




I. Introduction▲
L'assembleur est un langage dit bas niveau, c'est-├Ā-dire qu'il est tr├©s proche du langage machine.
Autrement dit, pour programmer en assembleur vous devez┬Ā:
- apprendre une architecture┬Ā: Intel par exemple┬Ā;
- avoir quelques connaissances basiques sur les syst├©mes d'exploitation┬Ā: Linux par exemple┬Ā;
- ma├«triser un assembleur┬Ā: l'assembleur GNU par exemple.
Apprendre une architecture, c'est comprendre le fonctionnement d'un processeur┬Ā: les registres, l'adressage et l'organisation de la m├®moire, les interruptionsŌĆ” et tout ce que vous avez appris dans le cours d'architecture des ordinateurs. Vous avez, sans doute, une id├®e claire et suffisante sur l'architecture Intel (IA ou x86) pour aborder ce tutoriel. D'autre part, apprendre un assembleur c'est apprendre une syntaxe pour programmer. C'est l'objectif de ce tutoriel┬Ā!
Le langage assembleur, ou simplement l'assembleur, est une repr├®sentation symbolique du langage machine (donn├®es binaires et instructions du processeur). Il existe deux syntaxes d'assembleurs┬Ā:
- l'assembleur Intel┬Ā: l'assembleur principal utilisant cette syntaxe est NASM┬Ā;
- l'assembleur AT&T┬Ā: l'assembleur principal est l'assembleur GNU ou simplement as.
Ce tutoriel va vous donner la description minimale pour coder en assembleur GNU sous un syst├©me GNU/Linux en utilisant le jeu d'instructions Intel 80386.
Les codes sources des exemples cit├®s dans ce tutoriel sont t├®l├®chargeables sur ![]() cette page.
cette page.
II. D├®finitions pr├®liminaires▲
II-A. Les syst├©mes de num├®ration▲
Pour ├¬tre trait├®e par un circuit num├®rique (un processeur, une m├®moire RAMŌĆ”), une information doit ├¬tre convertie en un format adaptable. Pour cela, elle doit ├¬tre repr├®sent├®e dans un syst├©me de num├®ration caract├®ris├® par une base b (b┬Ā>┬Ā1 est un entier). Les syst├©mes de num├®ration les plus utilis├®s sont┬Ā: le d├®cimal (b┬Ā=┬Ā10), le binaire (b┬Ā=┬Ā2), l'octal (b┬Ā=┬Ā8), l'hexad├®cimal (b┬Ā=┬Ā16).
Tableau 1┬Ā: Les syst├©mes de num├®ration
| D├®cimal | Binaire | Octal | Hexad├®cimal |
|---|---|---|---|
| 0 | 0000 | 0 | 0 |
| 1 | 0001 | 1 | 1 |
| 2 | 0010 | 2 | 2 |
| 3 | 0011 | 3 | 3 |
| 4 | 0100 | 4 | 4 |
| 5 | 0101 | 5 | 5 |
| 6 | 0110 | 6 | 6 |
| 7 | 0111 | 7 | 7 |
| 8 | 1000 | 10 | 8 |
| 9 | 1001 | 11 | 9 |
| 10 | 1010 | 12 | A |
| 11 | 1011 | 13 | B |
| 12 | 1100 | 14 | C |
| 13 | 1101 | 15 | D |
| 14 | 1110 | 16 | E |
| 15 | 1111 | 17 | F |
On ├®crit un nombre N┬Ā=┬Āan anŌłÆ1 ŌĆ” a1 a0 ŌĆ” , aŌłÆ1 aŌłÆ2 ŌĆ” aŌłÆm dans un syst├©me de num├®ration de base b selon l'expression suivante┬Ā:
N┬Ā=┬ĀŌłæŌłÆmŌēżiŌēżn (ai.bi) = an.bn+ anŌłÆ1.bnŌłÆ1 ŌĆ” a1.b1 + a0.b0 ŌĆ” , aŌłÆ1.bŌłÆ1 + aŌłÆ2.bŌłÆ2 ŌĆ” aŌłÆm.bŌłÆm
Avec i le poids (position) du chiffre (digit) ai dans le nombre N.
Exemples┬Ā:
- b = 10 et N = 2193┬Ā: 219310 = 2.103 + 1.102 + 9.101 + 3.100 = 2000 + 100 + 90 + 3
=┬Ā2193┬Ā; - b = 2 et N = 1011┬Ā: 10112 = 1.23 + 0.22 + 1.21 + 1.20 = 8 + 0 + 2 + 1
=┬Ā11┬Ā; - b = 16 et N = F3C9┬Ā: F3C916 = 15.163 +3.162 +12.161 +9.160 = 61440+768+192+9
=┬Ā62409┬Ā; - b = 2 et N = 10,11┬Ā: 10,112 = 1.21 + 0.20 + 1.2ŌłÆ1 + 1.2ŌłÆ2 = 2 + 0 + 0,5 + 0,25
=┬Ā2,75.
En fait, nous avons converti les quatre nombres N repr├®sent├®s dans les syst├©mes de num├®ration de bases b au format d├®cimal.
Il est clair que la base b d'un syst├©me de num├®ration est ├®gale au nombre de chiffres (digits) qui peuvent ├¬tre utilis├®s pour repr├®senter un nombre. Ainsi, le syst├©me binaire utilise deux digits {0, 1}, le syst├©me d├®cimal utilise dix digits {0, 1, 2, 3, 4, 5, 6, 7, 8, 9} et ainsi de suite.
D'autre part, pour adapter un syst├©me de num├®ration ├Ā un circuit num├®rique, il faut associer un niveau de tension (voltage) ├Ā chaque chiffre. Imaginez que nous d├®cidions d'utiliser le syst├©me d├®cimal pour construire un circuit num├®rique. Il faut donc utiliser dix niveaux de tension. Ce qui nous donne un circuit tr├©s compliqu├®. Par contre, le syst├©me binaire, ayant la plus faible base (b┬Ā=┬Ā2), est le plus adapt├®. Il n├®cessite seulement deux niveaux de tension, par exemple┬Ā: 0V pour le digit 0 et 5V pour le digit 1. Pour cette raison, les 0 et les 1 sont les deux seuls symboles du langage machine.
II-B. Le code ASCII▲
Le code ASCII (American Standard Code for Information Interchange) est un code alphanum├®rique utilis├® pour l'├®change des informations entre deux ou plusieurs ordinateurs ou entre un ordinateur et ses p├®riph├®riques.
Le processeur ne comprend pas la repr├®sentation humaine des caract├©res. Il utilise le codage ASCII (une s├®quence de 0 et 1), pour identifier les diff├®rents caract├©res alphanum├®riques. Par exemple, lorsque vous appuyez sur la touche ┬½┬ĀA┬Ā┬╗ de votre clavier, le processeur re├¦oit son code ASCII.
Le codage ASCII standard utilise 7 bits pour repr├®senter les caract├©res de l'alphabet (minuscule et majuscule), les chiffres d├®cimaux, les caract├©res de ponctuation et les caract├©res de contr├┤le┬Ā:
Tableau 2┬Ā: La table ASCII standard
| D├®cimal | Caract├©re | D├®cimal | Caract├©re | D├®cimal | Caract├©re |
|---|---|---|---|---|---|
| 0 | NUL | 43 | + | 86 | V |
| 1 | SOH | 44 | , | 87 | W |
| 2 | STX | 45 | - | 88 | X |
| 3 | ETX | 46 | . | 89 | Y |
| 4 | EOT | 47 | / | 90 | Z |
| 5 | ENQ | 48 | 0 | 91 | [ |
| 6 | ACK | 49 | 1 | 92 | \ |
| 7 | BEL | 50 | 2 | 93 | ] |
| 8 | BS | 51 | 3 | 94 | ^ |
| 9 | HT | 52 | 4 | 95 | _ |
| 10 | LF | 53 | 5 | 96 | ŌĆś |
| 11 | VT | 54 | 6 | 97 | a |
| 12 | ff | 55 | 7 | 98 | b |
| 13 | CR | 56 | 8 | 99 | c |
| 14 | SO | 57 | 9 | 100 | d |
| 15 | SI | 58 | : | 101 | e |
| 16 | DLE | 59 | ; | 102 | f |
| 17 | DC1 | 60 | < | 103 | g |
| 18 | DC2 | 61 | = | 104 | h |
| 19 | DC3 | 62 | > | 105 | i |
| 20 | DC4 | 63 | ? | 106 | j |
| 21 | NAK | 64 | @ | 107 | k |
| 22 | SYN | 65 | A | 108 | l |
| 23 | ETB | 66 | B | 109 | m |
| 24 | CAN | 67 | C | 110 | n |
| 25 | EM | 68 | D | 111 | o |
| 26 | SUB | 69 | E | 112 | p |
| 27 | ESC | 70 | F | 113 | q |
| 28 | FS | 71 | G | 114 | r |
| 29 | GS | 72 | H | 115 | s |
| 30 | RS | 73 | I | 116 | t |
| 31 | US | 74 | J | 117 | u |
| 32 | Space | 75 | K | 118 | v |
| 33 | ! | 76 | L | 119 | w |
| 34 | ŌĆØ | 77 | M | 120 | x |
| 35 | # | 78 | N | 121 | y |
| 36 | $ | 79 | O | 122 | z |
| 37 | % | 80 | P | 123 | { |
| 38 | & | 81 | Q | 124 | | |
| 39 | ' | 82 | R | 125 | } |
| 40 | ( | 83 | S | 126 | Ōł╝ |
| 41 | ) | 84 | T | 127 | DEL |
| 42 | * | 85 | U | ┬Ā | ┬Ā |
II-C. Le code BCD▲
Le code BCD, Binary Coded Decimal, est utilis├® pour coder des nombres d'une fa├¦on relativement proche de la repr├®sentation humaine usuelle (en base 10). En BCD, les nombres sont repr├®sent├®s en chiffres d├®cimaux et chacun de ces chiffres est cod├® sur quatre bits┬Ā:
| D├®cimal | BCD |
|---|---|
| 0 | 0000 |
| 1 | 0001 |
| 2 | 0010 |
| 3 | 0011 |
| 4 | 0100 |
| 5 | 0101 |
| 6 | 0110 |
| 7 | 0111 |
| 8 | 1000 |
| 9 | 1001 |
Il est remarquable que les bits 0-3 de chaque code ASCII d'un chiffre d├®cimal sont ├®gaux ├Ā son code BCD.
