, ESI ; d├®cr├®mente ESI deux fois avec 2 opcodes
SUB ESI, 2 ; d├®cr├®mente ESI deux fois avec 3 opcodesCela ├®tant, Intel recommande aujourd'hui d'├®viter d├®sormais l'utilisation des instructions INC registre et DEC registre et de leur pr├®f├®rer respectivement SUB registre, 1 et ADD registre, 1 afin d'uniformiser le traitement des flags.
En effet, les instructions INC et DEC ne modifient seulement qu'une partie des bits dans le registre des flags comparativement aux instructions ADD et SUB dont elles ne sont pourtant qu'un cas particulier. Selon Intel,(10) il peut m├¬me s'av├®rer particuli├©rement probl├®matique dans certains cas d'en poursuivre l'usage.
VIII-K-2-e. Utilisation des registres 16 bits▲
Dans la plupart des cas, l'utilisation d'un registre de 16 bits au lieu d'un registre ├Ā 8 ou 32 bits va ajouter un opcode suppl├®mentaire ├Ā votre code. En effet, l'assembleur doit g├®n├®rer l'octet de modification de taille (66h) avant l'instruction.
VIII-K-2-f. Multiplications utilisant LEA▲
Voici quelques exemples de multiplication rapide utilisant l'instruction LEA┬Ā:
LEA EAX, [EAX+EAX*2] ; multiplie EAX par 3 avec 3 opcodes et 1 cycle d'horloge
LEA EAX, [EAX+EAX*4] ; multiplie EAX par 5 avec 3 opcodes et 1 cycle d'horloge
LEA EAX, [EAX+EAX*8] ; multiplie EAX par 9 avec 3 opcodes et 1 cycle d'horloge
;
LEA EAX, [EAX+EAX*4] ; multiplie EAX par 5
LEA EAX, [EAX*2] ; le r├®sultat final est la multiplication par 10 (total 6 opcodes)
;
LEA EAX, [EAX+EAX*4] ; multiplie EAX par 5
SHL EAX, 1 ; le r├®sultat final est la multiplication par 10 (total 5 opcodes)
;
LEA EDX, [EAX*2] ; EDX = 2 * EAX
LEA EAX, [EAX+EAX*8] ; multiplie EAX par 9
LEA EAX, [EAX*8] ; maintenant, le r├®sultat dans EAX est EAX * 72
SUB EAX, EDX ; maintenant, le r├®sultat dans EAX est EAX * 70VIII-K-2-g. Utilisation d'un registre plus d'une fois▲
Pour copier dans un registre le contenu d'une adresse m├®moire, il est parfaitement admis de lui charger les donn├®es point├®es par lui-m├¬me, par exemple┬Ā:
MOV EAX, [EAX]VIII-K-2-h. Neutraliser une ligne en la transformant en commentaire▲
Lors du d├®veloppement de votre code, il peut ├¬tre n├®cessaire de neutraliser provisoirement une ligne d'instruction sans la supprimer de sorte qu'elle puisse ├¬tre restaur├®e facilement ult├®rieurement en cas de besoin. Pour cela, il suffit de placer un simple point-virgule en d├®but de ligne, de mani├©re ├Ā la transformer en commentaire┬Ā:
MOV EBX, ADDR WORTHYNESS
;MOV EDX, [EBX+14h] ; ligne neutralis├®e par sa mise en commentaire
MOV EDX, [EBX+10h] ; ligne rempla├¦ant la ligne ci-dessus mise en commentaire
; pour effectuer des tests transitoiresVIII-K-2-i. Tests pr├®c├®dant l'utilisation d'instructions MMX, SSE ou SSE2▲
Avant d'utiliser des mn├®moniques MMX, SSE ou SSE2, toujours v├®rifier que le processeur les accepte en mettant en ┼ōuvre l'instruction CPUID. Si tel n'est pas le cas, utiliser un code de remplacement utilisant des registres ordinaires.
VIII-K-2-j. Assemblage et ├®dition de liens avec les symboles de d├®bogage▲
Pour faciliter le d├®bogage au cours du d├®veloppement mettre le commutateur sur la ligne de commande du linker destin├® ├Ā produire une sortie de d├®bogage. Consulter le manuel de votre ├®diteur de liens pour voir comment proc├®der. Vous pouvez utiliser mon linker GoLink pour ce faire et, ensuite, mon d├®bogueur GoBug. GoAsm passe automatiquement tous les symboles ├Ā l'├®diteur de liens pour l'inclusion dans la sortie de d├®bogage. Puis, lorsque votre programme est termin├®, vous pouvez produire une version finale de l'ex├®cutable sans sortie de d├®bogage.