D'autre part, la plupart des ordinateurs stockent les donn├®es dans des octets (d'une taille de 8 bits). Deux m├®thodes communes permettent d'enregistrer les chiffres BCD de quatre bits dans un tel octet┬Ā:
- format non compact├®, Unpacked BCD┬Ā: ignorer les quatre bits suppl├®mentaires de chaque octet et leur ajouter quatre bits identiques (0 ou 1)┬Ā;
- format compact├®, Packed BCD┬Ā: enregistrer deux chiffres (4 bits) par octet.
Pour illustrer, supposons qu'on stocke successivement les chiffres d├®cimaux 9 et 1 au format BCD┬Ā:
- format non compact├®┬Ā: d├®cimal -> 1┬Ā9, binaire -> 0000┬Ā0001┬Ā0000┬Ā1001┬Ā;
- format compact├®┬Ā: d├®cimal -> 1┬Ā9, binaire -> 0001┬Ā1001.
III. L'assemblage et l'├®dition de liens sous Linux▲
Le code suivant est celui du programme classique permettant d'afficher, sur la console, le message ┬½┬ĀHello, World┬Ā!┬Ā┬╗┬Ā:
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
.data
msg : .asciz "Hello, World !\n"
len = . - msg
.bss
.text
.global _start
_start :
movl $msg,%ecx
movl $len,%edx
movl $1,%ebx
movl $4,%eax
int $0x80 # appel syst├©me
exit :
movl $0,%ebx
movl $1,%eax
int $0x80
Le code est ├®crit en assembleur GNU. Il utilise le jeu d'instructions d'un processeur de la famille x86-32. Nous en discuterons dans la section 5Exemples de codes assembleur. Dans cette section, nous allons juste montrer comment le faire tourner sur la machine.
Pour g├®n├®rer un fichier ex├®cutable ├Ā partir du code source, nous utiliserons un programme dit assembleur et un programme dit ├®diteur de liens (linker). Sous un syst├©me GNU/Linux, l'assembleur est le programme as et l'├®diteur de liens est le programme ld (loader).
Le sch├®ma suivant montre les ├®tapes ├Ā suivre pour g├®n├®rer l'ex├®cutable┬Ā:
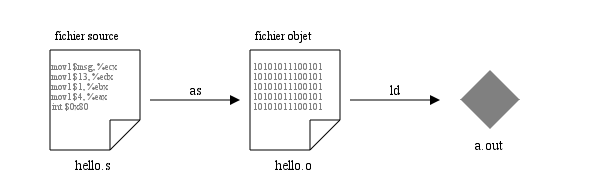
L'assembleur as prend comme entr├®e le fichier hello.s, ayant obligatoirement l'extension .s, pour g├®n├®rer le fichier objet hello.o. ├Ć son tour, l'├®diteur de liens va lier les diff├®rents morceaux du code objet et affecter ├Ā chacun son adresse d'ex├®cution (run-time address) et produire l'ex├®cutable. Celui-ci est au format ELF (Executable Linkable Format). C'est le format des fichiers binaires utilis├®s par les syst├©mes UNIX. C'est l'alternative ├Ā l'ancien format a.out (assembler output). Notre makefile contiendra les commandes (rules) suivantes┬Ā:
2.
3.
4.
5.
6.
7.
hello : hello.o
ld -o hello hello.o
hello.o : hello.s
as -o hello.o hello.s
clean :
rm -fv hello.o
Important [1]┬Ā: Le symbole global _start est le point d'entr├®e par d├®faut de l'├®diteur de liens. Il symbolise l'adresse ├Ā partir de laquelle le processeur commencera le fetch des instructions, lorsque le programme sera charg├® en m├®moire et ex├®cut├®. Si vous choisissez un nom de symbole de votre choix comme point d'entr├®e, vous devez passer l'option -e ou -entry ├Ā l'├®diteur de liens.
IV. Syntaxe de l'assembleur▲
Reprenons le code source du programme hello.s. Il contient trois sections┬Ā: .data, .bss et .text.
Chaque section contient un ensemble de d├®clarations et (optionnellement) des lignes de commentaires.
IV-A. Les sections▲
Un programme ├®crit en assembleur GNU peut ├¬tre divis├® en trois sections. Trois directives assembleur sont r├®serv├®es pour d├®clarer ces sections┬Ā:
- .text (read only)┬Ā: la section du code. Elle contient les instructions et les constantes du programme. Un programme assembleur doit contenir au moins la section .text┬Ā;
- .data (read-write)┬Ā: la section des donn├®es (data section). Elle d├®crit comment allouer l'espace m├®moire pour les variables initialisables du programme (variables globales)┬Ā;
- .bss (read-write)┬Ā: contient les variables non initialis├®es. Dans notre code, cette section est vide. On peut donc l'├®liminer.
Important [2]┬Ā: L'ordre des sections dans le code source n'est pas significatif. N'importe quelle section peut ├¬tre vide┬Ā!
IV-B. Les commentaires▲
Il existe deux m├®thodes pour commenter un code source. Les commentaires ├®crits entre /* et */ peuvent occuper plusieurs lignes. Un commentaire pr├®fix├® par un # ne peut occuper qu'une seule ligne.
IV-C. Les d├®clarations▲
Les d├®clarations peuvent prendre quatre formats┬Ā:
2.
3.
4.
5.
.nom directive
label_1 : .nom directive attribut
label_2 :
expression
instruction op1 , op2 , ...
Une d├®claration se termine par le caract├©re saut de ligne \n ou par le caract├©re ┬½┬Ā;┬Ā┬╗.
Une d├®claration peut commencer par une ├®tiquette (label). Une ├®tiquette peut ├¬tre suivie d'un symbole cl├® qui d├®termine le type de la d├®claration. Si le symbole cl├® est pr├®fix├® par un point, alors la d├®claration est une directive assembleur. Les attributs d'une directive peuvent ├¬tre un symbole pr├®d├®fini, une constante ou une expression.
IV-D. Les symboles▲
Un symbole est une s├®quence de caract├©res choisis parmi┬Ā:
- Les lettres de l'alphabet┬Ā: a .. z, A .. Z┬Ā;
- Les chiffres d├®cimaux┬Ā: 0, 1, 2, 3, 4, 5, 6, 7, 8, 9┬Ā;
- Les caract├©res┬Ā: . $.
Important [3]┬Ā: Un symbole ne doit jamais commencer par un chiffre. De plus, la casse est significative. Ainsi, on peut utiliser les symboles msg, Msg et MSg dans le m├¬me programme┬Ā: ils repr├®sentent des locations diff├®rentes dans la m├®moire.
Important [4]┬Ā: L'assembleur GNU r├®serve un ensemble de symboles cl├®s pour les directives.
Une ├®tiquette est un symbole suivi, imm├®diatement, du caract├©re ┬½┬Ā:┬Ā┬╗. Elle a deux usages┬Ā:
- Si l'├®tiquette est ├®crite dans la section du code, alors le symbole repr├®sente une valeur du compteur programme (le Program Counter ou le registre EIP du 80386).
On peut alors utiliser l'├®tiquette pour se r├®f├®rer dans le programme. On peut par exemple utiliser le nom du symbole de l'├®tiquette comme op├®rande de l'instruction jmp pour transf├®rer le contr├┤le ├Ā la portion de code situ├®e ├Ā l'adresse symbolis├®e par l'├®tiquette┬Ā; - Si l'├®tiquette est ├®crite dans la section de donn├®es (.data), alors le symbole repr├®sente une adresse dans la zone m├®moire des donn├®es. Par exemple, le symbole msg repr├®sente l'adresse du premier octet (code ASCII) de la cha├«ne de caract├©res ┬½┬ĀHello, World┬Ā!┬Ā┬╗.
Important [5]┬Ā: Le nom du symbole d'une ├®tiquette doit ├¬tre unique dans un programme. Autrement dit, vous ne devez jamais utiliser le m├¬me symbole pour repr├®senter deux locations (├®tiquettes) diff├®rentes. Les symboles locaux sont la seule exception.
Les symboles locaux▲
L'assembleur GNU propose dix noms de symboles locaux┬Ā: ┬½┬Ā0┬Ā┬╗, ┬½┬Ā1┬Ā┬╗ .. ┬½┬Ā9┬Ā┬╗. Vous pouvez d├®finir un symbole local en ├®crivant une ├®tiquette de la forme ┬½┬ĀN :┬Ā┬╗, avec N┬Ā=┬Ā0, 1 .. 9. Pour se r├®f├®rer au dernier symbole N d├®fini, vous pouvez, par exemple, sp├®cifier ┬½┬ĀNb┬Ā┬╗ comme op├®rande de l'instruction jmp. De m├¬me, pour se r├®f├®rer au premier symbole N suivant, vous pouvez sp├®cifier ┬½┬ĀNf┬Ā┬╗ comme op├®rande. La lettre ┬½┬Āb┬Ā┬╗ dans ┬½┬ĀNb┬Ā┬╗ est l'abr├®viation du mot anglais backwards. La lettre ┬½┬Āf┬Ā┬╗ dans ┬½┬ĀNf┬Ā┬╗ est celle du mot forwards.
1:
##
##
jmp 1b
jmp 1f
##
##
1:
##
jmp 1b
jmp 2f
2:
##
##
2:La premi├©re instruction jmp va transf├®rer le contr├┤le ├Ā la portion de code situ├®e ├Ā l'adresse symbolis├®e par la premi├©re ├®tiquette ┬½┬Ā1 :┬Ā┬╗. En ex├®cutant le deuxi├©me et le troisi├©me jmp, le processeur va commencer (imm├®diatement) l'ex├®cution ├Ā l'adresse symbolis├®e par la deuxi├©me ├®tiquette ┬½┬Ā1 :┬Ā┬╗. La quatri├©me instruction jmp va transf├®rer le contr├┤le ├Ā la portion de code situ├®e ├Ā l'adresse symbolis├®e par la premi├©re ├®tiquette ┬½┬Ā2 :┬Ā┬╗ (troisi├©me ├®tiquette dans le code┬Ā!).
Vous remarquez, dans l'exemple ci-dessus, qu'on a utilis├® le m├¬me symbole ┬½┬Ā1┬Ā┬╗ pour repr├®senter deux locations diff├®rentes. Ce qui est normalement interdit. Mais ├¦a fonctionnera quand m├¬me. En effet, les noms des symboles locaux sont juste des notations utilis├®es temporairement par le compilateur et le programmeur. Ils seront transform├®s en d'autres symboles avant d'├¬tre utilis├®s par l'assembleur. Vous pouvez consulter le manuel de l'assembleur GNU pour savoir comment ces symboles seront transform├®s.
IV-D-1. Le symbole ┬½┬Ā.┬Ā┬╗▲
Le symbole sp├®cial ┬½┬Ā.┬Ā┬╗ peut ├¬tre utilis├® comme une r├®f├®rence ├Ā une adresse au moment de l'assemblage.
Exemple┬Ā:
Dans le programme de la section 3L'assemblage et l'├®dition de liens sous Linux, avant d'ex├®cuter l'appel syst├©me, le registre EDX doit contenir la taille (le nombre de caract├©res) len du message. L'expression suivante permet de calculer pr├®cis├®ment len┬Ā:
len = . - msg
Ici, le symbole ┬½┬Ā.┬Ā┬╗ fait r├®f├®rence ├Ā l'adresse de l'octet situ├® juste apr├©s le message dans la zone m├®moire des donn├®es. Donc, len est ├®gale 14. C'est exactement le nombre d'octets de notre message.
IV-E. Les constantes▲
Les nombres entiers▲
Un nombre entier peut ├¬tre repr├®sent├® dans plusieurs syst├©mes de num├®ration. L'assembleur GNU en identifie quatre┬Ā: le binaire, le d├®cimal, l'octal et l'hexad├®cimal.
- Un nombre binaire est un 0b ou 0B suivi de z├®ro ou plusieurs chiffres binaires {0, 1}.
Exemple┬Ā: 0b10011. - Un nombre octal est un 0 suivi de z├®ro ou plusieurs chiffres octaux {0, 1, 2, 3, 4, 5, 6, 7}.
Exemple┬Ā: 09122. - Un nombre d├®cimal ne doit pas commencer par 0. Il contient z├®ro ou plusieurs chiffres d├®cimaux {0..9}.
Exemple┬Ā: 97340. - Un nombre hexad├®cimal est un 0x ou 0X suivi de z├®ro ou plusieurs chiffres hexad├®cimaux {0..9, A, B, C, D, E, F}.
Exemple┬Ā: 0x6FC9D.
Les caract├©res▲
Comme le montre le , chaque caract├©re est identifi├® par son code ASCII. Dans un code assembleur, on d├®finit un caract├©re en ├®crivant son code ASCII appropri├®. En utilisant, la syntaxe de l'assembleur GNU, un caract├©re peut ├¬tre ├®crit comme une apostrophe suivie imm├®diatement de son symbole. Exemple┬Ā:
- 'A est le code ASCII 65 de A┬Ā;
- '9 d├®signe le code ASCII 100 de 9.
Les cha├«nes de caract├©res▲
Une cha├«ne de caract├©res (string) est une s├®quence de caract├©res ├®crite entre guillemets. Elle repr├®sente un tableau contigu d'octets en m├®moire. Exemple┬Ā: ┬½┬ĀHello, World┬Ā!┬Ā┬╗.
Important [6]┬Ā: La mani├©re d'obtenir des caract├©res sp├®ciaux dans une cha├«ne de caract├©res est de les ├®chapper en les faisant pr├®c├®der d'un antislash ┬½┬Ā\┬Ā┬╗.
Exemple┬Ā:
Dans le programme de la section 3L'assemblage et l'├®dition de liens sous Linux, nous avons ├®chapp├® le caract├©re saut de ligne dans le message. Ainsi, nous avons utilis├® un seul appel syst├©me pour afficher ├Ā la fois le message et effectuer le saut de ligne┬Ā:
msg : .asciz "Hello, World !\n"Le caract├©re n, lorsqu'il est pr├®fix├® par un antislash, est ├®quivalent au code ASCII (10) du caract├©re saut de ligne.
IV-F. Les expressions▲
Une expression sp├®cifie une adresse ou une valeur num├®rique. Une expression enti├©re est un ou plusieurs arguments d├®limit├®s par des op├®rateurs. Les arguments sont des symboles, des chiffres ou des sous-expressions. Une sous-expression est une expression ├®crite entre deux parenth├©ses. Les op├®rateurs peuvent ├¬tre des pr├®fixes ou des infixes┬Ā:
Pr├®fixes▲
Les op├®rateurs pr├®fixes prennent un argument absolu. as propose deux op├®rateurs pr├®fixes┬Ā:
- L'op├®rateur Ōł╝ compl├®ment bit-├Ā-bit (bitwise not).
Exemple┬Ā: Ōł╝ 0b10001110 = 10001110 = 01110001┬Ā; - L'op├®rateur n├®gation - (compl├®ment ├Ā deux)┬Ā: ŌłÆN = Ōł╝ N + 1.
Exemple┬Ā: N = 142 = 0b10001110, ŌłÆ142 = 01110001 + 1 = 01110010.
Infixes▲
Un op├®rateur de type infixe prend deux arguments┬Ā: ŌłŚ, /, %, <, <<, >, >>, +, ŌłÆ, == ŌĆ”
Exemples d'expressions┬Ā:
2.
3.
4.
len = . - msg
SYSSIZE = 0x80000
SYSSEG = 0x1000
ENDSEG = SYSSEG + SYSSIZE # ENDSEG = 0x81000
IV-G. Syntaxe des instructions 80386 (IA-32)▲
Les op├®randes▲
- Les registres┬Ā: les op├®randes de type registre doivent ├¬tre pr├®fix├®s par un %.
Exemples┬Ā: %eax, %ax, %al, %ah, %ebx, %ecx, %edx, %esp, %ebp, %esi, %ediŌĆ” - Les op├®randes imm├®diats┬Ā: les op├®randes de ce type doivent ├¬tre pr├®fix├®s par un $.
Exemples┬Ā: $4, $0x79ff03C3, $0b10110, $07621, $msgŌĆ” - Les op├®randes m├®moire┬Ā: lorsqu'un op├®rande r├®side dans le segment de donn├®es du programme, le processeur doit calculer son adresse effective (EA┬Ā: Effective Address) en se basant sur l'expression suivante┬Ā:
EA = base + scale * index + disp.
L'assembleur GNU utilise la syntaxe AT &T qui traduit l'expression pr├®c├®dente en celle-ci┬Ā:
EA = disp (base, index, scale)
avec┬Ā:
- disp┬Ā: un d├®placement facultatif. disp peut ├¬tre un symbole ou un entier sign├®┬Ā;
- scale┬Ā: un scalaire qui multiplie index. Il peut avoir la valeur 1, 2, 4 ou 6. Si le scale n'est pas sp├®cifi├®, il est substitu├® par 1┬Ā;
- base┬Ā: un registre 32 bits optionnel. Souvent, on utilise EBX et EBP (si l'op├®rande est dans la pile) comme base┬Ā;
- index┬Ā: un registre 32 bits optionnel. Souvent, on utilise ESI et EDI comme index.
La taille des op├®randes peut ├¬tre cod├®e dans le dernier caract├©re de l'instruction┬Ā: b indique une taille de 8 bits, w indique une taille de 16 bits et l indique une taille de 32 bits.