VIII-K-2-k. Recherche d'erreurs dans votre programme▲
Consulter le manuel relatif ├Ā mon utilitaire GoBug dans le volume 2 de cette ├®dition.
VIII-L. Normalisation des proc├®dures Callback Win32▲
Cette annexe d├®crit ma m├®thode favorite de codage des proc├®dures CALLBACK dans un grand programme en assembleur pour Windows 32. J'y d├®cris tout d'abord ce que sont les proc├®dures callback Win32, puis y expose quelques exemples de code.
Au moment de l'ex├®cution, le syst├©me Win32 appelle votre programme selon un sch├®ma immuable et cadr├®. Les proc├®dures que vous fournissez au syst├©me ├Ā appeler sont nomm├®es proc├®dures CALLBACK.
Voici des exemples o├╣ elles sont utilis├®es.
- Pour g├®rer une fen├¬tre que vous avez cr├®├®e. Dans ce cas, le syst├©me va envoyer de nombreux messages ├Ā la proc├®dure de fen├¬tre pour la gestion de celle-ci. La proc├®dure de fen├¬tre est le label de code que vous fournissez lorsque vous vous d├®clarez votre classe de fen├¬tre (en appelant l'API RegisterClass). Par exemple, le message WM_SIZE est envoy├® par le syst├©me lorsque la fen├¬tre est redimensionn├®e.
- Pour informer le propri├®taire d'une fen├¬tre-fille d'├®v├®nements survenus dans cette fen├¬tre. Par exemple, WM_PARENTNOTIFY (avec un code de notification) est envoy├® ├Ā la proc├®dure de fen├¬tre du propri├®taire d'une fen├¬tre lorsque la fen├¬tre-fille est en cours de cr├®ation ou de destruction, ou si l'utilisateur clique sur un bouton de la souris alors que le curseur est en dehors de la fen├¬tre-fille.
- Pour informer le propri├®taire d'un contr├┤le commun d'├®v├®nements survenant dans le contr├┤le. Par exemple, si vous cr├®ez un bouton dans votre fen├¬tre, la proc├®dure de fen├¬tre correspondant ├Ā cette fen├¬tre re├¦oit le message BN_CLICKED si ledit bouton est cliqu├®.
- Les messages envoy├®s ├Ā un dialogue que vous avez cr├®├®. Ce sont des messages relatifs ├Ā la cr├®ation du dialogue ainsi que des diff├®rents contr├┤les associ├®s. La proc├®dure de dialogue est inform├®e des ├®v├®nements survenant dans les contr├┤les.
- Si vous ┬½┬Āsur-classez┬Ā┬╗ ou ┬½┬Āsous-classez┬Ā┬╗ un contr├┤le commun, vous recevez des messages pour que ce contr├┤le commun se comporte comme une proc├®dure de hame├¦onnage, tout en retenant que votre proc├®dure de fen├¬tre conserve la responsabilit├® de les transmettre au contr├┤le.
- Si vous cr├®ez des proc├®dures ┬½┬ĀHook┬Ā┬╗ (hame├¦onnage), vous pouvez intercepter les messages sur le point d'├¬tre envoy├®s ├Ā d'autres fen├¬tres. Le syst├©me appellera votre proc├®dure d'hame├¦onnage et ne passera le message qu'au retour de celle-ci.
- Vous pouvez demander au syst├©me de fournir ├Ā votre programme les informations ├Ā envoyer ├Ā une proc├®dure CALLBACK. Les exemples sont EnumWindows (├®num├®rer toutes les fen├¬tres de niveau sup├®rieur) ou EnumFonts (├®num├®rer toutes les polices de caract├©res disponibles).
Dans les cas 1 ├Ā 5 ci-dessus, juste avant que le syst├©me n'appelle la proc├®dure CALLBACK, le syst├©me pousse (PUSH) quatre DWords sur la pile (c'est-├Ā-dire quatre ┬½┬Āparam├©tres┬Ā┬╗). Traditionnellement, les noms donn├®s ├Ā ces param├©tres sont┬Ā:
- hWnd = handle de la fen├¬tre en cours d'appel┬Ā;
- uMsg = num├®ro de message┬Ā;
- wParam = param├©tre envoy├® avec le message┬Ā;
- lParam = autre param├©tre envoy├® avec le message.