Exemples┬Ā:
2.
3.
movb $0x4f,%al # 8-bit
movw $0x4ffc,%ax # 16-bit
movl $0x9cff83ec,%eax # 32-bit
L'ordre des op├®randes▲
L'assembleur GNU utilise la syntaxe AT&T. Ainsi, une instruction mov doit ├¬tre ├®crite comme suit┬Ā:
mov source,destination
Cet ordre doit ├¬tre respect├® avec le reste des instructions┬Ā: sub, addŌĆ”
Les instructions LJMP/LCALL▲
Les instructions LJMP (Long Jump) et LCALL (Long Call) permettent de transf├®rer le contr├┤le ├Ā un autre programme situ├® dans un autre segment (autre que celui o├╣ elles sont ├®crites┬Ā!). La syntaxe de ces deux instructions est┬Ā:
Ljmp $segment,$offset
lcall $segment,$offsetLe premier op├®rande de chaque instruction sera charg├® dans le registre CS et le deuxi├©me sera charg├® dans le registre EIP (ou IP en mode r├®el┬Ā!).
IV-H. Les directives▲
Les directives sont des pseudo-op├®rations. Elles sont utilis├®es pour simplifier, pour le programmeur, quelques op├®rations complexes telles que l'allocation de la m├®moire. Comme on l'a dit dans la section pr├®c├®dente, le nom d'une directive est un symbole cl├® pr├®fix├® par un point.
Il existe plus de 70 directives d├®finies par l'assembleur GNU. Les plus utilis├®es sont┬Ā:
.ascii ŌĆØstring_1ŌĆØ, ŌĆØstring_2ŌĆØ ŌĆ”▲
D├®finit z├®ro ou plusieurs cha├«nes de caract├©res s├®par├®es par des virgules.
2.
msg1 : .ascii "Hello, World !\ n"
bootMsg : .ascii "Loading system ..."
.asciz ŌĆØstring_1ŌĆØ, ŌĆØstring_2ŌĆØ ŌĆ”▲
D├®finit z├®ro ou plusieurs cha├«nes de caract├©res s├®par├®es par des virgules et dont chacune se termine par le caract├©re '\0.
Ainsi, ces deux d├®clarations sont ├®quivalentes┬Ā:
2.
msg1 : .ascii "Hello, World !\0"
msg2 : .asciz "Hello, World !"
.byte expression_1, expression_2 ŌĆ”▲
D├®finit et initialise un tableau d'octets.
tab_byte : .byte 23,'%,0xff,9,'\b
Le premier ├®l├®ment est le nombre 23 et il est situ├® ├Ā l'adresse tab_byte, suivi par le code ASCII du caract├©re %ŌĆ”
.word expression_1, expression_2 ŌĆ”▲
D├®finit et initialise un tableau de mots binaires (16 bits ou word).
2.
3.
4.
descrp : .word 0x07ff
.word 0x0000
.word 0x9200
.word 0x00C0
Important [7]┬Ā: Avec les processeurs de la famille x86, l'adresse d'un mot, double mot ou d'un quad-mot (64 bits) est l'adresse de son LSB (Least Significant Byte). Ainsi, le quad-mot 0x00C09200000007ff se trouve ├Ā l'adresse repr├®sent├®e par descrp. C'est l'adresse de l'octet 0x07ff.
.quad expression_1, expression_2 ŌĆ”▲
D├®finit et initialise un tableau de quad-mots.
2.
3.
4.
_gdt : .quad 0x0000000000000000
.quad 0x00c09A00000007ff
.quad 0x00C09200000007ff
.quad 0x0000000000000000
Un .quad est ├®quivalent ├Ā quatre .word successifs.
.int expression_1, expression_2 ŌĆ”▲
D├®finit et initialise un tableau d'entiers (quatre octets).
tab_int : .int 3*6,16,190,-122
.long expression_1, expression_2 ŌĆ”▲
D├®finit et initialise un tableau d'entiers (quatre octets).
2.
3.
matrix3_3 : .long 22,36,9
.long 10,91,0
.long 20,15,1
.fill repeat, size, value▲
R├®serve repeat adresses contigu├½s dans la m├®moire et les charge avec les valeurs value de taille size.
idt : .fill 256,8,0
D├®finit un tableau contenant 256 quad-mots ├Ā l'adresse idt. Chaque ├®l├®ment du tableau contient z├®ro comme valeur.
.org new-lc, fill▲
Avance le compteur location de la section courante ├Ā l'adresse new-lc.
2.
3.
4.
5.
.text
.global _start
_start :
.org 510,0
.word 0xAA55
Avance le compteur location (registre EIP) de la section texte (code segment) ├Ā l'adresse 510 puis ├®crit le mot 0xAA55. Les octets 0..509 seront charg├®s par des z├®ros.
.lcomm symbol, length▲
D├®clare un symbole local et lui attribue length octets sans les initialiser.
2.
.bss
.lcomm buffer,1024
Important [8]┬Ā: La directive doit ├¬tre ├®crite dans la section .bss.
.global symbol▲
D├®clare un symbole global et visible pour l'├®diteur de liens ld.
.global _start,main
Par d├®faut, l'├®diteur de liens ld reconna├«t le symbole global _start comme point d'entr├®e ├Ā l'├®dition de liens.
Important [9]┬Ā: Un symbole global d├®clar├® dans un fichier source peut ├¬tre utilis├® dans un autre fichier sans le red├®clarer.
.set symbol, expression et .equ symbol, expression▲
Ces deux directives sont similaires ├Ā l'expression┬Ā: symbol = expression.
2.
.set SYSSIZE,0x80000
.equ SYSSEG,0x1000
V. Exemples de codes assembleur▲
V-A. Exemple 1┬Ā: tri ├Ā bulles d'une liste d'entiers▲
Le programme tris.s utilise la m├®thode de tri ├Ā bulles pour trier une liste d'entiers positifs entr├®s au clavier. La liste tri├®e sera, ensuite affich├®e, sur la console.
D├®claration des variables▲
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
.data
line : .byte '\n
space : .byte 0x20
msg1 : .ascii " << "
len1 = . - msg1
msg2 : .ascii " >> "
len2 = . - msg2
.bss
.lcomm buffer,1024
.lcomm list,100
.lcomm stack,1024
- buffer┬Ā: une m├®moire tampon pour stocker temporairement les caract├©res entr├®s au clavier┬Ā;
- list┬Ā: c'est un tableau d'entiers qui peut stocker 25 nombres entiers┬Ā;
- stack┬Ā: pour r├®server 1024 octets dans la pile du programme.
├ētape 1┬Ā: entrer la liste d'entiers au clavier▲
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
msg_1 : ##
movl $msg1,%ecx ## ECX = l'adresse du message
movl $len1,%edx ## EDX = la longueur du message en octets
movl $1,%ebx ## EBX = file descriptor = 1 => standard output
movl $4,%eax ## Appel syst├©me 4 : write
int $0x80 ## Interruption logicielle (Exception) ID = 0x80
# Saisir les entiers #############
kybd : ##
movl $buffer,%ecx ## ECX = l'adresse du buffer
movl $1024,%edx ## EDX = la taille du buffer en octets
movl $0,%ebx ## EBX = file descriptor = 0 => standard input
movl $3,%eax ## Appel systeme 3 : read
int $0x80
# Compter les elements de la liste ##
subl %esi,%esi
1:
movl buffer(%esi),%ebx ## EA = Scale * Index + Displacement
incl %esi
cmp %bl,line
jne 1b
Les registres EAX, EBX, ECX, EDX doivent ├¬tre initialis├®s correctement avant l'ex├®cution de l'instruction int $0x80. L'instruction int n g├®n├©re une exception (interruption logicielle) imm├®diatement apr├©s son ex├®cution.
L'ID (Interrupt Identifier) de l'exception est cod├® dans l'instruction (n). Le noyau Linux utilise le nombre 128 (0x80) pour identifier les interruptions programm├®es des autres interruptions (NMI, Divide Error, TrapŌĆ”). Ainsi, l'instruction int $0x80 (ou int $128) permet ├Ā notre programme (application) d'acc├®der au mat├®riel (clavier, ├®cranŌĆ”) en ex├®cutant un appel syst├©me. Le fichier /usr/include/asm-x86/unistd_32.h liste tous les appels syst├©me Linux.
On va utiliser les appels syst├©me 1, 3 et 4. Le registre EAX doit explicitement contenir le num├®ro de l'appel syst├©me. ├ēgalement, le registre EBX doit contenir le descripteur (file descriptor) du p├®riph├®rique.
Les instructions 10..15 vont charger le buffer avec la liste des caract├©res (les entiers), en ex├®cutant l'appel syst├©me 3 (read). Les entiers entr├®s au clavier doivent ├¬tre s├®par├®s par un espace (seulement un┬Ā!).
En ex├®cutant les instructions 17..24, le processeur va calculer le nombre de caract├©res entr├®s et le charger dans le registre ESI.
Pour illustrer, supposons qu'on a entr├® la liste┬Ā: 19 208 9756 101 229. Le buffer contient 18 caract├©res┬Ā:
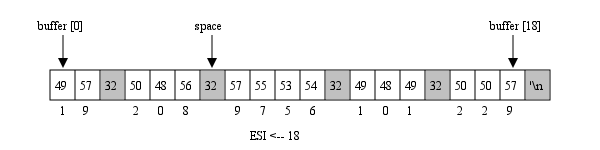
Le caract├©re saut de ligne doit ├¬tre entr├® ├Ā la fin pour valider la saisie.
├ētape 2┬Ā: convertir les caract├©res du buffer▲
On a dit, au d├®but de ce tutoriel, que l'ordinateur utilise le codage ASCII pour ├®changer de l'information avec les p├®riph├®riques d'entr├®e/sortie. Ainsi, et comme le montre le sch├®ma ci-dessus, la liste des entiers est re├¦ue par l'ordinateur comme un flux (stream) de codes ASCII. Chaque code repr├®sente un caract├©re.
Donc, pour qu'on puisse effectuer des traitements (arithm├®tiques, comparaisonsŌĆ”) sur des entiers, nous devons d'abord convertir le buffer en une liste d'entiers. C'est l'objectif des lignes de code suivantes┬Ā:
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
35.
36.
37.
38.
39.
decl %esi ## index dans le buffer
movl $0,%edi ## index dans la liste
new_elem :
movl $10,%esp ## pour multiplier par 10
movl $0,%ebp ## compter le poids de chaque chiffre
subl %eax,%eax ## EAX = 0
subl %ecx,%ecx ## ECX = 0
new_digit :
addl %eax,%ecx ## ECX = ECX + EAX
subl %eax,%eax
decl %esi
cmpl $0,%esi
jl 1f ## si ESI = 0
movb buffer(%esi),%al ## charger un nouveau chiffre dans AL
cmp $32,%al
je if_space ## si buffer (%esi) = 32 (espace)
subl $48,%eax ## chiffre decimal = ascii - 48
incl %ebp
cmpl $1,%ebp
je new_digit
movl %ebp,%ebx ## multiplier EAX n (poids) fois par 10
mult_10 :
mul %esp
decl %ebx
cmpl $1,%ebx
jg mult_10
je new_digit
if_space :
movl %ecx,list(,%edi,4) ## sauvegarder le contenu de ECX
incl %edi
jmp new_elem
1 :
movl %ecx,list(,%edi,4)
L'adresse effective d'un caract├©re dans le buffer est┬Ā:
EA = disp + base = buffer + %esi = buffer(base, 0, 1) = buffer(%esi)
L'instruction mul utilise implicitement le registre EAX pour stocker le nombre ├Ā multiplier. Le r├®sultat sera charg├® dans EDX:EAX. Le seul op├®rande de l'instruction est le multipliant, qui est le contenu (10) du registre ESP dans notre cas.
├ētant donn├® le code ASCII d'un nombre d├®cimal, pour convertir ce code au nombre d├®cimal appropri├®, on doit soustraire 48.
Exemple┬Ā: ASCII(3) = 51 = 3 + 48 <==> 3 = ASCII(3) ŌłÆ 48 (voir ).
D'autre part, un nombre d├®cimal est ├®gal ├Ā la somme de ses chiffres multipli├®s, chacun, par 10n. n est le poids de chaque chiffre dans le nombre.
Donc, pour convertir un nombre du buffer repr├®sent├® par des caract├©res, on doit d'abord convertir ces caract├©res en des nombres d├®cimaux. Puis, on doit appliquer la formule de la section II-ALes syst├©mes de num├®ration. Pour bien fixer les id├®es, on va prendre comme exemple le nombre 229 (voir le sch├®ma ci-dessus). Pour le convertir, le processeur doit effectuer le calcul suivant┬Ā:
229 = (50 ŌłÆ 48) ŌłŚ 102 + (50 ŌłÆ 48) ŌłŚ 101 + (57 ŌłÆ 48) ŌłŚ 100 = 2 ŌłŚ 100 + 2 ŌłŚ 10 + 9 ŌłŚ 1
Pour convertir tous les ├®l├®ments de la liste, le processeur proc├©de comme suit┬Ā: tant que ESI > 0┬Ā:
- charger l'octet ├Ā l'adresse buffer(%esi) dans le registre AL et le comparer ├Ā 32 (le code ASCII du caract├©re SPACE)┬Ā;
- si le contenu de AL est diff├®rent de 32, on soustrait 48 de AL. Ensuite, on multiplie le r├®sultat (AL - 48) n fois par 10 (n est le poids du chiffre). Le r├®sultat de la multiplication sera charg├® dans EAX. On doit l'ajouter au contenu de ECX, parce que la multiplication utilise implicitement les registres EAX et EDX. ECX doit ├¬tre nettoy├® ├Ā chaque fois qu'on rencontre un espace┬Ā;
- un jmp if_space est ex├®cut├® si le contenu de AL est ├®gal ├Ā 32. ECX contient la somme de tous les chiffres de chaque nombre apr├©s la multiplication par 10. Cette somme n'est autre que le code binaire (32 bits) du nombre. On le sauvegarde ├Ā l'adresse┬Ā:
EA = disp + scale*index = list + %edi * 4 = list( 0 , index, 4 ) = list(,%edi,4)
Le scale est ├®gal ├Ā 4 parce que la taille d'un entier est 4 octets┬Ā!
Finalement, Le registre EDI contient le nombre d'entiers de la nouvelle liste (list).
├ētape 3┬Ā: trier la liste▲
Voir le programme sort.c.
├ētape 4┬Ā: afficher la liste tri├®e▲
Pour afficher un ├®l├®ment de la liste, l'ordinateur doit envoyer le code ASCII de chacun de ses chiffres au p├®riph├®rique de sortie standard (l'├®cran, fd = 1). D'autre part, les entiers de la liste sont stock├®s dans la m├®moire au format binaire (32 bits). On doit donc les convertir en un flux de caract├©res. Autrement dit, on doit calculer les codes ASCII (48..57) de chacun de ces chiffres.
C'est l'objectif de cette portion de notre code┬Ā:
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
movl %edi,%esi
2 :
movl $10,%ebx
movl list(,%esi,4),%eax
movl $stack,%esp
3 :
movl $0,%edx
idivl %ebx
decl %esp
addl $48,%edx
movb %dl,(%esp)
cmpl $0,%eax
jg 3b
movl $stack,%edx
subl %esp,%edx
movl %esp,%ecx
movl $1,%ebx
movl $4,%eax
int $0x80
movl $1,%edx
movl $space,%ecx
movl $1,%ebx
movl $4,%eax
int $0x80
decl %esi
cmpl $0,%esi
jge 2b
Les propri├®t├®s de la pile vont nous faciliter cette t├óche. Une conversion ┬½┬Ād├®cimal-d├®cimal┬Ā┬╗ (division enti├©re par 10) nous permettra d'extraire les chiffres de chaque entier. Pour avoir le code ASCII de chaque chiffre, on doit ajouter 48 ├Ā son code obtenu par division enti├©re (divl). Le sch├®ma suivant montre la conversion du nombre 269┬Ā:
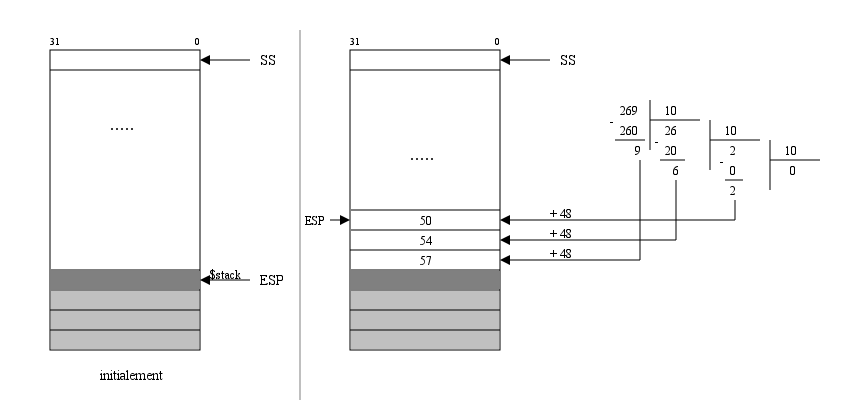
Les instructions 22 et 23 permettent de calculer le nombre d'octets empil├®s (12 octets pour le nombre 269). Le registre EDX doit contenir ce nombre pour ex├®cuter l'appel syst├©me. Le registre ECX pointe vers le TOS (Top Of Stack), c'est-├Ā-dire vers le premier chiffre. ├Ć l'ex├®cution de l'appel syst├©me, le processeur va afficher 2 puis 6 puis 9 (c'est exactement 269) puis un espace.
V-B. Exemple 2┬Ā: les sous-programmes en assembleur▲
Le but de l'exemple somme.s est de montrer le passage des param├©tres ├Ā travers la pile ├Ā un sous-programme. Une telle op├®ration doit suivre quelques r├©gles (conventions) pour rendre efficace la communication entre le programme appelant et le sous-programme appel├®.
Le stack frame▲
Le processeur alloue, dynamiquement, un espace de stockage dans la pile pour chaque sous-programme. Cet espace est appel├® stack frame. Il sera compl├©tement lib├®r├® au retour du sous-programme.