Le nombre de param├©tres envoy├®s aux proc├®dures d'hame├¦onnage et aux proc├®dures callback varie - voir le SDK Windows.
Dans la mesure o├╣ votre proc├®dure de fen├¬tre (ou de dialogue) devra r├®agir d'une certaine mani├©re en fonction du message envoy├®, votre code devra d├®tourner l'ex├®cution vers l'endroit appropri├® selon le message.
Les programmeurs en C ont l'avantage de pouvoir coder cela simplement, en utilisant ┬½┬Āswitch┬Ā┬╗ et ┬½┬Ācase┬Ā┬╗.
Les programmeurs en assembleur utilisent diverses techniques. Peut-├¬tre la pire de toutes, lorsqu'il y a beaucoup de messages ├Ā traiter, consiste-t-elle ├Ā ├®laborer la cha├«ne de comparaisons d├®crite ci-dessous (en format GoAsm)┬Ā:
MOV EAX, [EBP+0Ch] ; mettre en EAX le num├®ro du message
CMP EAX, 1h ; voir si c'est WM_CREATE
JNZ >L2 ; non
XOR EAX, EAX ; garantit que EAX prend la valeur z├®ro en sortie
JMP >L32 ; c'est fini
L2:
CMP EAX, 116h ; voir si c'est WM_INITMENU
JNZ >L4 ; non
CALL INITIALISE_MENU
JMP >L30 ; code de sortie correct
L4:
CMP EAX, 47h ; voir si c'est WM_WINDOWPOSCHANGED
JNZ >L8ŌĆ” et ainsi de suite.
Pour ├®viter ces longues cha├«nes de comparaison, les programmeurs en assembleur ont d├®velopp├® diverses techniques. Vous pouvez en voir de nombreux exemples sur diff├®rents sites de code assembleur utilisant des sauts conditionnels, des macros ou une indexation par table. Je ne veux pas comparer ces diff├®rentes m├®thodes, mais simplement mettre en avant ma pr├®f├®rence actuelle, qui je crois, poss├©de les avantages suivants┬Ā:
- elle fonctionne sur tous les assembleurs┬Ā;
- elle est modulaire, ├Ā savoir que le code pour chaque fen├¬tre peut ├¬tre concentr├® dans une partie particuli├©re de votre code source┬Ā;
- il est facile de suivre ├Ā partir du code source quel message provoque quel r├®sultat┬Ā;
- la m├¬me fonction peut facilement ├¬tre appel├®e ├Ā partir de proc├®dures de fen├¬tre diff├®rentes.
Ma m├®thode est illustr├®e par la proc├®dure de fen├¬tre tr├©s simple qui suit (en format GoAsm)┬Ā:
WndProc:
MOV EDX, OFFSET MAINMESSAGES
CALL GENERAL_WNDPROC
RET 10ho├╣ les messages et les fonctions (sp├®cifiques ├Ā cette proc├®dure de fen├¬tre particuli├©re) sont d├®finis dans un tableau comme celui-ci┬Ā:
; ----------------------------------------------------------
DATA SECTION ; assembleur pour mettre ce qui suit dans la section DATA
; ----------------------------- WNDPROC messages de fonctions
MAINMESSAGES DD (ENDOF_MAINMESSAGES-$-4)/8 ; = nombres de messages
DD 312h, HOTKEY, 116h, INITMENU, 117h, INITMENUPOPUP, 11Fh, MENUSELECT
DD 1h, CREATE, 2h, DESTROY, 410h, OWN410, 411h, OWN411
DD 231h, ENTERSIZEMOVE, 47h, WINDOWPOSCHANGED, 24h, GETMINMAXINFO
DD 1Ah, SETTINGCHANGE, 214h, SIZING, 46h, WINDOWPOSCHANGING
DD 2Bh, DRAWITEM, 0Fh, PAINT, 113h, TIMER, 111h, COMMAND
DD 104h, SYSKEYDOWN, 100h, KEYDOWN, 112h, SYSCOMMAND
DD 201h, LBUTTONDOWN, 202h, LBUTTONUP, 115h, SCROLLMESS
DD 204h, RBUTTONDOWNUP, 205h, RBUTTONDOWNUP
DD 200h, MOUSEMOVE, 0A0h, NCMOUSEMOVE, 20h, SETCURSORM
DD 4Eh, NOTIFY, 210h, PARENTNOTIFY, 86h, NCACTIVATE, 6h, ACTIVATE
DD 1Ch, ACTIVATEAPP
ENDOF_MAINMESSAGES: ; label utilis├® pour d├®terminer le nombre de messages
; ----------------------------------------------------------
CODE SECTION ; assembleur pour mettre ce qui suit dans la section CODE
; ----------------------------------------------------------et o├╣ chacune des fonctions ici est une proc├®dure, par exemple┬Ā:
CREATE:
XOR EAX, EAX ; garantit le retour avec EAX=0 et Cf=0
RETet o├╣ GENERAL_WINDPROC s'├®crit comme suit┬Ā:
GENERAL_WNDPROC:
PUSH EBP
MOV EBP, [ESP+10h] ; r├®cup├©re uMsg dans EBP
MOV ECX, [EDX] ; r├®cup├©re le nombre de messages ├Ā traiter
ADD EDX, 4 ; sauter apr├©s le dword donnant la taille
L33:
DEC ECX
JS >L46 ; flag de signe = 1 => message non trouv├®
CMP [EDX+ECX*8], EBP ; voir si c'est le message correct
JNZ L33 ; non
MOV EBP, ESP
PUSH ESP, EBX, EDI, ESI ; sauvegarde les registres comme requis par Windows
ADD EBP, 4 ; on saute le Dword contenant le nombre de messages
; maintenant, [EBP+8]=hWnd, [EBP+0Ch]=uMsg, [EBP+10h]=wParam, [EBP+14h]=lParam
CALL [EDX+ECX*8+4] ; appel de la proc├®dure correspondant au message
POP ESI, EDI, EBX, ESP
JNC >L48 ; NC = ne pas appeler DefWindowProc EAX = code de sortie
L46:
PUSH [ESP+18h], [ESP+18h], [ESP+18h], [ESP+18h] ; ESP change au fur et ├Ā mesure des PUSHs
CALL DefWindowProcA
L48:
POP EBP
RETVIII-L-1. Notes▲
- Au lieu de donner la valeur courante du message, vous pouvez, bien s├╗r, donner le nom d'une EQUATE.
Par exemple (dans la syntaxe Asm)┬Ā:
WM_CREATE EQU 1hou si vous pr├®f├®rez┬Ā:
WM_CREATE = 1hou, enfin┬Ā:
#define WM_CREATE 1hvous permet d'├®crire WM_CREATE, CREATE au lieu de 1h, CREATE dans les d├®clarations de MAINMESSAGES si vous le jugez plus appropri├®.
- Il est tentant de positionner la table de messages dans la section de code. Ceci est parfaitement possible parce que la seule diff├®rence que fait le syst├©me Win32 entre la section de code et la section de donn├®es tient au fait que la zone m├®moire correspondant ├Ā la section de code est utilisable en lecture seule, alors que la section de donn├®es l'est en lecture/├®criture. Cependant, il peut en r├®sulter une perte de performance parce que le processeur est con├¦u pour lire les donn├®es plus rapidement ├Ā partir de la section de donn├®es.
J'ai effectu├® quelques tests ├Ā ce propos et mis en ├®vidence que la pr├®sence de la table dans la section de code plut├┤t que dans la section de donn├®es ralentit consid├®rablement l'ex├®cution ainsi qu'en t├®moignent les r├®sultats suivants┬Ā:
- processeur 486┬Ā: 22% ├Ā 36% plus lent┬Ā;
- processeur AMD-K6-3D┬Ā: 78% ├Ā 193% plus lent.
Ces essais ont ├®t├® r├®alis├®s sur une table de 60 messages et les valeurs trouv├®es ont trait ├Ā la rapidit├® d'exploration de la table pour trouver le message.
- Les noms de proc├®dure ne doivent pas ├¬tre des noms d'import d'API pour ├®viter toute confusion┬Ā! Par exemple modifier l├®g├©rement SetCursor pour ├®viter toute confusion avec l'API SetCursor.
- Si une fonction restitue le flag de carry Cf ├Ā 1, la proc├®dure de fen├¬tre appellera DefWindowProc. Un retour avec flag de carry Cf ├Ā z├®ro traduira simplement un retour au syst├©me avec le code de retour dans EAX. Certains messages doivent ├¬tre trait├®s de cette mani├©re.
- Vous pouvez envoyer un param├©tre de votre initiative ├Ā GENERAL_WNDPROC en utilisant EAX. Ceci est utile si vous souhaitez identifier une fen├¬tre particuli├©re.