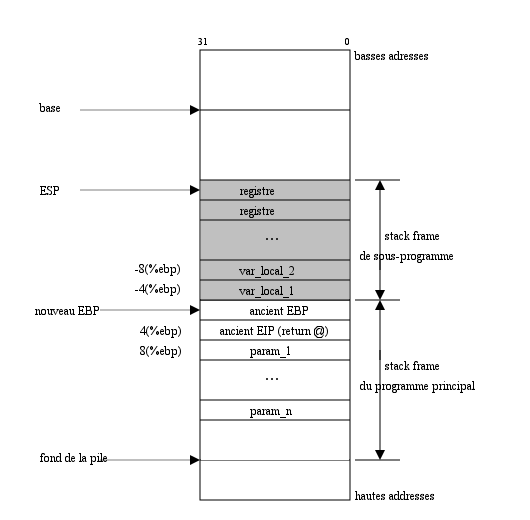
Un sous-programme utilise son propre stack frame pour stocker ses variables locales (variables automatiques en C, qui seront perdues au retour du sous-programme┬Ā!) durant son ex├®cution. M├¬me la fonction principale main() d'un programme poss├©de son propre stack frame┬Ā!
Les ├®tapes ├Ā suivre▲
Les ├®tapes n├®cessaires pour invoquer efficacement un sous-programme sont┬Ā:
- empiler les param├©tres qu'on veut passer au sous-programme┬Ā;
- appeler le sous-programme avec l'instruction call┬Ā;
- enregistrer et mettre ├Ā jour le registre EBP, dans le sous-programme┬Ā:
2.
push %ebp
movl %esp,%ebp
- sauvegarder le contexte┬Ā: empiler le contenu des registres du processeur pour ne pas les perdre durant l'ex├®cution du sous-programme┬Ā;
- ex├®cuter le sous-programme┬Ā: au cours de cette ├®tape, le registre ESP ne doit pas ├¬tre modifi├®. Le registre EBP est utilis├® pour se r├®f├®rer aux donn├®es dans la pile┬Ā;
- lib├®rer l'espace m├®moire allou├® aux variables locales, en les d├®pilant de la pile┬Ā;
- restaurer les anciennes valeurs des registres┬Ā;
- restaurer la valeur de EBP┬Ā: cette ├®tape va d├®truire le stack frame. ├ēcrire ces deux lignes de code avant l'instruction RET┬Ā:
2.
movl %ebp,%esp
pop %ebp
- charger l'adresse de retour dans EIP┬Ā: en ex├®cutant l'instruction RET. Tout simplement, elle va charger le nouveau TOS dans le registre EIP┬Ā;
- nettoyer la pile┬Ā: en d├®pilant les param├©tres empil├®s pendant l'├®tape┬Ā1.
Le code somme.c montre comment effectuer un passage par adresse et un passage par valeur en langage C. Cependant, le code somme.s montre ces deux m├®thodes de passage des param├©tres en assembleur GNU.
Ce programme fait appel ├Ā la fonction C printf(). L'exemple┬Ā3 va expliquer comment le faire.
V-C. Exemple 3┬Ā: interfacer du code assembleur et du langage C▲
Le programme date.s utilise les fonctions C standard scanf et printf pour saisir et afficher la date.
En langage C, les param├©tres sont pass├®s entre parenth├©ses┬Ā: printf(param,ŌĆ”) et scanf(param,ŌĆ”). Ce n'est pas le cas en assembleur┬Ā: les param├©tres doivent ├¬tre pass├®s ├Ā travers la pile┬Ā!
L'ordre des param├©tres dans la pile est significatif. Ils doivent ├¬tre pass├®s dans l'ordre suivant┬Ā:
| Adresse | Param├©tre |
|---|---|
| 0(%ebp) | l'ancien EBP |
| 4(%ebp) | adresse de retour |
| 8(%ebp) | adresse de format (pformat et sformat) |
| 12(%ebp) | valeur/adresse de la variable jour |
| 16(%ebp) | valeur/adresse de la variable mois |
| 20(%ebp) | valeur/adresse de la variable an |
Ainsi, les param├©tres doivent ├¬tre empil├®s dans l'ordre inverse ├Ā celui dans lequel ils sont ├®crits dans le prototype de la fonction (parm1, parm2ŌĆ”)┬Ā! Autrement dit, le dernier param├©tre doit ├¬tre empil├® le premier et le premier param├©tre doit ├¬tre empil├® le dernier┬Ā!
Les valeurs de retour de scanf et printf sont retenues dans le registre EAX.
Les ├®tapes 3-9 d'appel des sous-programmes en assembleur sont invisibles, puisque nous ne sommes pas responsables de l'impl├®mentation de la fonction standard. On va juste y faire appel.
Le Makefile▲
Pour construire l'ex├®cutable ├Ā partir d'un code source ├®crit purement en assembleur, on a utilis├® les programmes as et ld. C'est le cas de l'exemple 1. Mais pour assembler et faire l'├®dition de liens d'un programme assembleur invoquant des fonctions C, on doit utiliser un compilateur. Sous Linux, le compilateur C est le programme gcc.
2.
3.
4.
5.
6.
7.
date : date.o
gcc -gstabs -o date date.o
date.o : date.s
gcc -c -o date.o date.s
clean :
rm -fv date date.o
Le compilateur gcc va transformer (compiler) notre code source (C + assembleur) en un code cible (code assembleur). Puis il va faire appel ├Ā as pour assembler et ├Ā ld pour construire l'ex├®cutable. Le point d'entr├®e de ld doit ├¬tre le symbole global main.
Retour sur l'exemple┬Ā1
Le dossier exemple_3 contient un sous-dossier nomm├® tri. Le code source qu'il contient est une r├®├®criture du programme tri.s de l'exemple┬Ā1. On a modifi├® le programme par l'utilisation des deux fonctions C d├®finies dans le fichier func.c┬Ā: saisir() et trier()┬Ā:
- la fonction saisir(), lorsqu'elle est appel├®e, va demander ├Ā l'utilisateur de saisir (scanf()) une liste d'entiers et de les charger dans un tableau (list) d'entiers┬Ā;
- la fonction trier() va trier la liste d'entiers en utilisant l'algorithme de tri ├Ā bulles.
L'utilisation de ces deux fonctions, ainsi que l'utilisation de la fonction C standard printf() pour l'affichage, va nous aider ├Ā r├®duire la taille du programme, en ├®liminant pas mal d'instructions assembleur. Notre code devient plus simple, plus structur├® et donc plus compr├®hensible.
V-D. Exemple 4┬Ā: un programme d'amor├¦age▲
Un secteur d'amor├¦age (Boot Sector) est, g├®n├®ralement, constitu├® des 512 premiers octets d'un support de stockage (disquette, disque dur, CD/DVD, flash disk) qui peut contenir un programme d'amor├¦age (Bootstrap program). Pour un CD/DVD, une disquette ou un disque dur, un tel secteur n'est autre que le premier secteur (piste 0, t├¬te 0, secteur 1).
D'autre part, un programme d'amor├¦age est un programme 16 bits ex├®cutable, qui sera charg├® par le programme de d├®marrage du BIOS, dans la m├®moire RAM durant la s├®quence d'amor├¦age de l'ordinateur.
├Ć travers cet exemple, on va montrer comment ├®crire un tel programme et comment le faire tourner sur une machine occup├®e par un processeur de la famille x86 (x86-32 ou x86-64).
Les codes sources des exemples cit├®s dans cette section sont t├®l├®chargeables sur cette page.
Le mode r├®el▲
Le 80386 a introduit aux processeurs de la famille x86 la capacit├® ├Ā fonctionner en trois modes┬Ā: mode prot├®g├®, mode virtuel et mode r├®el (ou mode 8086).
Le mode r├®el est le mode de fonctionnement du processeur imm├®diatement apr├©s la mise de l'ordinateur sous tension. Dans ce mode, certains registres du processeur sont initialis├®s, par INTEL, ├Ā des valeurs pr├®d├®finies. En outre, la protection, les interruptions et la pagination sont d├®sactiv├®es et l'espace m├®moire complet est disponible.
Ainsi, le processeur peut ex├®cuter uniquement des programmes 16 bits. Cet ├®tat du processeur est ad├®quat pour ex├®cuter un programme d'amor├¦age.
L'architecture interne du processeur en mode r├®el▲
En mode r├®el, un processeur de la famille x86 (x86-32 ou x86-64) ex├®cute uniquement des codes 16 bits con├¦us pour le 80286 et le 8086. Par cons├®quent, son architecture interne est presque identique ├Ā celle du 8086.
Le tableau suivant montre comment certains registres (le 30486, le Pentium┬ĀI et tous les processeurs de la famille P6) sont initialis├®s en mode r├®el┬Ā:
| Registre | Contenu |
|---|---|
| EFLAGS | 0x0002 |
| EIP | 0xFFF0 |
| CS | S├®lecteur┬Ā: 0xF000 Base┬Ā: 0xFFFF0000 Limite┬Ā: 0xFFFF |
| DS,SS,ES,FS,GS | Base┬Ā: 0x00000000 Limite┬Ā: 0xFFFF |
| GDTR,IDTR | Base┬Ā: 0x00000000 Limite┬Ā: 0xFFFF |
Pour plus de d├®tails, jetez un coup d'┼ōil sur le chapitre 9 de ce document.