Par exemple┬Ā:
SpecialWndProc:
MOV EAX, OFFSET hSpecialWnd
MOV EDX, OFFSET SPECIALWND_MESSAGES
CALL GENERAL_WNDPROC
RET 10h- L'instruction ADD EBP,4 juste avant le CALL ├Ā la fonction (CALL [EDX+ECX*8+4]) a pour objet de garantir que EBP pointe les param├©tres sur la pile de la m├¬me mani├©re que si la proc├®dure de fen├¬tre avait ├®t├® saisie normalement. Ceci est destin├® ├Ā garantir que la fonction sera compatible si elle est appel├®e par une proc├®dure de fen├¬tre ordinaire ├®crite en assembleur, par exemple┬Ā:
WndProc:
PUSH EBP
MOV EBP, ESP ; maintenant [EBP+8]=hWnd, [EBP+0Ch]=uMsg, [EBP+10h]=wParam, [EBP+14h]=lParam- Une proc├®dure normalis├®e pour traiter les messages d'une proc├®dure de dialogue peut ├®galement ├¬tre cr├®├®e de la m├¬me mani├©re, sauf qu'elle doit retourner TRUE (EAX = 1) si le message est trait├® et FALSE (EAX = 0) s'il ne l'est pas, et ne pas appeler DefWindowProc. La m├¬me m├®thode de codage peut ├¬tre appliqu├®e ├Ā des hame├¦onnages et de recenseurs CALLBACKS bien ceux-ci puissent varier.
Adapt├® de l'article publi├®, pour la premi├©re fois, sur Asm Journal N┬░┬Ā5.
VIII-M. Fichiers Batch▲
Les fichiers batch sont un h├®ritage du DOS. Bien que th├®oriquement ├®trangers au monde Windows, ils permettent de lancer des s├®quences de commandes programm├®es en mode console. ├Ć ce titre, ils sont tr├©s utiles pour simplifier les op├®rations d'assemblage puis d'├®dition de liens, celles-ci pouvant comporter de nombreux param├©tres dont la saisie r├®p├®t├®e lors du processus de mise au point peut se r├®v├®ler fastidieuse.
Comme les fichiers asm, les fichiers bat ne doivent contenir aucun caract├©re de contr├┤le et peuvent donc s'├®crire avec un simple ├®diteur de texte du style Bloc-Notes de Windows.
Les fichiers batch mettent en ┼ōuvre une batterie d'instructions dont nous n'allons d├®tailler ici que les plus essentielles pour mener ├Ā bien les t├óches dont il est question ici.
VIII-M-1. Un premier aper├¦u de fichier batch▲
Mais auparavant, voici un fichier batch nomm├® aslink.bat destin├® ├Ā automatiser le processus d'assemblage/├®dition de liens┬Ā:
2.
3.
4.
rem *** Assemblage + ├ēdition de liens ***
goasm %1.asm %1.obj
golink %1.obj %1.exe user32.dll gdi32.exe
pause
On le lance par la commande suivante en mode console┬Ā:
C:\GOASM\aslink testCette commande prescrit ├Ā aslink.bat la t├óche d'assembler le fichier test.asm puis d'en assurer l'├®dition de liens en une seule op├®ration. Notons que l'extension .asm n'est pas mentionn├®e au lancement de aslink car reconstitu├®e automatiquement dans son processus.
Examinons maintenant le fichier batch ligne par ligne┬Ā:
Ligne 1┬Ā: REM *** Assemblage + ├ēdition de liens ***
Elle commence par l'instruction REM, qui indique que tous les caract├©res qui suivent, jusqu'├Ā la fin de ligne sont seulement des commentaires ├Ā destination du lecteur du listing et n'ont, de ce fait, aucune fonction dans le processus.
Ligne 2┬Ā: goasm %1.asm %1.obj
Cette ligne voit l'assembleur GoAsm entrer en action. Le terme %1 recueille, par construction, le premier param├©tre de la ligne de commande de aslink, soit le mot test dans notre cas. De ce fait, la ligne 2 ├®quivaut ├Ā la formulation goasm test.asm test.obj.
Ligne 3┬Ā: golink %1.obj %1.exe user32.dll gdi32.exe
Selon les principes ├®nonc├®s ├Ā la ligne pr├®c├®dente, cette formulation revient ├Ā ├®crire golink test.obj test.exe user32.dll gdi32.dll. En clair, GoLink proc├©de ├Ā l'├®dition des liens de test.obj pour produire l'ex├®cutable final test.exe. Pour ce faire, il entre en relation avec les DLL user32.dll et gdi32.dll afin d'y rechercher les adresses d'ex├®cution n├®cessaires ├Ā certaines API du programme.