L'adressage de la m├®moire en mode r├®el▲
Quelle que soit la taille de la m├®moire de votre ordinateur, dans le mode r├®el le processeur peut adresser seulement 1┬ĀMo + 64┬ĀKo de RAM. Les 64┬ĀKo sont utilis├®s pour adresser les p├®riph├®riques d'entr├®es/sorties. Le processeur peut, alors, seulement manipuler des octets et des mots (16 bits). Cet espace m├®moire peut ├¬tre localis├® dans n'importe quelle zone de la m├®moire physique, ├Ā condition qu'elle ne soit pas r├®serv├®e par INTEL.
En mode prot├®g├®, un processeur de la famille x86 utilise la r├©gle suivante pour calculer une adresse physique┬Ā:
Adresse lin├®aire = Adresse physique = Base + Offset
On l'a appel├®e adresse physique parce qu'en mode r├®el, la pagination sera d├®sactiv├®e.
D'autre part, en mode r├®el l'adresse physique est normalement calcul├®e en utilisant cette r├©gle┬Ā:
adresse logique = offset : base[segment selector]
adresse physique = base x 16 + offset
Cependant, ├Ā la r├®initialisation du processeur (RESET), l'adresse de base est ├®gale ├Ā 0xFFFF0000 (voir le tableau ci-dessus). Ainsi, l'adresse de d├®part est form├®e par l'addition de la valeur de l'adresse de base et le contenu du registre EIP (offset). Ainsi┬Ā:
Adresse physique = 0xFFFF0000 + 0xFFF0 = 0xFFFFFFF0
Juste apr├©s la mise sous tension de l'ordinateur, le processeur utilise la premi├©re r├©gle pour localiser et ex├®cuter le programme BIOS. Ensuite, le processeur va suivre la r├©gle normale pour la traduction des adresses en mode r├®el (processeur 8086).
La premi├©re instruction qui sera ex├®cut├®e par le processeur, apr├©s RESET, devrait ├¬tre ├Ā l'adresse physique 0xFFFFFFF0. Cette instruction va amener le processeur ├Ā ex├®cuter une instruction JMP vers le programme BIOS. Lorsque celui-ci prend le contr├┤le, il commence par ex├®cuter les tests POST. Une fois ces tests pass├®s avec succ├©s, le programme BIOS va chercher un p├®riph├®rique amor├¦able pour d├®marrer le syst├©me.
Le BIOS▲
Pour une machine compatible avec l'IBM PC, le BIOS (Basic Input Output System) est le premier programme (microcode ou firmware) ex├®cut├® par le processeur (en mode r├®el) juste apr├©s la mise sous tension de l'ordinateur. Le programme (les routines) BIOS est stock├® dans une m├®moire non volatile (ROM) int├®gr├®e ├Ā la carte m├©re. Il a deux fonctions principales┬Ā:
- Ex├®cuter les tests POST (Power-On Selft-test)┬Ā: v├®rifier l'int├®grit├® du programme BIOS lui-m├¬me, tester la RAM, tester et initialiser les autres p├®riph├®riques de l'ordinateur, initialiser l'IVT (Interrupt Vector Table)ŌĆ”┬Ā;
- Chercher un p├®riph├®rique amor├¦able (bootable) pour d├®marrer le syst├©me (charger le noyau du syst├©me en m├®moire). C'est en v├®rifiant, dans l'ordre, le secteur d'amor├¦age de chaque p├®riph├®rique connect├® ├Ā l'ordinateur et configur├® dans la liste (du BIOS) des p├®riph├®riques d'amor├¦age. Lorsque le BIOS rencontre un secteur d'amor├¦age, il charge en m├®moire le programme stock├® dedans, et lui transf├©re le contr├┤le.
Pour v├®rifier si un support de stockage est amor├¦able ou non, le BIOS teste simplement les deux derniers octets (octets 510 et 511) de son secteur d'amor├¦age. Si ces deux octets contiennent la valeur 0xAA55 (Boot Signature), alors le BIOS d├®duira que ce p├®riph├®rique est amor├¦able. Alors, il chargera les 512 octets du code ├Ā l'adresse physique 0x7C00 de la m├®moire et lui transf├®rera le contr├┤le (JMP 0x7C00).
Enfin, vous trouverez toutes les informations sur les BIOS sur ce site.
L'IVT┬Ā: Interrupt Vector Table▲
Le BIOS met ├Ā la disposition de tout programme qui s'ex├®cute en mode r├®el des routines qui vont l'aider ├Ā effectuer quelques op├®rations compliqu├®es, comme l'acc├©s au mat├®riel de l'ordinateur. Ces routines sont appel├®es les services ou encore les interruptions BIOS.
├Ć ce propos, un tableau de 256 entr├®es est stock├® par le BIOS ├Ā l'adresse absolue entre 0x0 et 0x3FF (le premier Kb de la m├®moire). Chaque entr├®e de ce tableau est de quatre octets et contient deux adresses [segment :offset] comme pointeurs vers une routine d'interruption.

Ces routines sont accessibles via l'instruction int n. Chaque interruption BIOS est identifi├®e par un nombre n. Le processeur multiplie par 4 le nombre n et utilise le r├®sultat (index) pour localiser, dans l'IVT, le vecteur d'interruption appropri├®. Le premier mot (16 bits) sera charg├® dans le registre CS (segment) et le deuxi├©me sera charg├® dans le registre IP (offset).
Ainsi, le processeur va ex├®cuter la routine convenable.
Une entr├®e dans ce tableau est not├®e vecteur parce qu'il redirige le processeur pour ex├®cuter une autre portion du code.
Un programme d'amor├¦age minimal▲
Le code suivant est celui d'un programme d'amor├¦age minimal┬Ā:
2.
3.
4.
5.
6.
7.
8.
.code16
.data
.text
.global _start
_start :
.org 510,0
.word 0xaa55
Un support de stockage, dont le secteur d'amor├¦age contient le binaire de ce programme, sera certainement amor├¦able. Mais, comme vous voyez, ce programme ne fera rien ├Ā son ex├®cution (un ├®cran noir et vide sera affich├®). Il va juste rendre votre support de stockage amor├¦able. La directive .org a d├®j├Ā ├®t├® expliqu├®e. La directive .code16 va demander ├Ā l'assembleur d'assembler un code 16 bits (mode r├®el).
En fait, tout Linuxien a un programme d'amor├¦age pr├¬t sur son ordinateur. C'est le stage1 du chargeur de boot GRUB. Ce fichier est stock├® dans le r├®pertoire /usr/lib/grub/stage1. Son r├┤le est d'initialiser le processeur au d├®marrage et de charger en m├®moire le noyau GRUB (stage2).
Pour tester un programme d'amor├¦age, vous pouvez utiliser une machine virtuelle au lieu de red├®marrer votre ordinateur plusieurs fois. Le logiciel VirtualBox, par exemple, vous permettra d'en cr├®er une.
En cas de probl├©me de d├®marrage d'une machine virtuelle sur un flash disk, visitez cette page.
Exemple 1┬Ā: hello.s
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
.code16
.text
.global_start
_start :
mov %cs,%ax # ax = 0x7c0
mov %ax,%ds # ds = 0x7c0
mov %ax,%es # es = 0 x7c0
mov %ax,%ss # ss = 0 x7c0
mov $0x100,%ax # 256 words dans la pile (512 octets)
mov %ax,%sp # sp = 256 (TOS)
mov $0x2f,%bl
mov $0,%dh # colonne 0
mov $0,%dl # ligne 0
mov $0x1301,%ax # afficher une cha├«ne de caract├©res
mov $msg,%bp # offset du message ES:BP
mov $13,%cx # taille du message
int $0x10
msg :
.asciz "hello, world !"
.org 510
signature :
.word 0xaa55
Comme on l'a dit, au d├®marrage de l'ordinateur ce programme sera charg├® dans la m├®moire ├Ā l'adresse 0x7C00 et prendra le contr├┤le. Le registre CS (base) sera charg├® avec la valeur 0x7C0 et le contenu de EIP (offset) sera 0. Ainsi, le processeur commencera la recherche des instructions (fetch) et l'ex├®cution ├Ā partir de l'adresse physique┬Ā:
CS x 16 + EIP = 0x07C0 x 0x10 + 0x0000 = 0x7C00
Notre programme poss├©de les m├¬mes segments de donn├®es de pile et de code (DS = SS = ES = CS = 0x7C0). On a utilis├® l'interruption 0x10 du BIOS pour afficher notre message. Une liste des interruptions est disponible sur cette page.
Assemblage et ├®dition de liens▲
Les commandes d'assemblage et d'├®dition de liens sont┬Ā:
as -o hello.o hello.s
ld --oformat binary -Ttext 7c00 -Tdata 7c00 -o hello hello.oOn a utilis├® l'option -oformat pour sp├®cifier ├Ā l'├®diteur de liens le format binaire du fichier de sortie (hello). Le format binaire doit ├¬tre choisi. Si on ├®dite les liens sans utiliser cette option, la taille du fichier g├®n├®r├® d├®passera 512 octets. Quand on passe cette option ├Ā l'├®diteur de liens, il va g├®n├®rer un fichier de sortie au format raw binary. Autrement dit, il va g├®n├®rer un code machine ayant exactement une taille de 512 octets. ├ēgalement, les options -Ttext et -Tdata sont utilis├®es pour indiquer ├Ā l'├®diteur de liens que les sections de texte et de donn├®es doivent ├¬tre charg├®es ├Ā l'adresse 0x7C00.