Ligne 4┬Ā: pause
Cette instruction a pour effet de suspendre l'ex├®cution ligne par ligne du fichier batch et d'attendre la pression d'une touche quelconque pour continuer. Cette suspension prend toute son importance dans l'environnement Windows o├╣ le simple fait de double-cliquer sur le fichier aslink.bat ├Ā partir de l'Explorateur de fichier d├®clenche l'ouverture fugitive d'une fen├¬tre DOS, la tr├©s br├©ve ex├®cution de aslink.bat et un retour quasi imm├®diat ├Ā l'Explorateur. Autant dire que nous ne voyons rien de ce qui se passe pendant l'ex├®cution du fichier batch et notamment d'├®ventuelles erreurs intervenues ├Ā l'une ou l'autre des ├®tapes de ce processus. C'est ici qu'intervient l'instruction pause qui maintient l'affichage de la fen├¬tre DOS et de toutes les informations qu'elle contient tant que l'utilisateur n'a pas d├®cid├® de la poursuite des op├®rations.
En ce sens qu'il se propose d'appliquer un traitement indiff├®renci├® aux scripts source asm, un tel processus batch reste assez th├®orique, car il propose un cadre de traitement rigide, s'agissant notamment de la liste des DLL ├Ā solliciter lors de la phase d'├®dition de liens qui d├®pend ├®troitement des API sollicit├®es par le programme.
VIII-M-2. Instructions et configurations utilisables dans les fichiers batch▲
Les instructions de commande sont destin├®es au processeur cmd.exe g├®n├®ralement localis├® dans le r├®pertoire C:\Windows\System32\.
VIII-M-2-a. Espaces dans les noms de fichiers, r├®pertoires et sous-r├®pertoires▲
Si l'usage de l'espace ├®tait nagu├©re proscrit dans les noms de fichiers, r├®pertoires et sous-r├®pertoires, cette restriction est d├®sormais lev├®e sous Windows et sans inconv├®nient aucun. Les commandes du DOS accessibles par Windows ont suivi cette ├®volution et acceptent ├®galement l'espace avec, toutefois, une possibilit├® de d├®connexion de cette fonction.
L'autorisation de l'espace rel├©ve du mode ├®tendu de cmd.exe g├®n├®ralement install├®e par d├®faut. On peut toutefois d├®connecter cette facilit├® et retrouver ainsi les pratiques du bon vieux DOS mais il nous faut agir, pour cela au niveau de la base de registres. Il convient de se r├®f├®rer au site Microsoft si cette voie est choisie. Sachez, en tout cas, qu'elle est r├®serv├®e aux programmeurs exp├®riment├®s.
VIII-M-2-b. Les principales instructions▲
|
Cd (Chdir) |
Change le r├®pertoire courant ou affiche le nom du r├®pertoire courant si la commande est lanc├®e sans aucun param├©tre. Syntaxe cd rep1\nouveau rep┬Ā: le r├®pertoire courant devient nouveau rep si rep1 puis nouveau rep sont des r├®pertoires en aval du r├®pertoire courant avant l'application de cd. cd..┬Ā: le r├®pertoire courant devient le r├®pertoire amont avant l'application de cd. cd\┬Ā: le r├®pertoire courant devient le r├®pertoire racine. cd┬Ā: affiche le r├®pertoire courant incluant tous les r├®pertoires amont ainsi que le nom de lecteur. |
| Cls | Efface l'├®cran et remet le curseur en haut de l'├®cran |
| Del |
Efface le ou les fichiers sp├®cifi├®s. Le nom des fichiers peut ├¬tre sp├®cifi├® en utilisant des caract├©res g├®n├®riques. Cette commande doit ├¬tre utilis├®e avec prudence, car son ex├®cution n'est pr├®c├®d├®e d'aucun avertissement comme dans Windows. De m├¬me, le m├®canisme de sauvegarde en Corbeille est inactif, car n'agissant que dans le cadre de Windows. Syntaxe del machin.txt┬Ā: efface le fichier machin.txt dans le r├®pertoire courant. del machin.txt bidule.ttg┬Ā: efface les fichiers machin.txt et bidule.ttg dans le r├®pertoire courant. del m*.txt┬Ā: efface tous les fichiers avec l'extension txt dont le nom commence par la lettre m dans le r├®pertoire courant. del *.txt┬Ā: efface tous les fichiers avec l'extension txt dans le r├®pertoire courant. del *.*┬Ā: efface tous les fichiers du r├®pertoire courant. Lorsqu'elle est valid├®e, cette commande envoie opportun├®ment le message de demande de confirmation ┬½┬Ā├Ŗtes-vous s├╗r (O/N)┬Ā?┬Ā┬╗. Mais c'est le seul casŌĆ” |
| Dir | Affiche le nom des fichiers et sous-r├®pertoires contenus dans le r├®pertoire courant. L'option /p accol├®e ├Ā cette commande permet de suspendre le d├®filement si l'affichage n├®cessite plus d'une page, l'utilisateur ├®tant invit├® ├Ā actionner une touche quelconque pour acc├®der ├Ā la page suivante. |
| Echo |
echo permet d'activer (echo on) ou de d├®sactiver (echo off) l'affichage des diff├®rentes lignes d'un fichier batch. Cet affichage est actif par d├®faut. La commande, en elle-m├¬me, peut ne pas ├¬tre affich├®e en stipulant @echo. Si l'on pr├®f├©re un affichage personnalis├® par ligne, il suffit de mettre le symbole @ devant toute commande. Enfin, on peut obtenir un saut de ligne dans l'affichage en mettant un point ├Ā la fin d'echo. Exemples echo off┬Ā: neutralise l'affichage de toutes les lignes du fichier batch ├Ā partir de cette commande mais affiche n├®anmoins cette derni├©re. @echo off┬Ā: neutralise l'affichage de toutes les lignes du fichier batch ├Ā partir de cette commande mais n'affiche pas cette derni├©re. echo tout est parfait┬Ā: affiche le texte tout est parfait. echo.┬Ā: provoque un saut de ligne du prompt. |
| Dir | Affiche le nom des fichiers et sous-r├®pertoires contenus dans le r├®pertoire courant. L'option /p accol├®e ├Ā cette commande permet de suspendre le d├®filement si l'affichage n├®cessite plus d'une page, l'utilisateur ├®tant invit├® ├Ā actionner une touche quelconque pour acc├®der ├Ā la page suivante. |
| Pause | Suspend l'ex├®cution du fichier batch avec affichage d'un message invitant l'utilisateur ├Ā actionner une touche quelconque pour poursuivre l'ex├®cution du batch. Cette instruction est particuli├©rement utile lorsqu'on lance des commandes DOS en mode console Windows, car, la plupart du temps, l'ex├®cution du fichier batch est trop fugitive pour avoir le temps de prendre connaissance des messages affich├®s (notifications d'erreurs ou compte-rendu d'ex├®cution). |
|
Ren (Rename) |
Renomme le fichier mentionn├® avec le nom sp├®cifi├® imm├®diatement apr├©s. Exemple Ren file.txt file2.txt┬Ā: renomme le fichier file.txt en file2.txt. |
Nous nous en tiendrons l├Ā dans cette ├®num├®ration des commandes DOS susceptibles d'├¬tre utilis├®es dans les fichiers batch. Les commandes cit├®es sont de loin les plus courantes et il est toujours possible de recourir, en cas de besoin, ├Ā une documentation exhaustive sur internet.
VIII-M-2-c. Le fichier Config.fil▲
Le fichier Config.fil est utilisable avec GoLink dont il d├®crit les param├©tres de la ligne de commande. On en trouvera une description d├®taill├®e dans l'annexe C - Organisation de votre travail de programmation.
IX. Index Alphab├®tique▲
Copyright ┬® Jeremy Gordon 2001-2016
X. Notes relatives au document▲
Le pr├®sent ouvrage est une traduction fran├¦aise aussi fid├©le que possible de documents originaux propos├®s sur le site http://www.godevtool.com/. Le tableau ci-dessus en donne les liens sous une forme directement activable. Dans quelques cas, assez rares, des ajouts ou des modifications ont ├®t├® op├®r├®s. La liste exhaustive est propos├®e apr├©s le tableau.