La commande suivante permet de d├®sassembler le fichier g├®n├®r├®┬Ā:
objdump -b binary -mi8086 -D helloL'option -b va sp├®cifier le format de fichier d'entr├®e (binaire). L'option -m va sp├®cifier l'architecture pour laquelle on va d├®sassembler. Nous avons sp├®cifi├® l'architecture i8086.
Pour charger votre programme de boot sur le secteur d'amor├¦age de votre flash disk, utilisez le programme dd_rescue.
Exemple 2┬Ā: rtc.s
Dans cet exemple, nous allons ├®crire un programme d'amor├¦age qui, ├Ā son ex├®cution, va lire l'horloge temps r├®el (RTC) de l'ordinateur en utilisant l'interruption BIOS num├®ro 0x1A et l'afficher au format hh:mm:ss.
├Ć l'ex├®cution de cette interruption, le processeur va lire l'horloge RTC et stocker sa valeur au format BCD compact├® (Packed BCD), dans les registres CX et BX┬Ā:
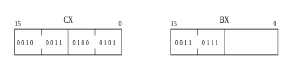
Pour afficher l'horloge, nous devons, d'abord, convertir chacun de ses chiffres cod├®s au format BCD en son code ASCII appropri├®. Le codage BCD utilise quatre bits pour coder chaque chiffre d├®cimal. Tandis que, le codage ASCII utilise 8 bits (├®tendu) ou 7 bits (standard).
On a dit, au d├®but de ce tutoriel (section II-CLe code BCD), que les bits 0-3 de chaque code ASCII d'un chiffre sont ├®gaux ├Ā son code BCD. On va utiliser cette propri├®t├® pour convertir les codes BCD en des codes ASCII.
Le sous-programme bcd_to_ascii va r├®aliser cette conversion (voir le code source rtc.s). Pour l'illustrer, nous allons prendre un exemple. Supposons que l'horloge lue soit 23:45:37. Le contenu des registres CX et BX sera┬Ā:
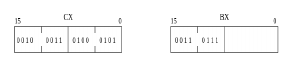
Nous allons expliquer comment convertir l'heure (h2h1) du format BCD au format ASCII.
├ētape 1┬Ā:
D├®calage logique (SHR) de 4 bits du contenu du registre AL┬Ā:
SHR $4, %al : 0010 0011 ┬╗ 4 = 0000 0010
├ētape 2┬Ā:
Addition de 48┬Ā:
0000 0010 + 00110000 = 110010 = 5010 = ASCII(2)
Ensuite, on charge le contenu de AL dans la m├®moire ├Ā l'adresse rtc(%si).
├ētape 3┬Ā:
Maintenant, nous allons convertir h2. Tout d'abord, on charge le contenu du registre CH dans AL. Ensuite, on ajuste le contenu de AL avec l'instruction AAA┬Ā:
AAA : 0010 0011 ==> 0000 0011
├ētape 4┬Ā:
Addition de 48┬Ā:
0000 0011 + 00110000 = 0011 0011 = 5110 = ASCII(3)
Ensuite, on charge le contenu de AL dans la m├®moire ├Ā l'adresse rtc(%si).
Les m├¬mes ├®tapes seront utilis├®es pour convertir les minutes et les secondes. Utilisez les m├¬mes commandes (exemple 1) pour assembler, ├®diter les liens et tester cet exemple.
Exemple 3┬Ā: int 0x13, AH = 0x42┬Ā: lecture ├®tendue des secteurs.
Dans cet exemple, on va montrer comment utiliser la fonction 0x42 de l'interruption BIOS 0x13 pour lire (en mode r├®el) des secteurs ├Ā partir d'un p├®riph├®rique de stockage de masse (un flash disk dans notre cas).
Le code source de l'exemple contient deux fichiers┬Ā:
- boot.s┬Ā: c'est un programme d'amor├¦age qui sera stock├® dans le premier secteur de notre p├®riph├®rique de stockage. Son r├┤le est de lire le deuxi├©me secteur du p├®riph├®rique et de charger le programme stock├® dedans (hello.s) en m├®moire et, ensuite, lui transf├®rer le contr├┤le┬Ā;
- hello.s┬Ā: le binaire de ce programme sera stock├® dans le deuxi├©me secteur de notre p├®riph├®rique de stockage (juste apr├©s le secteur d'amor├¦age). ├Ć son ex├®cution, ce programme va afficher un message ├Ā l'├®cran en utilisant l'interruption BIOS 0x10.
En fait, le BIOS propose une autre fonction de l'interruption 0x13 pour lire des secteurs ├Ā partir d'un p├®riph├®rique de stockage. C'est la fonction classique num├®ro 0x2 (AH = 0x2).
Cette fonction est tr├©s compliqu├®e parce qu'elle utilise l'adressage CHS (Cylinder/Head/Sector) pour localiser les secteurs ├Ā lire. De plus, elle limite le nombre de cylindres (pas plus de 1024 cylindres) et le nombre de secteurs (pas plus de 63 secteurs) ├Ā lire.
Le nombre de cylindres (d'un disque dur ou d'une disquette) est ├®gal au nombre de pistes (track) par plateau.
Par contre, la fonction 0x42 de l'interruption BIOS est tr├©s simple ├Ā utiliser et permet de lire n'importe quel secteur du p├®riph├®rique. Cette fonction traite le p├®riph├®rique comme un tableau contigu de secteurs (512 octets), o├╣ chaque ├®l├®ment (secteur) est identifi├® uniquement par son num├®ro (index)┬Ā! Cette m├®thode d'adressage des secteurs de disque dur est souvent nomm├®e Logical Block Addressing, LBA.
Le tableau suivant liste les param├©tres qu'on doit sp├®cifier pour l'interruption 0x13┬Ā:
| AL | 0x42, num├®ro de la fonction |
| DL | index du p├®riph├®rique de stockage (flash disk par exemple) |
| DS:SI | [segment :offset] pointeur vers le DAP┬Ā: Disk Address Packet |
L'index de p├®riph├®rique de stockage sera charg├® automatiquement par le BIOS, au d├®marrage, dans le registre DL. D'autre part, le DAP est une structure de donn├®es qu'on doit sp├®cifier ├Ā l'interruption 0x13. Elle doit contenir exactement les informations suivantes┬Ā:
| Offset | Taille | Description |
|---|---|---|
| 0x0 | 1 octet | La taille du DAP = 16 octets |
| 0x1 | 1 octet | inutilis├®, doit ├¬tre ├®gal ├Ā 0 |
| 0x2 - 0x3 | 2 octets | nombre de secteurs ├Ā lire |
| 0x4 .. 0x7 | 4 octets | [segment :offset]┬Ā: un pointeur vers la zone m├®moire dans laquelle on va stocker les donn├®es lues |
| 0x8 .. 0xf | 8 octets | le num├®ro du premier secteur qu'on va lire┬Ā: 0 .. (264 ŌłÆ 1) |
Ainsi, la fonction 0x42 peut lire 216 secteurs ├Ā la fois (nombre de secteurs ├Ā lire) et peut traiter un disque dur (par exemple) de taille 264 ŌłŚ 512 octets┬Ā! Et je vous laisse faire le calcul.
En cas d'erreur de lecture, le bit CF du registre EFLAGS sera mis ├Ā 1. Une instruction JC (Jump short if carry) peut ├¬tre utilis├®e pour traiter l'erreur, en r├®p├®tant la lecture par exemple.
Le code de notre programme d'amor├¦age (boot.s) est le suivant┬Ā:
.code16
.text
.global _start
_start :
mov %cs,%ax
mov %ax,%ds # DS = 0 x7c0
mov %ax,%es # ES = 0 x7c0
mov %ax,%ss # SS = 0 x7c0
mov $0x100,%sp # TOS = 256 (512 octets)
movb $0x42,%ah # fonction 0x42 : lecture ├®tendue des secteurs
movw $dap,%si # SI = dap : pointeur vers la structure
int $0x13
ljmp $0x900,$0x0 # JMP vers [segment:offset] =
# 0x900 x 0x16 + 0x0 = 0x9000
## DAP : Disk Address Packet
dap : .byte 0x10 # taille de dap = 16 octets
.byte 0x0 # inutilis├® : ├®gale 0
.word 0x1 # nombre de secteurs ├Ā lire
## buffer = [ segment:offset] : m├®moire vers
## laquelle on va transf├®rer le contenu des secteurs lus
.word 0x0000 # offset
.word 0x900 # segment
.quad 0x1 # secteur2 : l'index du premier secteur
.org 510
.word 0xaa55├Ć son ex├®cution, notre programme va lire le deuxi├©me secteur du p├®riph├®rique de stockage (secteur num├®ro 1) et charger les donn├®es stock├®es dedans (binaire du programme hello.s) dans la m├®moire ├Ā l'adresse physique 0x9000┬Ā:
segment :offset = 0x0900 :0x0000
adresse physique = 0x0900 * 0x10 + 0x0000 = 0x9000
L'instruction ljmp va transf├®rer le contr├┤le au programme situ├® ├Ā cette adresse (voir section IV-GSyntaxe des instructions 80386 (IA-32)).
VI. R├®f├®rences▲
- Intel 80386 Programmer's Reference Manual
- le manuel de l'assembleur GNU
- le manuel du linker ld
- PC Assembly Language, par Paul A. Carter.