X-A. Sources▲
| Sections I (Introduction) ├Ā VI et IX (index) | View the GoAsm manual |
| Section VII | Writing 64-bit programs |
| Annexes | |
| Annexe A - Exemples de programmes | |
| Programme HelloWorld1.asm | Simple Windows console program |
| Programme HelloWorld2.asm | Simple Windows GUI program |
| Programme HelloWorld3.asm | Simple Windows GUI program |
| Programme HelloDialog.asm | Simple Dialog program |
| Programme Hello64World1.asm | Hello 64World 1 |
| Programme Hello64World2.asm | Hello 64World 2 |
| Programme Hello64World3.asm | Hello 64World 3 |
| Annexe B - ├ēcriture d'un programme Windows ├®l├®mentaire | Quick start toŌĆ” writing a simple Windows program |
| Annexe C - Pour les d├®butantsŌĆ” en programmation | For those new toŌĆ” programming |
| Annexe D - Repr├®sentations binaires | UnderstandŌĆ” bits, binary and bytes |
| UnderstandŌĆ” hex numbers | |
| UnderstandŌĆ” finite, negative, signed and two's complement numbers | |
| Annexe E - Pour les d├®butantsŌĆ” en langage assembleur | For those new toŌĆ” assembly language |
| Annexe F - Flags, sauts conditionnels, CMOVcc et SETcc | UnderstandŌĆ” flags and conditional jumps |
| Annexe G - Pour les d├®butantsŌĆ” en Windows | For those new toŌĆ” Windows |
| Annexe H - Pour les d├®butantsŌĆ” en d├®bogage symbolique | For those new toŌĆ” symbolic debugging |
| Annexe I - ComprendreŌĆ” la Pile -Partie 1 | UnderstandŌĆ” the stack - Part 1 |
| Partie 2 | UnderstandŌĆ” the stack - Part 2 |
| Annexe J - ComprendreŌĆ” la m├®morisation invers├®e | UnderstandŌĆ” reverse storage |
| Annexe K - Quelques conseils et astuces de programmation | Some programmingŌĆ” hints and tips |
| Annexe L - Normalisation des proc├®dures Callback Win32 | Standardized window and dialog procedure |
| Annexe M - Fichiers Batch | ajout├® |
X-B. Ajouts et modifications▲
X-B-1. Introduction, sections II ├Ā VI▲
Paragraphe IV.O.5┬Ā: ajout d'un diagramme repr├®sentant l'organisation des bits dans un TWord (source Intel).
X-B-2. Annexe A┬Ā: Exemples de programmes▲
Les sept fichiers .asm d├®crits dans cette annexe b├®n├®ficient syst├®matiquement de commentaires traduits en fran├¦ais. Ils sont assortis, dans chaque cas, d'une copie d'├®cran de la fen├¬tre la plus explicite et d'un petit expos├® introductif.
X-B-3. Annexe B┬Ā: ├ēcriture d'un programme Windows ├®l├®mentaire▲
La portion de l'introduction d├®crivant les diff├®rentes sections d'un programme a ├®t├® ├®toff├®e.
X-B-4. Annexe D┬Ā: Repr├®sentations binaires▲
Le tableau ci-dessus mentionne que cette annexe regroupe trois tutoriels du site Godevtool. Y figurent ├®galement de notables ajouts. Parmi ces derniers, une introduction sur les syst├©mes de num├®ration en g├®n├®ral et le syst├©me binaire en particulier, un expos├® succinct sur la repr├®sentation des nombres entiers et en virgule flottante.
X-B-5. Annexe F┬Ā: Flags, sauts conditionnels, CMOVcc et SETcc▲
Flag Of┬Ā: pour faciliter la compr├®hension du m├®canisme de fonctionnement de l'instruction SAR, un diagramme issu de documentation Intel a ├®t├® ajout├® et traduit.
Sauts conditionnels┬Ā: ajout d'un paragraphe d├®crivant les conventions de traduction en fran├¦ais pour les comparaisons entre grandeurs sign├®es et non sign├®es.
Instructions CMOVcc et SETcc┬Ā: une description de ces deux instructions a ├®t├® ajout├®e car relevant maintenant du m├®canisme de sauts conditionnels. Elle a ├®t├® emprunt├®e, pour l'essentiel, ├Ā des documents Intel.
X-B-6. Annexe H┬Ā: Pour les d├®butantsŌĆ” en d├®bogage symbolique▲
Le listing du testeur a ├®t├® int├®gr├® au texte. Le sous-programme TEST_HEXWRITE a ├®t├® simplifi├® par la mise en ┼ōuvre d'une boucle.
X-B-7. Annexe K┬Ā: Quelques conseils et astuces de programmation▲
Conform├®ment ├Ā la documentation Intel, des restrictions ont ├®t├® ├®mises quant ├Ā l'utilisation des instructions INC et DEC en lieu et place de ADD et SUB, respectivement (┬¦ K.2.d).
X-B-8. Annexe M┬Ā: Fichiers Batch▲
Section r├®dig├®e par le traducteur.
X-C. Remerciements▲
Merci ├Ā Claude Leloup pour sa relecture.